Ԥ���˿�ģ��
���û�ɫԤ��ģ��Ԥ���˿�
Ӧ��
��ɫԤ��ģ��(Gray Forecast Model)��ͨ�������ġ�����ȫ����Ϣ,������ѧģ�Ͳ�����Ԥ���һ��Ԥ�ⷽ�����Ǵ���С����(4���Ϳ���)Ԥ���������Ч����,������С����Ԥ������ع���������Ч������̫���롣
��ɫϵͳ
���dz���Ϣ��ȫδȷ����ϵͳΪ��ɫϵͳ,����Ϣ��ȫȷ����ϵͳΪ��ɫϵͳ,��ɫϵͳ�����������֮��,һ������Ϣ����֪��,��һ������Ϣ��δ֪��,ϵͳ�ڸ����ؼ��в�ȷ���Ĺ�ϵ��
�ص�
- �û�ɫ��ѧ������ȷ����,ʹ֮������
- ���������֪��ϢѰ��ϵͳ���˶����ɡ�
- ��ɫϵͳ�����ܴ���ƶ��Ϣϵͳ��
��ɫ��������
��ɫϵͳ������Ϊ,���ܿ۱�����,�����������幦�ܵ�,��˱�Ȼ�̺�ij�����ڹ��ɡ��ؼ��������ѡ���ʵ��ķ�ʽȥ�ھ������������ɫϵͳʱͨ����ԭʼ���ݵ�������Ѱ����仯���ɵ�,����һ�־�����Ѱ�����ݵ���ʵ���ɵ�;��,Ҳ���ǻ�ɫ���е�������һ�л�ɫ���ж���ͨ��ij�����������������,����������ԡ��������ɵij��÷�ʽ���ۼ����ɡ��ۼ����ɺͼ�Ȩ�ۼ����ɡ����õ����ۼ����ɡ�
��ԭʼ����Ϊ��ԭʼ����Ϊ
x
(
0
)
=
(
x
0
(
1
)
,
x
0
(
2
)
,
��
��
,
x
0
(
n
)
)
x^{(0)}=\left(x^{0}(1), x^{0}(2), \ldots \ldots, x^{0}(n)\right)
x(0)=(x0(1),x0(2),����,x0(n))
1.�ۼ�����
x 1 ( 1 ) = x 0 ( 1 ) x^{1}(1)=x^{0}(1) x1(1)=x0(1)
x 1 ( 2 ) = x 0 ( 1 ) + x 0 ( 2 ) x^{1}(2)=x^{0}(1)+x^{0}(2) x1(2)=x0(1)+x0(2)
x 1 ( 3 ) = x 0 ( 1 ) + x 0 ( 2 ) + x 0 ( 3 ) x^{1}(3)=x^{0}(1)+x^{0}(2)+x^{0}(3) x1(3)=x0(1)+x0(2)+x0(3)
x 1 ( n ) = x 0 ( 1 ) + x 0 ( 2 ) + �� �� + x 0 ( n ) x^{1}(n)=x^{0}(1)+x^{0}(2)+\ldots \ldots+x^{0}(n) x1(n)=x0(1)+x0(2)+����+x0(n)
�ۼӵ�����Ϊ
x
(
1
)
=
(
x
1
(
1
)
,
x
1
(
2
)
,
��
��
,
x
1
(
n
)
)
x^{(1)}=\left(x^{1}(1), x^{1}(2), \ldots \ldots, x^{1}(n)\right)
x(1)=(x1(1),x1(2),����,x1(n))
������һ�����ݵĵ���������
��ʱ���ܿ���������ʲô�Ĺ���,�������ۼ����ɺ�Ľ������
����������һ�������Ĺ���(����20��ij��ӱ���λ�Ƶ�����,˳ˮ��������α�һ����������)
2.��Ȩ��ֵ����
z
0
(
2
)
=
a
x
0
(
2
)
+
(
1
?
a
)
x
0
(
1
)
z^{0}(2)=a x^{0}(2)+(1-a) x^{0}(1)
z0(2)=ax0(2)+(1?a)x0(1)
z
0
(
3
)
=
a
x
0
(
3
)
+
(
1
?
a
)
x
0
(
2
)
z^{0}(3)=a x^{0}(3)+(1-a) x^{0}(2)
z0(3)=ax0(3)+(1?a)x0(2)
z
0
(
4
)
=
a
x
0
(
4
)
+
(
1
?
a
)
x
0
(
3
)
z^{0}(4)=a x^{0}(4)+(1-a) x^{0}(3)
z0(4)=ax0(4)+(1?a)x0(3)
��
\ldots
��
z
1
(
n
)
=
a
x
0
(
n
)
+
(
1
?
a
)
x
0
(
n
?
