目录
一、图片转化
(1)原图
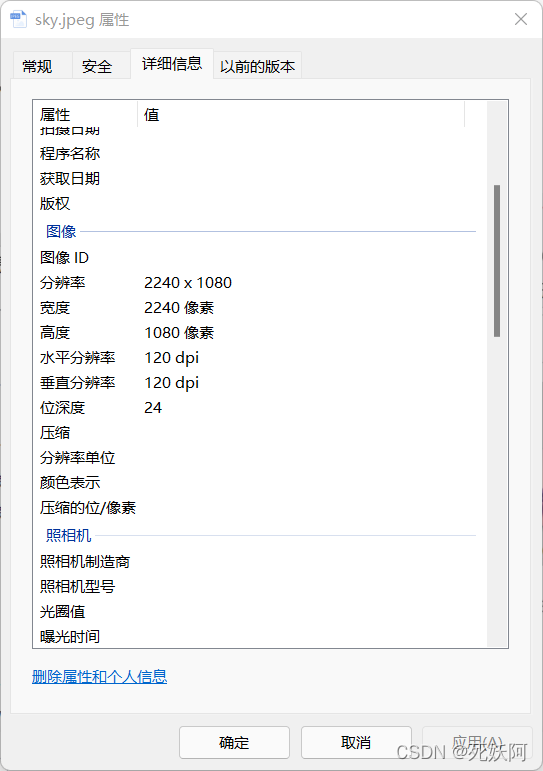
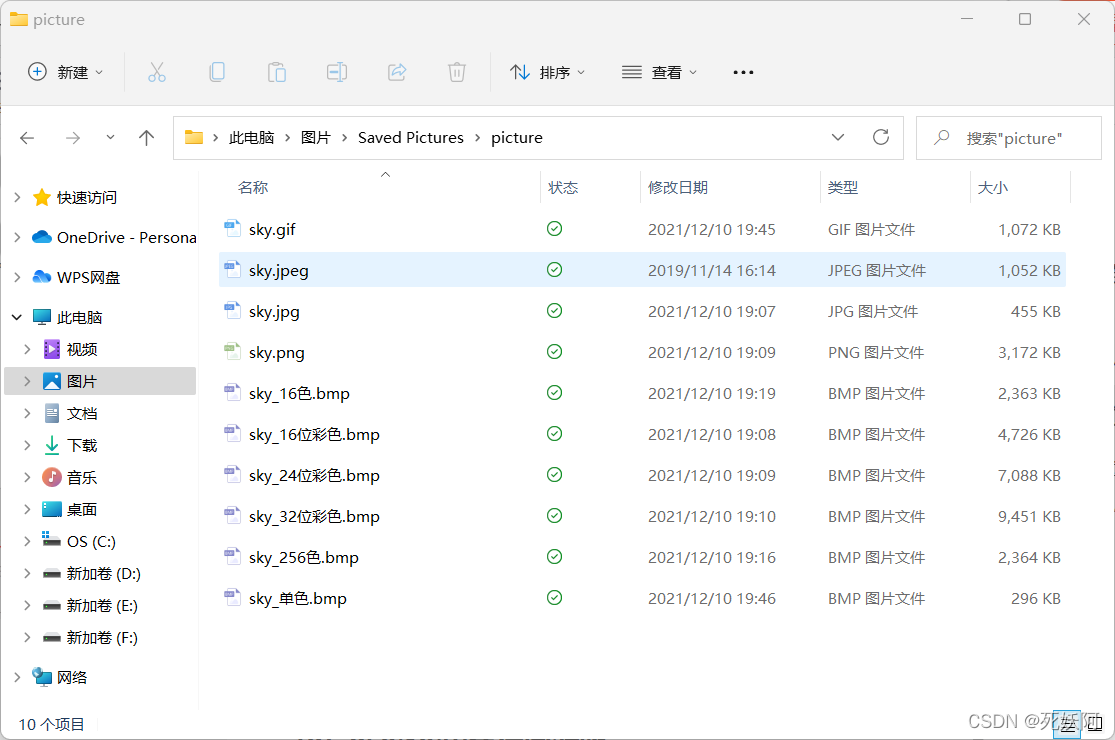
1.原图 sky.jpeg(2240*1080)
 2.原图信息
2.原图信息
(2)转换为位图
1.使用工具有Photoshop和电脑自带的画图工具或者IrfanView更改图片的色彩格式、位深度,将原图转化为以下图片,分别有32位、24位、16位彩色和256色、16色、单色的位图(BMP)文件,png,gif,jpg,bmp(前面的都是):
2.计算位图方式(以sky_24位彩色为例):2240108024/8/1024=7087.5KB/1024≈6.92MB,其他位图也可这样计算,宽度高度位深度/一个字节8个比特位/1024=多少KB
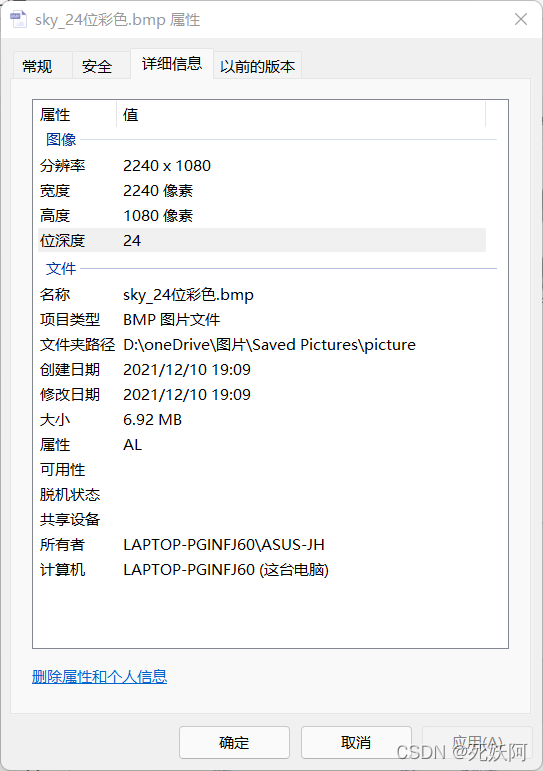
3.以sky_24位彩色为例,UltraEdit查看图片头文件信息如下
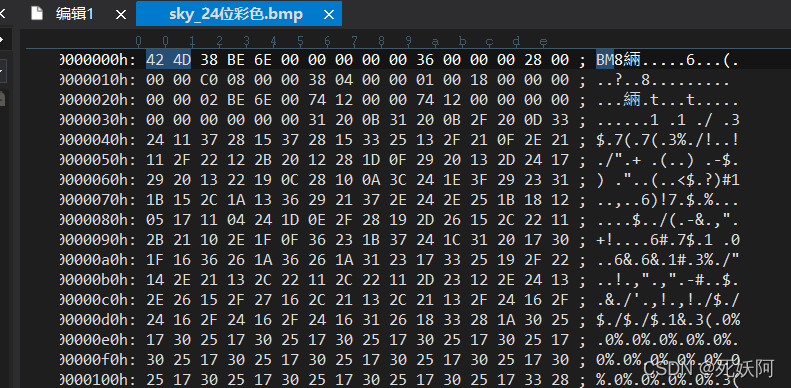
4.位图文件头分4部分,共14字节:
bfType 2字节 标识,就是“BM”二字 BM
bfSize 4字节 整个BMP文件的大小 0x000C0036(786486)【与右键查看图片属性里面的大小值一样】
bfReserved1/2 4字节 保留字,没用 0
bfOffBits 4字节 偏移数,即 位图文件头+位图信息头+调色板 的大小 0x36(54)
5.色彩格式和图片文件格式都在影响图片大小:
(3)压缩率
1.原图片是sky.jpeg大小为1052KB,而gif的大小为1072KB,jpg大小为455KB,png为3172KB,bmp(以sky_24位彩色为例)为7088KB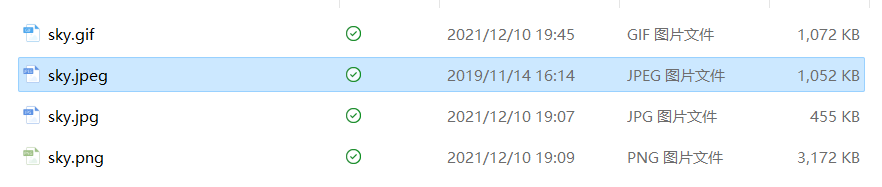
比较大小:
PNG压缩比:-301.5%
BMP压缩比:-673.8%
JPG压缩比:43.3%
