1 ����
1.1 ��Ϊ���ع顱�ķ�����
���ع���һ����Ϊ���ع顱�����Է�����,���ı����������Իع�仯������,һ�ֹ㷺ʹ���ڷ��������еĹ���ع��㷨��Ҫ�������ع�Ӻζ���,�����������Իع顣���Իع��ǻ���ѧϰ����Ļع��㷨,д��һ������������Ϥ�ķ���:
z
=
a
0
+
a
1
x
1
+
a
2
x
2
+
.
.
.
+
a
n
x
n
z=a_0+a_1x_1+a_2x_2+...+a_nx_n
z=a0?+a1?x1?+a2?x2?+...+an?xn?
����,
a
a
a��ͳ��Ϊģ�͵IJ���,����
a
0
a_0
a0?����Ϊ�ؾ�(intercept),
a
1
a_1
a1?~
a
n
a_n
an?����Ϊϵ��(coefficient)��ʹ�þ�������ʾ�������,����
x
x
x��
a
a
a�����Ա�����ʱһ���о���,����:
z
=
(
a
0
a
1
a
2
.
.
.
a
n
)
?
(
x
0
x
1
x
2
.
.
.
x
n
)
=
a
T
x
(
x
0
=
1
)
z=\begin{pmatrix}a_0&a_1&a_2&...&a_n\end{pmatrix}*\begin{pmatrix}x_0\\x_1\\x_2\\...\\x_n\end{pmatrix}=\textbf{a}^T\textbf{x}(x_0=1)
z=(a0??a1??a2??...?an??)????????x0?x1?x2?...xn?????????=aTx(x0?=1)
���Իع������,���ǹ���һ��Ԥ�⺯��
z
z
z��ӳ���������������
x
x
x�ͱ�ǩֵ
y
y
y�����Թ�ϵ,������Ԥ�⺯���ĺ��ľ����ҳ�ģ�͵IJ���:
a
T
a^T
aT��
a
0
a_0
a0?,��������С���˷���������������Իع��в�������ѧ������
ͨ������
z
z
z,���Իع�ʹ���������������
x
x
x�����һ�������͵ı�ǩֵy_pred,����ɸ���Ԥ�������ͱ���������(��Ԥ���Ʒ����,Ԥ��ɼ۵�)�������ǩ����ɢ�ͱ���,������,���������0-1�ֲ�����ɢ�ͱ���,����ͨ��������ϵ����(link function),�����Իع鷽��
z
z
z�任Ϊ
g
(
z
)
g(z)
g(z),������
g
(
z
)
g(z)
g(z)��ֵ�ֲ���
(
0
,
1
)
(0,1)
(0,1)֮��,�ҵ�
g
(
z
)
g(z)
g(z)�ӽ�Ϊ0ʱ�����ı�ǩΪ���0,��
g
(
z
)
g(z)
g(z)�ӽ�Ϊ1ʱ�����ı�ǩΪ���1,�����͵õ�һ������ģ��,�������ϵ�����������ع���˵,����Sigmoid����:
g
(
z
)
=
1
1
+
e
?
z
g(z)=\frac{1}{1+e^{-z}}
g(z)=1+e?z1?
Sigmoid�����Ĺ�ʽ������:Sigmoid������һ��S�͵ĺ���,���Ա���
z
z
z����������ʱ,�����
g
(
z
)
g(z)
g(z)������1,����
z
z
z����������ʱ,
g
(
z
)
g(z)
g(z)������0,���ܹ����κ�ʵ��ӳ�䵽
(
0
,
1
)
(0,1)
(0,1)����,ʹ������ڽ�����ֵ����ת��Ϊ���ʺ϶�����ĺ�������Ϊ�������,Sigmoid����Ҳ�������ǹ�һ����һ�ַ���,��֮ǰѧ����MinMaxScalerͬ��,����������Ԥ�����еġ����š�����,���Խ�����ѹ����
[
0
,
1
]
[0,1]
[0,1]֮�ڡ���������,MinMaxScaler��һ��֮��,�ǿ���ȡ��0��1��(���ֵ��һ�������1,��Сֵ��һ�������0),��Sigmoid����ֻ������������0��1��
���Իع���
z
=
a
T
x
z=\textbf{a}^T\textbf{x}
z=aTx,��
z
z
z����,�͵õ��˶�Ԫ���ع�ģ�͵�һ����ʽ:
g
(
z
)
=
y
(
x
)
=
1
1
+
e
?
a
T
x
g(z)=y(x)=\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}
g(z)=y(x)=1+e?aTx1?
��
g
(
z
)
g(z)
g(z)�������ع鷵�صı�ǩֵ����ʱ,
y
(
x
)
y(x)
y(x)��ȡֵ����
[
0
,
1
]
[0,1]
[0,1]֮��,���
y
(
x
)
y(x)
y(x)��
1
?
y
(
x
)
1-y(x)
1?y(x)��ӱ�ȻΪ1�������
y
(
x
)
y(x)
y(x)����
1
?
y
(
x
)
1-y(x)
1?y(x)���Եõ����Ƽ���(odds)��
y
(
x
)
1
?
y
(
x
)
\frac{y(x)}{1-y(x)}
1?y(x)y(x)?,�ڴ˻�����ȡ����,���Ժ����õ�:
l
n
y
(
x
)
1
?
y
(
x
)
=
l
n
(
1
1
+
e
?
a
T
x
1
?
1
1
+
e
?
a
T
x
)
=
l
n
(
1
1
+
e
?
a
T
x
e
?
a
T
x
1
+
e
?
a
T
x
)
=
l
n
(
1
e
?
a
T
x
)
=
l
n
(
e
a
T
x
)
=
a
T
x
ln\frac{y(x)}{1-y(x)}=ln(\frac{\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}}{1-\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}})=ln(\frac{\frac{1}{1+e^{-\textbf{a}^T\textbf{x}}}}{\frac{e^{-\textbf{a}^T\textbf{x}}}{1+e^{-\textbf{a}^T\textbf{x}}}})=ln(\frac{1}{e^{-\textbf{a}^T\textbf{x}}})=ln(e^{\textbf{a}^T\textbf{x}})=\textbf{a}^T\textbf{x}
ln1?y(x)y(x)?=ln(1?1+e?aTx1?1+e?aTx1??)=ln(1+e?aTxe?aTx?1+e?aTx1??)=ln(e?aTx1?)=ln(eaTx)=aTx
���ѷ���,
y
(
x
)
y(x)
y(x)�����Ƽ��ʶ����ı�����ʵ�������Իع�
z
z
z,ʵ�������ڶ����Իع�ģ�͵�Ԥ����ȡ�������������������ޱƽ�0��1�����,���Ӧ��ģ�ͱ���Ϊ���������ʻع顱(logistic regression),Ҳ�������ع�,�����Ϊ���ع顱��ģ����������������ķ�������
���Իع�ĺ���������ͨ�����
a
\textbf{a}
a����
z
z
z���Ԥ�⺯��,��ϣ��Ԥ�⺯��
z
z
z�ܹ������������,������ع�ĺ�������Ҳ�����Ƶ�:���
a
\textbf{a}
a������һ���ܹ�����������ݵ�Ԥ�⺯��
y
(
x
)
y(x)
y(x),��ͨ����Ԥ�⺯��������������������ȡ��Ӧ�ı�ǩֵ
y
y
y��
˼��:
y
(
x
)
y(x)
y(x)����������Ϊijһ���ǩ�ĸ�����?:
l
n
y
(
x
)
1
?
y
(
x
)
ln\frac{y(x)}{1-y(x)}
ln1?y(x)y(x)?�����ƶ������ʵ�һ�ֱ仯��������odds�ı�����ʵ��
p
1
?
p
\frac{p}{1-p}
1?pp?,����
p
p
p���¼�A�����ĸ���,��
1
?
p
1-p
1?p���¼�A���ᷢ���ĸ���,����
p
+
(
1
?
p
)
=
1
p+(1-p)=1
p+(1?p)=1�����,���������ع�ʱ,��Ϊ
y
(
x
)
y(x)
y(x)��ij����
i
i
i�ı�ǩ��Ԥ��Ϊ1�ĸ���,��
1
?
y
(
x
)
1-y(x)
1?y(x)��ij����
i
i
i�ı�ǩ��Ԥ��Ϊ0�ĸ���,
y
(
x
)
1
?
y
(
x
)
\frac{y(x)}{1-y(x)}
1?y(x)y(x)?��ij����
i
i
i�ı�ǩ��Ԥ��Ϊ1����Ը��ʡ�������������,ʹ�������Ȼ�����ʷֲ������Ƶ������ع����ʧ����,���Ұѷ��������ڱ�ǩȡֵ�ϵĸ��ʵ��������ع��������ʹ�á��������������Ƿ���ȷ��ȷ����
1.2 Ϊʲô��Ҫ���ع�
���Իع�����ݵ�Ҫ����ϸ�,��������ʵ�龳��������������ЩҪ��,������Իع��ںܶ���ʵ�龰��Ӧ��Ч�����ޡ����ع������Իع�任������,�����������Ҳ��һ����Ҫ��,�������ع����ԭ��������������ģ�;����������ɭ��,���ǵķ���������ǿ,���Ҳ���Ҫ���������κ�Ԥ���������,�������ھ��˹��������漰����ҽ�ơ�����������ʶ������ʶ�������,���ع�û��̫��ij������ᡣ����,���ۻ���ѧϰ�������,���ع���Ȼ��һ���ܹ�ҵ��ҵ�Ȱ�,��ʹ�ù㷺��ģ��,��Ϊ���������ŵ�:
- ���ع�����Թ�ϵ�����Ч���ܺ�,�������ǩ֮������Թ�ϵ��ǿ������,����������е����ÿ���թ�����ֿ������������е�Ӫ��Ԥ�����ص�����,�������ع��ǿ���Ȼ�������ݶ�������GDBT,�����ع�Ч����,Ҳ������������ѯ��˾ʹ��,�����ع��ڽ�������,����������ҵ�е�ͳ�ε�λ��Ȼ�Dz��ɶ�ҡ�ġ�
- ���ع�����,������������,���ع����Ϻͼ��㶼�dz���,����Ч������SVM�����ɭ��,�����ڴ��������ϡ�
- ���ع鷵�صķ��������ǹ̶���0,1,������С����ʽ���ֵ����������,�������ع鷵�صĽ����������������������,�������ֿ�����ʱ,������Ҫ�жϿͻ��Ƿ��ΥԼ,����Ҫ����ȷ���ġ����÷֡�,��������÷ֵļ������Ҫʹ������ʼ�����Ķ�������,�������������ɭ�������ķ�����,���Բ���������,�����������(��Ȼ,��sklearn��,����Ҳ���Բ�������,ʹ�ýӿ�predict_proba���þͺ�,��һ�����,�����ľ������˹���)��
����,���ع黹�п�������ǿ���ŵ�,�������ع���С���ݼ��ϱ��ָ���,�ڴ��͵����ݼ���,��ģ���и��õ�ģ�͡�
���ع���һ�����ض������ʵ�,�����������ϱ�������ķ���������Ҫ��Ӧ���ڽ�����������ѧĿ��������ܹ���ģ�Ͷ�������ϳ̶ȸ��ߵIJ��� a \textbf{a} a��ֵ,�Դ˹���Ԥ�⺯�� y ( x ) y(x) y(x),Ȼ��������������Ԥ�⺯������������ع�Ľ�� y y y����Ȼ��Ϥ�����ع�ͨ�������ڴ�������������,�����ع�Ҳ����������ࡣ
1.3 sklearn�е����ع�
���ع���ص���:
linear_model.LogisticRegression:���ع������(�ֽ�logit,����ط�����)
linear_model.LogisticRegressionCV:��������֤�����ع������
linear_model.logistic_regression_path:����Logistic�ع�ģ���Ի�����������б�
linear_model.SGDClasiifier:�����ݶ��½��������Է�����(SVM,���ع��)
linear_model.SGDRegressor:�����ݶ��½���С���������ʧ���������Իع�ģ��
metrics.log_loss:������ʧ,�ֳ�����ʧ������ʧ
ע:linear_model.RandomizedLogisticsRegression(��������ع�)��sklearn0.21�汾�м������Ƴ�
�������漰����:
metrics.confusion_matrix:��������,ģ������ָ��֮һ
metrics.roc_auc_score:ROC����,ģ������ָ��֮һ
metrics.accuracy_score:��ȷ��,ģ������ָ��֮һ
2 linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression(penalty = ��l2��, dual = False, tol = 0.001, C = 1.0, fit_intercept = True, intercept_scaling = 1, class_weight = None, random_state = None, solver = ��warn��, max_iter = 100, multi_class = ��warn��, verbose = 0, warm_start = False, n_jobs = None)
2.1 ��Ԫ���ع����ʧ����
2.1.1 ��ʧ�����ĸ�������
��ģ����ģ���ڲ��Լ��ϵı�������,���ģ�͵�����ָ����������������ģ���ڲ��Լ��ϵı��ֵġ�Ȼ��,���ع����Ż���ѵ������������
a
\textbf{a}
a������,����ϣ��ѵ��������ģ���ܹ������ܵ����ѵ������,��ģ����ѵ�����ϵ�Ԥ��ȷ��Խ����100%Խ�á�
���,ʹ�á���ʧ�������������ָ��,����������Ϊ
a
\textbf{a}
a��ģ�����ѵ����ʱ������ѶϢ��ʧ�Ĵ�С,���Դ˺�������
a
\textbf{a}
a�������������һ�������ģ��,ģ����ѵ�����ϱ�������,������Ϊģ����Ϲ����е���ʧ��С,��ʧ������ֵ��С,�����������;�෴,���ģ����ѵ�����ϱ������,��ʧ�����ͻ�ܴ�,ģ�;�ѵ������,Ч���ϲ�,����Ҳ�ͱȽϲҲ����˵,��������
a
\textbf{a}
aʱ,����ʧ������С,��ģ����ѵ�������ϵ����Ч������,��Ԥ��ȷ�ʾ�������100%��
��ʧ����:��������
a
a
a���ӵ�����ָ��,������������Ų����Ĺ��ߡ���ʧ����С,ģ����ѵ�����ϱ�������,��ϳ��,��������;��ʧ������,ģ����ѵ�����ϱ��ֲ,��ϲ���,������⡣Ѱ���ܹ�����ʧ������С���IJ��������
ע:û�С��������������ģ��û����ʧ����,��KNN����������
���ع����ʧ�������ɼ�����Ȼ�����Ƶ�������,�����Ƶ�����:
J
(
a
)
=
?
��
i
=
1
m
(
y
i
?
l
o
g
(
y
a
(
x
i
)
)
+
(
1
?
y
i
)
?
l
o
g
(
1
?
y
a
(
x
i
)
)
J(a)=-\sum_{i=1}^{m}(y_i*log(y_a(x_i))+(1-y_i)*log(1-y_a(x_i))
J(a)=?��i=1m?(yi??log(ya?(xi?))+(1?yi?)?log(1?ya?(xi?))
����,
a
a
a��ʾ��������һ�����,
m
m
m�������ĸ���,
y
i
y_i
yi?������
i
i
i����ʵ�ı�ǩ,
y
a
(
x
i
)
y_a(x_i)
ya?(xi?)������
i
i
i�ϻ��ڲ���
a
a
a������������ع鷵��ֵ,
x
i
x_i
xi?������
i
i
i����������ȡֵ��Ŀ��������ʹ
J
(
a
)
J(a)
J(a)����
a
a
aȡֵ��ע��,�����ع�ı��ʺ���
y
(
x
)
y(x)
y(x)��,��������
x
x
x���Ա���,������
a
a
a��������ʧ������,����
a
a
a����ʧ�������Ա���,
x
x
x��
y
y
y������֪����������ͱ�ǩ,�൱������ʧ�����IJ�������ͬ�ĺ�����,�Ա����Ͳ������в�ͬ��
����ʧ��������Сֵ,��ģ����ѵ�����ϱ�������,���ܻ�����:���ģ����ѵ�����ϱ�ʾ����,ȴ�ڲ��Լ��ϱ������,ģ�;ͻ����ϡ���Ȼ���ع�����Իع�������Ƿ��ϵ�ģ��,��������Ҫ���ƹ���ϵļ�������������ģ��,�����ع��й���ϵĿ���,����ͨ��������ʵ����
2.1.2 ��Ԫ���ع���ʧ��������ѧ���͡���ʽ�Ƶ�����
2.2 ��Ҫ����penalty&C
2.2.1 ����
������������ֹģ����ϵĹ���,���õ���L1����L2��������ѡ��,�ֱ�ͨ������ʧ������
a
\textbf{a}
a��L1��ʽ��L2��ʽ�ı�����ʵ�֡�������ӵķ�ʽ,����Ϊ�������,Ҳ����Ϊ���ͷ������ʧ��������ʧ���������Ż������IJ���ȡֵ��Ȼ�ı�,�Դ�������ģ����ϵij̶ȡ�����L1������ÿ�������ľ���ֵ֮��,L2��������Ϊ���������е�ÿ��������ƽ���͵Ŀ���ֵ��
J
(
a
)
L
1
=
C
?
J
(
a
)
+
��
j
=
1
n
�O
a
j
�O
(
j
>
=
1
)
J(a)_{L1}=C*J(a)+\sum_{j=1}^n|a_j|(j>=1)
J(a)L1?=C?J(a)+��j=1n?�Oaj?�O(j>=1)
J
(
a
)
L
1
=
C
?
J
(
a
)
+
��
j
=
1
n
(
a
j
)
2
(
j
>
=
1
)
J(a)_{L1}=C*J(a)+\sqrt{\sum_{j=1}^n(a_j)^2}(j>=1)
J(a)L1?=C?J(a)+��j=1n?(aj?)2?(j>=1)
����
J
(
a
)
J(a)
J(a)����ʧ����,
C
C
C�������������̶ȵij�����,
n
n
n�Ƿ���������������,Ҳ�Ƿ����в���������,
j
j
j����ÿ������,��
j
j
jҪ���ڵ���1,����Ϊ��������
a
\textbf{a}
a��,��һ��������
a
0
a_0
a0?,�ǽؾ�,��ͨ���Dz��������ġ�
Ҳ����д��/:
J
(
a
)
L
1
=
J
(
a
)
+
1
2
b
2
��
j
�O
a
j
�O
J(a)_{L1}=J(a)+\frac{1}{2b^2}\sum_j|a_j|
J(a)L1?=J(a)+2b21?��j?�Oaj?�O
J
(
a
)
L
1
=
J
(
a
)
+
a
T
a
2
��
2
J(a)_{L1}=J(a)+\frac{a^Ta}{2��^2}
J(a)L1?=J(a)+2��2aTa?
�ڴ���������,�������dz���������,ͨ�����������������ڶ�ģ�͵ijͷ�����sklearn��,������
C
C
C������ʧ����ǰ���,ͨ��������ʧ���������Ĵ�С�����ڶ�ģ�͵ijͷ���
- penalty:�������롰l1����l2����ָ��ʹ����һ������ʽ,����дĬ�ϡ�l2����ע��:��ѡ��l1������,����solver���ܹ�ʹ����ⷽʽ��liblinear���͡�saga��,��ʹ�á�l2������,����solver�����е���ⷽʽ������ʹ�á�
- C:
C
C
C����ǿ�ȵĵ���,������һ������0�ĸ�����,����дĬ��1.0,��Ĭ������������ʧ�����ı�ֵ��1:1��
C
C
CԽС,��ʧ������ԽС,ģ�Ͷ���ʧ�����ijͷ�Խ��,����Ч��Խǿ,����
a
a
a����ѹ����Խ��ԽС��
L1����L2������Ȼ�����Կ��ƹ����,����Ч��������ͬ��������ǿ��������(�� C C C��С),���� a a a��ȡֵ����С,��L1���Ὣ����ѹ��Ϊ0,L2����ֻ���ò�������С,����ȡ��0��
��L1������ǿ�Ĺ�����,Я����Ϣ��С�ġ���ģ���ײ���������IJ���,���Я��������Ϣ�ġ���ģ���о��������IJ�������ر��0,����L1��������һ������ѡ��Ĺ���,�ƹ��˲����ġ�ϡ���ԡ���L1����Խǿ,���������о�Խ�����Ϊ0,������Խϡ��,ѡ������������Խ��,�Դ�����ֹ����ϡ����,����������ܴ�����ά�Ⱥܸ�,��������ʹ��L1��������L1�����������,���ع������ѡ�������EmbeddedǶ�뷨����ɡ���Ե�,L2�����ڼ�ǿ�Ĺ�����,�ᾡ����ÿ��������ģ�Ͷ���һЩС����,��Я����Ϣ��,��ģ���ײ���������IJ�����dz��ӽ���0��ͨ����˵,��ҪĿ����Ϊ�˷�ֹ�����,ѡ��L2�����㹻�ˡ��������ѡ��L2�����ǹ����,ģ����δ֪���ݼ��ϵ�Ч�����ֺܲ�,�Ϳ��Կ���L1�������������� C C C��ȡֵ,������ͨ��ѧϰ���������е�����
ͨ���������ع�,���۲�L1����L2���IJ��:
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
x = data.data
y = data.target
data.data.shape
#���:(569, 30)
lrl1 = LR(penalty = 'l1',solver = 'liblinear',C = 0.5,max_iter = 1000)
lrl2 = LR(penalty = 'l2',solver = 'liblinear',C = 0.5,max_iter = 1000)
#���ع����Ҫ����coef_,�鿴ÿ����������Ӧ�IJ���
lrl1 = lrl1.fit(x,y)
lrl1.coef_
#���:array([[ 4.00032682, 0.03166875, -0.1370455 , -0.01621622, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.50461921, 0. , -0.07127911, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , -0.24565067, -0.12856333, -0.01441737, 0. ,
0. , -2.04220443, 0. , 0. , 0. ]])
(lrl1.coef_ != 0).sum(axis = 1)
#���:array([10])
lrl2 = lrl2.fit(x,y)
lrl2.coef_
#���:array([[ 1.61541411e+00, 1.02300859e-01, 4.79634999e-02,
-4.45030890e-03, -9.43136469e-02, -3.01439405e-01,
-4.56192113e-01, -2.22484448e-01, -1.35800316e-01,
-1.93953254e-02, 1.60057189e-02, 8.84862500e-01,
1.19637597e-01, -9.46955296e-02, -9.82838672e-03,
-2.36327058e-02, -5.71011111e-02, -2.70319142e-02,
-2.77745541e-02, 2.15950986e-04, 1.26261246e+00,
-3.01767368e-01, -1.72676431e-01, -2.21705021e-02,
-1.73511093e-01, -8.79035647e-01, -1.16340871e+00,
-4.27935079e-01, -4.21045045e-01, -8.69853368e-02]])
��ѡ��L1����ʱ,���������IJ�����������Ϊ0,��Щ������������ģʱ,�����������ģ����,��L2�����Ƕ����������������˲�����
l1 = []
l2 = []
l1test = []
l2test = []
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
for i in np.linspace(0.05,1,19):
lrl1 = LR(penalty = 'l1',solver = 'liblinear',C = i,max_iter = 1000)
lrl2 = LR(penalty = 'l2',solver = 'liblinear',C = i,max_iter = 1000)
lrl1 = lrl1.fit(xtrain,ytrain)
l1.append(accuracy_score(lrl1.predict(xtrain),ytrain))
l1test.append(accuracy_score(lrl1.predict(xtest),ytest))
lrl2 = lrl2.fit(xtrain,ytrain)
l2.append(accuracy_score(lrl2.predict(xtrain),ytrain))
l2test.append(accuracy_score(lrl2.predict(xtest),ytest))
graph = [l1,l2,l1test,l2test]
color = ['green','black','lightgreen','gray']
label = ['L1','L2','L1test','L2test']
plt.figure(figsize = [6,6])
for i in range(len(graph)):
plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label = label[i])
plt.legend(loc = 4)#ͼ����λ��,4��ʾ���½�
plt.show()
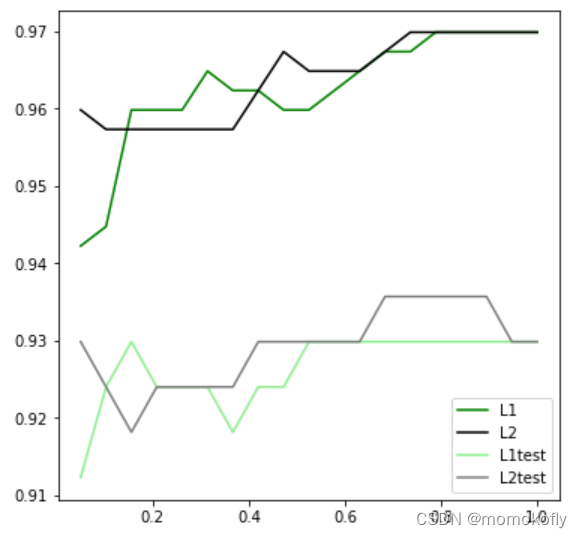
�����ٰ����ݼ���,�������Ľ������,������
C
C
C�����,����ǿ��Խ��ԽС,ģ����ѵ�����Ͳ��Լ��ϵı��ֶ�����������,ֱ��
C
=
0.8
C=0.8
C=0.8����,ѵ�����ϵı�����Ȼ���߸�,��ģ����δ֪���ݼ��ϵı��ֿ�ʼ�µ�,��ʱ�����˹���ϡ�������Ϊ,
C
C
C�趨Ϊ0.9��ȽϺá���ʵ��ʹ��ʱ,������Ĭ��ʹ��l2����,����о���ģ�͵�Ч������,�Ǿͻ�l1���ԡ�
2.2.2 ���ع��е���������
�������������ܶ��ʱ��,����ҵ����,Ҳ���ڼ������Ŀ���,ͨ�������ع��������ѡ��ѡ������ά��
- ҵ��ѡ��
��ά������ѡ��,����������ҵ����������ѡ��,���Ժͱ�ǩ�йص�������Ҫ���µġ���Ȼ,������˽�ҵ��,�����г�ǧ���������,��Ҳ����ʹ���㷨��ɸѡ��һ������,Ȼ����������������,�ٸ���ҵ��ʶ��ѡ��������������� - PCA��SVDһ�㲻��
˵����ά,�����뵽���Ǹ�Ч��ά�㷨,PCA��SVD,�������ַ��������ʱ�����������ع顣���ع��������Իع��ݱ����,���Իع��һ������Ŀ����ͨ����������̽������x���ǩy֮��Ĺ�ϵ,�����ع�Ҳ�̳����������,��Ҫͨ�����ع�Ľ�����ж���Щ��������������,�����Ҫ����������ԭò����PCA��SVD�Ľ�ά����Dz��ɽ��͵�,���һ����ά,�������������ͱ�ǩ֮��Ĺ�ϵ����Ȼ,�ڲ���Ҫ̽���������ǩ֮���ϵ������������,��ά�㷨PCA��SVDҲ�ǿ���ʹ�õġ� - ͳ�Ʒ�������ʹ��,�����Ƿdz���Ҫ
��Ȼ��ά�㷨����ʹ��,��Ҫ������ѡ�������ع�����ݵ�Ҫ��������Իع�,���ڲ���ʹ����С���˷������,�������ع�����ݵ�����ֲ��ͷ���û��Ҫ��,Ҳ����Ҫ�ų�����֮��Ĺ�����,�����ȷʵ��Ҫʹ��һЩͳ�Ʒ���,�緽�����������Ϣ�ȷ�����������ѡ��,Ҳ��û�����⡣���˷������еķ���,�������������ع��ϡ�
�������Իع���˵,���ع����Ի�Ӱ��Ƚϴ�,������Ҫʹ�÷�����˺ͷ�����������VIF(variance inflation factor)�����������ԡ��������ع����,��ʵ���Ƿdz���Ҫ,������ʱ��Ҫ��һЩ�����������������ǿģ�͵ı��֡���Ȼ,�����ͨ��������ʽ����ģ�ͱ���,����ģ���еĹ�����Ӱ����ģ��Ч��,�ǿ���������VIF��������������,����sklearn�в�û���ṩVIF���ܡ� - ��Ч��Ƕ�뷨embedded
����L1����ʹ�ò���������Ӧ�IJ���Ϊ0,���L1����������������ѡ��,���Ƕ�뷨��ģ��SelectFromModel,���Ժ�����ɸѡ����ģ��ʮ�ָ�Ч��������ע��,Ŀ���Ǿ�������ԭ�����ϵ���Ϣ,��ģ���ڽ�ά��������ϵ����Ч����������,��˲�����ѵ�������Լ�������,���������ݶ�����ģ�ͽ��н�ά��
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectFromModel
data = load_breast_cancer()
data.data.shape
#���:(569, 30)
LR_ = LR(solver = 'liblinear',C = 0.9,random_state = 420)
cross_val_score(LR_,data.data,data.target,cv = 10).mean()
#���:0.9490601503759398
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
#norm_order = 1��ʾʹ��L1��ʽ
x_embedded.shape
#���:(569, 9)
cross_val_score(LR_,x_embedded,data.target,cv = 10).mean()
#���:0.9368107769423559
��Ȼ�������������ٵ���λ��,��ģ�͵�Ч����û���½�̫��,���,���Ҫ��,��һ�����ǿ��Եġ����Ƿ������ģ�͵����Ч�����õĵ���������?
1)��һ�ֵ��ڷ���:����SelectFromModel���еIJ���threshold,����Ƕ�뷨����ֵ,��ʾɾ�����в����ľ���ֵ���������ֵ��������thresholdĬ��ΪNone,����SelectFromModelֻ����L1���Ľ����ѡ������,��ѡ��������L1���������Ϊ0��������ֻҪ����threshold��ֵ(����threshold��ѧϰ����),�Ϳ��Թ۲����ͬ��threshold��ģ�͵�Ч����α仯��
fullx = []
fsx = []
threshold = np.linspace(0,(LR_.fit(data.data,data.target).coef_).max(),20)
k = 0
for i in threshold:
x_embedded = SelectFromModel(LR_,threshold = i,norm_order = 1).fit_transform(data.data,data.target)
fullx.append(cross_val_score(LR_,data.data,data.target,cv = 5).mean())
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv = 5).mean())
print((threshold[k],x_embedded.shape[1]))
k += 1
plt.figure(figsize=[20,5])
plt.plot(threshold,fullx,label = 'full')
plt.plot(threshold,fsx,label = 'feature selection')
plt.xticks(threshold)
plt.legend()
plt.show()
#���:
(0.0, 30)
(0.10649103899794485, 17)
(0.2129820779958897, 12)
(0.3194731169938345, 11)
(0.4259641559917794, 8)
(0.5324551949897243, 8)
(0.638946233987669, 6)
(0.7454372729856139, 5)
(0.8519283119835588, 5)
(0.9584193509815037, 5)
(1.0649103899794485, 5)
(1.1714014289773933, 4)
(1.277892467975338, 2)
(1.384383506973283, 2)
(1.4908745459712278, 2)
(1.5973655849691728, 1)
(1.7038566239671176, 1)
(1.8103476629650623, 1)
(1.9168387019630073, 1)
(2.023329740960952, 1)
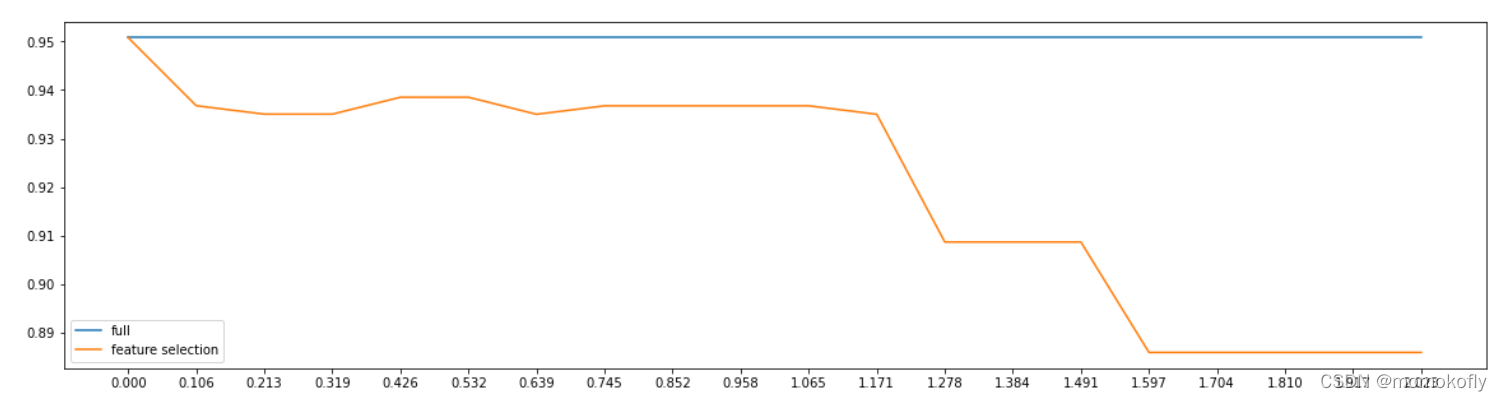
Ȼ�����ַ����ڸ����ݼ�������Ч�ġ���Ϊ��thresholdԽ��Խ��,��ɾ��������Խ��Խ��,ģ�͵�Ч��Խ��Խ��,ģ����õ��������Ҫ��֤��17�����ϵ�����,��ϸ����ѧϰ������ʾ,���Ҫ��֤ģ�͵�Ч���Ƚ�άǰ����,��Ҫ����25������,�����ʵ���������,��һ����Ч�Ľ�ά:��άǰ���������������,������ͨ����ά�����ܺõ����������Ľ��͡�
2)�ڶ��ֵ��ڷ���:�������ع����LR_,ͨ����C��ѧϰ������ʵ��:
fullx = []
fsx = []
C = np.arange(0.01,10.01,0.5)
for i in C:
LR_ = LR(solver = 'liblinear',C = i,random_state = 420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv = 10).mean())
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv = 10).mean())
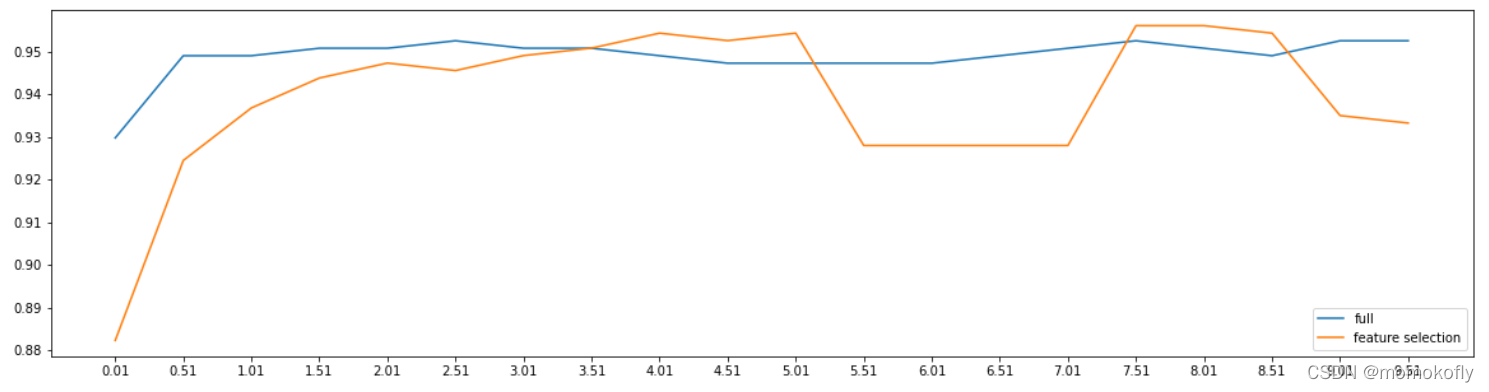
print(max(fsx),C[fsx.index(max(fsx))])
#���:0.9561090225563911 7.51
plt.figure(figsize = [20,5])
plt.plot(C,fullx,label = 'full')
plt.plot(C,fsx,label = 'feature selection')
plt.xticks(C)
plt.legend()
plt.show()
fullx = []
fsx = []
C = np.arange(7.01,8.01,0.005)
for i in C:
LR_ = LR(solver = 'liblinear',C = i,random_state = 420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv = 10).mean())
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv = 10).mean())
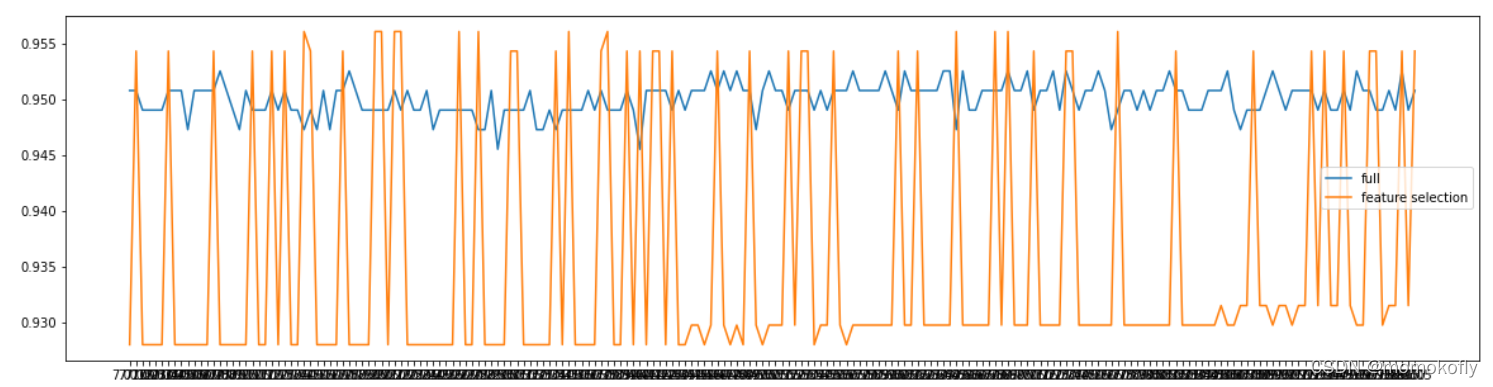
print(max(fsx),C[fsx.index(max(fsx))])
#���:0.9561090225563911 7.144999999999997
plt.figure(figsize = [20,5])
plt.plot(C,fullx,label = 'full')
plt.plot(C,fsx,label = 'feature selection')
plt.xticks(C)
plt.legend()
plt.show()
LR_ = LR(solver = 'liblinear',C = 7.144999999999997,random_state = 420)
cross_val_score(LR_,data.data,data.target,cv = 10).mean()
#���:0.9473057644110275
LR_ = LR(solver = 'liblinear',C = 7.144999999999997,random_state = 420)
x_embedded = SelectFromModel(LR_,norm_order = 1).fit_transform(data.data,data.target)
cross_val_score(LR_,x_embedded,data.target,cv = 10).mean()
#���:0.9561090225563911
x_embedded.shape
#���:(569, 9)
��ʱ��ʵ����������ѡ���ǰ����,����ģ����ϵĸ�Ч����Ȼ,����Ƕ�뷨֮��,ϵ���ۼӷ����߰�װ��Ҳ����ʹ�á�
- �Ƚ��鷳��ϵ���ۼӷ�
ϵ���ۼӷ���ԭ���dz���,coef_��Ȼ���ص���������ϵ��,����ϵ���Ĵ�С�;������е�feature_importances_�Լ���ά�㷨�еĿɽ����Է���explained_variance_��������,���Ǻ�����������Ҫ�̶Ⱥ��ȵġ���PCA��,ͨ�������ۻ��ɽ����Է������������ѡ����,�����ع�����ʵҲ����,�������ع�Ҳ�����Ƶ�:�ҳ�������������ƽ����ת�۵�,ת�۵�֮ǰ���ۼӵ�����������Ҫ��,ת��֮��IJ���Ҫ���������ַ�����ԱȽ��鷳,��ΪҪ�ȶ�����ϵ�����дӴ�С������,��Ҫȷ��֪��������ÿ��ϵ����Ӧ��ԭʼ������λ��,������ȷ�ҳ���Ҫ�����������ʹ�������ķ���,����ֱ��ʹ��Ƕ�뷨���÷��㡣 - ���ٵİ�װ��
��Ե�,��װ������ֱ���趨��Ҫ����������,���ع�����ʵ������ʱ,���ܻ��С���Ҫ5-8����������������,��װ����ʱ�ͱȽϷ����ˡ��������ع�İ�װ����ʹ�ú������㷨һ��,���������ر�֮����
2.3 �ݶ��½�:��Ҫ����max_iter
���ع����ѧĿ��������ܹ���ģ�����Ż�,��ϳ̶���õIJ��� a a a��ֵ,������ܹ�����ʧ���� J ( a ) J(a) J(a)��С���� a a aֵ�����ڶ�Ԫ���ع���˵,�ж��ַ����������������� a a a,��������ݶ��½���(Gradient Descent)�������½���(Coordinate Descent)��ţ�ٷ�(Newton-Raphson method)��,�������ݶ��½�����Ϊ����,ÿ�ַ��������漰���ӵ���ѧԭ��,����Щ������ִ�е����������Ƶġ�
2.3.1 �ݶ��½�������ع�
��������Ҳ��õ��ݶ��½���Ϊ����
**��sklearn�����ع����max_iter,�������ݶ��½����ߵ������,��������������**����,�ݶ��½���ʵ�������ڶ�����Ŀ���ȡֵ�б���,һ�δ�����������ݶ�����,��������ʧ������ȡֵ
J
J
J�ƽ���Сֵ,�ٷ��������Сֵ��Ӧ�IJ���ȡֵ�Ĺ��̡�
2.3.2 �ݶ��½��ĸ�������
�����ݶ��½���������ʧ�����϶���ʧ�����������Ա���(���ع�Ԥ�⺯���IJ���)��ƫ����
�����ع���,��ʧ����Ϊ:
J
(
a
)
=
?
��
i
=
1
m
(
y
i
?
l
o
g
(
y
a
(
x
i
)
)
+
(
1
?
y
i
)
?
l
o
g
(
1
?
y
a
(
x
i
)
)
J(a)=-\sum_{i=1}^{m}(y_i*log(y_a(x_i))+(1-y_i)*log(1-y_a(x_i))
J(a)=?��i=1m?(yi??log(ya?(xi?))+(1?yi?)?log(1?ya?(xi?))
����������ϵ��Ա���
a
\textbf{a}
a��ƫ��,�Ϳ��Եõ��ݶ������ڵ�
j
j
j��
a
a
a��������ϵı�ʾ��ʽ:
d
j
=
��
i
=
1
m
(
y
a
(
x
i
)
?
y
i
)
x
i
j
d_j=\sum_{i=1}^m(y_a(x_i)-y_i)x_{ij}
dj?=��i=1m?(ya?(xi?)?yi?)xij?
�������ʽ��,ֻҪ����һ��
a
\textbf{a}
a��ȡֵ
a
j
\textbf{a}_j
aj?,�ٴ�����������
x
x
x,�Ϳ��������һ��
a
\textbf{a}
aȡֵ�µ�Ԥ����
y
a
(
x
i
)
y_a(x_i)
ya?(xi?),�����ʵ��ǩ����
y
y
y,�Ϳ��Ի����һ��
a
j
\textbf{a}_j
aj?ȡֵ�µ��ݶ�����,���С��ʾΪ
d
j
d_j
dj?��Ŀ����Ҫ�ڿ��ܵ�
a
\textbf{a}
aȡֵ�Ͻ��б���,һ�δμ����ݶ�����,�����ݶ������ķ���������ʧ����
J
J
J�½�����Сֵ�������������,
a
\textbf{a}
a���ݶ������Ĵ�С
d
d
d����ϸı�,������
a
\textbf{a}
a�Ĺ��̿�������Ϊ:
a
j
+
1
=
a
j
?
��
?
d
j
=
a
j
?
��
?
��
i
=
1
m
(
y
a
(
x
i
)
?
y
i
)
x
i
j
a_{j+1}=a_j-\alpha*d_j=a_j-\alpha*\sum_{i=1}^m(y_a(x_i)-y_i)x_{ij}
aj+1?=aj??��?dj?=aj??��?��i=1m?(ya?(xi?)?yi?)xij?
����
a
j
+
1
\textbf{a}_{j+1}
aj+1?�ǵ�
j
j
j�����IJ�������,
a
j
\textbf{a}_j
aj?�ǵ�
j
j
j����IJ�������,
��
\alpha
������Ϊ����,������ÿ��һ��(ÿ����һ��)��
a
a
a�ı仯,���Դ���Ӱ��ÿ�ε�������ݶ������Ĵ�С�ͷ���
2.3.3 �����ĸ�������
���������κ���������,�����������ݶ��½��������κξ����ֱ�ӱ仯,�����ݶ������Ĵ�С
d
d
d�ϵı���,Ӱ���Ų�������
a
a
aÿ�ε�����ı�IJ��֡�
��Ȼ���������ǿ��ݶ������Ĵ�С
d
d
d*����
��
\alpha
����ʵ�ֵ�,��
J
(
a
)
J(a)
J(a)�Ľ������ǿ�����
a
\textbf{a}
a��ʵ�ֵ�,���Բ������Ե�����ʧ�����½������ʡ�����ʧ�������͵ķ�����,����Խ��,
a
\textbf{a}
a�ı䶯��Խ����Ե�,��������ܶ�,
a
\textbf{a}
a��ÿ�α䶯�ͺ̡ܶ������˵,�������̫��,��ʧ�����½��þͷdz���,��Ҫ�ĵ��������ͺ���,���ݶ��½����̿���������ʧ��������͵�,����ȡ����ֵ��������̫С,��Ȼ�������ƽ���Ҫ����͵�,���������ٶ�ȴ�ܻ���,������������Ҫ�ܶࡣ
��sklearn��,���ò���max_iter���������������沽��,�Կ���ģ�͵ĵ����ٶȲ���ʱ����ģ��ͣ��,max_iterԽ��,��������ԽС,ģ�͵���ʱ��Խ��,��֮,������������úܴ�,ģ�͵���ʱ��̡ܶ�
��������,��ȡ��
J
(
a
)
J(a)
J(a)����Сֵ��,�Ϳ����ҳ���Сֵ��Ӧ�IJ�������
a
\textbf{a}
a,���ع��Ԥ�⺯��Ҳ�Ϳ��Ը��������������
a
\textbf{a}
a��������
�������ٰ����ݼ���,max_iter��ѧϰ����Ϊ:
l2 = []
l2test = []
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
for i in np.arange(1,201,10):
lrl2 = LR(penalty = 'l2',solver = 'liblinear',C = 0.9,max_iter = i)
lrl2 = lrl2.fit(xtrain,ytrain)
l2.append(accuracy_score(lrl2.predict(xtrain),ytrain))
l2test.append(accuracy_score(lrl2.predict(xtest),ytest))
graph = [l2,l2test]
color = ['black','gray']
label = ['L2','L2test']
plt.figure(figsize = [20,5])
for i in range(len(graph)):
plt.plot(np.arange(1,201,10),graph[i],color[i],label = label[i])
plt.legend(loc = 4)
plt.xticks(np.arange(1,201,10))
plt.show()
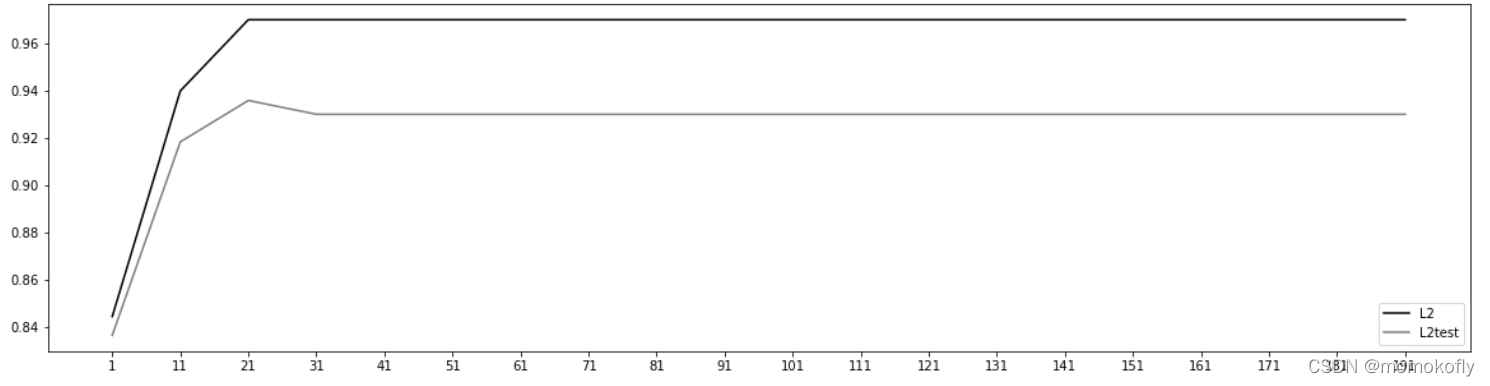
#����ʹ������.n_iter_�����ñ������������ʵ�ֵĵ�������
lr = LR(penalty = 'l2',solver = 'liblinear',C = 0.9,max_iter = 300).fit(xtrain,ytrain)
lr.n_iter_
#���:array([24], dtype=int32)
��max_iter�����ƵIJ����Ѿ�����,���ع�ȴ��û���ҵ���ʧ��������Сֵ,���� a a a��ֵ��û�б�����,sklearn�ͻᵯ����ɫ�ľ���:
lr = LR(penalty = 'l2',solver = 'liblinear',C = 0.9,max_iter = 10).fit(xtrain,ytrain)
lr.n_iter_
������solver = ��liblinear��:

������solver = ��sag��:

��Ȼд����ͬ,����ʵ����һ������:����û������,��Ҫ����max_iter����������֡���Ҳ��һ��Ҫ��ȫ������ֺ�ɫ���档max_iter�ܴ�,��ζ�Ų�����,ģ�����еû���ӻ�������Ȼ���ݶ��½����������ʧ������Сֵ,����Ҳ������ζ��ģ�ͻ�����(��ѵ�����ϱ��ֵ�̫��,�ڲ��Լ���ȴ��һ��),���,���max_iter�������������,ģ�͵�ѵ����Ԥ��Ч�����Ѿ�������,�ǾͲ���Ҫ������max_iter�е���Ŀ�ˡ�
2.4 ��Ԫ�ع����Ԫ�ع�:��Ҫ����solver&multi_class
sklearn�ṩ�˶��ֿ���ʹ�����ع鴦������������ѡ�����,����ij�ַ������Ͷ�����1,����ķ������Ͷ�����0,�͡�����Ԥ�������еĶ�ֵ����˼ά����,���ַ�������Ϊ��һ�Զࡱ(One-vs-rest),���OvR����sklearn�б�ʾΪ��ovr��;���߰Ѻü����������ͻ�Ϊ1,ʣ�µļ����������ͻ�Ϊ0,����һ�֡���Զࡱ(Many-vs-Many)�ķ���,���MvM,��sklearn�б�ʾΪ��multinominal����ÿ�ַ�ʽ�����L1��L2��������ʹ�á�
��sklearn��,ʹ�ò���multi-class������ģ��,Ԥ���ǩ�Ǻ������͡����롰ovr������multinominal������auto������ʾ��ͬ����,Ĭ��Ϊ��ovr��(Ĭ��ֵ��sklearn��0.22�汾�дӡ�ovr������Ϊ��auto��)����ovr����ʾ���������Ƕ�����,����ģ��ʹ�á�һ�Զࡱ����ʽ��������������;��multinominal����ʾ�������������,���������ڲ���solver�ǡ�liblinear��ʱ������;��auto����ʾ��������ݵķ������������������ȷ��ģ��Ҫ�����ķ�����������͡�
�ݶ��½���ֻ��������ع����
a
a
a��һ�ַ���,sklearn�ṩ�˶���ѡ��,����ʹ�ò�ͬ����������������ع顣�������ѡ��,�ɲ�����solver������,��������ѡ�����С�liblinear���Ƕ�����ר��,Ҳ�����ڵ�Ĭ���������(�����л�ɫ��Ԫ���ʾȱ��)
