MASTERING ATARI WITH DISCRETE WORLD MODELS
主要提出了一种基于模型的强化学习,叫DreamerV2.
论文题目:mastering atari with discrete world models
论文项目地址及代码:https://danijar.com/project/dreamerv2/
没有偏差的报道:https://ai.googleblog.com/2021/02/mastering-atari-with-discrete-world.html
Intro-Model based RL:Model+RL
什么强化学习?什么是基于模型的强化学习?
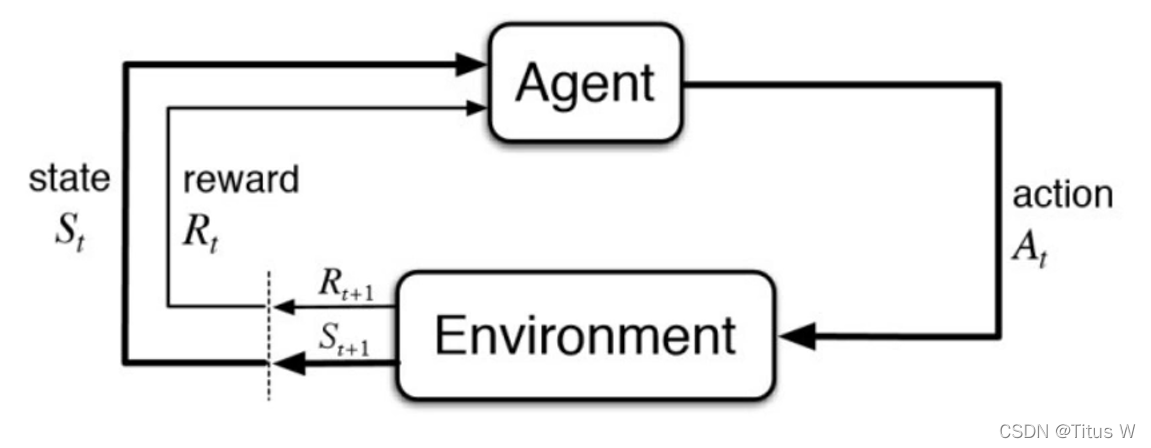
Agent就是机器或者机器人或者是任何一个Policy策略都可以,首先Agent会先观察周围的环境,环境会在每一个时刻返回给Agent一个state状态,Agent会根据Policy来做出相应的动作action来影响环境。随着动作的输入,环境会给出相应的reward奖励,目的就是使Agent在环境中获得尽可能多的奖励。
环境不仅会给Agent提供状态,也要提供奖励。
但是这种经典的强化学习发现,在不断训练和学习的过程中,Agent需要通过action和reward不断地和环境交互,但是在实际部署过程中,往往不一定会有这样的条件,比如操作一个机器手,机器手本身是有损耗的,等等。所以此时就要引入基于模型的强化学习。
