Ŀ¼
����Ŀ¼
hi!�ֵ�ÿ�ܷ�����ʱ����,ϣ��������ү�������ջ�ѽ!!!!!!!!!!!!!!
������Ҫ����ҽ�����ƪ�йضԱ�ѧϰ�����ġ�
�Ա�ѧϰ�����ķ�������Ȼ�����б��ܹ�ע����ʹ�óɶԵ�ѵ��������ǿΪ�������õı�ʾ�����ı�����������������Ȼ��,��NLP������,ͨ���Ա�ѧϰ����ѧϰ��Ҫ���ѵöࡣ֮ǰ�Ĺ��������ʼ��仯���γɶԱȶ�,��С�ı任���ܻᵼ�¾��Ӻ���������仯��
һ��Simple Contrastive Representation Adversarial Learning for NLP Tasks

���ĵ�ַ:https://arxiv.org/pdf/2111.13301.pdf
�ڱ�����,�Կ�ѵ������NLP��embedding�ռ������ɾ�����ս�Ժ���ѧϰ�ĶԿ���ʾ����Ϊѧϰ�ԡ�ʹ�öԱ�ѧϰ����˶Կ�ѵ���ķ���������ͬʱ,�Կ���ѵ��Ҳ��ǿ�˶Ա�ѧϰ��³���ԡ�
1.1 dz̸�Կ�
ͨ�Ľ��Կ�ѵ����ʵ������ԭ��������������һЩ�Ŷ������ɶԿ�����,�˿���������ûʲô����,���Ƕ���ģ����˵ȴ��������,ͨ����һͨ����ģ�ͻ��ø����ȶ�,���ģ�͵ı���,���ǻ���ʧģ��һ���ķ����ԡ�

�� \delta �����������ӵ��Ŷ�,������̫��,���̫��Ļ����������ĶԿ�������ԭ�������ͻ�Ƚϴ�,�Ͳ��ܴﵽ��������������Ч��,����Ҫ����һ����Լ��,��ʽ���ұߵ�Լ�� �O �O �� �O �O < ? ||\delta|| < \epsilon �O�O���O�O<?,���� ? \epsilon ?��һ������,�����Ŷ���Ŀ������� L c e L_{ce} Lce?,������ģ�;���ȥ�������ݶ��½��Ǽ�Сloss,��ô��֮���ǿ��Բ����ݶ����������� L c e Lce Lce������� �� \delta ����

������ܻ���Щ�ɻ�,������ܽ��¶Կ�ѵ������:
? a��������x��ע���Ŷ� �� \delta ��,�����Ŷ���Ŀ������ L c e L_{ce} Lce?Խ��Խ��,����Ҳ����̫��,���и�Լ��
? b��ÿ��������������Կ����� x + �� x+\delta x+��,Ȼ���öԿ�������Ϊ����ȥ��С������loss�����²��� �� \theta ��(�ݶ��½�,ǰ�潲���ݶ�������Ϊ�˸��� �� \delta ��)
? c������ִ��a,b��������
��NLP��������һ������Embedding���������Ŷ�,����ʵ�ֿ��Բο�����Ĵ���:
https://github.com/bojone/keras_adversarial_training
���������������ӱ�Ŀ��,�ල�ԱȶԿ�ѧϰ (SCAL) ���ල SCAL (USCAL),����ͨ�����öԿ�ѵ�����жԱ�ѧϰ������ѧϰ�ԡ����üල����Ļ��ڱ�ǩ����ʧ�����ɶԿ���ʾ��,���ල����������Ա���ʧ��
1.2 �ල�ԱȶԿ�ѧϰ
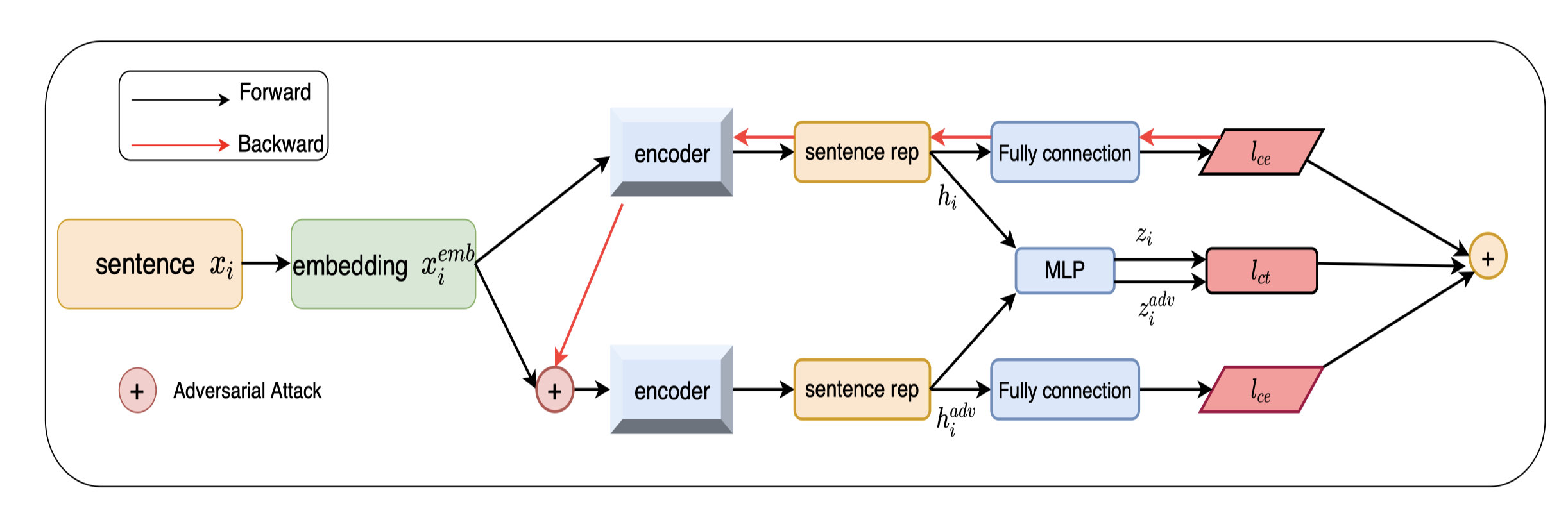
��ģ��ͼ����ʵҲ�ܺ������Ǿ��������Ż�����loss,��һ��loss��������x��������������Ŀ��ȥ����loss(����loss);�ڶ���loss����ȥ�Ż�ԭ�����ͼ����Ŷ���������������(�Ա�loss);������loss���Ǽ����Ŷ������� x + �� x+\delta x+����������������Ŀ��ȥ����loss(����loss),�������loss��������Ż���
�ʹ�ͳ����Ա������ķ�ʽ��ͬ,������Ϊ֮ǰ����ͨ��������ǿ�ȷ�ʽ(ɾ�����滻�����Ƶ�)����Աȶ����ڴʼ������,������word-embedding�Ȳ����ϼ����Ŷ���
ģ��ͼ�е�һ��loss�͵�����loss��ʽ:

�����Ŷ�:

ԭ��ʵ���� 𝜀 �� {0.1, 0.2, 0.3, 0.4, 0.5}
�Ա�loss:

�� \tau �������¶�ϵ��,����������Ϊ0.05��
����loss:

1.3 �ල�ԱȶԿ�ѧϰ
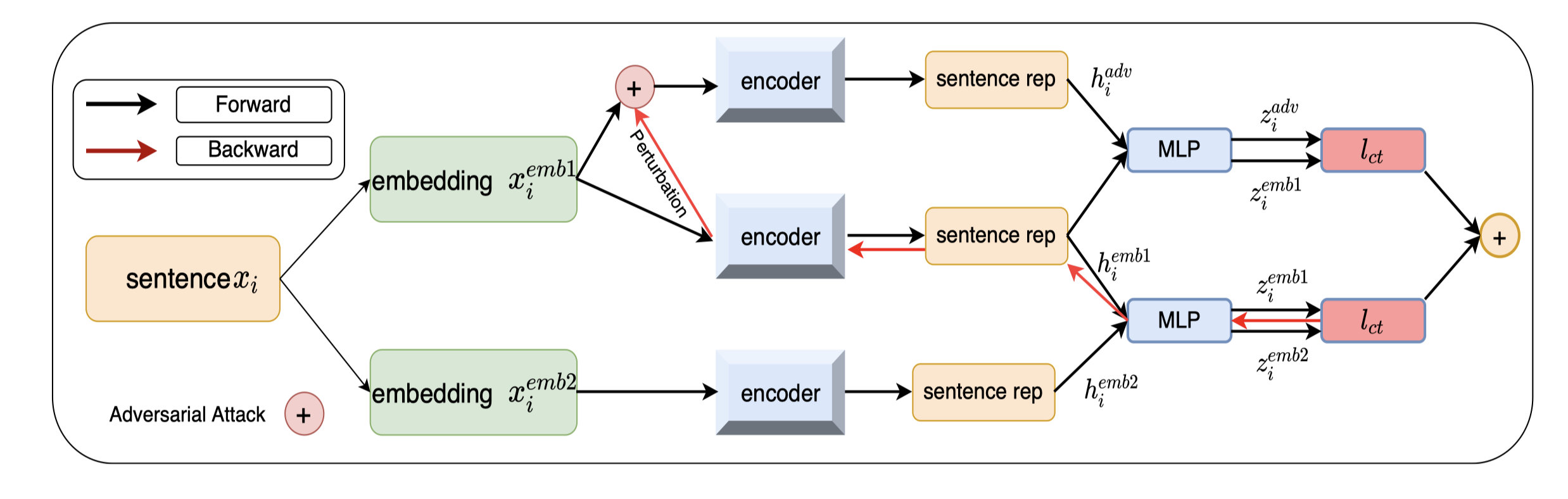
e m b e d d i n g embedding embedding x i e m b 2 x_{i}^{emb2} xiemb2? �����ɷ�ʽ�ο���SimCSE,������Transformer��Feed Forward Network (ǰ��������)��Muti-head Attention�м���һ��Dropout, �����Ļ�һ�������������뵽ģ���о��ܵõ�������ͬ��Embedding�Դ�������������
�ල�汾���Ż��������Ա�loss,һ����ԭ�����ͼ����Ŷ��ĶԱ�loss,��һ��ͨ��dropout masks��ʽ�����������ע���Ŷ��������Ա�loss��
����Ҫע���������Ŷ��ķ�ʽ���мලģ���е㲻һ��,��ͨ��ԭ������ x i e m b 1 x_{i}^{emb1} xiemb1?��ͨ��dropout masks��� x i e m b 2 x_{i}^{emb2} xiemb2?���Ϸ����ݶ������������Ŷ��ġ�

����loss:

����𝛼�dz���,С��1,���ƶԱ���ʧ�ı�����
1.4 ʵ����
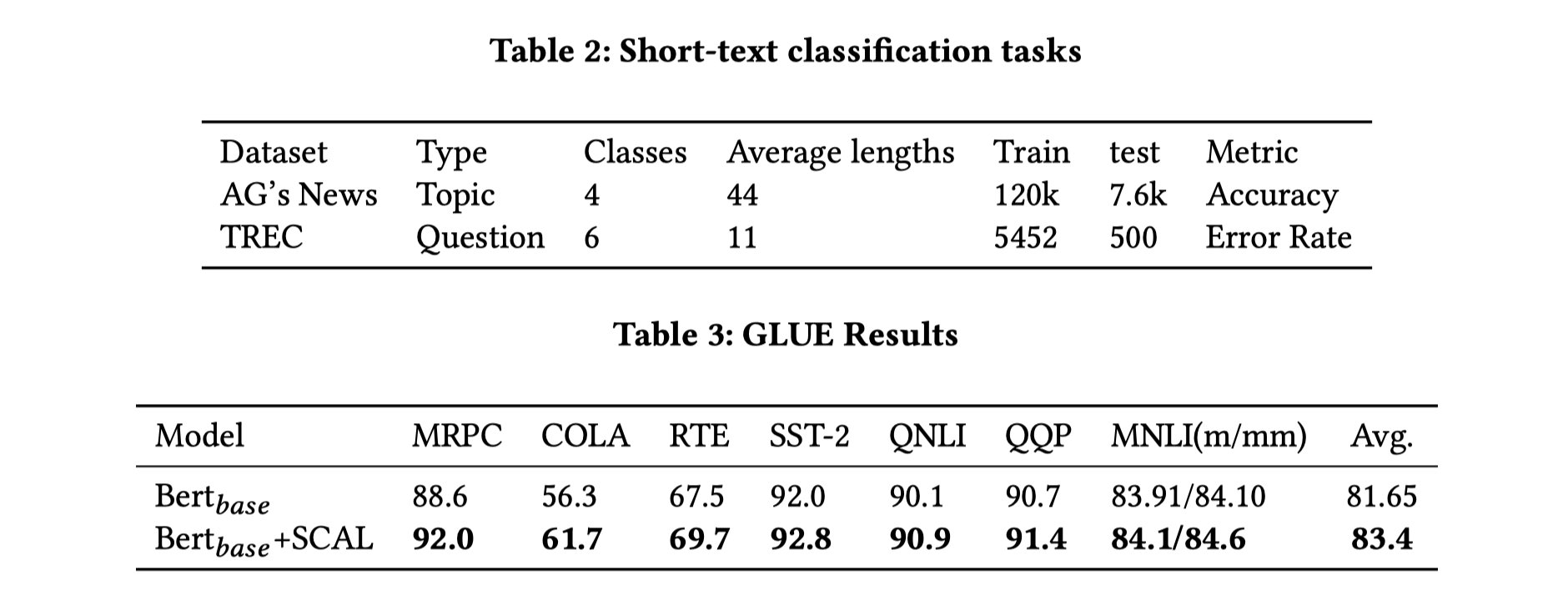
Ϊ����֤�������ܵ���Ч��,�����н���Ӧ���ڻ��� Transformer ��ģ��,������Ȼ�������⡢���������ı������ԺͶԿ���ѧϰ����GLUE �����������ʵ��������,���ļල�������� BERT b a s e _{base} base? ���� 1.75%���������ı������� (STS) �������������ල����,ʹ�� BERT b a s e _{base} base? ��� 77.29%���Ƚ����� NLI ����Ķ���Կ������ݼ��²��������Ƚ��Ľ����
����PromptBERT

���ĵ�ַ:https://openreview.net/forum?id=7I3KTEhKaAK
2.1 Motivation
�������е��о�����,BERT�ľ�������ʾ����,��Ҫ����Ϊ�ܸ�Ƶ�ʵ�Ӱ��,BERT����������ֲ����³���Բ��,��Ƶ�ʻ�ֲ���Բ����,����Ƶ�ʷֲ��ڵײ�,����ȥ����ʶ�ȵĻ����ܻ�����ֲ�ƫ��,��Ƶ��֮������ʶ�ȵ÷�����ڸ�Ƶ�����Ƶ��֮����һЩ,��Ҳ����anisotropy���⡣
����ͨ���о�����,BERT�ھ������ƶ������ϱ��ֲ��ԭ��,��ʵ��anisotropy��ϵ����,������Ϊstatic token embedding bias �� ��Ч��BERT layer���Ƚ�naive����������ȥ����β���bias�Ĵ�,��������ͨ������Prompt,Ȼ��ʹ�ñ�mask��token����ʾ���ӡ�
2.2 ����idea
1������Prompt,����ǿ�Ծ��ӵı�ʾ,ģ����: ��[X] means [MASK]�� X������ľ���,[MASK]��ģ�ͽ�Ҫѧϰ�ľ��ӱ�ʾ��
2������ͬ��Promptģ�����ɵľ��ӱ�ʾ���жԱȡ�
����������ַ�ʽ����ʾ����:
��һ����ֱ��ʹ�ñ�mask��hidden vector����ʾ����(������ʵ���Dz�̫����,�о����߿�����Ҫ������ǹ̶�סlabel,Ȼ����ÿһ��label�ĸ���,ȡ������ΪԤ��label)��
�ڶ����ǽ�mask���ܶ�Ӧ��top-k��token��������м�Ȩ��͡�

�������ھ���embedding���Ծ�̬embedding������ƽ��,����Ȼ�ܵ�ƫ���Ӱ�졢�Լ���Ȩƽ��ʹ��BERT���������������н�����������������Dz��õ�һ�ַ�ʽ��
���߲����ֶ���Ʋ�ͬ��Promptģ��,Ȼ��ȥ��������ֱ�ӵĶԱ�loss��
2.3 ʵ����
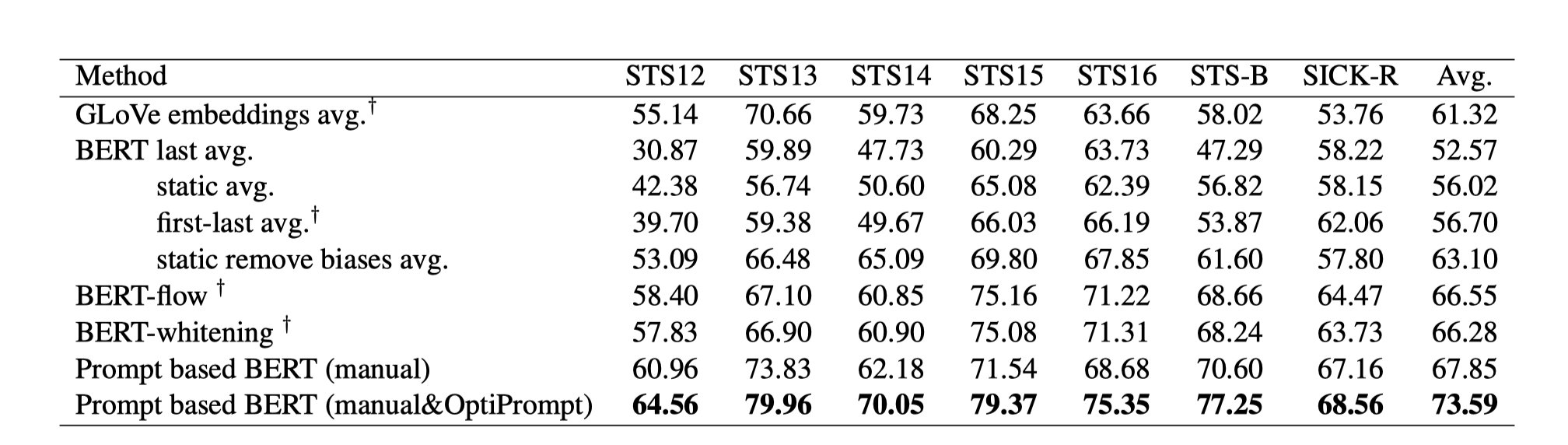
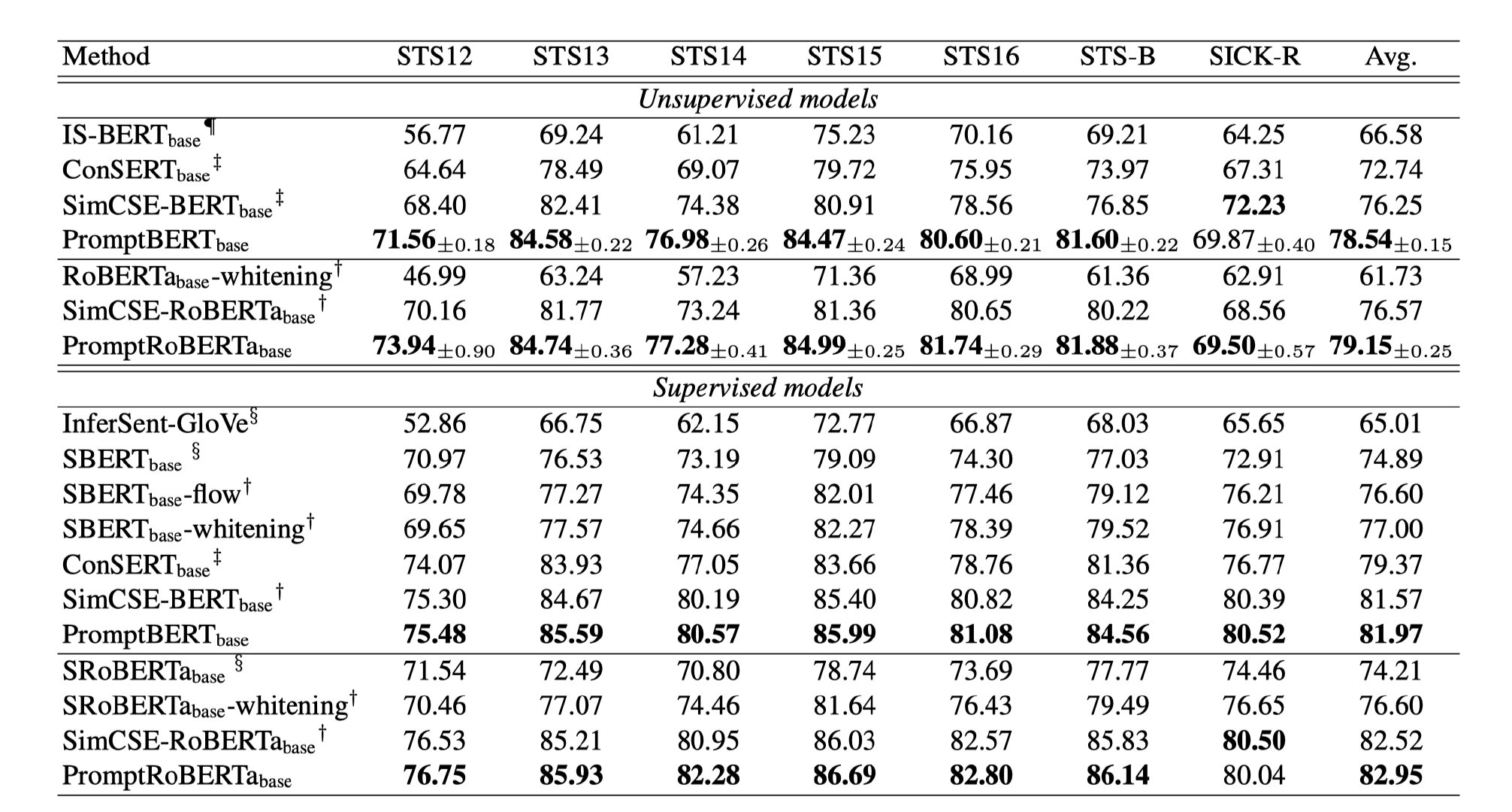
����������������˼��ʵ�����Ȥ�����ѿ���ȥ����ԭ�ġ�
�����ܽ�
��һƪ�����ܽ��¾���ͨ�������Ŷ������������ԴӶ����жԱ�ѧϰ��
�ڶ�ƪ�����Ҹ�����Ϊ��ͬģ��֮��ĶԱ�ֻ�Ǹ���������(ͨ���Լ���һЩʵ�鲻ͬģ��֮��ĶԱ������dz�����,��Լһ���㲻��),��Ҫ������ͨ������Promptģ���ܹ���Ч�ı�ʾ����,ǰ�����������̸��Promptģ���ܹ�����Ԥѵ��ģ�ͻ������Լ�Ԥѵ��ѧ����֪ʶ,��ʵ˵���˾��ǽ����������Ԥѵ�������ͳһ(����)��
