0.介绍项目目标
- 项目是基于东南亚小语种迁移学习所需要的数据集爬取任务,而目标选择定为小语种文献期刊双语标题和双语摘要进行对齐学习。
- 第一步先研究泰文数据集,目标文献期刊网站为:http://cuir.car.chula.ac.th/simple-search?query=

 - 目标就是爬取这些信息,对每一条论文记录,框起来的那些都是要爬取的(泰语标题、英语标题、泰语摘要、英语摘要、学位类型),生成一个tsv文件,列名包括序号、泰语标题、英语标题、泰语摘要、英语摘要、学位类型
1.网站分析
1.1 寻找文档的uri规律
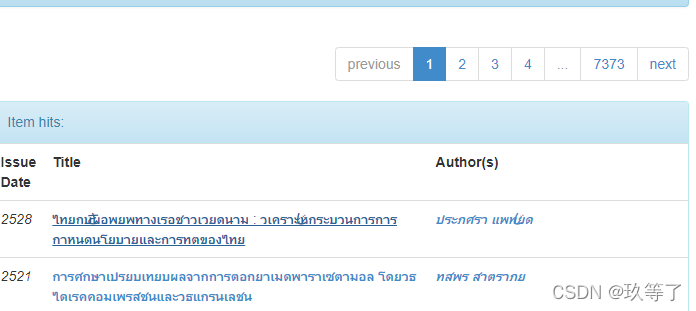
- 这是所有的文献集合,我们先随便选取一篇,发现地址栏十分复杂
# ps:【】表示连接的区别
# 第一篇文档
http://cuir.car.chula.ac.th/handle/123456789/
72181?
src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%26rpp
%3D10%26etal%3D0%26start%3D0%26brw_total%3D64845%26brw_pos%
3D0&query=
# 第二篇文档
http://cuir.car.chula.ac.th/handle/123456789/
71235?
src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%26rpp%
3D10%26etal%3D0%26start%3D0%26brw_total%3D64845%26brw_pos%
3D1&query=
# 第三篇文档
http://cuir.car.chula.ac.th/handle/123456789/
71233?
src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%
26rpp%3D10%26etal%3D0%26start%3D0%26brw_total%3D64845%26brw_pos%
3D2&query=
# 最后一篇文档
http://cuir.car.chula.ac.th/handle/123456789/
27447?src=%2Fsimple-search%3Fquery%3D%26filter_field_1%3Dtype%26filter_type_1%3Dequals%
26filter_value_1%3DThesis%26sort_by%3Ddc.date.issued_dt%26order%3Ddesc%
26rpp%3D10%26etal%3D0%26start%3D64840%26brw_total%3D64845%26brw_pos%
3D64844&query=
# 但是经过多篇比对,我们发现每一篇文献的不同之处在于这两个地方:
http://cuir.car.chula.ac.th/handle/123456789/【72181】?