���β�����ݼ�Ϊ��,�۲�multinominal��ovr������:
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
for multi_class in ("multinomial","ovr"):
lr = LogisticRegression(solver = 'sag',max_iter = 100,random_state = 42,multi_class = multi_class).fit(iris.data,iris.target)
#��ӡ����multi_classģʽ�µ�ѵ������
#%���÷�,��%�������ӡ���ַ�����,���ɱ����滻�IJ��֡�%.3f��ʾ,��������С���ĸ�������%s��ʾ,�ַ�����
#�ַ������%��ʹ��Ԫ�������ɱ���,�ַ������м���%,Ԫ���о���Ҫ�м���������
print("training score : %.3f (%s) " % (lr.score(iris.data,iris.target),multi_class))
#���:training score : 0.987 (multinomial)
# training score : 0.960 (ovr)
2.5 ������ƽ�������class_weight
������ƽ����ָ��һ�����ݼ���,��ǩ��һ������ռ�кܴ�ı���,�������Ĵ��ۺܸߡ���Ҫ��DZ�ڷ����ߺ���ͨ�˽��з���,�Լ�����Ҫ�ж�һ���¿ͻ��Ƿ��ΥԼ�������Ҫʹ�ò���class_weight��������ǩ����һ���ľ���,�������ı�ǩ�����Ȩ��,��ģ��ƫ����������,��������ķ���ģ���ò���Ĭ��ΪNone,��ģʽ��ʾ�Զ��������ݼ��е����б�ǩ��ͬ��Ȩ��,���Զ�1:1���������Ĵ��ۺܸߵ�ʱ��,ʹ�á�balance��ģʽ,ֻ��ϣ���Ա�ǩ���о����ʱ��,ʲô������Ϳ��Խ���������������⡣
���Ƕ���sklearn���еIJ���class_weight,�����ҳ��������������ģ������,������ѧϰ����������������Ч��,��˷dz���ʹ�á��д�������������ĸ��ַ���,�����������Dz�����,��ͨ���ظ������ķ�ʽ��ƽ���ǩ,���Խ����ϲ���(���������������),��SMOTE,�����²���(���ٶ����������)���������ع���˵,�ϲ�������õķ�����
3 ����:�����ع��������ֿ�
�����н��������,���ֿ���һ���Է�����ʽ������һ���ͻ������÷��մ�С���ֶ�,����������˽�Ǯ����(������,��Ҫ���ʵĹ�˾)�����������к�ͬ�еĻ�����Ϣ����,���ý�Ǯ�����˵���(������,����)������ɾ�����ʧ�Ŀ����ԡ�һ����˵,���ֿ�����ķ���Խ��,�ͻ�������Խ��,����ԽС��
������˽�Ǯ���ˡ������Ǹ���,������������Ĺ�˾����ҵ��������ҵ����,�������������������;�ֱ�ʹ����ҵ����ģ�͡��ֽ�������ģ�͡���Ŀ����ģ�͵�ģ�͡����ڸ�����˵,�С����ſ������жϸ��˵����ó̶�:A����B����C����F������˵�ġ����ֿ�������ָA��,�ֳ�Ϊ����������ģ��,��Ҫ�������������û�����������,���жϽ��ڻ����Ƿ�Ӧ�ý�Ǯ��һ�����û�,�������˵ķ���̫��,���Ծܾ����
һ��������ģ�Ϳ���,��Ҫ���µ�����:

�Ը����������������Ϊ��,����A���Ľ�ģ���������̡�������Ҫ���ܡ�������ϴ���͡�ģ�Ϳ�������
3.1 ����,��ȡ����
ʹ�õ����ݼ���kaggle�е�give me some credit���ݼ�
%matplotlib inline
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
data = pd.read_csv(r"C:\Users\86188\Desktop\coding\Kaggle-give me some credit\Give_me_some_credit_Data_cs-training.csv",index_col = 0)
��Ҫ�˽�ÿ��ָ����������ֺ���,ͨ��,�������dz����ʱ��,һ����ȥ�˽�Ҫ���ܶ�ʱ��,������������ܶ�,����������ά��
3.2 ̽������������Ԥ����
��һ��Ҫ�˽���������Ĵ�����,��鿴ȱʧֵ�������Ƿ�ͳһ���Ƿ��ʺ����Ʊ����ȵȡ���ʵ���ݵ�̽��������Ԥ������������ȫ�ֿ���,��һ��Ҫ�����ĸ���
#�۲���������
data.head()
#�۲����ݽṹ
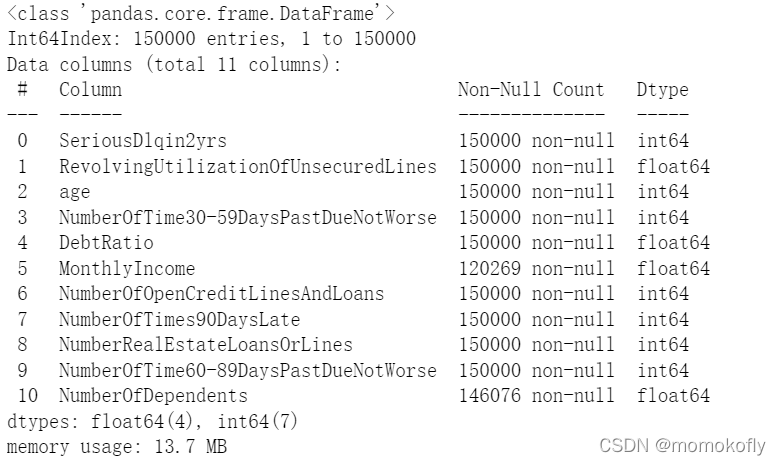
data.shape
#���:(150000, 11)
data.info()

3.2.1 ȥ���ظ�ֵ
��ʵ����,����������ҵ����,���ܻ���ڵ�һ��������������ظ�,���г���һ�е���������ʾ������������һ������ʱ������ϵͳ¼���ظ�,��ʱ��������Ϊ�����ظ�,��֮��������ݽ���ȥ�ش�������Ȼ�п��ܳ�����������������һģһ��,�����ֿ���������,����������ҵ���ݾ����Ǽ��ٸ�����,������ij����˼��˵����,Ҳ���ܵ�����������Ϣ��ʧ,����¼�����ظ�ֵ��ȥ��
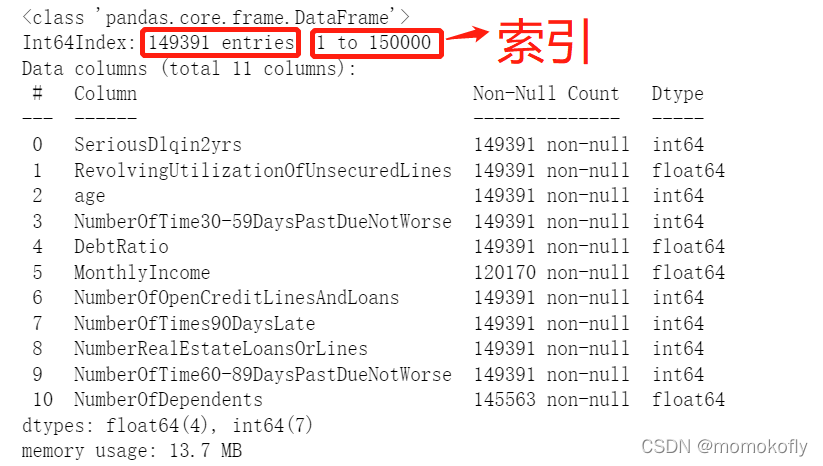
#ȥ���ظ�ֵ
data.drop_duplicates(inplace = True)
data.info()
#ɾ��֮��,��Ҫ�ָ�����
data.index = range(data.shape[0])
data.info()

3.2.2 �ȱʧֵ
#̽��ȱʧֵ
data.info()
data.isnull().sum()/data.shape[0]
#data.insull().mean()
#���:
SeriousDlqin2yrs 0.000000
RevolvingUtilizationOfUnsecuredLines 0.000000
age 0.000000
NumberOfTime30-59DaysPastDueNotWorse 0.000000
DebtRatio 0.000000
MonthlyIncome 0.195601
NumberOfOpenCreditLinesAndLoans 0.000000
NumberOfTimes90DaysLate 0.000000
NumberRealEstateLoansOrLines 0.000000
NumberOfTime60-89DaysPastDueNotWorse 0.000000
NumberOfDependents 0.025624
dtype: float64
����ȱʧֵ�������ǡ�MonthlyIncome���͡�NumberOfDependents������NumberOfDependents��ȱʧ��������,��ȱʧ�˴�Լ2.56%,���Կ���ֱ��ɾ��,����ʹ�þ�ֵ�������MonthlyIncome��ȱʧ�˼���20%,������һ����Ҳ��Ӱ���������ֵ���Ҫ����,���,�����������Ҫ�����������ʹ�þ�ֵ�����NumberOfDependents����
data["NumberOfDependents"].fillna(data["NumberOfDependents"].mean(),inplace = True)
#���ѡ��ɾ��ȱʧֵ���ڵ���,�ǵûָ�����
data.info()
#���:
SeriousDlqin2yrs 0.000000
RevolvingUtilizationOfUnsecuredLines 0.000000
age 0.000000
NumberOfTime30-59DaysPastDueNotWorse 0.000000
DebtRatio 0.000000
MonthlyIncome 0.195601
NumberOfOpenCreditLinesAndLoans 0.000000
NumberOfTimes90DaysLate 0.000000
NumberRealEstateLoansOrLines 0.000000
