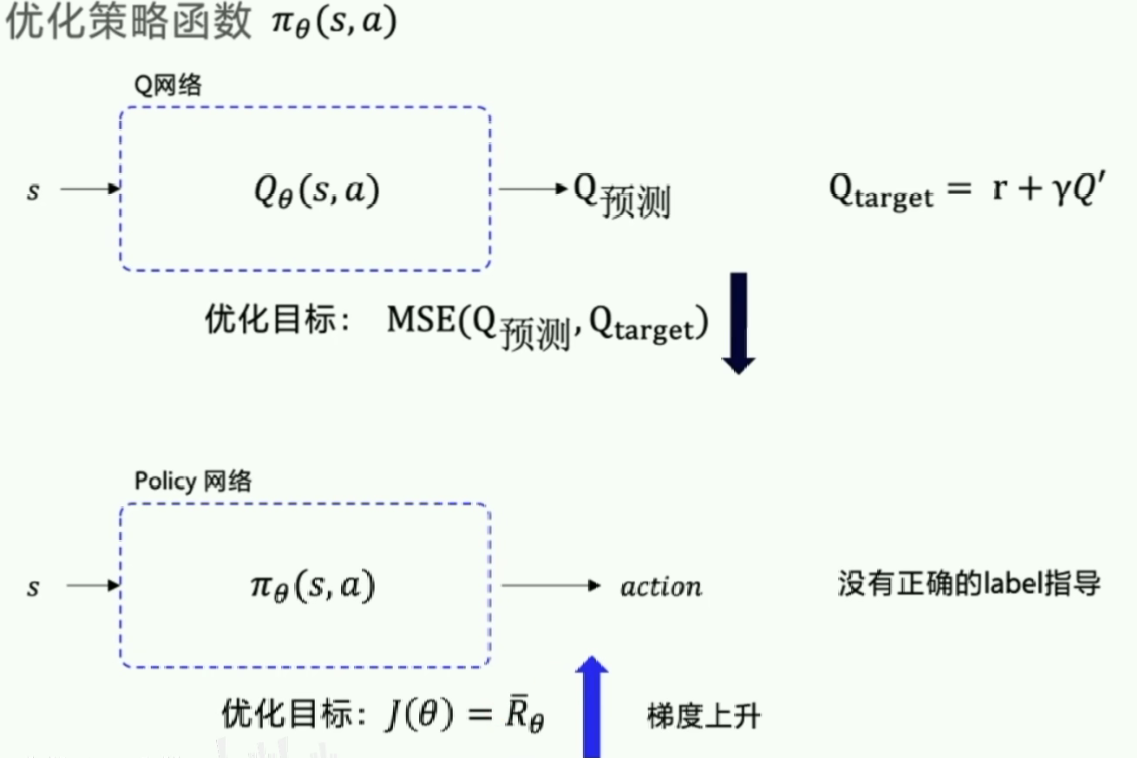
前文:深度强化学习 # Deep-Q-Network利用神经网络对Q value function作近似表示。局限性在于其只适用于action有限的情况(神经网络输出层的节点数显然不能是无限的)。
在前文有提到过NN的两种结构,如果是输入State和action来得到Q呢?这里输出只有一个。是不是可以解决连续情况?答案是否定的。(因为我们还需要对所有的action求一个max(Q),虽然此时NN可以build,但是计算max(Q)时的循环次数无限次,导致max(Q)的计算不可行,且这种做法效率极度低下。
那么我们考虑第三种出路:神经网络输入状态直接输出动作,这就是策略梯度的思想了。
Policy Gradients:不通过分析奖励值, 直接输出行为的方法。对比起以值为基础的方法, Policy Gradients 直接输出动作的最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 比如 Q-learning只能适用于action数量有限的情况。Policy Gradients可以结合神经网络。强化学习里面无标签,所以Policy Gradients没有误差,那要怎么进行神经网络的误差反向传递呢?(因此还是需要充分利用reward的信息)
Policy Gradients的核心思想: 观测的信息通过神经网络分析, 选出了左边的行为, 我们直接进行反向传递, 使之下次被选的可能性增加, 但是奖惩信息却告诉我们, 这次的行为是不好的, 那我们的动作可能性增加的幅度随之被减低. 假如这次的观测信息让神经网络选择了右边的行为, 右边的行为随之想要进行反向传递, 使右边的行为下次被多选一点, 这时, 奖惩信息也来了, 告诉我们这是好行为, 那我们就在这次反向传递的时候加大力度(好,请加大力度!~)。这样就能靠奖励来左右我们的神经网络反向传递。
Policy Gradients要输出的不是action对应的value而是action,这样就跳过了 value 这个阶段。最大的一个优势是: 输出的这个 action 可以是一个连续的值, 之前我们说到的 value-based 方法输出的都是不连续的值。