src=%2Fsimple-search%3Fquery%3D%26brw_total%3D73726%
26brw_pos%3D【0】&query=
# 而其他地方是一样的,这是否就是规律呢?先不着急下定论,
# 因为这个页面有一个return to list,我怀疑这是一个展示页而不是论文真正存放的物理路径。
- 我们往下看,发现一个叫做uri的属性
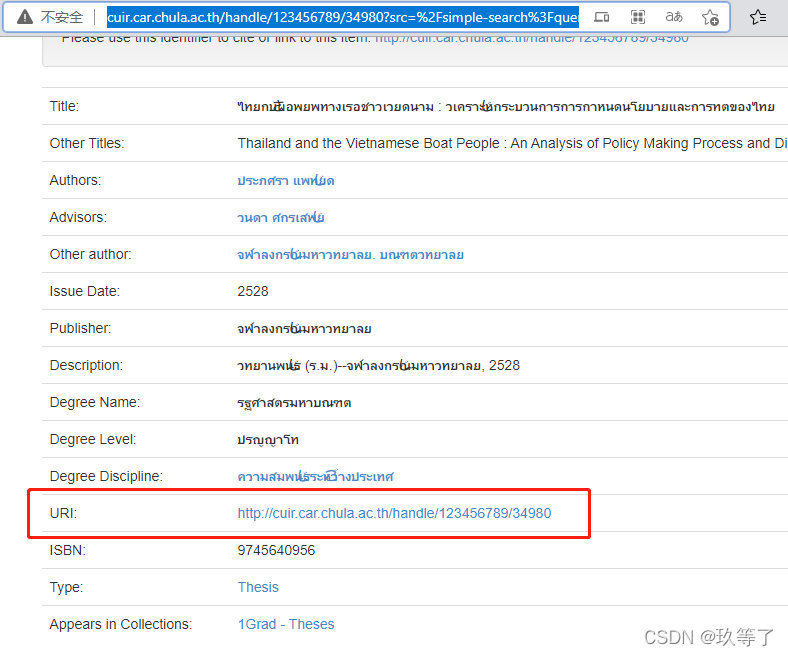 - 点击之后进入的居然是相同的页面,并且地址栏已经被改动
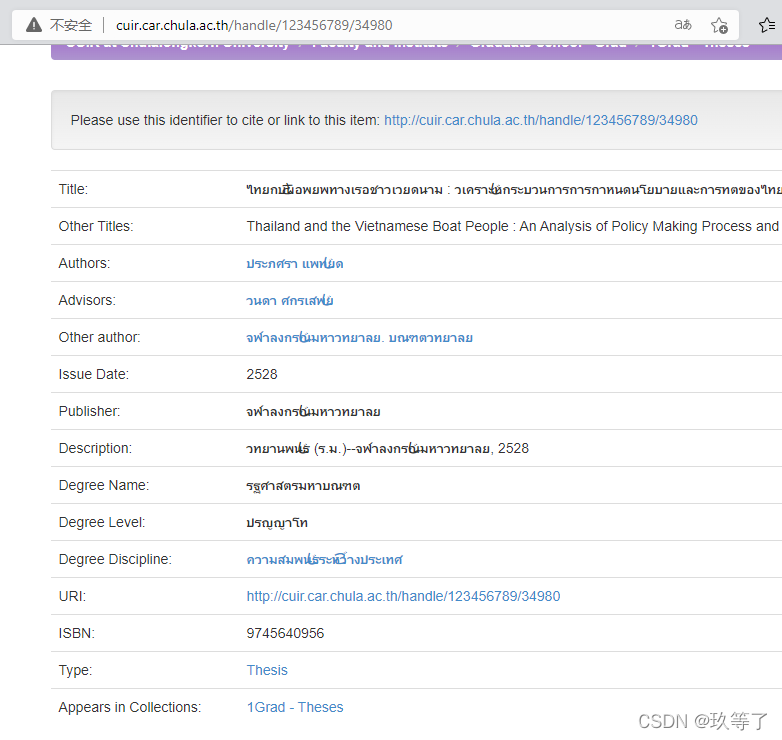 - 这个地址栏的规律不比刚刚那个好找?