NumberOfTime60-89DaysPastDueNotWorse 0.000000
NumberOfDependents 0.000000
dtype: float64
��������������˵,���������ƶ�:һ����Ǯ����Ӧ���ǻ�֪��,�������롱���ߡ��ȶ����롱���Լ����Ի��������������е�һ������,��������ȶ����õ���,�϶���������д���Լ����������,��ô��Щ��MonthlyIncome������ֵȱʧ����,������������״̬���ȶ�������Ƚϵ͵��ˡ����������ж�,�������ķ�λ�����ȱʧֵ,�����С�MonthlyIncome���ֶ�ֵΪ�յĿͻ��������ǵ�������Ⱥ����Ȼ,��ЩȷʵҲ���������������ռ������е�ʧ��,�����ж�Ϊʲô��������ȱʧ,�������ϵ��ƶ�Ҳ�����Dz���ȷ�ġ��������ʲô�ֶ��ȱʧֵ,Ҫ��ҵ����Ա��ͨ,�۲�ȱʧֵ����β����ġ�����ʹ�����ɭ�����MonthlyIncome����
���ɭ�����á���Ȼ������A��B��CԤ��Z,Ҳ����ʹ��A��C��ZԤ��B����˼�����ȱʧֵ������һ����n��������������˵,��������T��ȱʧֵ,�Ͱ�����T������ǩ,������n-1��������ԭ���ı�ǩ����µ����������Ƕ���T��˵,��û��ȱʧ�IJ���,����Y_train,�ⲿ�����ݼ��б�ǩҲ������,����ȱʧ�IJ���,ֻ������û�б�ǩ,������ҪԤ��IJ��֡�
����T��ȱʧ��ֵ��Ӧ������n-1������+�����ı�ǩ:X_train
����T��ȱʧ��ֵ:Y_train
����Tȱʧ��ֵ��Ӧ������n-1������+�����ı�ǩ:X_test
����Tȱʧ��ֵ:δ֪,����ҪԤ���Y_predict
��������,����ijһ����������ȱʧ,��������ȴ�����������,�dz����á�������дһ���ܹ���κ��еĺ���,��һ��ֻ���һ��:
def fill_missing_rf(x,y,to_fill):
"""
ʹ�����ɭ���һ��������ȱʧֵ�ĺ���
����:
x:Ҫ�����������
y:�����ġ�û��ȱʧֵ�ı�ǩ
to_fill:�ַ���,Ҫ�����һ�е�����
"""
#����������������±�ǩ
df = x.copy()
fill = df.loc[:,to_fill]
df = pd.concat([df.loc[:,df.columns != to_fill],pd.DataFrame(y)],axis = 1)
#�ҳ�ѵ�����Ͳ��Լ�
ytrain = fill[fill.notnull()]
ytest = fill[fill.isnull()]
xtrain = df.iloc[ytrain.index,:]
xtest = df.iloc[ytest.index,:]
#�����ɭ�ֻع����ȱʧֵ
from sklearn.ensemble import RandomForestRegressor as rfr
rfr = rfr(n_estimators = 100)
rfr = rfr.fit(xtrain,ytrain)
ypredict = rfr.predict(xtest)
return ypredict
�������ݼ���Ӧ�IJ������뺯����
x = data.iloc[:,1:]
y = data["SeriousDlqin2yrs"]
#y = data[:,0]
x.shape
#���:(149391, 10)
y_pred = fill_missing_rf(x,y,"MonthlyIncome")
y_pred
#���:array([0.13, 0.38, 0.13, ..., 0.22, 0.13, 0. ])
#ȷ�Ͻ������֮��,���Խ����ݸ���
data.loc[data.loc[:,"MonthlyIncome"].isnull(),"MonthlyIncome"] = y_pred
data.info()

3.2.3 ������ͳ�ƴ����쳣ֵ
��ʵ������Զ������һЩ�쳣ֵ,����Ҫȥ������,Ȼ��۲������ʡ�ע��:�쳣ֵ�ܶ�ʱ��ȴ���ص��о������ճ������쳣ֵ,ʹ������ͼ����KaTeX parse error: Undefined control sequence: \lsigma at position 2: 3\?l?s?i?g?m?a?�������ҵ��쳣ֵ(��Ҫ�������۾���,����ҵ������,��Ҫע�ط���)����������������,ϣ���ų��ġ��쳣ֵ������һЩ�����߳��͵�����,����һЩ�����ϳ���������,�����벻��Ϊ����,����һ������ˮƽ������ȴ�Ǻ�����,���Դ��ڡ����������ҵ��,������ʹ����ͨ��������ͳ�����۲����ݵ��쳣��������ݵķֲ������ע��,���ַ���ֻ��������������������½���,����м��ٸ����������ɹ���ά��������ѡ����Ч,������ 3 �� 3\sigma 3���ȽϺá�
#������ͳ��
data.describe([0.01,0.1,0.25,0.5,0.75,0.9,0.99]).T
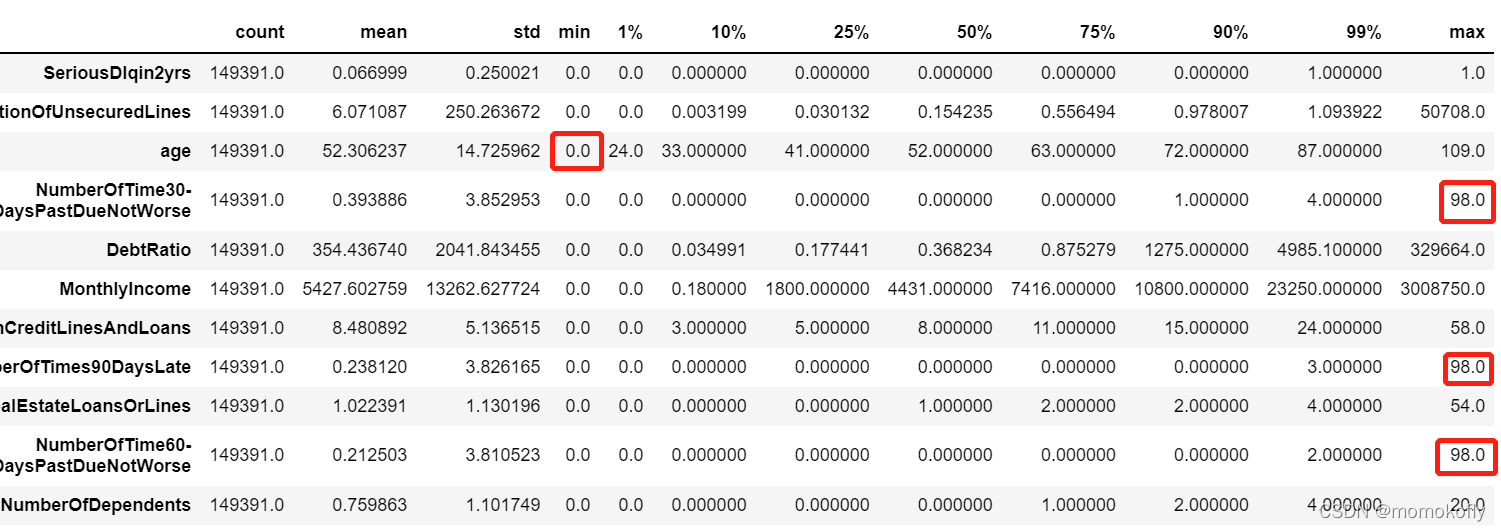
#�쳣ֵ���۲쵽,�������Сֵ��Ȼ��0,����Ȼ���������е�ҵ������,�����Ƕ�ͯ�˻�ҲҪ����8��,��˿��Բ鿴����Ϊ0�����ж���
(data["age"] == 0).sum()
#���:1
#����ֻ��һ��������Ϊ0,�����ж���϶���¼��ʧ����ɵ�,���Ե���ȱʧֵ����,ֱ��ɾ���������
data = data[data["age"] != 0]
"""
����,������ָ�꿴���������:
"NumberOfTime30-59DaysPastDueNotWorse"
"NumberOfTime60-89DaysPastDueNotWorse"
"NumberOfTimes90DaysLate"
������ָ��ֱ��ǡ���ȥ�����ڳ���35-59�����ڵ���û�з�չ�ĸ����Ĵ�����,����ȥ�����ڳ���60-89�����ڵ���û�з�չ�ĸ����Ĵ�����,����ȥ�����ڳ���90�����ڵĴ�������������ָ��,��99%�ķֲ���ʱ����Ȼ��2,���ֵȴ��98,�������dz���֡�һ�����ڹ�ȥ����������35-59��98��,һ��6��60��,����������98����������ʵ��
������ѯҵ����Ա,������ڴ�������μ���ġ�������ָ����������,��ô������������98�εĿͻ����ǻ��ͻ���������ѯ�����ǵ������,�Ȳ鿴һ���ж����������������쳣��
"""
#data[data.loc[:,"NumberOfTimes90DaysLate"] > 90]
data[data.loc[:,"NumberOfTimes90DaysLate"] > 90].count()
#��� :
#SeriousDlqin2yrs 225
#RevolvingUtilizationOfUnsecuredLines 225
#age 225
#NumberOfTime30-59DaysPastDueNotWorse 225
#DebtRatio 225
#MonthlyIncome 225
#NumberOfOpenCreditLinesAndLoans 225
#NumberOfTimes90DaysLate 225
#NumberRealEstateLoansOrLines 225
#NumberOfTime60-89DaysPastDueNotWorse 225
#NumberOfDependents 225
#dtype: int64
#��225�����������������,����ͨ������Щ�����Ĺ۲�,��ǩ��������1,Ҳ�Ͳ������ǻ��ͻ������,���������ж�,��Щ������ij���쳣,Ӧ��ɾ��
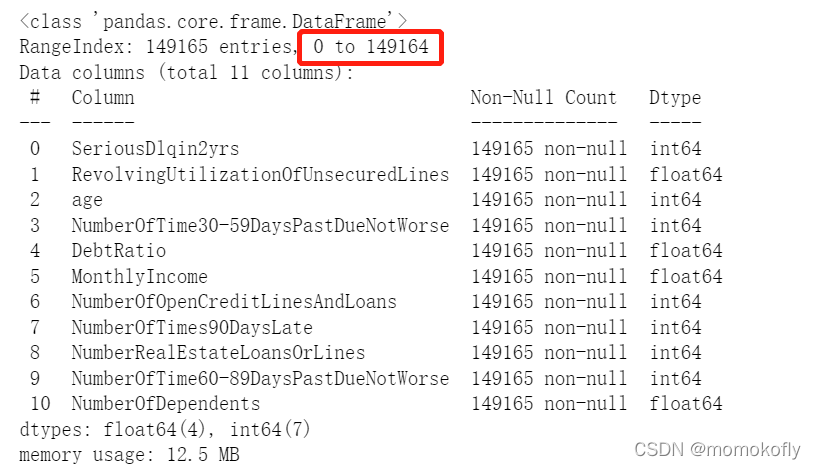
data = data[data.loc[:,"NumberOfTimes90DaysLate"] < 90]
#�ָ�����
data.index = range(data.shape[0])
data.info()
3.2.4 Ϊʲô��ͳһ����,Ҳ���������ݷֲ�?
