目录
一、前言
? ? ? ? 最近才接触GAN,昨天利用GAN生成动漫头像时候发现生成的图片质量不太好,今天利用CGAN(Conditional Generative Adversarial Nets)来生成一下动漫人物头像。数据集采用的是李宏毅老师视频中提供的face,链接见底部。
二、GAN简介
? ? (一)GAN
? ? ? ? GAN由生成器(Generator)和判别器(Discriminator)组成,生成器负责生成假的图片来骗过判别器,而判别器需要不断从真实图片上学习特征来提高自己的判别能力。
????????GAN本质是一个博弈的过程,首先生成器G将输入的随机噪声通过神经网络生成一张图,判别网络D会对G生成的假图进行打分(分值越接近0表示图片越假,越接近1表示图片越真),从而引导G生成更真的图(既然判别器D要引导生成器G变得更好,那么D的判别能力起到至关重要的作用,因此判别器D也在不断学习真实图片的特征,从而提高自己的判别能力)。
? ? ? ?训练过程中,生成器G和判别器D要分别进行优化。?在优化过程中,生成器G的目的是要让判别器对G生成的图片尽量打出高分;判别器D的目的是要尽可能将真实图片与G生成的图片区分开来(这部分理论就不进行详细说明了)。
? ? ? ? 最终,当判别器D无法判断生成器G生成图片的真假时训练结束,此时G生成的图片可以以假乱真。
? ? (二)CGAN
????????CGAN本质是一种监督学习,通过引导信息促使G朝着人为设定的方向生成图片。
????????由于生成器G的输入是噪声信号z,即便最终模型训练好,依旧没办法人为控制G生成我们想要的图片。因此我们希望通过一种手段,能够控制G按照我们的需求去生成图片,主要有两种方式:(1)text-to-Image,即通过text去引导G;(2)Image-to-Image,即通过图像去引导G。这两种方法大同小异,因为text的本质也是一个embedded,将其与噪声信息进行cat拼接即可输入G中,这里把引导信息(image或text)记作c。此外,D的评价准则不仅仅只依靠G生成图片的真假,还需要判断G生成的图片是否与c匹配,因此判别器D的输入同样有两部分,输入的图片(G生成的或者真实的图片)以及c。只有当D的输入为真实图片并且与c匹配时候,D才会打高分,其他情况D需要尽量打出低分。
三、代码
? ??(一)数据读取
? ? ? ? (图片,特征)存放在了extra_data下的tags.csv下,如下图所示。
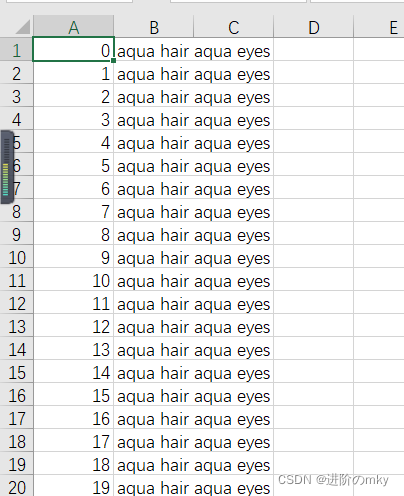
? ? ? ? 第一列代表图片的序号,第二列是图片对应的特征信息,共包括四个特征,第一个aqua表示头发的颜色(这里共有13种),hair表示有头发,第二个aqua表示眼睛的颜色(同样有13种),eyes表示有眼睛(这部分是我自己的理解,写这篇博文的时候发现好像这部分理解有点问题,实际是两个特征,前两个表示头发特征,后两个表示眼睛特征,不过理解成四个特征并不影响实际结果)。
? ? ? ? 首先创建一个json文件来存储颜色对应的索引,如下图所示。?我用一个长度为28的一维向量P来表示该张图片的特征,前13个元素表示头发颜色,假设颜色为red,那么对应索引为4,就将这个一维向量P第4个位置(索引是3的位置)置为1,眼睛颜色同理,最后将P的索引位置为13以及最后一个元素置为1(表示有头发有眼睛)。
? ? ? ? 注:这部分也可以用别的方法来表示图片特征。
{
"aqua": "0",
"gray": "1",
"green": "2",
"orange": "3",
"red": "4",
"white": "5",
"black": "6",
"blonde": "7",
"blue": "8",
"brown": "9",
"pink": "10",
"purple": "11",
"yellow": "12"
}? ? ? 数据集加载部分代码如下:
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
import json
import pandas as pd
import os
import torch
class Datasets(Dataset):
def __init__(self,root_dir):
#获取图片路径以及label
with open('features.json', 'r', encoding='utf-8') as file:
fea_index = json.load(file)
# 读取csv文件并解析
fts = pd.read_csv(os.path.join(root_dir, 'tags.csv'), header=None) # headr None 表示不把第一行作为属性
