1. ���ݷ���
����һ���Ϊ<ѵ����(train)����֤��(dev)�����Լ�(test)>
����,��֤����������ѡ����õ�ģ��,���Լ�����������
| ѵ���� | ��֤�� | ���Լ� |
|---|
(1)����������Сʱ(100��1000��1000)
����һ�㰴�����±���
| ѵ���� | ��֤�� | ���Լ� |
|---|---|---|
| 60% | 20% | 20% |
(2) ���������ϴ�ʱ(��ʮ��,����)
����һ�㰴�����±���
| ѵ���� | ��֤�� | ���Լ� |
|---|---|---|
| 98% | 1% | 1% |
����:
| ѵ���� | ��֤�� | ���Լ� |
|---|---|---|
| 99.5% | 0.5% | 0.1% |
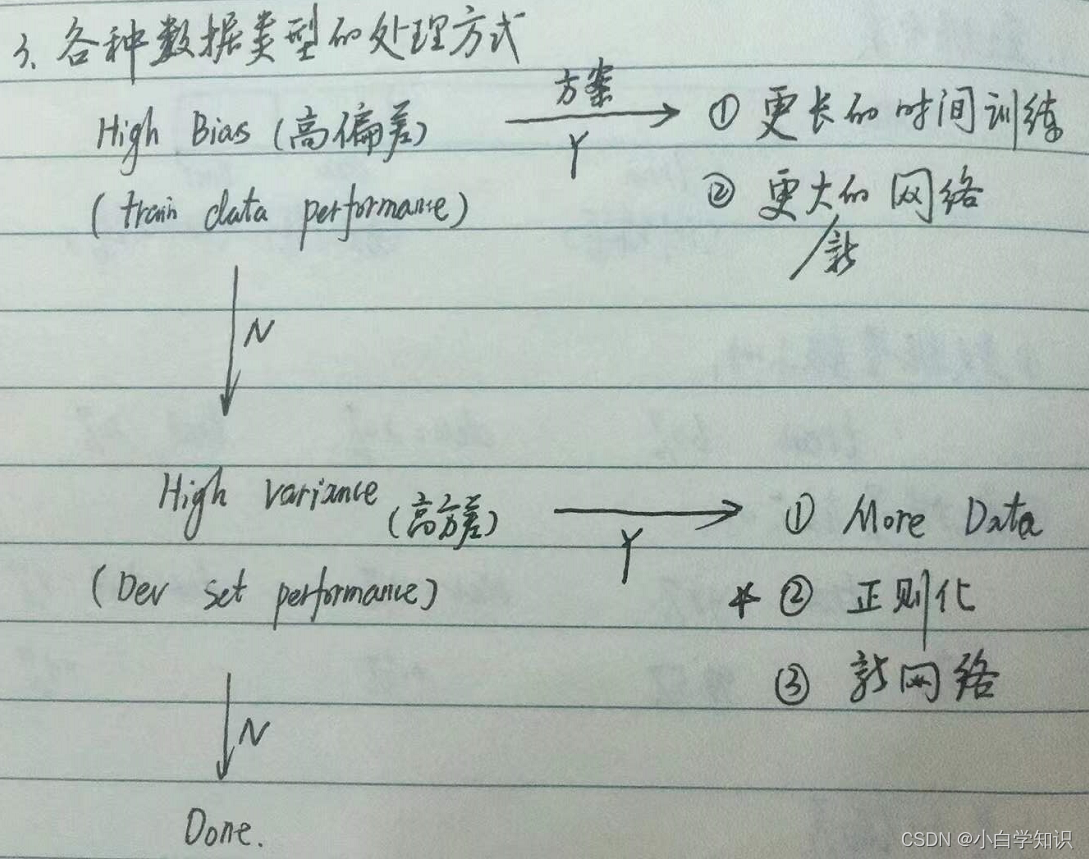
2. ����(variance)��ƫ��(bias)
(1)����
������Ԥ��ֵ������һ��ָ��,��ƫ����Ԥ��ֵ����ʵֵ��һ��ָ�ꡣ
(2) ʾ��
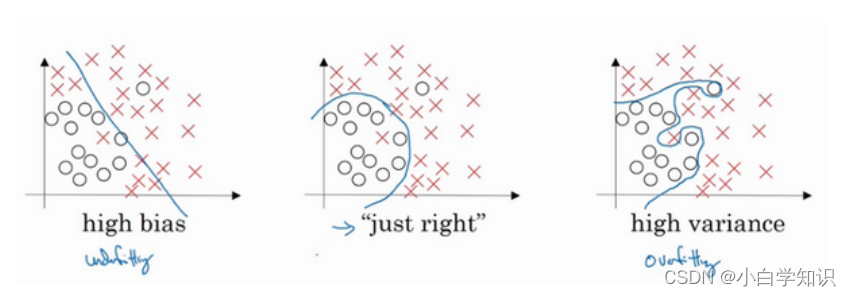
3. �������εĴ�����ʽ
4. ����
(1)��������
���ѧϰ���ܴ��ڹ�������⡪���߷���,�������������,һ��������,��һ���������������,���Ƿdz��ɿ��ķ���,���������ʱʱ�̿����㹻���ѵ�����ݻ���ȡ�������ݵijɱ��ܸ�,������ͨ�������ڱ������ϻ�������������
(2) L 2 L2 L2 ����
J
(
w
,
b
)
=
1
2
��
i
=
1
m
L
(
y
^
i
,
y
i
)
+
��
2
m
�O
�O
w
�O
�O
2
2
J(w, b) = {1\over2} \sum_{i=1}^m L(\hat{y}^{i}, y^{i}) + {\lambda \over{2m}} ||w||^2_2
J(w,b)=21?i=1��m?L(y^?i,yi)+2m��?�O�Ow�O�O22?
����:
��
\lambda
�� :������,ͨ��ʹ����֤���������������
�O
�O
w
�O
�O
2
2
||w||^2_2
�O�Ow�O�O22? :ŷ����÷���(2����)��ƽ��,����:
�O
�O
w
�O
�O
2
2
=
��
n
j
=
1
w
j
2
=
w
T
w
||w||^2_2= \underset{j=1}{\overset{n}{\sum}} w^2_j=w^Tw
