确定变量间的关系
确定变量间的关系
变量间的关系大体上分为函数关系和相关关系(大致理解:前者是一个变量值的变化完全依赖于另一个变量的变化,后者是一个变量的取值不能由另一个变量唯一确定)
相关关系的描述
描述相关关系的一种常用工具就是散点图
对于两个变量x和y,可以根据散点图的分布形状等判断它们之间有没有什么关系
数据:20家医药生产企业的销售收入和广告支出

导入数据:example9_1<-read.csv("D:/R/example9_1.csv")
绘制散点图:
library(car)
scatterplot(销售收入~广告支出,data=example9_1,pch=19,xlab="广告支出",ylab="销售收入",cex.lab=0.8)
带有箱线图、拟合直线、拟合曲线的销售收入与广告收入的散点图
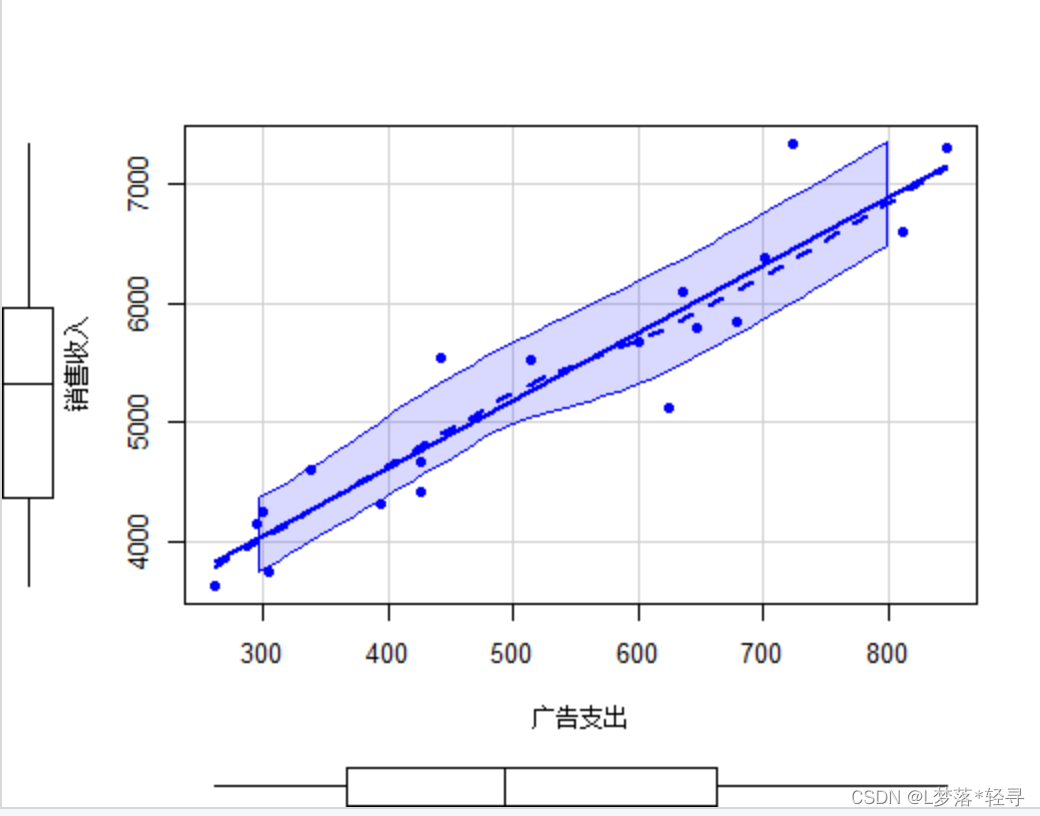
广告支出与销售收入的观测点分布在一条直线周围,因而具有正的线性相关关系,从拟合的曲线来看,非线性特征不明显,显示两个变量为线性关系
关系强度的度量
- 相关系数