1
)
z^{1}(n)=a x^{0}(n)+(1-a) x^{0}(n-1)
z1(n)=ax0(n)+(1?a)x0(n?1)
�ɴ˵õ������г�Ϊ��ֵ������,Ȩ �� \alpha �� Ҳ��Ϊ����ϵ���� �ر��,������ϵ�� �� = \alpha= ��= 0.5 0.5 0.5 ʱ,��Ƹ�����Ϊ��ֵ������,Ҳ��Ϊ��Ȩ��ֵ��������
��ɫģ��GM(1,1)
GM����grey model(��ɫģ��),GM(1,1)��һ���ַ���ģ�͡�
1.���ݼ���
ʹ�� G M ( 1 , 1 ) \mathrm{GM}(1,1) GM(1,1) ��ģ��Ҫ�����ݽ��м���,���ȼ������еļ���
�� ( k ) = x 0 ( k ? 1 ) x 0 ( k ) \lambda(k)=\frac{x^{0}(k-1)}{x^{0}(k)} ��(k)=x0(k)x0(k?1)?, ���� k = 2 , 3 , �� , n k=2,3, \ldots, n k=2,3,��,n
������еļ��ȶ����ڿ��ݸ������� X = ( e ? 2 n + 1 , e 2 n + 1 ) X=\left(e^{\frac{-2}{n+1}}, e^{\frac{2}{n+1}}\right) X=(en+1?2?,en+12?) ��,������ x ( 0 ) \left.x^{(} 0\right) x(0) ���Խ���
G M ( 1 , 1 ) \mathrm{GM}(1,1) GM(1,1) ģ�ͽ��л�ɫԤ�⡣�������Ҫ���������ʵ��ı任����,��ƽ�Ƶȡ�
2.������ɫģ��
���� x ( 1 ) x^{(1)} x(1) �Ļҵ���Ϊ
d ( k ) = x 0 ( k ) = x 1 ( k ) ? x 1 ( k ? 1 ) d(k)=x^{0}(k)=x^{1}(k)-x^{1}(k-1) d(k)=x0(k)=x1(k)?x1(k?1)
�� z 1 ( k ) z^{1}(k) z1(k) Ϊ���� x 1 x^{1} x1 ����ֵ��������,��
z 1 ( k ) = a x 1 ( k ) + ( 1 ? a ) x 1 ( k ? 1 ) z^{1}(k)=a x^{1}(k)+(1-a) x^{1}(k-1) z1(k)=ax1(k)+(1?a)x1(k?1)
���Ƕ��� G M ( 1 , 1 ) G M(1,1) GM(1,1) �Ļ��ַ���ģ��Ϊ
d ( k ) + a z 1 ( k ) = b d(k)+a z^{1}(k)=b d(k)+az1(k)=b
����, a a a ��Ϊ��չϵ��, z 1 ( k ) z^{1}(k) z1(k) ��Ϊ������ֵ, b b b ��Ϊ�������������������ǵõ��� �·�����
x 0 ( 2 ) + a z 1 ( 2 ) = b x^{0}(2)+a z^{1}(2)=b x0(2)+az1(2)=b
x 0 ( 3 ) + a z 1 ( 3 ) = b x^{0}(3)+a z^{1}(3)=b x0(3)+az1(3)=b
x 0 ( n ) + a z 1 ( n ) = b x^{0}(n)+a z^{1}(n)=b x0(n)+az1(n)=b
���վ���ķ����г�
$
u=\left[\begin{array}{l}
a \
b
\end{array}\right], Y=\left[\begin{array}{c}
x^{0}(2) \