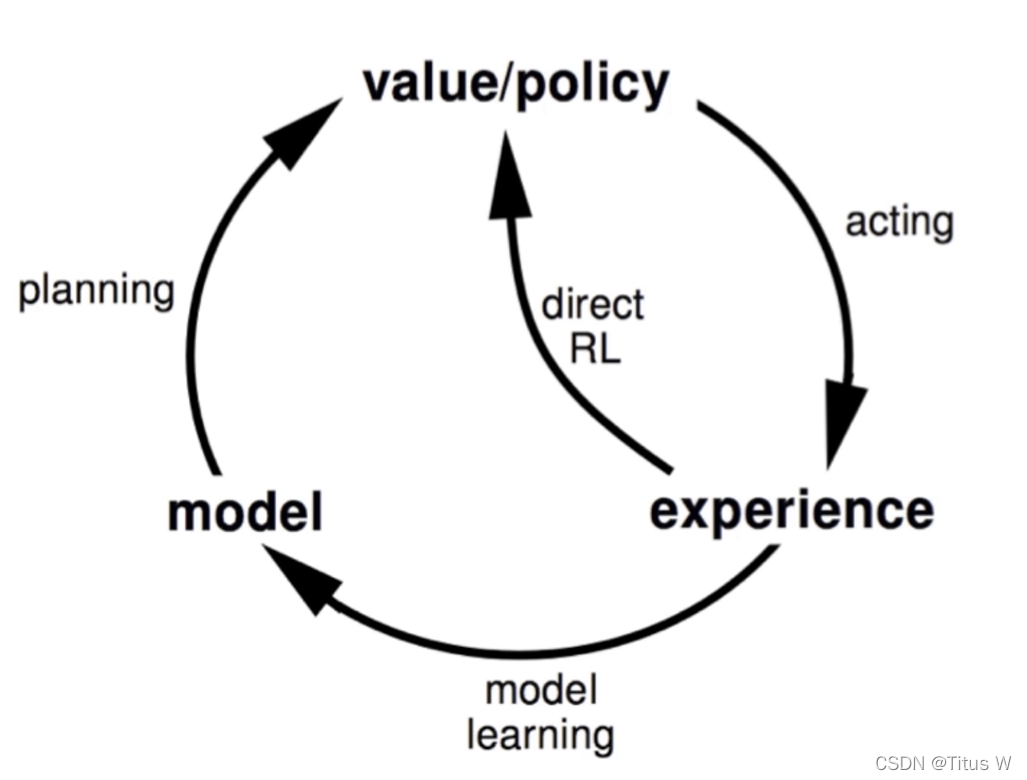
平时训练Policy的同时,我们也在训练一个model,这个模型model的作用是用来描述当前所在环境的一些动力学特征的演化规则,客观规则,如果模型能够学习到相关规则,就可以自己运行一个模拟器,来模拟外界环境,这样就避免了机器人真正到了危险环境而导致的交互不足。这样就可以在模拟的环境中不断更新迭代学习获得更好的表现。
所以在model学习的过程就叫做dreamer。
Intro
这篇文章就是第一个实现model-based的方法,比起没有model的方法,dreamer的方法还要好!而且远高于之前的基于模型的强化学习。像Rainbow就是DQN的集大成者。model-free是没有基于模型的强化学习。灰色的线就是人类玩家平均的表现。
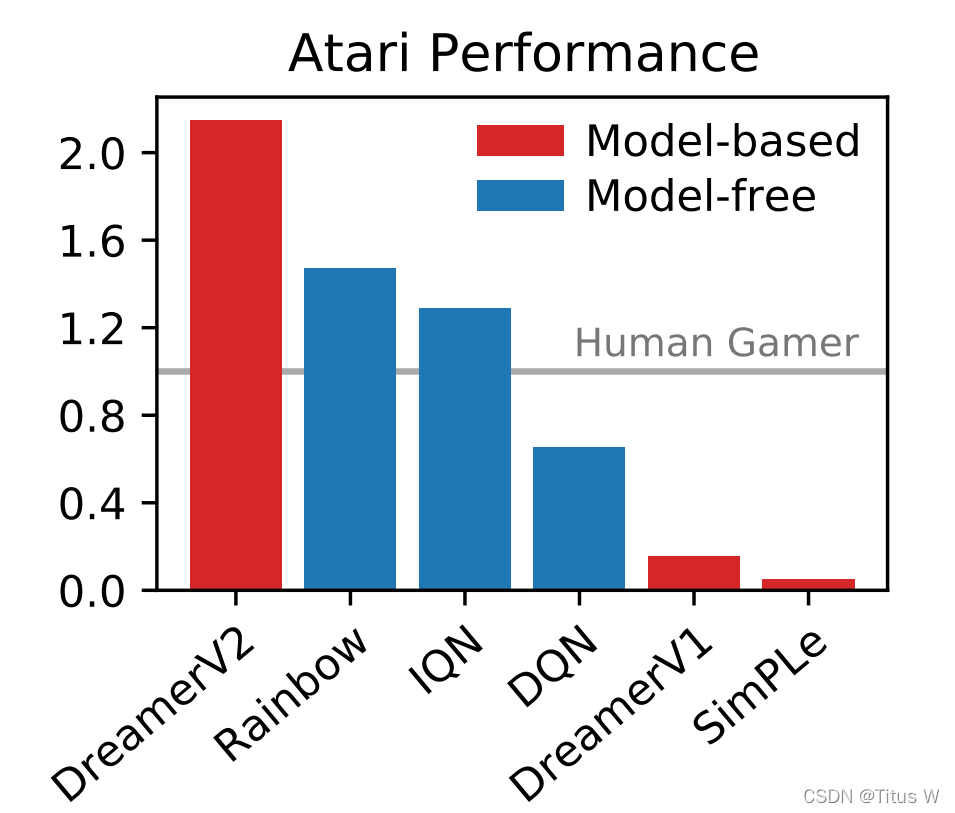
最关键的地方就是模型所预测出来的环境一定要和真实环境相对应。基于模型的意思就是,基于模型所预测出来的环境的问题。

对游戏环境所观察学习并预测出来的环境和原始真正环境几乎一模一样。
World model
论文的亮点,就是他们如何实现world model来构建model based?作者是怎么样构建模型来描述游戏世界呢?