GIF压缩比:101.9%
二、区分位图
(1)16/32位位图对照
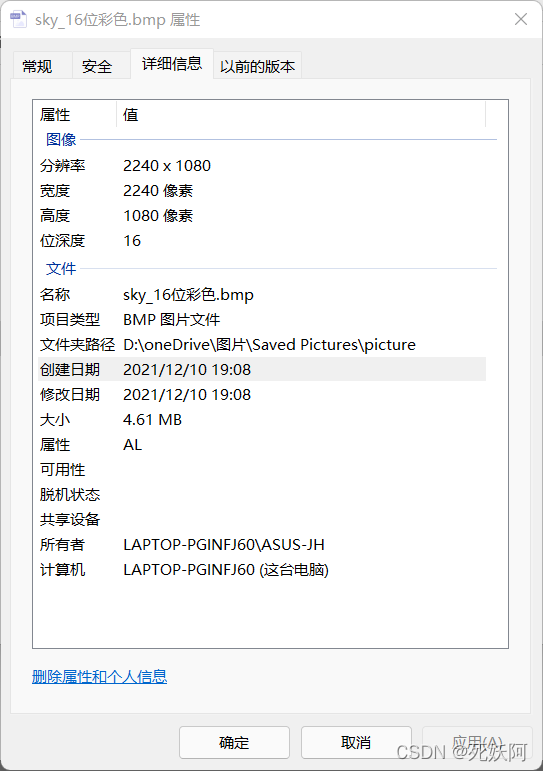
1.16位位图信息
2.32位位图信息
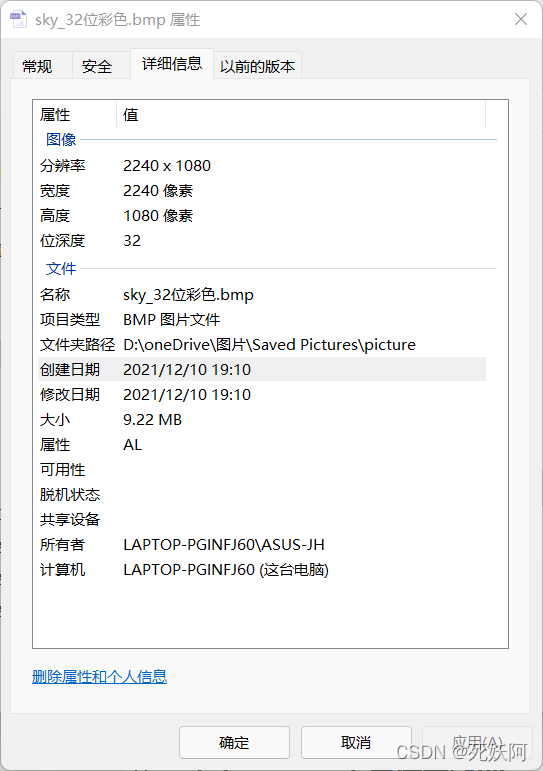
3.由上图可知4.61MB*2=9.22MB
16位位图所占存储空间大小比32位少,接近32位位图的一半,32位位图压缩了一半变成了16位位图
(2)256/16/单色位图对照
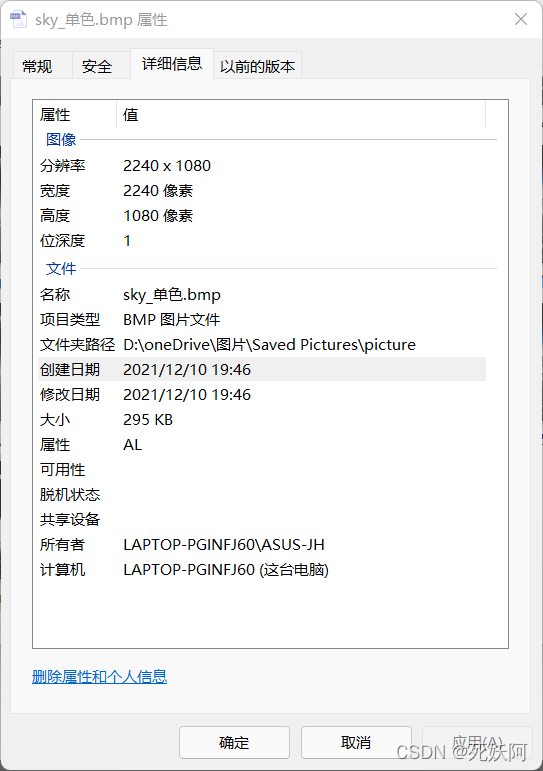
1.单色位图

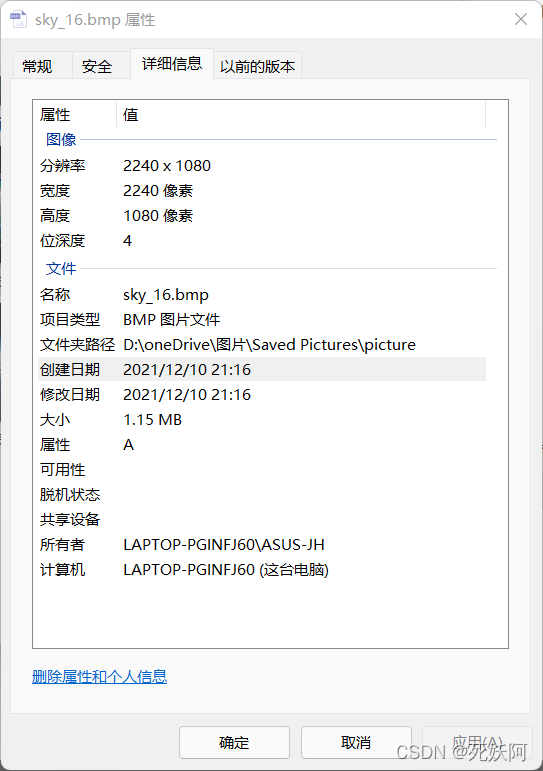
2.16色位图

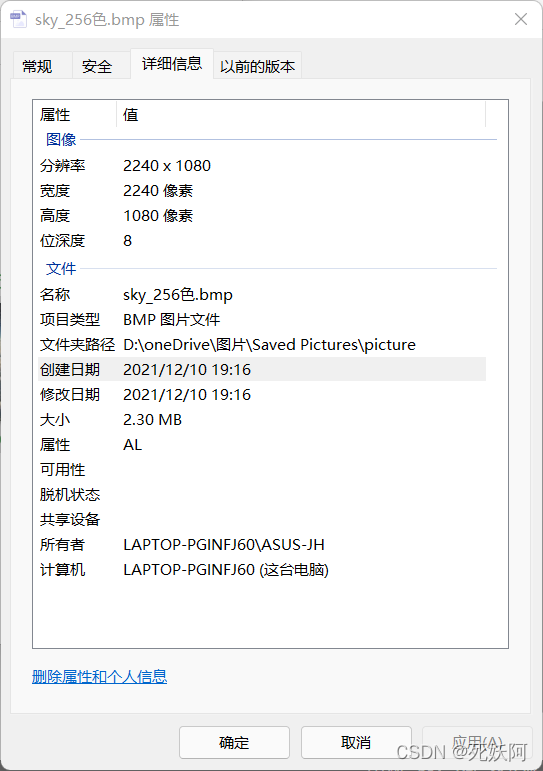
3.256色位图

4.三张图片的信息
单色:
16色:
256色:
可以清晰的发现颜色越多,图片越大
三、图片处理编程
(一)奇异函数分解(SDV)
1.代码
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib as mpl
from pprint import pprint
def restore1(sigma, u, v, K): # 奇异值、左特征向量、右特征向量
m = len(u)
n = len(v[0])
a = np.zeros((m, n))
for k in range(K):
uk = u[:, k].reshape(m, 1)
vk = v[k].reshape(1, n)
a += sigma[k] * np.dot(uk, vk)
a[a < 0] = 0
a[a > 255] = 255
# a = a.clip(0, 255)
return np.rint(a).astype('uint8')
def restore2(sigma, u, v, K): # 奇异值、左特征向量、右特征向量