x^{0}(3) \
\ldots \
x^{0}(n)
\end{array}\right], B=\left[\begin{array}{cc}
-z^{1}(2) & 1 \
-z^{1}(3) & 1 \
\cdots & \
-z^{1}(n) & 1
\end{array}\right]
$
�� G M ( 1 , 1 ) \mathrm{GM}(1,1) GM(1,1) �Ϳ��Ա�ʾΪ Y = B u Y=B u Y=Bu ,������������ a a a �� b b b ��ֵ,����ʹ�����Իع���� ( B T B ) ? 1 B T Y \left(B^{T} B\right)^{-1} B^{T} Y (BTB)?1BTY (���淽��) �Ȱ��|��С���˵�ԭ������� a a a �� b b b ��ֵ (�������з���ʱ a a a �������дһ�� ��,���� 1 2 \frac{1}{2} 21? ,���� a a a �� ( 1 ? a ) (1-a) (1?a) ��һ���Ŀ������������д) ��
3.Ԥ��
��Ӧ�İ�ģ��Ϊ
d x 1 ( t ) d t + a x 1 ( t ) = b \frac{d x^{1}(t)}{d t}+a x^{1}(t)=b dtdx1(t)?+ax1(t)=b
�ɴ˵õ� x 1 ( t ) x^{1}(t) x1(t) �Ľ�Ϊ
x 1 ( t ) = ( x 0 ( 1 ) ? b a ) e ? a ( t ? 1 ) + b a x^{1}(t)=\left(x^{0}(1)-\frac{b}{a}\right) e^{-a(t-1)}+\frac{b}{a} x1(t)=(x0(1)?ab?)e?a(t?1)+ab?
�� t + 1 = t t+1=t t+1=t ��
x 1 ( t + 1 ) = ( x 0 ( 1 ) ? b a ) e ? a + b a x^{1}(t+1)=\left(x^{0}(1)-\frac{b}{a}\right) e^{-a}+\frac{b}{a} x1(t+1)=(x0(1)?ab?)e?a+ab?, ���� k = 1 , 2 , 3 �� , n ? 1 k=1,2,3 \ldots, n-1 k=1,2,3��,n?1
��������ǵ�Ԥ��ֵ��
4.����
��ɫģ�͵ľ��ȼ���һ�������ַ�����ɫģ�͵ľ��ȼ���һ�������ַ���,�������С���鷨,�����ȼ��鷨�ͺ������鷨�����õ�Ϊ�������鷨��
-
��Ԥ��� x ^ 1 \hat{x}^{1} x^1 ʹ���ۼ����ɵõ�
x ^ 0 \hat{x}^{0} x^0 x ^ 0 ( k ) = x ^ 1 ( k ) ? x ^ 1 ( k ? 1 ) \hat{x}^{0}(k)=\hat{x}^{1}(k)-\hat{x}^{1}(k-1) x^0(k)=x^1(k)?x^1(k?1), ���� k = 2 , 3 , �� , n k=2,3, \ldots, n k=2,3,��,n
-
����в�
e ( k ) = x 0 ( k ) ? x ^ 0 ( k ) e(k)=x^{0}(k)-\hat{x}^{0}(k) e(k)=x0(k)?x^0(k), ���� k = 1 , 2 , �� , n k=1,2, \ldots, n k=1,2,��,n -
����ԭʼ���� x 0 x^{0} x0 �ķ��� S 1 S_{1} S1? �Ͳв� e e e �ķ��� S 2 S_{2} S2?