�O�Ow�O�O22?=j=1��n??wj2?=wTw
5. ��������ʵ�� �� 2 \lambda2 ��2����
??�������а���һ���ɱ�����,�ú�������
w
[
1
]
,
b
[
1
]
,
.
.
.
,
w
l
1
]
,
b
[
l
]
w^{[1]}, b^{[1]},...,w^{l1]},b^{[l]}
w[1],b[1],...,wl1],b[l]���в���,��ĸ
l
l
l��������IJ���,��˳ɱ���������
m
m
m��ѵ��������ʧ�������ܺͳ���
1
m
1\over{m}
m1?, ������Ϊ
��
2
m
��
L
1
�O
w
[
l
]
�O
2
{\lambda\over{2m}} \underset{1}{\overset{L}{\sum}}|w^{[l]}|^2
2m��?1��L??�Ow[l]�O2,���dz�֮Ϊ
�O
�O
w
[
l
]
�O
�O
2
||w^{[l]}||^2
�O�Ow[l]�O�O2ƽ������,���������������Ϊ����������Ԫ�ص�ƽ�����
J
(
w
[
1
]
,
b
[
1
]
,
.
.
.
,
w
[
L
]
,
b
[
L
]
)
=
1
m
��
m
i
=
1
L
(
y
^
(
i
)
,
y
(
i
)
)
+
��
2
m
��
L
l
=
1
�O
�O
w
[
l
]
�O
�O
F
2
J(w^{[1]}, b^{[1]},...,w^{[L]}, b^{[L]}) = {1\over{m}} \underset{i=1}{\overset{m}{\sum}}L(\hat{y}^{(i)},y^{(i)}) + {\lambda\over{2m}} \underset{l=1}{\overset{L}{\sum}}||w^{[l]}||^2_F
J(w[1],b[1],...,w[L],b[L])=m1?i=1��m??L(y^?(i),y(i))+2m��?l=1��L??�O�Ow[l]�O�OF2?
??����,F: ��ʾ�����ޱ�����˹������,���±� F ��ע��,��������;
�O
�O
w
[
l
]
�O
�O
F
2
=
��
n
[
l
?
1
]
i
=
1
��
n
[
l
]
j
=
1
(
w
i
j
[
l
]
)
2
||w^{[l]}||^2_F = \underset{i=1}{\overset{n^{[l-1]}}{\sum}} \underset{j=1}{\overset{n^{[l]}}{\sum}} (w^{[l]}_{ij})^2
�O�Ow[l]�O�OF2?=i=1��n[l?1]??j=1��n[l]??(wij[l]?)2