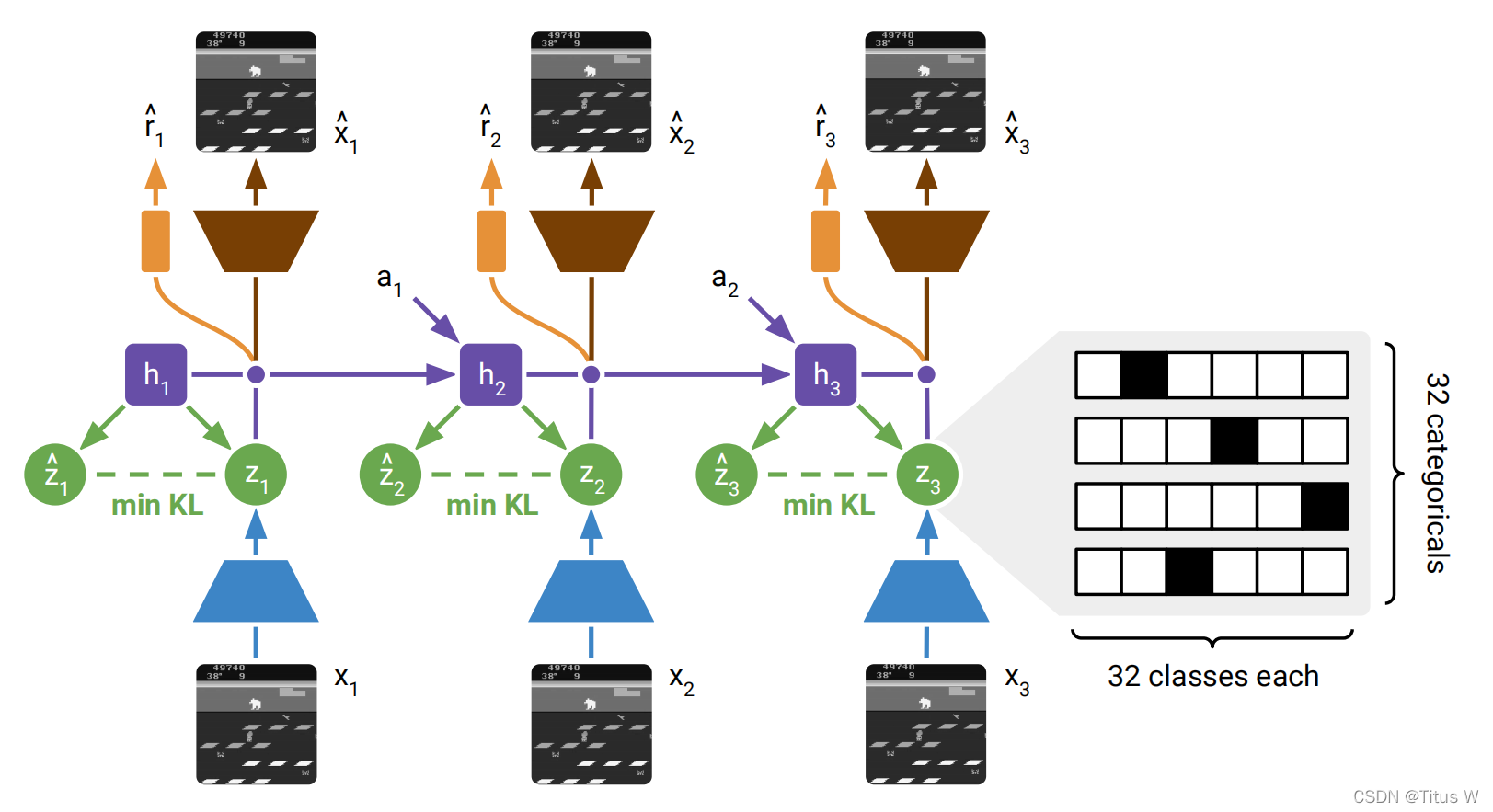
如上图,作者选取了视频序列来作为模型的输入,对于每一帧来讲,使用一个卷积神经网络下采样来描述这一帧的内容,Z1就是X1图像的内容,同时模型的内部会维持一个隐含状态h1.通过结合h1和z1,就可以是模型重构出X1这个图像。
于此同时,结合h1和Z1,还有用户的输入a1,我们可以预测出在下一时刻模型内部的隐藏状态h2,并且根据h2导出在下一时刻图像的描述子Z2的预测Z2hat(实际运行中,除了X1的图像都是不可用的),以此类推,我们就可以继续预测h3和Z3hat。
那么怎么去训练模型呢?