S 1 = 1 n �� k = 1 n ( x 0 ( k ) ? x �� ) 2 S_{1}=\frac{1}{n} \sum_{k=1}^{n}\left(x^{0}(k)-\bar{x}\right)^{2} S1?=n1?��k=1n?(x0(k)?x��)2 S 2 = 1 n �� k = 1 n ( e ( k ) ? e �� ) 2 S_{2}=\frac{1}{n} \sum_{k=1}^{n}(e(k)-\bar{e})^{2} S2?=n1?��k=1n?(e(k)?e��)2 -
���������
C = S 2 S 1 C=\frac{S_{2}}{S_{1}} C=S1?S2?? -
����۲�Ч��
| ģ�;��ȵȼ� | �������ֵC |
|---|---|
| 1 ��(��) | C<=0.35 |
| 2 ��(�ϸ�) | C<=0.5&c>0.35 |
| 3 ��(��ǿ) | C<=0.65&c>0.5 |
| 4 ��(���ϸ�) | C>0.65 |
��ɫԤ��ģ��Ԥ���˿�
1.��������
�ӹ���ͳ�ƾֻ�ȡʮ����˿�����
| �˿����� | ��� |
|---|---|
| 127627 | 2011 |
| 128453 | 2012 |
| 129227 | 2013 |
| 129988 | 2014 |
| 130756 | 2015 |
| 131448 | 2016 |
| 132129 | 2017 |
| 132802 | 2018 |
| 133450 | 2019 |
| 134091 | 2020 |
���û�ɫԤ��ģ��Ԥ���ĺ�ʮ����˿�����
| �˿�����(����) | ��� | Ԥ������(����) | ����� |
|---|---|---|---|
| 127627 | 2001 | 127627 | 0.000% |
| 128453 | 2002 | 128575.416 | 0.095% |
| 129227 | 2003 | 129265.6577 | 0.030% |
| 129988 | 2004 | 129959.6049 | 0.022% |
| 130756 | 2005 | 130657.2774 | 0.076% |
| 131448 | 2006 | 131358.6954 | 0.068% |
| 132129 | 2007 | 132063.8788 | 0.049% |
| 132802 | 2008 | 132772.8479 | 0.022% |
| 133450 | 2009 | 133485.623 | 0.027% |
| 134091 | 2010 | 134202.2245 | 0.083% |
| 134916 | 2011 | 134922.6731 | 0.005% |
| 135922 | 2012 | 135646.9893 | 0.202% |
| 136726 | 2013 | 136375.1939 | 0.257% |
| 137646 | 2014 | 137107.3077 | 0.391% |
| 138326 | 2015 | 137843.3519 | 0.349% |