fts = fts.values
img_path = [os.path.join(root_dir, 'images') + '\\' + str(idx) + '.jpg' for idx in list(fts[:, 0])] # 图片路径
feature = [[item.split(' ')[0], item.split(' ')[2]] for item in list(fts[:, 1])]
# 处理真实label (即c)
final_feature = []
for i in feature:
demo = torch.zeros(28,dtype=torch.int8)
demo[13],demo[-1] =1,1
demo[int(fea_index[i[0]])]=1 #第一个特征
demo[int(fea_index[i[1]])+14]= 1 # 第二个特征
final_feature.append(demo)
self.img_list = img_path
self.labels = final_feature
self.transforms=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
def __len__(self):
return len(self.img_list)
def __getitem__(self, item):
image = Image.open(self.img_list[item])
image = self.transforms(image)
label = self.labels[item]
return image , label
? ? (二)model
import torch.nn as nn
import torch
from torch.nn.utils import weight_norm
#定义编码器
class GAN_generator(nn.Module):
def __init__(self,x_dim,c_dim):
"""
:param x_dim: 输入噪声的dim,本代码中是100
:param c_dim: 引导信息c的dim,本代码中是28
"""
super(GAN_generator, self).__init__()
#定义基本的卷积、BN、relu
def base_Conv_bn_relu(in_channels,outchannels,stride):
pad = stride // 2
return nn.Sequential(
nn.ConvTranspose2d(in_channels,outchannels,4,stride,pad),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True)
)
dim = x_dim + c_dim
self.G=nn.Sequential(
#[batch,in_dim,1,1] =>[batch,128,1,1]
base_Conv_bn_relu(dim,dim*2,1), #[batch,256,4,4]
base_Conv_bn_relu(dim*2,dim*4,2), #[batch,512,8,8]
base_Conv_bn_relu(dim*4,dim*2,2), #[batch,256,16,16]
base_Conv_bn_relu(dim*2,dim,2), #[batch,128,32,32]
nn.ConvTranspose2d(dim,3,4,2,1) #[batch,3,64,64]
)
def forward(self,x , c):
#x: [batch, x_dim] c: [batch , c_dim]
inp = torch.cat([x,c],1) #[batch, c_dim + x_dim]
inp = inp.view(inp.size(0),inp.size(1),1,1) #[batch , x_dim + c_dim , 1 , 1]
out = self.G(inp)
return out
#定义解码器
class GAN_discriminator(nn.Module):
def __init__(self,c_dim):
super(GAN_discriminator, self).__init__()
#定义基本的卷积、BN、leakRelu
def base_conv_bn_lrelu(in_channels,out_channels,kernel_size,stride):
pad = stride // 2
return nn.Sequential(