根据散点图可以判断两个变量之间有无相关关系,并对关系形态做出大致描述,但要准确度量变量间的关系强度,则需要计算相关系数,计为r
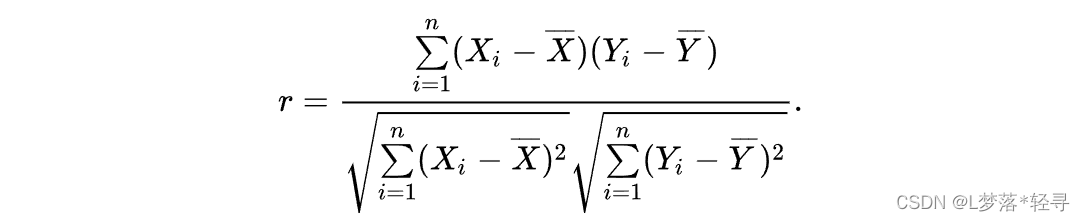
按上式计算的相关系数也叫Pearson相关系数
计算相关系数时,假定两个变量之间是线性关系,而且两个变量都是随机变量,服从一个联合的双变量正态分布(并不是简单地要求两个变量各自服从正态分布),此外样本数据中不应有极端值,否则会对相关系数的值有较大影响
r的取值范围在-1~1,r=0值表示两个变量之间不存在线性关系,并不表示没有任何关系,|r|->1表示两个变量之间的线性关系强
- 相关系数的检验
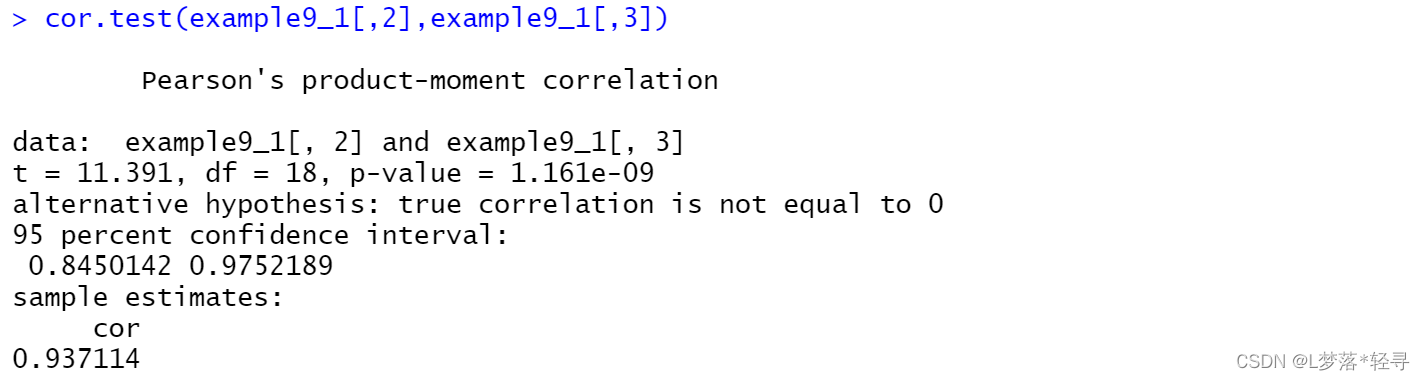
总体相关系数通常是未知的,需要根据样本相关系数r做近似估计,由于r是根据样本数据计算的,抽取的样本不同,r的取值也不同,因此r是一个随机变量,能否用样本相关系数表示总体的相关程度,需要进行显著性实验,通常采用t检验方法,该检验可用于小样本也可用于大样本。
计算相关系数
#相关系数r越大线性关系越显著