| 139232 | 2016 | 138583.3474 | 0.466% |
| 140011 | 2017 | 139327.3155 | 0.488% |
| 140541 | 2018 | 140075.2774 | 0.331% |
| 141008 | 2019 | 140827.2548 | 0.128% |
| 141212 | 2020 | 141583.269 | 0.263% |
����ʾ���1%����,Ч���ܺá�
��2011-2020������Ԥ��δ��ʮ����˿�����
| ��� | �˿���Ŀ(����) |
|---|---|
| 2021 | 142440.9 |
| 2022 | 143150.2 |
| 2023 | 143863.1 |
| 2024 | 144579.5 |
| 2025 | 145299.5 |
| 2026 | 146023 |
| 2027 | 146750.2 |
| 2028 | 147481 |
| 2029 | 148215.5 |
| 2030 | 148953.6 |
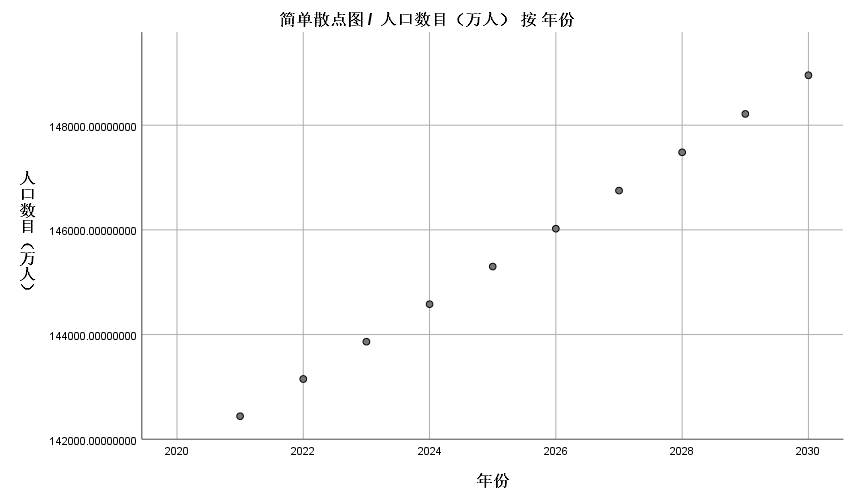
����Ϊһ��ֱ��,�����ݹ���ͳ�ƾ�Ԥ��,�ҹ��˿ڽ���10����ӭ���յ㡣
�ʸ���Ԥ��ģ�͡�
����Ȼ������Ԥ��
��Ȼ����������
| ��� | ��Ȼ������ |
|---|---|
| 2011 | 6.13 |
| 2012 | 7.43 |
| 2013 | 5.9 |
| 2014 | 6.71 |
| 2015 | 4.93 |
| 2016 | 6.53 |
| 2017 | 5.58 |
| 2018 | 3.78 |
| 2019 | 3.32 |
| 2020 | 1.45 |
������Ȼ������ɢ��ͼ
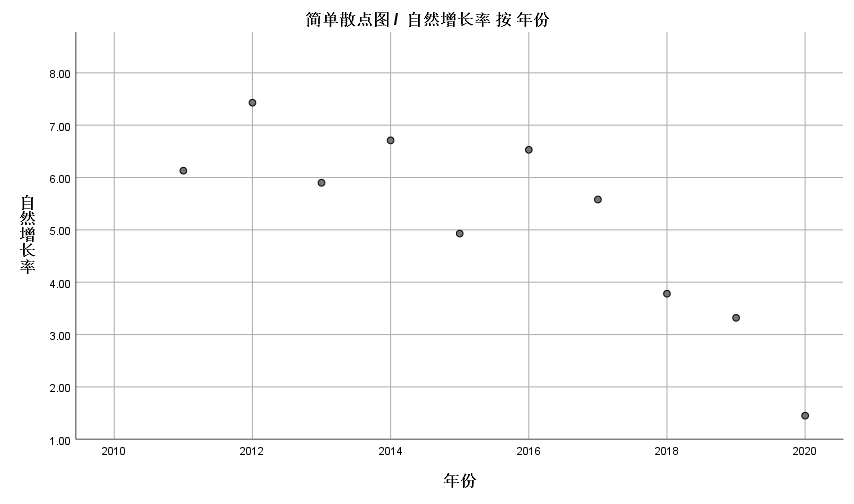
ɢ��ͼû�г����ʺϻҶ�ģ�͵�����(ָ����),�Ҳ����ϴ�,�������ûҶ�ģ��,�������Ϊ(��ȥ��Ԥ������)
������δͨ������
a=[0.10967811]
b=[8.69394742]
2��,Ч���ϸ�
����δ��������,�ʲ����ûҶ�ģ��Ԥ����Ȼ�����ʡ�
����SPSS����Ȼ�����ʽ������߹������
�������߹������,��������ģ���ʺ϶��˿ڽ���Ԥ�⡣
���߹�������������:
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-kSJ9iqM6-1639318859800)(https://s2.loli.net/2021/12/12/YcnwZG7IEJ1OzVd.png)]
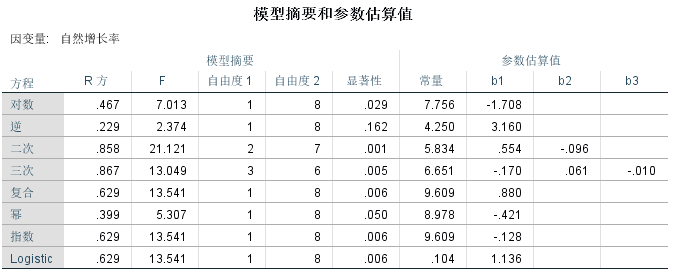
����������Ρ����Ρ����ϡ��ݡ�ָ����������������Զ�����0.05,���ɲ���,�Ҷ��κ�������š�
�˴�ѡ����κ���,����δ��5�����Ȼ����������:
| ��� | ��Ȼ������(��) |
|---|---|