第一篇:http://cuir.car.chula.ac.th/handle/123456789/72181
第二篇:http://cuir.car.chula.ac.th/handle/123456789/71235
第三篇:http://cuir.car.chula.ac.th/handle/123456789/71233
第四篇:http://cuir.car.chula.ac.th/handle/123456789/73078
第五篇:http://cuir.car.chula.ac.th/handle/123456789/69502
第六篇:http://cuir.car.chula.ac.th/handle/123456789/71254
第20篇:http://cuir.car.chula.ac.th/handle/123456789/77274
第60篇:http://cuir.car.chula.ac.th/handle/123456789/75905
最后一篇:http://cuir.car.chula.ac.th/handle/123456789/27447
检测:
http://cuir.car.chula.ac.th/handle/123456789/55
http://cuir.car.chula.ac.th/handle/123456789/77960
# 从55开始一直到77960都存在文献
- 通过二分法缩短范围,我们发现只有55-77960才有文献【截止至2021.12.10】
- 但是这个规律已经很好用了,只需要给一个循环就行。
1.2 寻找html规律
- 我们对该页面打开f12查看元素
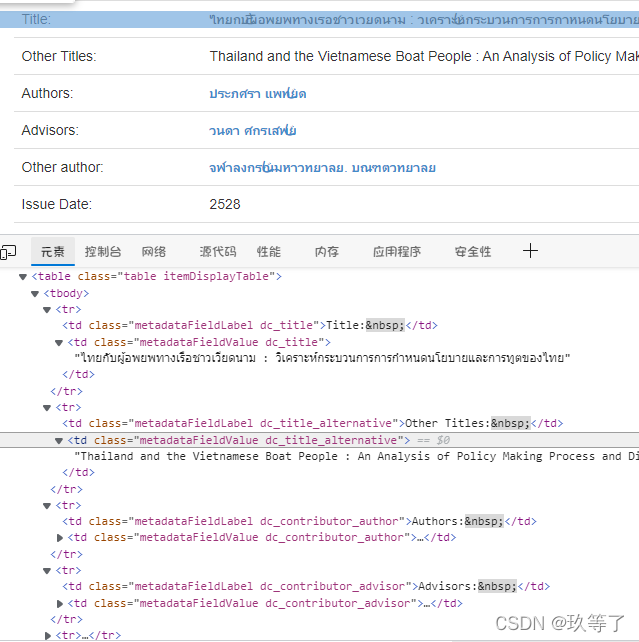 - 不难发现,这个网站很容易爬取,内容都显示在td里,使用beautifulsoup的find方法:soup.find(class_=“metadataFieldValue dc_title”).string 就可以定位到这个字符串了。关于beautifulsoup的使用,自行学习。下面代码我会提供注释。
- 理论成立,开始写代码
2.爬取操作
2.1 多线程实现访问和爬取
- 要注意,这里一共有7w+的uri,我们需要的是一次一次地去访问,效率太低,我们要充分利用cpu多核的优势去实现多线程,当然不要分太多线程,过多的线程如果cpu承载不了也是会降低效率,因为还是需要排队获取cpu时间片。我们采用稳妥一点的三线程。
- 下面直接提供代码,跟着代码注释从上往下看。
import requests
import sys
import io
import threading
from bs4 import BeautifulSoup
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
class thread1(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
processDocument(55,26023,1)
print ("退出线程:" + self.name)
class thread2(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
processDocument(26023,51991,2)
print ("退出线程:" + self.name)
class thread3(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
processDocument(51991,77961,3)
print ("退出线程:" + self.name)
def processDocument(num1,num2,thread_no):
for serial_num in range(num1,num2):
fail_count = 0
success_count = 0
document_URL = 'http://cuir.car.chula.ac.th/handle/123456789/'+str(serial_num)
try:
response = requests.get(document_URL, timeout=2)
status = response.status_code
if status == 200:
success_count += 1
with open("uri"+str(thread_no)+".txt","a") as file:
file.write(document_URL+"\n")
except:
fail_count += 1
print(success_count)
thread_1 = thread1(1, "Thread-1", 1)
thread_2 = thread2(2, "Thread-2", 2)
thread_3 = thread3(3, "Thread-3", 3)
thread_1.start()
thread_2.start()
thread_3.start()
- 爬取好后差不多长这样,当然我们需要的不是这些uri,而是uri对应的内容,这里只是简单查看一下结果,所以爬取一会儿就可以停止了。
2.2 html 处理
- 我们使用beautifulsoup模块,请自行学习。pip下载该模块后可以直接导入和使用。
def processDocument(num1,num2,thread_no):
for serial_num in range(num1,num2):
fail_count = 0
success_count = 0
document_URL = 'http://cuir.car.chula.ac.th/handle/123456789/'+str(serial_num)
try:
response = requests.get(document_URL, timeout=2)
status = response.status_code
if status == 200:
success_count += 1
processSoup('数据集1.tsv',response.text)
except:
fail_count += 1
print(success_count)
def processSoup(filename,html_text):
soup = BeautifulSoup(html_text,'lxml')
title = soup.find('td',class_='metadataFieldValue dc_title').string
other_title = soup.find('td',class_='metadataFieldValue dc_title_alternative').string
abstract = soup.find('td',class_='metadataFieldValue dc_description_abstract').string
other_abstract = soup.find('td',class_='metadataFieldValue dc_description_abstractalternative').string
degree_discipline = soup.find('td',class_='metadataFieldValue dc_degree_discipline').a.string
thai_title = title