cor(example9_1[,2],example9_1[,3])
检验相关系数
cor.test(example9_1[,2],example9_1[,3])
模型估计和检验
确定变量间的关系后,就可以依据关系形态建立适当的回归模型
回归模型与回归方程
描述因变量y如何依赖于自变量x和误差项的方程称为回归模型
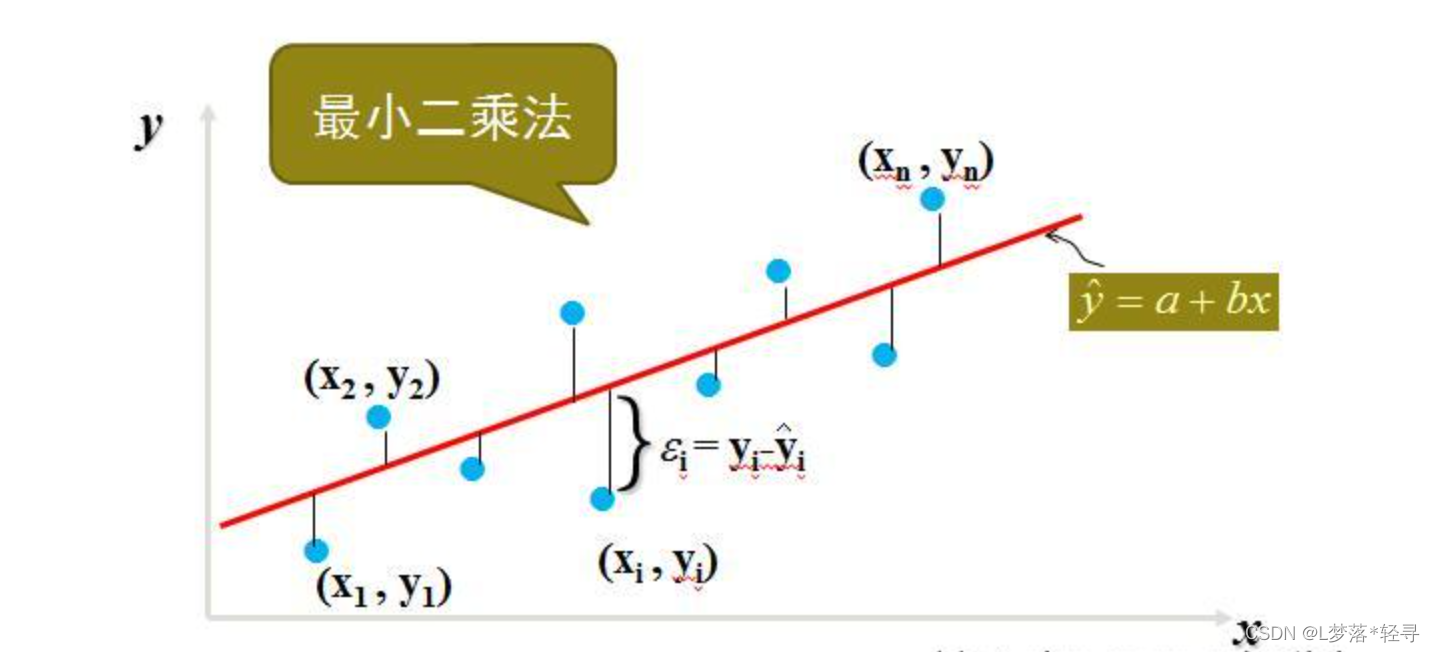
模型参数的估计通常采用最小二乘估计,或称最小平方估计
利用最小二乘估计法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小
 回归模型的拟合
回归模型的拟合
model<-lm(销售收入~广告支出,data=example9_1)#模型拟合
summary(model)#输出结果
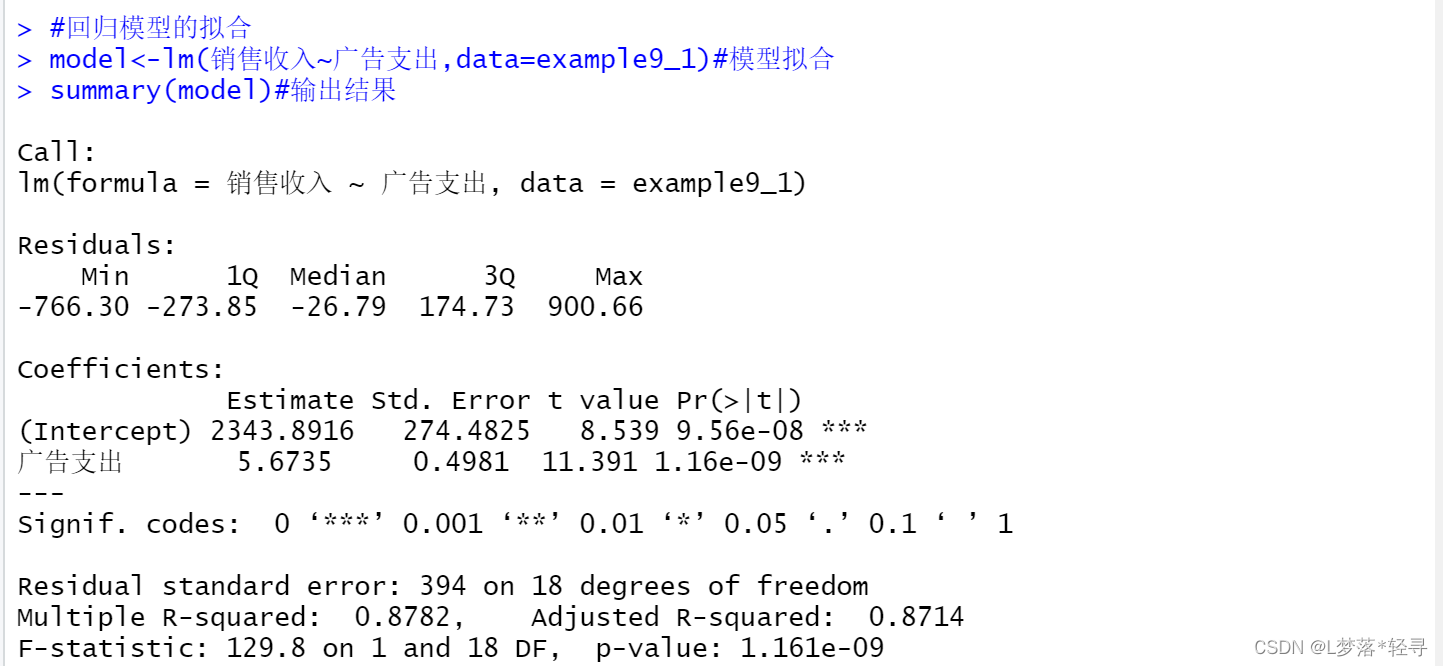
根据结果可知,销售收入与广告支出的估计方程为:y^=2343.8916+5.6735*广告支出
计算回归系数的置信区间
confint(model,level=0.95)

输出方差分析表
anova(model)

模型的拟合优度
回归直线与个观测点的接近程度称为回归模型的拟合优度
评价拟合优度的一个重要统计量就是决定系数(Multiple R-squared)

残差的标准误是残差平方和的均方根,用se表示(Residual standard error)
se=sqrt(SSE/(n-2))
即残差平方和除以自由度(n-2)后开方
模型的显著性检验
回归分析中的显著性检验主要包括线性关系检验和回归系数检验
线性关系检验简称F检验,它是检验因变量与自变量之间的线性关系是否显著,或者说它们之间能否用一个线性模型来表示(F-statistic)
假设H0:两个变量之间的线性关系不显著 H1:两个变量间的线性关系显著
回归系数检验简称t检验,用于检验自变量对因变量的影响是否显著
在一元线性回归中,由于只有一个自变量,回归系数检验与线性关系检验是等价的
利用回归方程进行预测
回归分析的主要目的是根据所建立的回归方程用给定的自变量来预测因变量
如果对于x的一个给定值x0,求出y的一个预测值y0^,就是点估计
在点估计的基础上,可以求出y的一个估计区间
估计区间有两种:均值的置信区间和个别值的预测区间
均值的置信区间:对x的一个给定值x0,求出的y的均值的估计区间
个别值的预测区间:对x的一个给定值x0,求出y的一个个别值的估计区间
计算点预测值、置信区间和预测区间
x0<-example9_1$广告支出
pre_model<-predict(model)
cont_int<-predict(model,data.frame(广告支出=x0),interval="confidence",level=0.95)
pre_int<-predict(model,data.frame(广告支出=x0),interval="prediction",level=0.95)
data.frame(销售收入=example9_1$销售收入,点预测值=pre_model,置信下限=cont_int[,2],置信上限=cont_int[,3],预测下限=pre_int[,2],预测上限=pre_int[,3])
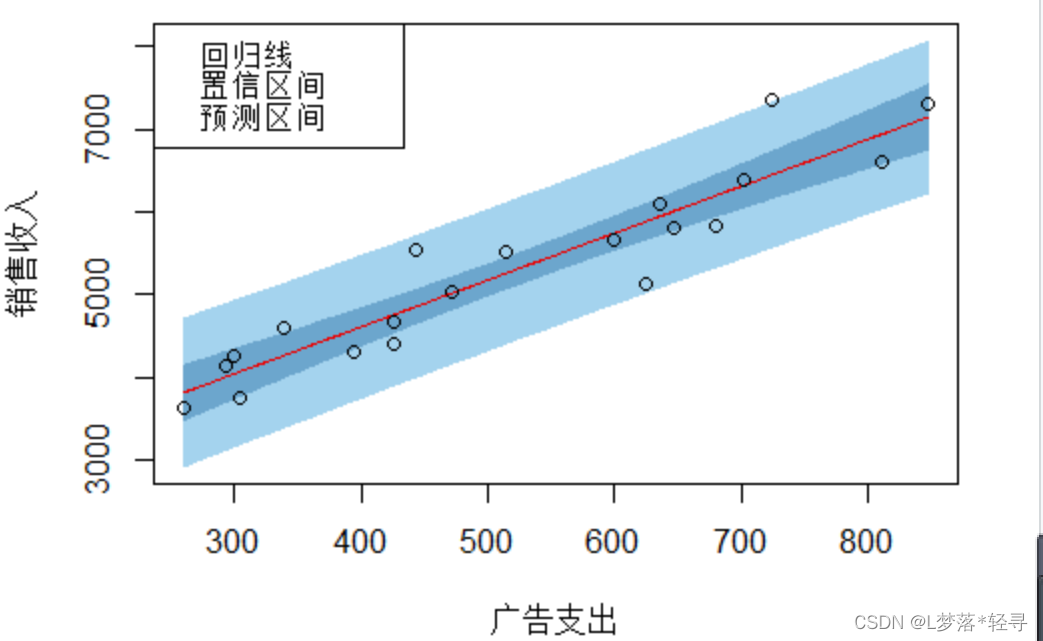
绘制置信带和预测带