weight_norm(nn.Conv2d(in_channels,out_channels,kernel_size,stride,pad)),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2,inplace=True)
)
self.D=nn.Sequential(
#[batch,3+c_dim,64,64]
base_conv_bn_lrelu(3+c_dim,64,3,2),
#[batch,64,32,32]
base_conv_bn_lrelu(64,128,3,2),
#[batch,128,16,16]
base_conv_bn_lrelu(128,256,3,2),
#[batch,256,8,8]
base_conv_bn_lrelu(256,256,3,2),
#[batch,256,4,4]
nn.AvgPool2d(kernel_size=4),
#[batch,256,1,1]
)
self.linear = nn.Sequential(
weight_norm(nn.Linear(256,1))
)
def forward(self, x, c):
# c => [batch , c_dim] x => [batch,3,64,64]
c = c.view(c.size(0),c.size(1),1,1) * torch.ones(c.size(0),c.size(1),x.size(2),x.size(3),dtype=torch.int8,device='cuda')
r_x = torch.cat([x,c],1)
out = self.D(r_x)
out = out.flatten(1)
out = self.linear(out)
return out? ? (三)main
? ? ? ? 配置中,weights是预训练好的权重(末尾我会上传我训练的权重文件),dirPath是数据的根目录(tags.csv文件的父目录),every是设置每迭代多少个batch显示训练成果(这部分在utils下),Cdim和Zdim不用修改。
import torch
import torch.nn as nn
from torch import optim
from GAN_model import GAN_generator,GAN_discriminator
from load_datasets import Datasets
from split_data import split_data
import argparse
import os
from torch.utils.data import DataLoader
from utils import train_one_epoch,eval_G
from torch.utils.tensorboard import SummaryWriter
def main(opt):
batch_size = opt.batch
data_path = opt.dirPath
x_dim = opt.Zdim
c_dim = opt.Cdim
epoches=opt.epoches
#定义使用的设备
device='cuda' if torch.cuda.is_available() else 'cpu'
if not os.path.exists('./weights'):
os.mkdir('./weights')
#加载真实数据
train_datasets=Datasets(data_path)
train_dataloader=DataLoader(train_datasets,batch_size=batch_size,shuffle=True)
#实例化生成器和判别器
D_model=GAN_discriminator(c_dim).to(device)
G_model=GAN_generator(x_dim,c_dim).to(device)
#定义优化器和损失函数
D_optim=optim.Adam(D_model.parameters(),lr=0.0002,betas=(0.5,0.999))
G_optim=optim.Adam(G_model.parameters(),lr=0.0002,betas=(0.5,0.999))
loss=nn.MSELoss()
#初始化epoch
start_epoch = 0
if opt.weights:
#加载预训练权重
ckpt=torch.load(opt.weights)
D_model.load_state_dict(ckpt['D_model'])
G_model.load_state_dict(ckpt['G_model'])