在PG中很多问题是分幕式(Episode)的。优化目标是让每个episode的总reward都尽可能大。


当N足够大时可以近似期望回报(采样)。
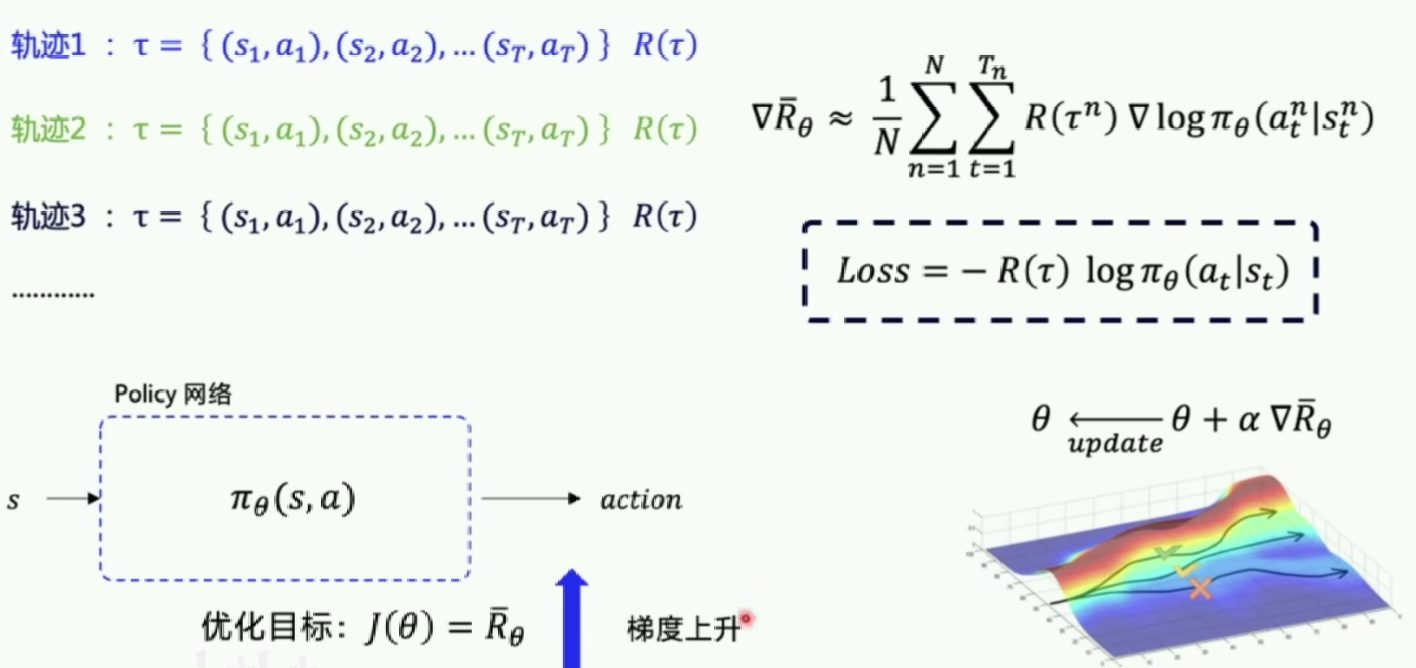
基于 整条回合数据 的更新
Policy gradient的第一个算法是一种基于 整条回合数据 的更新, 也叫 REINFORCE 方法。因为也是NN所以需要梯度下降。

重点:梯度下降里面,希望动作在下一次有机会更多出现,
v
t
v_t
vt?告诉我们这个更新方向是否正确,如果正确就更新幅度更大,否则更小。log形式的概率会有更好的收敛性。
?
θ
(
log
?
(
p
o
l
i
c
y
(
s
t
,
a
t
)
)
?
V
)
\nabla_{\theta}(\log(policy(s_t,a_t))*V)
?θ?(log(policy(st?,at?))?V)表示状态S对选择的动作a的吃惊度
代码:github
因为是基于回合的,所以会在回合中的每一次reward进行处理,让reward能更有导向性的引导policy gradient的方向。
如何处理整个回合的reward使得其能正确引导梯度下降的方向呢?

Reference
- https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/intro-PG/
- 《Policy Gradient Methods for Reinforcement Learning with Function Approximation》NIPS-1999
- paddlepaddle-强化学习