m = len(u)
n = len(v[0])
a = np.zeros((m, n))
for k in range(K+1):
for i in range(m):
a[i] += sigma[k] * u[i][k] * v[k]
a[a < 0] = 0
a[a > 255] = 255
return np.rint(a).astype('uint8')
if __name__ == "__main__":
A = Image.open("./Lena.jpeg", 'r')
print(A)
output_path = r'./SVD_Output'
if not os.path.exists(output_path):
os.mkdir(output_path)
a = np.array(A)
print(a.shape)
K = 50
u_r, sigma_r, v_r = np.linalg.svd(a[:, :, 0])
u_g, sigma_g, v_g = np.linalg.svd(a[:, :, 1])
u_b, sigma_b, v_b = np.linalg.svd(a[:, :, 2])
plt.figure(figsize=(11, 9), facecolor='w')
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
for k in range(1, K+1):
print(k)
R = restore1(sigma_r, u_r, v_r, k)
G = restore1(sigma_g, u_g, v_g, k)
B = restore1(sigma_b, u_b, v_b, k)
I = np.stack((R, G, B), axis=2)
Image.fromarray(I).save('%s\\svd_%d.jpeg' % (output_path, k))
if k <= 50:
plt.subplot(10, 5, k)
plt.imshow(I)
plt.axis('off')
plt.title('奇异值个数:%d' % k)
plt.suptitle('SVD与图像分解', fontsize=20)
#plt.tight_layout(0.3, rect=(0, 0, 1, 0.92))
# plt.subplots_adjust(top=0.9)
plt.show()
2.运行结果

可以观察到,随着奇异值的增加图片变得越来越清晰。
(二)用图像的开闭运算(腐蚀-膨胀),检测出2个样本图像中硬币、细胞的个数
1.硬币代码
import cv2
import numpy as np
def stackImages(scale, imgArray):
"""
将多张图像压入同一个窗口显示
:param scale:float类型,输出图像显示百分比,控制缩放比例,0.5=图像分辨率缩小一半
:param imgArray:元组嵌套列表,需要排列的图像矩阵
:return:输出图像
"""
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]),
None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank] * rows
hor_con = [imageBlank] * rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None, scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor = np.hstack(imgArray)
ver = hor
return ver
#读取图片
src = cv2.imread("./coin.png")
img = src.copy()
#灰度
img_1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#二值化