1.对比X1hat和X1就能构建重构损失
2.同时对于每个隐藏状态h,我们都在预测下一幅图像的Zhat,因此通过对比Zhat和Z,也可以获得一种约束。
3.同时h1,Z1,a1可以得到X2hat,所以X2hat和X2又能构成一种约束。
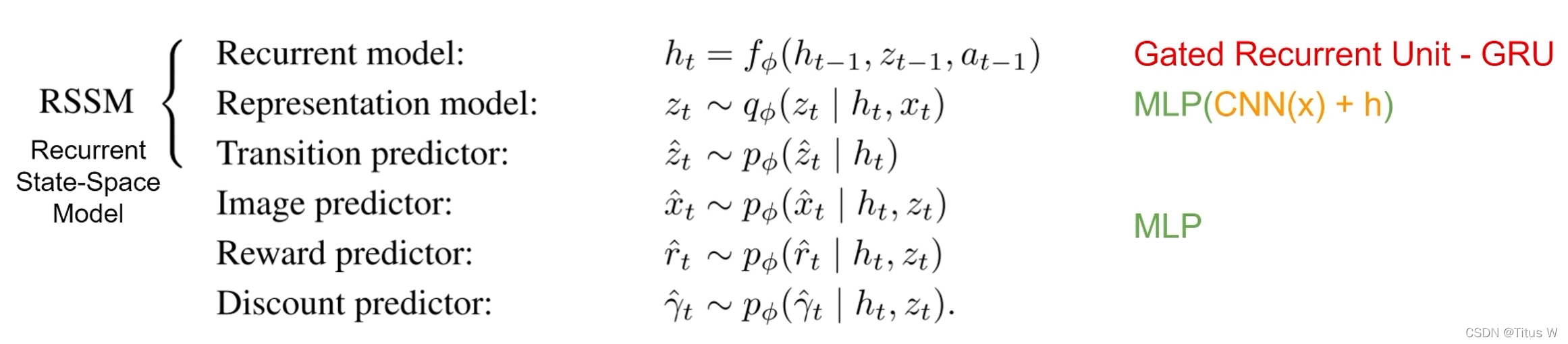
在整个world model中存在6个部分:两幅图对比着看很容易理解。
Recurrent model:维持维护隐藏状态h的模型,用的GRU。
Representation model:需要三个输入,x传入卷积再加上h送入多层全连接层
Transition predictor:通过h来预测Zhat
Image predictor:重构回图像
Reward predictor:预测环境中给予Agent的奖励
Discount predictor:预测环境中给予Agent的奖励
Main contributions论文最重要的两点贡献
1.learning a categorical latent space
一般的论文都使用连续变量来描述系统的状态也叫隐含空间,而这篇文章提出了一连串离散的变量来描述系统的状态。
2.using KL balancing
KL本身就不是对称的,作者通过调整KL的权重来实现模型的泛化。

整个模型使用Zt和ht两个变量,来一起来描述。其中Zt是一个随机的状态,因为Zt在概率分布中随机采样产生,而ht是确定的,根据第一个公式,ht就是由recurrent model产生的。这两个变量就决定的了当前系统的状态。
通过离散的变量表达整个模型的状态,以及为什么这样做是合理的?
