基于贝叶斯的自然语言数据标注算法原理详解及实现
??标注数据是每个算法工程师的噩梦,无穷的数据量和无技术意义的体力活往往是很折磨人的,这里给各位介绍一个比较能大大提高标注效率的算法工具-贝叶斯,相信贝叶斯各位都是很熟悉的,这里会从算法原理到整体标注实现方案都会一一进行梳理,希望能帮到需要做标注的同学。
??值得凡尔赛一下的是整体代码纯粹自己实现,且亲测标注过程中很实用,到后面只需要让模型自己预测就行,操作简单,效率大大提高(想想如果每条数据标注节省几秒,几十万几百万的数据那就省了不可估量的时间,并且同时能着实感受到所用到算法模型的性能,优势和缺点,提高自己对算法模型的理解,这也是给各位标注数据的同学一点点自我安慰了),正文开始!!!
1、贝叶斯是什么
?? 贝叶斯是一个后验概率(经常出现在似然估计中的似然函数的计算),比如在NLP中其实就是给你一句话术,它是属于某个类别的概率,这里举例话术意图有H个,话术数据为D,那么贝叶斯公式可以表示为:
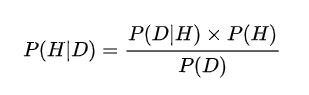
贝叶斯计算的就是在得到一个话术D后,判断这个话术属于哪个类别D的概率(想到这里其实已经可以开始看到了我们标注数据的雏形了,确实我们这些苦逼的数据标注工具人做的就是这么一个事情,拿到一个数据话术,然后来给它进行分类)。
2、怎样将话术数据使用贝叶斯进行建模
?? 作为算法工程师最重要的任务就是建模了,将简单问题抽象化,即将实际问题转化为数学问题,下面继续细谈。
?? 从一部分中我们已经感觉到了,后验概率中H就是我们想要分的类别,其实在NLP标注中可以理解为你要分到的域domain或者是意图intent,这里我们表示成上面的H(h_intent1,h_intent2,…,h_intentn);D是我们标注的每一个话术(话术九十八一句话比如:我想明天去买一个华为手机),D中包含了若干个词,NLP中处理数据最小单位就是词了,所以D需要进行一下分词处理,处理结果为D[‘我’,‘想’,‘明天’,‘去买’,‘一个’,‘华为手机’],根据贝叶斯公式:
??????????
P(H|D)=P(D|H)*P(H)/P(D)
??写的再详细一点就明白了:
??这里我们将各个概率部分都单独领出来写一下.
2.1 P(D|H) 怎么算
P(D|H)=P([‘我’,‘想’,‘明天’,‘去买’,‘一个’,‘华为手机’]/[H])
??[]中每个元素都是一个独立的事件,所以就可以转换为联合概率的形式:
??
P(D|H)
=P(‘我’/[H])*P(‘想’/[H])*P(‘明天’/[H])*P(‘去买’/[H])*P(‘一个’/[H])*P(‘华为手机’/[H])
有一点需要说一下,在实际计算中,将各个类别带入就是成了:
P(D|h_intent1)
=P(‘我’/[h_intent1])*P(‘想’/[h_intent1])*P(‘明天’/[h_intent1])*P(‘去买’/[h_intent1])*P(‘一个’/[h_intent1])*P(‘华为手机’/[h_intent1])
…
P(D|h_intentn)
=P(‘我’/[h_intentn])*P(‘想’/[h_intentn])*P(‘明天’/[h_intentn])*P(‘去买’/[h_intentn])*P(‘一个’/[h_intent1])*P(‘华为手机’/[h_intentn])
2.2 P(H) 怎么算
??这个相对计算起来简单多了,就是计算每个类别的概率,比如在时间标注数据中,每个类别都会有相对应得发生次数,所以每个类别可以计算为:
P(h_intent1) = 发生次数(h_intent1)/总发生数,
…
P(h_intentn) = 发生次数(h_intentn)/总发生数
2.3 P(D) 怎么算
??这个其实可以不用计算,因为对于每个话术,它得后验概率公式中分母 P(D) 都是相同得,都是:
P(D|H)=P([‘我’,‘想’,‘明天’,‘去买’,‘一个’,‘华为手机’])
=P(‘我’)*P(‘想’)*P(‘明天’)*P(‘去买’)*P(‘一个’)*P(‘华为手机’)
其中每个词的概率,比如P(‘我’)=‘我’的出现次数/所有词出现次数,这个就是个词频,和上面介绍的类别中的词频不同的是这个分母是所有文档的词频。
2.4 最后的后验概率怎么算
??把上面计算公式都带入总的贝叶斯概率模型中,所以有:
P(H|D)=P(D|H)*P(H)/P(D)
==P(‘我’/[H])*P(‘想’/[H])*P(‘明天’/[H])*P(‘去买’/[H])*P(‘一个’/[H])*P(‘华为手机’/[H]) *P(H) /P(‘我’)*P(‘想’)*P(‘明天’)*P(‘去买’)*P(‘一个’)*P(‘华为手机’)
看懂了把,假如计算第一个类别:
P(h_intent1|D)=P(D|h_intent1)*P(h_intent1)/P(D)
==P(‘我’/[h_intent1])*P(‘想’/[h_intent1])*P(‘明天’/[h_intent1])*P(‘去买’/[h_intent1])*P(‘一个’/[h_intent1])*P(‘华为手机’/[h_intent1]) *P(h_intent1) /P(‘我’)*P(‘想’)*P(‘明天’)*P(‘去买’)*P(‘一个’)*P(‘华为手机’)
以此将每个类别h_intentn 带入就计算出了每个类别的概率,取概率最大的作为所属结果,因为每个话术的P(D)都是一样的所以可以直接计算分子的内容就可以了,所以最终结果可以为:
P(h_intent1|D)=P(D|h_intent1)*P(h_intent1)/P(D)
==P(‘我’/[h_intent1])*P(‘想’/[h_intent1])*P(‘明天’/[h_intent1])*P(‘去买’/[h_intent1])*P(‘一个’/[h_intent1])*P(‘华为手机’/[h_intent1]) *P(h_intent1)
最终,实际工作中值得注意的俩点:
1、比如上面的词有 一个、我、的 这类对分类每有意义的词可以直接过滤掉,即构建一个有效词典,不同的业务其实词典是不同的;
2、上面的计算公式可以转化为似然函数计算方式,即使用log函数计算,这样一来,上式的乘的计算转化为了相加的方式,即最终结果为:
log(P(H|D))=log(P(D|H)*P(H)/P(D))
=log(P(‘我’/[H]))+log(P(‘想’/[H]))+log(P(‘明天’/[H]))+…+log(P(‘华为手机’/[H])) *log(P(H))
这就是最终算法计算公式了。
标注实现算法逻辑技术框架 待续。
代码 github链接地址(后续修改好附上)