ret, img_2 = cv2.threshold(img_1, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
#腐蚀(腐蚀主要为了把每个硬币区分开。过大会造成缺失,过低会无法区分开。参数可以自己设置以达到合适。)
kernel = np.ones((17, 17), int)
img_3 = cv2.erode(img_2, kernel, iterations=1)
#膨胀(膨胀到合适的值,这样每一个白色区域就是一个硬币。)
kernel = np.ones((3, 3), int)
img_4 = cv2.dilate(img_3, kernel, iterations=1)
#找到硬币中心
contours, hierarchy = cv2.findContours(img_4, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[-2:]
#标识硬币
cv2.drawContours(img, contours, -1, (0, 0, 255), 5)
#显示图片
cv2.putText(img, "count:{}".format(len(contours)), (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(src, "src", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_1, "gray", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_2, "thresh", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_3, "erode", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
cv2.putText(img_4, "dilate", (0, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 3)
imgStack = stackImages(1, ([src, img_1, img_2], [img_3, img_4, img]))
cv2.imshow("imgStack", imgStack)
cv2.waitKey(0)
2.结果
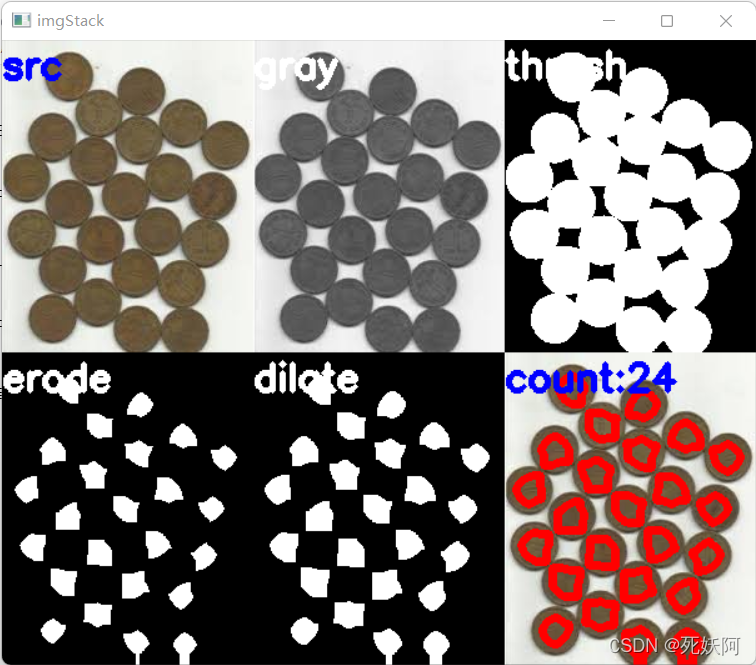
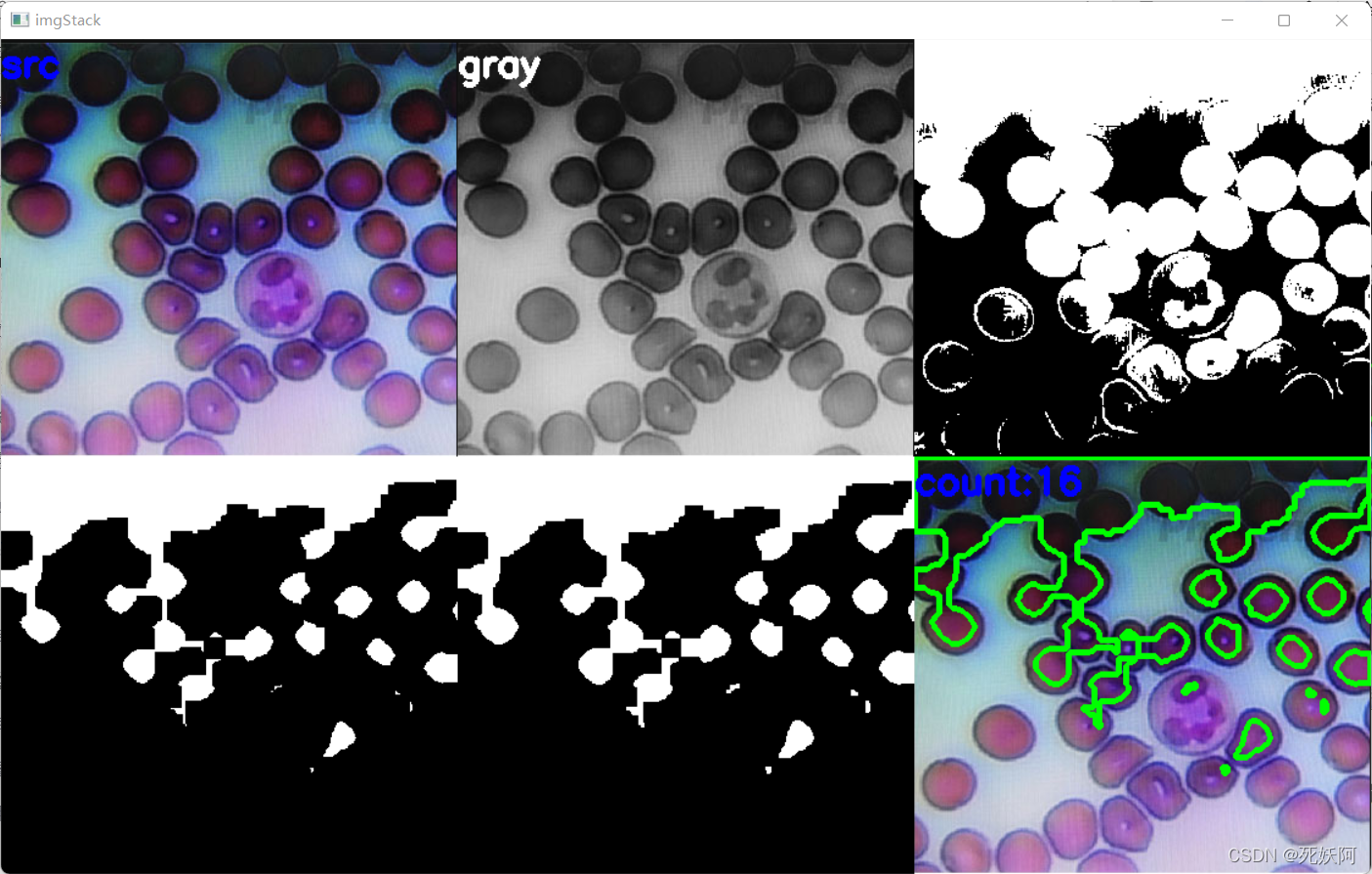
3.细胞代码
在这里插入代码片
4.结果
四、图片条形码定位
1.代码
import cv2
import pyzbar.pyzbar as pyzbar
import numpy
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
def decodeDisplay(img_path):
img_data = cv2.imread(img_path)
# 转为灰度图像
gray = cv2.cvtColor(img_data, cv2.COLOR_BGR2GRAY)
barcodes = pyzbar.decode(gray)
for barcode in barcodes:
# 提取条形码的边界框的位置
# 画出图像中条形码的边界框
(x, y, w, h) = barcode.rect
cv2.rectangle(img_data, (x, y), (x + w, y + h), (0, 255, 0), 5)
# 条形码数据为字节对象,所以如果我们想在输出图像上
# 画出来,就需要先将它转换成字符串
barcodeData = barcode.data.decode("utf-8")
barcodeType = barcode.type
#不能显示中文