| 2021 | 0.202 |
| 2022 | -1.462 |
| 2023 | -3.318 |
| 2024 | -5.366 |
| 2025 | -7.606 |
������Ȼ������Ԥ��δ��5���˿�
| ��� | �˿ڼ�Ԥ���˿�(����) |
|---|---|
| 2021 | 141240.5 |
| 2022 | 141034 |
| 2023 | 140566.1 |
| 2024 | 139811.8 |
| 2025 | 138748.4 |
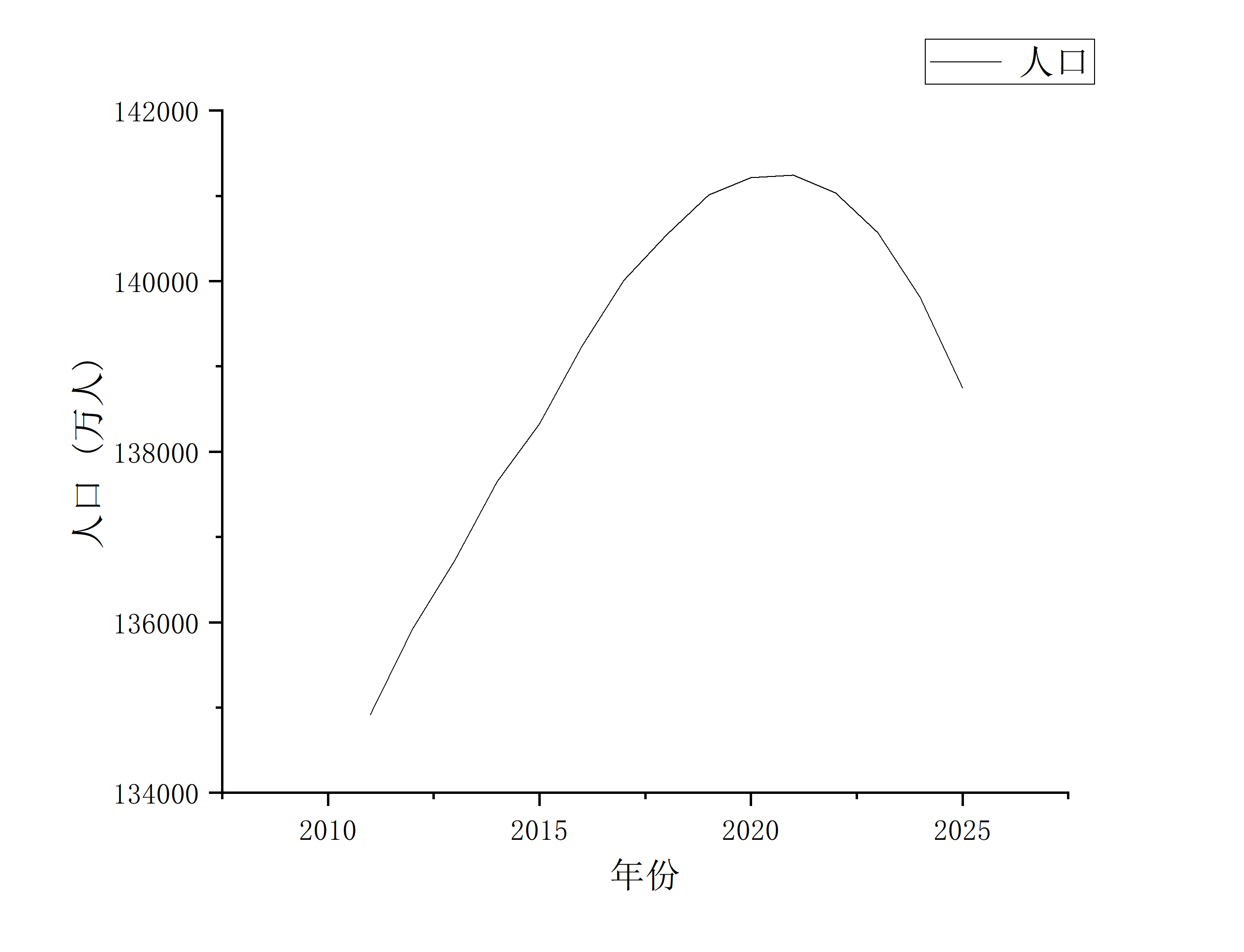
�˿�ת�۵���2022�ꡣ
��ɫԤ��ģ��python����
# ��ɫģ��Ԥ��
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
dir = 'C:\\Users\\shuai\\Desktop\\����ͳ��ѧ\\���ۿ�'
data = pd.read_csv(dir+'\\test.csv')
data = np.array(data['pdata'])
lens = len(data) # ������
# ���ݼ���
## ���㼶��
lambds = []
for i in range(1, lens):
lambds.append(data[i-1]/data[i])
## ��������
X_min = np.e**(-2/(lens+1))
X_max = np.e**(2/(lens+1))
## ����
is_ok = True
for lambd in lambds:
if (lambd < X_min or lambd > X_max):
is_ok = False
if (is_ok == False):
print('������δͨ������')
else:
print('������ͨ������')
# ������ɫģ��GM(1,1)
## �ۼ�����
data_1 = []
data_1.append(data[0])
for i in range(1, lens):
data_1.append(data_1[i-1]+data[i])
## �ҵ�������ֵ��������
ds = []
zs = []
for i in range(1, lens):
ds.append(data[i])
zs.append(-1/2*(data_1[i-1]+data_1[i]))
## ��a��b
B = np.array(zs).reshape(lens-1,1)
one = np.ones(lens-1)
B = np.c_[B, one] # ����һ��1
Y = np.array(ds).reshape(lens-1,1)
a, b = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Y)
print('a='+str(a))
print('b='+str(b))
# Ԥ��
def func(k):
c = b/a
return (data[0]-c)*(np.e**(-a*k))+c
data_1_hat = [] # �ۼ�Ԥ��ֵ
data_0_hat = [] # ԭʼԤ��ֵ