library(investr)
plotFit(model,interval="both",level=0.95,shade=TRUE,col.conf="skyblue3",col.pred="lightskyblue2",col.fit="red2")
legend(x="topleft",legend=c("回归线","置信区间","预测区间"),col=c("red2","skyblue3","lightskyblue2"),cex=0.8)
计算x0=500时销售收入的点预测值、置信区间、预测区间
x0<-data.frame(广告支出=500)
predict(model,newdata=x0)
predict(model,newdata=x0,interval = "confidence",level=0.95)
predict(model,newdata=x0,interval = "prediction",level=0.95)
回归模型的诊断
残差与残差图
残差是因变量的观测值与根据回归方程求出的估计值之差,用e表示,它反映了用估计的回归方程预测yi而引起的误差
残差除以它的标准误后的结果称为标准化残差
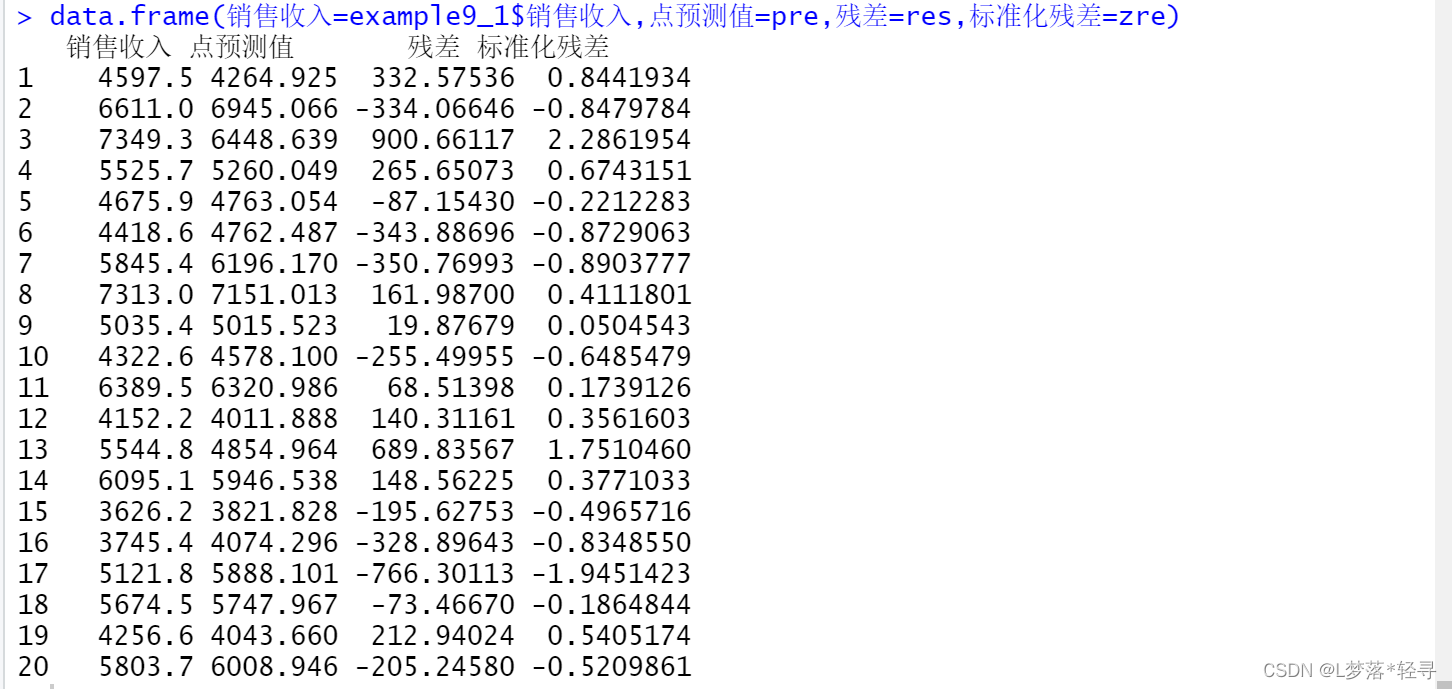
计算回归预测值,残差,标准化残差
pre<-fitted(model)
res<-residuals(model)
zre<-model$residuals/(sqrt(deviance(model)/df.residual(model)))
data.frame(销售收入=example9_1$销售收入,点预测值=pre,残差=res,标准化残差=zre)
检验模型假定
- 检验线性关系
检验因变量与自变量之间为线性关系的假定,除了可以通过F检验外,还可以绘制成分残差图
library(car)
crPlots(model)
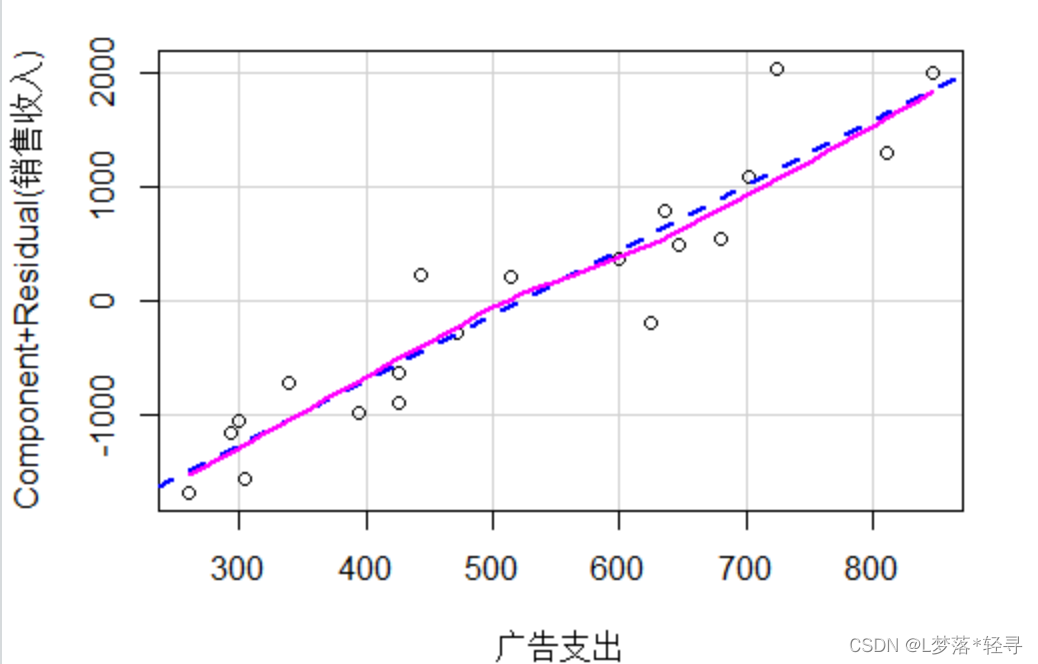 横坐标是自变量的实际观测值,纵坐标是因变量与残差之和
横坐标是自变量的实际观测值,纵坐标是因变量与残差之和
销售收入与广告支出之间没有明显的非线性模式,说明二者之间的线性关系假定成立
- 检验正态性