try:
start_epoch = ckpt['epoch']+1
except:
pass
writer=SummaryWriter(log_dir='train_logs1') #观察训练结果
# 训练
for epoch in range(start_epoch,epoches):
D_mean_loss , G_mean_loss = train_one_epoch(
epoch=epoch,
D=D_model,
G=G_model,
D_optim=D_optim,
G_optim=G_optim,
train_loader=train_dataloader,
loss=loss,
in_dim=x_dim,
visable_every=opt.every,
writer=writer
)
#绘制损失曲线
writer.add_scalars('mean_loss',{
'G_loss': G_mean_loss,
'D_loss': D_mean_loss
},epoch)
#保存模型
save_dict = {
'D_model' : D_model.state_dict(),
'G_model' : G_model.state_dict(),
'epoch' : epoch
}
torch.save(save_dict,'./weights/CGAN_best1.pth')
#每隔k个epoch验证训练效果 保存到本地
if (epoch+1) % 1 == 0:
eval_G(G=G_model,batch=batch_size,x_dim=x_dim,epoch=epoch)
def parse():
arg=argparse.ArgumentParser()
arg.add_argument('--batch',default=64,type=int)
arg.add_argument('--epoches', default=100, type=int)
arg.add_argument('--weights',default='',help='load weights')
arg.add_argument('--Zdim',default=100,type=int,help='input noise length')
arg.add_argument('--Cdim', default=28, type=int, help='feature length')
arg.add_argument('--every', default=10, type=int, help='visible train result every 100 batch')
arg.add_argument('--dirPath',default='',type=str,help='train data dir path')
opt=arg.parse_args()
return opt
if __name__ == '__main__':
opt=parse()
print(opt)
main(opt)?? ?(四)train?
import os
import torch
import numpy as np
import torchvision
from torch.autograd import Variable
from tqdm import tqdm
def train_one_epoch(epoch,D,G,D_optim,G_optim,train_loader,loss,in_dim,visable_every,writer):
tq = tqdm(train_loader)
all_loss, D_loss, G_loss = 0, 0 , 0
step = 0
for idx , data in enumerate(tq):
image = data[0].to('cuda')
c_data = data[1].to('cuda')
D.train()
G.train()
#用于计算loss的真实label
f_label,r_label=Variable(torch.zeros((image.size(0),1))).cuda(),Variable(torch.ones((image.size(0),1))).cuda()
#随机生成噪声
random_input = np.random.normal(0,1,(2,image.size(0),in_dim)).astype(np.float32) #[2,batch,in_dim]
random_input = torch.from_numpy(random_input).to('cuda')
# 训练3次D,训练一次G
random_input1 = Variable(random_input[0],requires_grad=True)
#真实图片数据
D_r = D(image,c_data)
G_f1=G(random_input1,c_data).detach()
D_f1=D(G_f1,c_data)
loss_D1=loss(D_f1,f_label)
loss_D2=loss(D_r,r_label)
D_optim.zero_grad()
loss_D = 0.5 * (loss_D1 + loss_D2) #D的总损失
loss_D.backward()
D_optim.step()
D_loss +=loss_D
# 固定D,训练G
if (idx+1) % 3 ==0:
random_input2 = Variable(random_input[1], requires_grad=True)
G_f2 = G(random_input2,c_data)
D_f2 = D(G_f2,c_data)
loss_G = loss(D_f2,r_label)
G_optim.zero_grad()
loss_G.backward()
G_optim.step()
G_loss +=loss_G
#动态更新训练情况
try:
tq.desc = 'G_loss : {} D_loss : {}'.format(loss_G.item(),loss_D.item())
except:
tq.desc = 'D_loss : {}'.format(loss_D.item())
#可视化训练效果 == 每(3*every)个batch显示一次结果
if (idx+1) % visable_every == 0 and (idx+1) % 3 ==0:
# writer.add_images(tag='train_epoch', img_tensor=G_f2,global_step=epoch)
writer.add_images(tag='train_epoch{}'.format(epoch), img_tensor=(G_f2 +1)/ 2.0, global_step=step)
step +=1
mean_D_loss = D_loss / len(train_loader)
mean_G_loss = G_loss / len(train_loader)
return mean_D_loss , mean_G_loss
@torch.no_grad()
def eval_G(G,batch,x_dim,epoch):
"""
这部分用来检验训练的成果,c表示我们希望G生成的特征(这里是我随便写的一个特征c)
:return:
"""
#生成特征c
c = gene_C(batch).to('cuda') #[batch,]
# 随机生成噪声
z = Variable(torch.normal(0,1,(batch,x_dim),dtype=torch.float32).cuda())
G.eval()
f_img = G(z,c)
#将图像还原回原样
result_img = (f_img + 1) / 2.0
#保存图片
if not os.path.exists('./results'):
os.mkdir('./results')
torchvision.utils.save_image(result_img,'./results/epoch{}_result.jpg'.format(epoch))
def gene_C(batch):
#生成目标特征c
c1 = [torch.eye(13,14)] * (batch // 13)
c2 = [torch.eye(13,14)] * (batch // 13)
c1 = torch.cat(c1,dim=0)
c2 = torch.cat(c2,dim=0)
c = torch.cat([c1,c2],dim=1)
c3 = torch.zeros((batch % 13,28),dtype=torch.int8)
c3[:,1],c3[:,-1] = 1,1
c = torch.cat([c,c3],dim=0)
c[:,14],c[:,-1] = 1,1
return c
四、训练结果
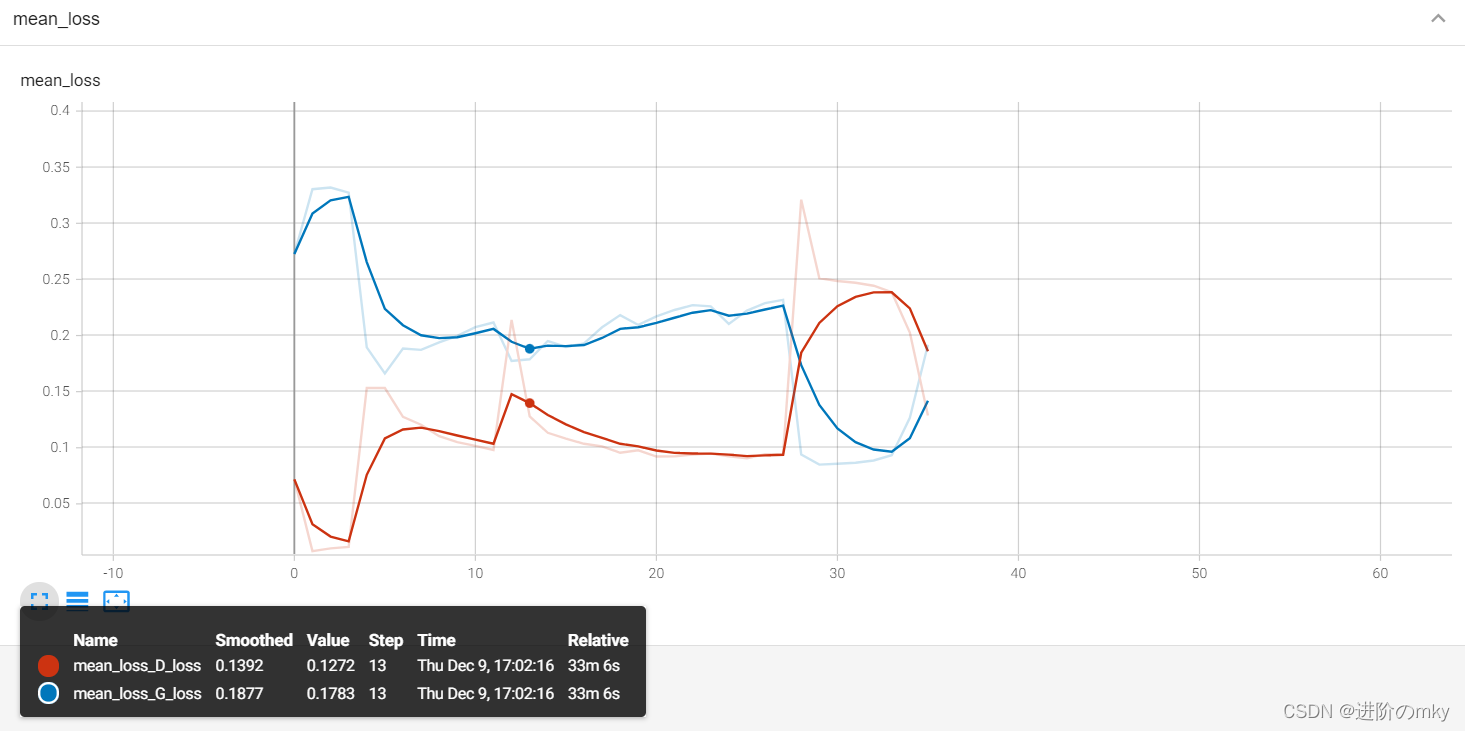
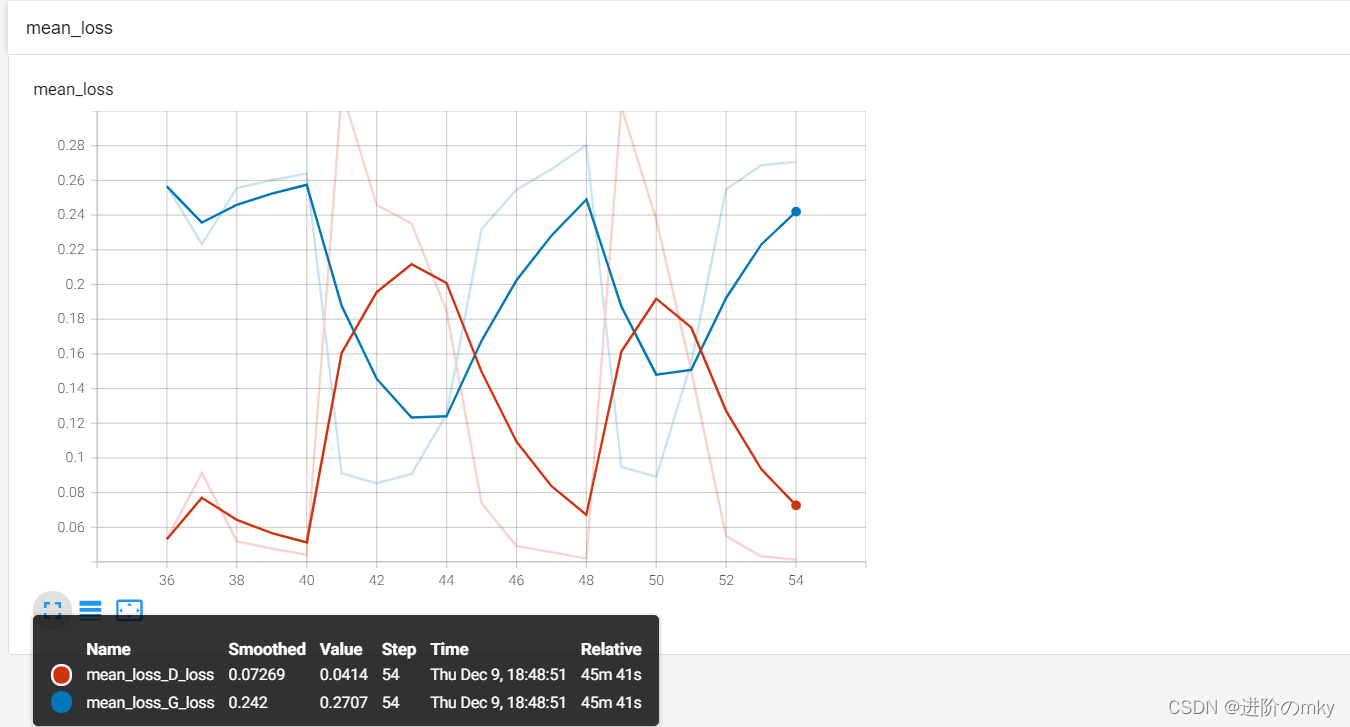
? ? ? ? 最开始,我把生成器G的学习率设为了0.01,D的学习率设为0.0002,迭代了35个epoch之后发现训练效果没有改善,因此后续又将G学习率调为0.0002训练了18个epoch。训练损失如下图所示。? ??
????????
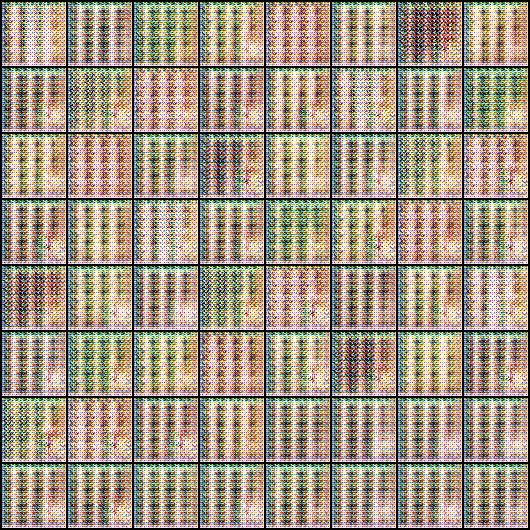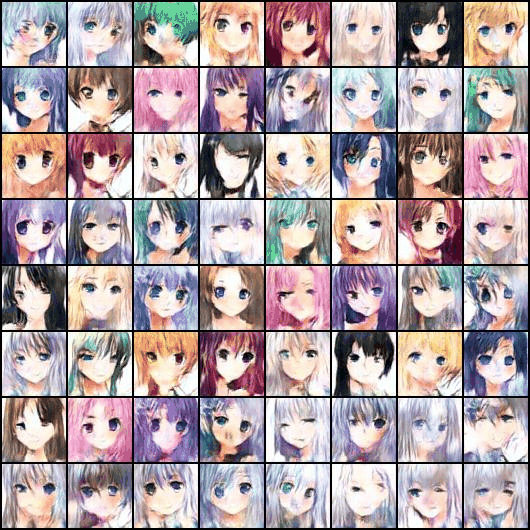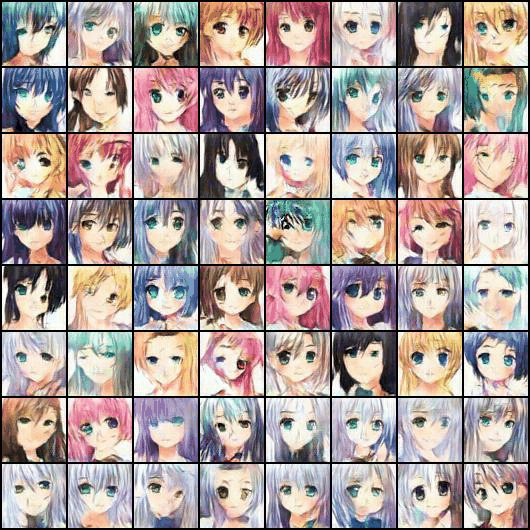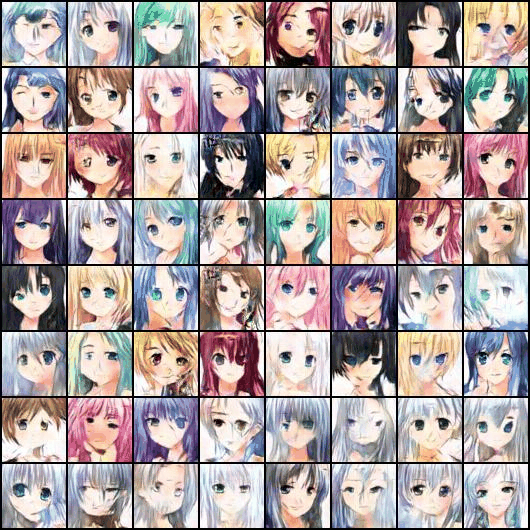
? ? ? ? ?由于设备硬件问题,最终只训练了50个epoch左右,训练成果如下图所示(这里我人为设置了让最后一行的头发均为银色,可见效果还不错)。
五、完整代码
? ? ? ? 代码(包含权重):完整代码? ? ? ??? 提取码:dhen?
????????数据集:data? ? ? ? 提取码:j74u