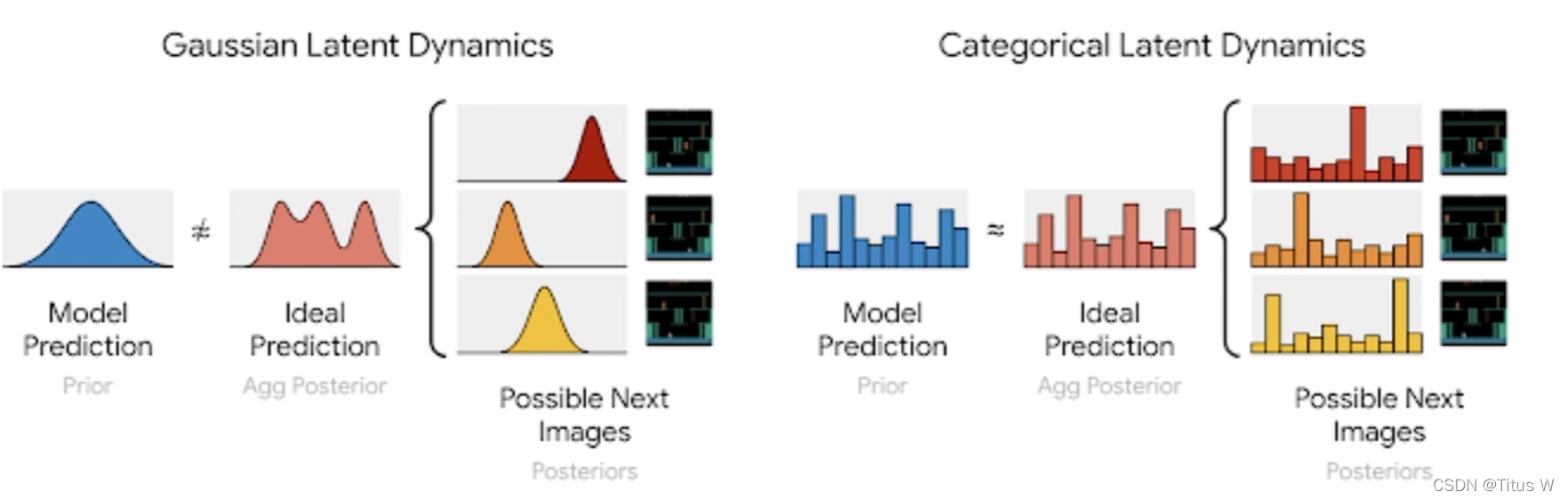
如左图,加入我们使用原来的随机变量,我们其实是默认未来的图像都是符合高斯分布的。那么未来所有图像的高斯分布呢,叠在一起可能会形成粉色的Ideal Prediction这样的,很显然这个分布根本不是高斯分布,但是我们实际的模型(蓝色的Model Prediction)用高斯分布尝试拟合粉色的模型,肯定很难达到一个满意的拟合效果。相反如果我们全部使用稀疏离散的变量来描述图像的状态,把这些分布结合在一起不管怎么样都能获得一个离散的状态空间。
某种程度上讲,使用离散变量之后,我们模型的自由度反而变高了,可以更加准确的拟合模型的概率分布,那么这就是作者为什么认为离散的表达是一个好的表达。
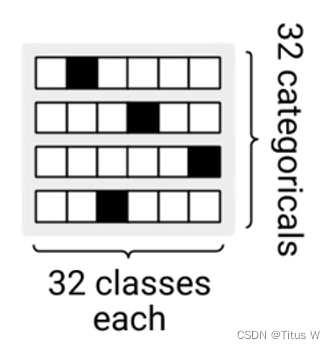
那么在实际的操作中呢,作者使用了32个变量,每个变量又会拥有32个种类,也就是会有32*32种可能性用来描述整个状态空间。并且使用了稀疏编码,黑色地方是1其他都是0,也即one-hot-encoding这样的策略。但是我们用离散状态表达又会带来一个问题,就是当梯度传递的时候,梯度是无法翻过离散变量的,那么如何解决这样的问题呢?