data_1_hat.append(func(0))
data_0_hat.append(data_1_hat[0])
for i in range(1, lens+10): # ��Ԥ��10��
data_1_hat.append(func(i))
data_0_hat.append(data_1_hat[i]-data_1_hat[i-1])
print('Ԥ��ֵΪ:')
for i in data_0_hat:
print(i)
# ģ�ͼ���
## Ԥ��������
data_h = np.array(data_0_hat[0:10]).T
sum_h = data_h.sum()
mean_h = sum_h/lens
S1 = np.sum((data_h-mean_h)**2)/lens
## ��
e = data - data_h
sum_e = e.sum()
mean_e = sum_e/lens
S2 = np.sum((e-mean_e)**2)/lens
## ������
C = S2/S1
## ���
if (C <= 0.35):
print('1��,����')
elif (C <= 0.5 and C >= 0.35):
print('2��,Ч���ϸ�')
elif (C <= 0.65 and C >= 0.5):
print('3��,Ч����ǿ')
else:
print('4��,Ч�����ϸ�')
# ��ͼ
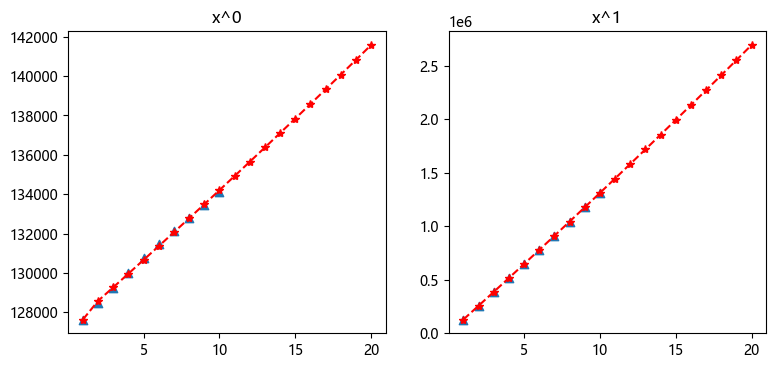
plt.figure(figsize=(9, 4), dpi=100)
x1 = np.linspace(1, 10, 10)
x2 = np.linspace(1, 20, 20)
plt.subplot(121)
plt.title('x^0')
plt.plot(x2, data_0_hat, 'r--', marker='*')
plt.scatter(x1, data, marker='^')
plt.subplot(122)
plt.title('x^1')
plt.plot(x2, data_1_hat, 'r--', marker='*')
plt.scatter(x1, data_1, marker='^')
plt.show()
����������
������ͨ������
a=[-0.00535402]
b=[127548.20761512]
Ԥ��ֵΪ:
[127627.]
[128575.41598519]
[129265.6576876]
[129959.60486981]
[130657.27742425]
[131358.69535014]
[132063.87875406]
[132772.84785051]
[133485.62296254]
[134202.22452229]
[134922.67307159]
[135646.98926251]
[136375.19385806]
[137107.30773265]
[137843.35187279]
[138583.34737763]
[139327.31545959]
[140075.277445]
[140827.25477463]
[141583.26900437]
1��,����