# 绘出图像上条形码的数据和条形码类型
#text = "{} ({})".format(barcodeData, barcodeType)
#cv2.putText(imagex1, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX,5, (0, 0, 125), 2)
#更换为:
img_PIL = Image.fromarray(cv2.cvtColor(img_data, cv2.COLOR_BGR2RGB))
# 参数(字体,默认大小)
font = ImageFont.truetype('msyh.ttc', 150)
# 字体颜色(rgb)
fillColor = (0, 255, 255)
# 文字输出位置
position = (x, y-50)
# 输出内容
str = barcodeData
# 需要先把输出的中文字符转换成Unicode编码形式( str.decode("utf-8) )
draw = ImageDraw.Draw(img_PIL)
draw.text(position, str, font=font, fill=fillColor)
# 使用PIL中的save方法保存图片到本地
img_PIL.save('ma1.jpg', 'jpeg')
# 向终端打印条形码数据和条形码类型
print("扫描结果==》 类别: {0} 内容: {1}".format(barcodeType, barcodeData))
ma1 = mpimg.imread('ma1.jpg')
img = plt.imshow(ma1)
plt.axis('off') # 不显示坐标轴
plt.show()
if __name__ == '__main__':
decodeDisplay("ma.jpg")
2.原图

3.结果

五、总结
对位图有了更进一步的了解,对图像的编程处理也加强了学习,区分了位图的区别,图像颜色更多,图片更大,也知道了位图大小的计算。