Straight-Through Gradients (第一个贡献)

如上图所示,第一行:上游的模型输出一个概率分布之后首先进行一个采样,最后得到一个离散的sample。
第二行:同时使用softmax对概率分布进行一个处理,传递一个softmax过后的一个概率分布。
第三行:通过这样的操作之后呢,既可以保留原来sample的数值,同时也把gradient导数通过softmax的形式传递过来了。
这就是作者如何训练出离散的状态空间表达。
KL Balancing(第二个贡献)

回到模型架构图看到,作者通过h来预测Z1hat,同时Z1是由一个卷积神经网络从实际的图像X1提取出来的。此时需要设想一种情况,不管输入图像X1是什么,卷积实际网络都会输出一个相同的或者很像的Z1作为真实值(ground truth)。那么对于h1来讲预测未来非常简单,因为所有的Z1.Z2…几乎都一样,预测器h1其实每次预测出来的值Z1hat都是相同的就可以了,这样看来Z1,Z2…的变化是不足以反应出X1,X2之间的不同的,导致了模型坍塌。一旦导致模型坍塌的话,就不能重建会之前的图像,不能精确的重构损失,更别说预测未来的图像了。尤其是当一起训练大模型,模型坍塌的问题会经常出现。
所以作者这里使用了两个KL divergence加权,使prior更加倾向于posterior,也就是我们在训练这个模型的时候,这个Z1hat更加接近Z1,而不是在Z1hat和Z1之间找一个相互靠近的点,而是强制把Z1hat向Z1靠拢。这样就能使transition predictor能够真正学到对未来的预测。
Policy learning
Actor-Critic & Learn from latent space
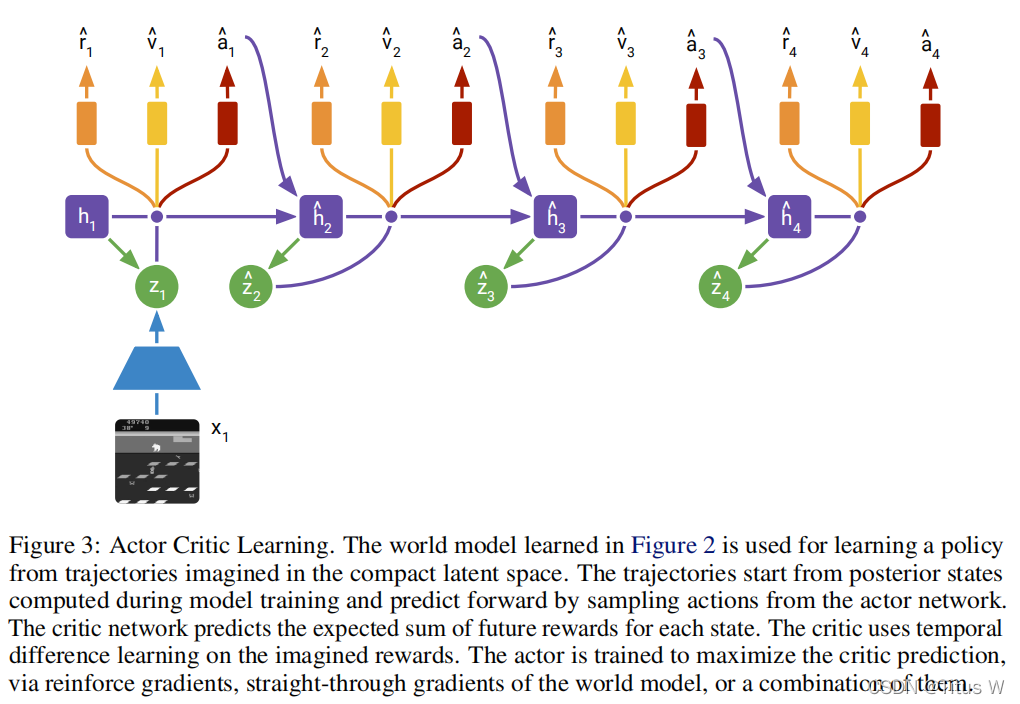
作者使用了经典的Actor-Critic结构。Actor网络用来产生真正的policy,产生真正的action,并用Critic来评判action是否是一个好的action。事实上像GAN一样。这两个网络是不断在对抗中进步的。而且因为在前面的world model网络中已经提取出latent represention。也就是Actor-Critic不需要再从低信息密度中提取信息,他们是可以直接从latent space也就是我们之前讲的Zt和ht这两个表达直接学习出自己的policy,减少了参数量,进一步提高了效率。
同时作者也尝试在训练actor的过程中,使用straight-through gradients,和最开始经典的reinforce gradients的一同训练这个模型。
训练中使用真实环境训练word model随后只使用world model训练policy而且因为使用letent representation不需要world model重建图像,训练效率更高。
Results
实验结果和玻璃实验.