en_title = other_title
thai_abstract = abstract
en_abstract = other_abstract
for i in range(10):
index = random.randint(1,20)
if(thai_title[index] == ',' or thai_title[index] == ' ' or thai_title[index] == '.' or thai_title[index] == '(' or thai_title[index] == ')' or thai_title[index] == '?' or thai_title[index] == '!'):
continue
else:
if(ord(title[1])>=65 and ord(title[1])<=122):
thai_title = other_title
en_title = title
thai_abstract = other_abstract
en_abstract = abstract
break
with open(filename,'a',encoding='utf-8') as file:
file.write(thai_title+",")
file.write(en_title+",")
file.write(thai_abstract+",")
file.write(en_abstract+",")
file.write(degree_discipline+"\n")
return
2.3 tsv转换
- 因为我们目标是一个tsv文件,也就是分隔符是tab键。我们选择使用python自带的csv包进行改写
with open(filename,'a',encoding='utf-8',newline='') as file:
tsv_w = csv.writer(file,delimiter='\t')
tsv_w.writerow([thai_title,en_title,thai_abstract,en_abstract,degree_discipline])
3.完整代码
import requests
import sys
import io
import threading
from bs4 import BeautifulSoup
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
class thread1(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
processDocument(55,26023,1)
print ("退出线程:" + self.name)
class thread2(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
processDocument(26023,51991,2)
print ("退出线程:" + self.name)
class thread3(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
processDocument(51991,77961,3)
print ("退出线程:" + self.name)
def processDocument(num1,num2,thread_no):
for serial_num in range(num1,num2):
fail_count = 0
success_count = 0
document_URL = 'http://cuir.car.chula.ac.th/handle/123456789/'+str(serial_num)
try:
response = requests.get(document_URL, timeout=2)
status = response.status_code
if status == 200:
success_count += 1
processSoup('数据集'+thread_no+'.tsv',response.text)
except:
fail_count += 1
print(success_count)
def processSoup(filename,html_text):
soup = BeautifulSoup(html_text,'lxml')
title = soup.find('td',class_='metadataFieldValue dc_title').string
other_title = soup.find('td',class_='metadataFieldValue dc_title_alternative').string
abstract = soup.find('td',class_='metadataFieldValue dc_description_abstract').string
other_abstract = soup.find('td',class_='metadataFieldValue dc_description_abstractalternative').string
degree_discipline = soup.find('td',class_='metadataFieldValue dc_degree_discipline').a.string
thai_title = title
en_title = other_title
thai_abstract = abstract
en_abstract = other_abstract
for i in range(10):
index = random.randint(1,20)
if(thai_title[index] == ',' or thai_title[index] == ' ' or thai_title[index] == '.' or thai_title[index] == '(' or thai_title[index] == ')' or thai_title[index] == '?' or thai_title[index] == '!'):
continue
else:
if(ord(title[1])>=65 and ord(title[1])<=122):
thai_title = other_title
en_title = title
thai_abstract = other_abstract
en_abstract = abstract
break
with open(filename,'a',encoding='utf-8',newline='') as file:
tsv_w = csv.writer(file,delimiter='\t')
tsv_w.writerow([thai_title,en_title,thai_abstract,en_abstract,degree_discipline])
return
thread_1 = thread1(1, "Thread-1", 1)
thread_2 = thread2(2, "Thread-2", 2)
thread_3 = thread3(3, "Thread-3", 3)
thread_1.start()
thread_2.start()
thread_3.start()
4.结果展示

- 一共会有三个这样的文件,直接首尾拼接就可以作为迁移学习的一个对齐数据集了
|