通过绘制残差的Q-Q图完成
par(mfrow=c(2,2),cex=0.8,cex.main=0.7)
plot(model)
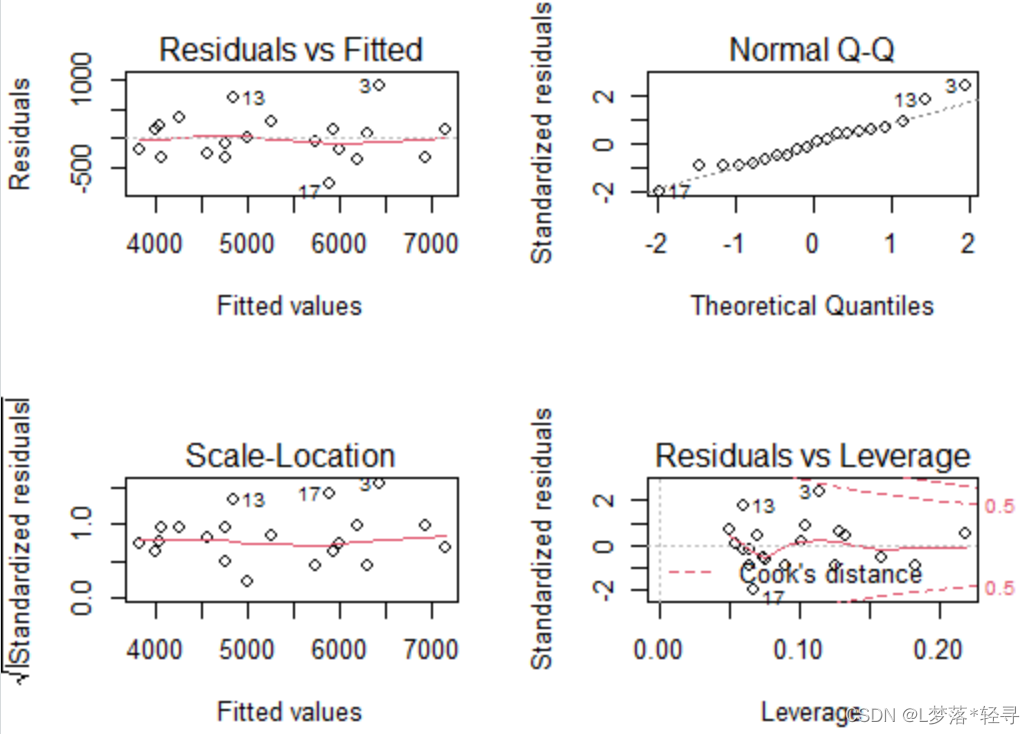
从该图可以看出,各个点基本上在直线周围随机分布,没有固定模式,因此,在销售收入与广告支出的线性模型中,关于正态性的假定基本成立
- 检验方差齐性
通过绘制散布-水平图实现
ncvTest(model)
spreadLevelPlot(model)

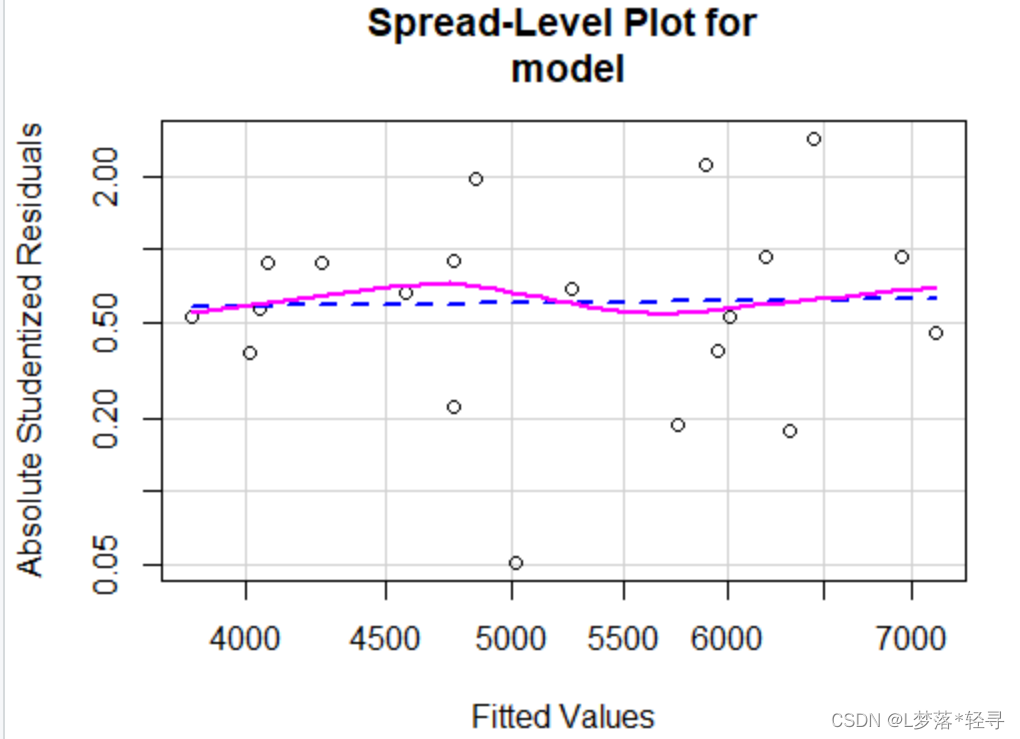
由于p=0.2885358,不拒绝原假设,则可以认为满足方差齐性
从该图可以看出,拟合曲线接近于水平直线,没有非线性特征,而且各个点在改线周围随机分布,显示建立的线性模型满足方差齐性的假定
- 检验独立性
判断残差之间是否存在自相关的方法之一就是使用Durbin-Watson检验,简称D-W检验
library(car)
durbinWatsonTest(model)

检验的P值等于0.52,不拒绝原假设,显示残差无自相关,独立性假定成立。