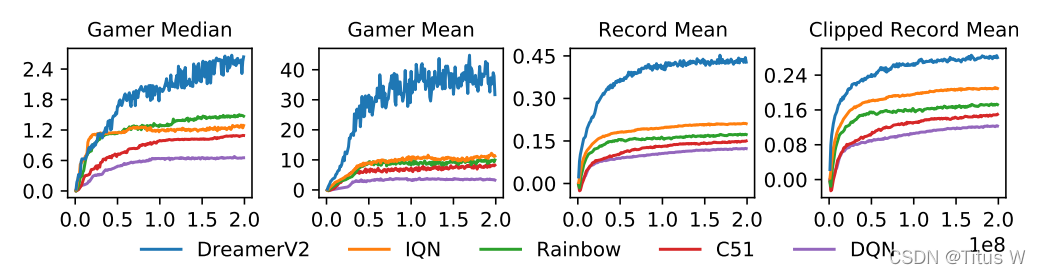
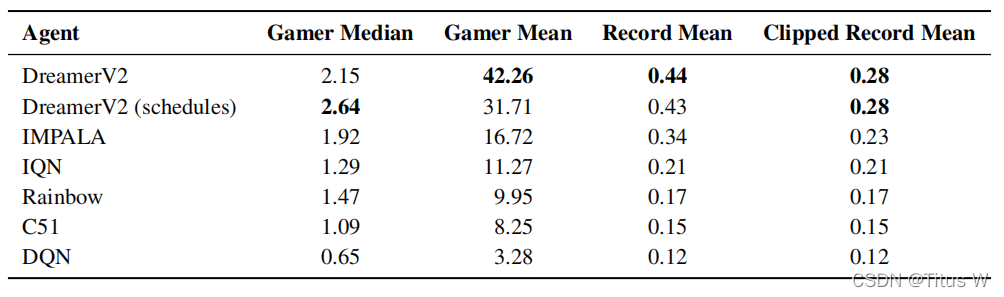
如图,在横轴上表示训练的次数,纵轴是Agent所取得的累计的奖励。前两辐图是各种任务人类玩家的中位数 和平均数的表现,后面两幅图相当于世界记录人类玩家的表现。可以看出来DreamerV2相对比一般的人类玩家有着不错的水平,但是相对比世界记录玩家还是有一些差距。
ablation study
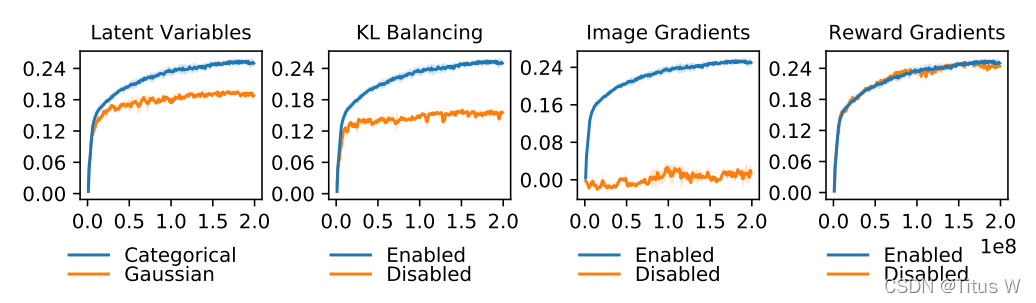
接下来看作者所做的玻璃实验来验证本文提出的两个方法确实能够改进和改善增强学习的效果。
第一幅图,作者使用离散的随机变量对比传统连续的高斯模型的状态变量。
第二幅图,启用KL Banlancing和不用时性能的对比。
第三幅图比较有意思,作者有没有使用Image Gradients,也就是重构的损失,也就是模型根据latent represention来复原出图像和时间的图像对比。明显重构损失非常有用,如果没有重构损失基本上学不到什么东西。说明该模型确实从图像中学到了信息,而不是从辅助的其他信息如奖励等学到了东西。
第四幅图,是否使用奖励,好像确实没有什么区别。

作者也尝试了一些其他东西,但是没有获得什么效果,比如二进制隐表示,更长期的熵,是否需要定期更改学习率这些超参数,但是都没什么效果。
Conclusion

作者通过实验证明离散变量加KL平衡两种策略,可以有效地且大幅度改进强化学习中Agent的性能。