��������ͳ�ƽ����,���Թ۲쵽�����������Բ�ͳһ,���Ҵ���һ���ּ�ƫ�ķֲ�,��Ȼ���ع�û�зֲ�Ҫ��,����������ݷ�����̬�ֲ��Ļ�,�ݶ��½����������ø��졣�����ﲻ���б�������,Ҳ����������ͳһ,��Ҫ����Ϊ:
�����㷨��ʲô���Ĺ涨����ͳ��ѧ����ʲô����Ҫ��,����Ŀ�Ķ���ҪΪҵ������������ֿ�����Ҫ�����ݽ��С��ֵ���,������20-30��Ϊһ��,����30-50��Ϊһ��,������1w����Ϊһ��,5000-1wΪһ��,ÿ���ķ�����ͬ��һ��������ͳһ����,���߱���֮��,���ݴ�С�ͷ�Χ����ı�,ͳ�ƽ��Ư����,���Ƕ���ҵ����Ա��˵,������ȫ������,�������������0.00328-0.00467֮��Ϊһ����ʲô���塣����,�¿ͻ���д����Ϣ,�����������ٲ�ͳһ�ġ���Ȼ���Խ����е���Ϣ¼��֮��,ͳһ���б���,Ȼ�����㷨����,���������䵽ҵ����Ա����ȥ�жϵ�ʱ��,���ǿ�����ȫ������Ϊʲô¼�����Ϣ�����һ��ͳ���Ϻ�����ʵ���ϸ��������������֡�
���,����ҵ��Ҫ��,���������ֿ���ʱ��,Ҫ�����������ݵ�ԭò,�������8-110������,������Ǵ���0,���ֵ���������������,�������ٲ�ͳһ,Ҳ����Ҫ�����ݽ��б���������
3.2.5 ��������������
x = data.iloc[:,1:]
y = data.iloc[:,0]
y.value_counts()
#���:
#0 139292
#1 9873
#Name: SeriousDlqin2yrs, dtype: int64
n_sample = x.shape[0]
n_1_sample = y.value_counts()[1]
n_0_sample = y.value_counts()[0]
print('��������:{};1ռ{:.2%};0ռ{:.2%}'.format(n_sample,n_1_sample/n_sample,n_0_sample/n_sample))
#���:��������:149165;1ռ6.62%;0ռ93.38%
���Կ���,�������ز�����,ʵ��ΥԼ���˲����ࡣ�������в������һ���Ӵ������л�ΥԼ�Ķ���,�ܶ����ǻỹǮ��,ֻ�������˻�����,�ܶ����Dz�Ը��ǷǮ��,���ǵ�ʱ����ʽ���ת����,���Է�������,��һ����Ǯ�ͻ��Ǯ���ϡ�����������˵,���ֻҪ�ܹ���Ǯ����,��Ը����,��Ϊ����ͻ�������(��Ϣ)�����,����������Ҫ�б��������ʵ�ǡ�����ΥԼ������,���ⲿ���˷dz��dz���,�����ͻ���ֲ�ƽ��������Ҳ������ҵ��ģ��һ��ʹ��:��Զϣ�����������ࡣ
���ع���ʹ���������ϲ���������ƽ������:
import imblearn
#�������,���Ȱ�װ:pip install imblearn
#imblearn��ר������������ƽ�����ݼ��Ŀ�,�ڴ���������ƽ�����������ܸ߹�sklearn�ܶ�
#imblearn����Ҳ��һ��������,Ҳ��Ҫ����ʵ����,fit���,��sklearn�÷�����
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state = 42)#ʵ����
x, y = sm.fit_resample(x, y)#�����Ѿ��ϲ�����Ϲ������������ͱ�ǩ
#fit_sample����DataFrame(����),fit_resample����Series����
n_sample_ = x.shape[0]
n_1_sample_ = y.value_counts()[1]
n_0_sample_ = y.value_counts()[0]
print('��������:{};1ռ{:.2%};0ռ{:.2%}'.format(n_sample_,n_1_sample_/n_sample_,n_0_sample_/n_sample_))
#���:��������:278584;1ռ50.00%;0ռ50.00%
3.2.6 ��ѵ�����Ͳ��Լ�
from sklearn.model_selection import train_test_split
x = pd.DataFrame(x)
y = pd.DataFrame(y)
x_train,x_vali,y_train,y_vali = train_test_split(x,y,test_size = 0.3)
model_data = pd.concat([y_train,x_train],axis = 1)
model_data.index = range(model_data.shape[0])
model_data.columns = data.columns
vali_data = pd.concat([y_vali,x_vali],axis = 1)
vali_data.index = range(vali_data.shape[0])
vali_data.columns = data.columns
model_data.to_csv(r"C:\Users\86188\Desktop\coding\Kaggle-give me some credit\model_data.csv")
vali_data.to_csv(r"C:\Users\86188\Desktop\coding\Kaggle-give me some credit\mvali_data.csv")
3.3 ����
Ҫ�������ֿ�,��Ҫ�������������зֵ�,�Ա�ҵ����Ա�ܹ������¿ͻ���д����ϢΪ�¿ͻ����д�֡���������ֿ�����������,��Ҫ�IJ���֮һ���Ƿ��䡣����˵,���������ֿ�����,Ҳ������ĵIJ��֡�����ı�����ʵ������ɢ����������,��ӵ�в�ͬ���Ե��˱��ֳɲ�ͬ�����(���ϲ�ͬ�ķ���),�䱾�������ھ��ࡣ
- �ֶ������Ӳź���
�ʼ����֪��,���Ǽ�Ȼ�ǽ������ͱ�����ɢ��,���Ӹ�����Ȼ����̫��,��ÿ�����ʮ�����¡��������������ֿ�,�������4-5����ѡ���ɢ�������ͱ�����Ȼ��������Ϣ����ʧ,��������Խ��,��Ϣ��ʧԽ��Ϊ�˺��������ϵ���Ϣ���Լ�������Ԥ�⺯���Ĺ���,����ҵ�����˸���Information Value(IV):
I V = �� i = 1 N ( g o o d % ? b a d % ) ? W O E i IV=\sum_{i=1}^N(good\%-bad\%)*WOE_i IV=��i=1N?(good%?bad%)?WOEi?
���� N N N��������������ӵĸ���, i i i����ÿ������, g o o d % good\% good%��������ڵ����ʿͻ�(��ǩΪ0�Ŀͻ�)ռ�����������������ʿͻ��ı���, b a d % bad\% bad%�����������Ļ��ͻ�(��ǩΪ1�Ŀͻ�)ռ�������������л��ͻ��ı���,�� W O E i WOE_i WOEi?����Ϊ:
W O E i = l n ( g o o d % b a d % ) WOE_i=ln(\frac{good\%}{bad\%}) WOEi?=ln(bad%good%?)
����������ҵ����������ΥԼ���ʵ�ָ��,���ij�Ϊ֤��Ȩ��(weight of Evidence),������ʵ�������ʿͻ��Ȼ��ͻ��ı����Ķ�����WOE�Ƕ�һ��������˵,WOEԽ��������������������ʿͻ�Խ��,��IV�Ƕ�����������˵,IV���������±���ʾ:

�ɼ�,IV����Խ��Խ��,Ҫ�ҵ�IV�Ĵ�С�����Ӹ�����ƽ��㡣���Ի���������з���,Ȼ�����ÿ��������ÿ��������Ŀ�µ�WOEֵ,����IVֵ������,�ҳ����ʵķ�������� - ����Ҫ���ʲô����Ч��?
ϣ����ͬ���Ե����в�ͬ�ķ���,�����ͬһ�������ڵ��˵������Ǿ������Ƶ�,����ͬ���ӵ��˵������Ǿ�����ͬ��,����˵�ġ��������,���ڲ���С�����������ֿ���˵,ϣ��һ�������ڵ���ΥԼ���������Ƶ�,����ͬ���ӵ��˵�ΥԼ���ʲ��ܴ�,��WOE���Ҫ��,����ÿ�������л��ͻ���ռ�ı���( b a d % bad\% bad%)ҲҪ��ͬ������ʹ�ÿ����������Ա���������֮���������,�����������֮�俨�������Pֵ�ܴ�,��˵�����Ƿdz�����,���Խ��������Ӻϲ�Ϊһ�����ӡ�
����������˼��,�ܽ�����¶�һ���������з���IJ���:
1)���Ȱ������ͱ����ֳ�һ�������϶�ķ����ͱ���,�罫����������ֳ�100��,��50��;
2)ȷ��ÿһ�����ж�Ҫ����������������,����IVֵ��������;
3)�����ڵ�����п�������,���������Pֵ�ܴ������кϲ�,ֱ�������е�����С���趨�� N N N��Ϊֹ;
4)��һ�������ֱ�ֳ�[2,3,4,��,20]��,�۲�ÿ����������µ�IVֵ��α仯,�ҳ�����ʵķ������;
5)������Ϻ�,����ÿ�����WOEֵ, b a d % bad\% bad%,�۲����Ч����
���ϲ��趼��ɺ�,���ԶԸ������������з���,Ȼ��۲�ÿ��������IVֵ,�Դ�����ѡ������
�ԡ�age��Ϊ��,ʵ�ַ�����̡�
3.3.1 ��Ƶ����
#���յ�Ƶ����Ҫ������н��з���,�ԡ�age��Ϊ��
model_data["qcut"],updown = pd.qcut(model_data["age"],retbins = True, q =20)
"""
pd.qcut,���ڷ�λ���ķ��亯��,�����ǽ������ͱ�����ɢ����ֻ�ܹ�����һά����,�������ӵ���������
����q:Ҫ����ĸ���
����retbins = TrueҪ��ͬʱ���ؽṹ������Ϊ����������,Ԫ��Ϊ�ֵ������ӵ�Series
���ڷ�������ֵ:ÿ�����������ĸ�����,�Լ��������ӵ���������
"""
#��model_data������һ�н�����qcut��,��һ����ʵ����ÿ����������Ӧ������
model_data["qcut"]
#�������ӵ���������
updown
#ͳ��ÿ������0,1������
#ʹ�������ӱ��Ĺ���groupby
count_y0 = model_data[model_data["SeriousDlqin2yrs"] == 0].groupby(by = "qcut").count()["SeriousDlqin2yrs"]
count_y1 = model_data[model_data["SeriousDlqin2yrs"] == 1].groupby(by = "qcut").count()["SeriousDlqin2yrs"]
#num_binsֵ�ֱ�Ϊÿ��������Ͻ硢�½�,0���ֵĴ���,1���ֵĴ���
num_bins = [*zip(updown,updown[1:],count_y0,count_y1)]
#ע��:zip�ᰴ����̵���һ���б��������,zip���Խ��б����һ�Զ���Ӧ��Ԫ��
num_bins
#���:
#[(21.0, 28.0, 4241, 7581),
# (28.0, 31.0, 3487, 5986),
# (31.0, 34.0, 3981, 6750),
# (34.0, 36.0, 2942, 4696),
# (36.0, 39.0, 5119, 7492),
# (39.0, 41.0, 3984, 5761),
# (41.0, 43.0, 4017, 5610),
# (43.0, 45.0, 4368, 5915),
# (45.0, 47.0, 4701, 6397),
# (47.0, 48.0, 2485, 3084),
# (48.0, 50.0, 4884, 6091),
# (50.0, 52.0, 4621, 5800),
# (52.0, 54.0, 4671, 5067),
# (54.0, 56.0, 4645, 4125),
# (56.0, 58.0, 4561, 3439),
# (58.0, 61.0, 6656, 4935),
# (61.0, 64.0, 6961, 3260),
# (64.0, 68.0, 6655, 2353),
# (68.0, 74.0, 6778, 1897),
# (74.0, 109.0, 7666, 1346)]
3.3.2 ȷ��ÿ�����ж���0��1(ѡѧ)
for i in range(20):
#�����һ����û�а���������������,���ϲ�
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
"""
�ϲ�֮��,��һ�е����Ƿ�һ��������������?��һ��
���ԭ���ĵ�һ��͵ڶ��鶼û�а���������,���߶�û�а���������,��ô�ϲ�֮��,��һ�е���Ҳ����û�а�����������
������ÿ�κϲ����֮��,��Ҫ�ټ��,��һ���Ƿ��Ѿ���������������
����ʹ��continue�����˱���ѭ��,��ʼ��һ��ѭ��,���Իص����ʼ��for i in range(20),��i+1
�������������Ĵ���,�ִ�ͷ��ʼ����һ���Ƿ������������
�����һ������Ȼû�а�����������,��ifͨ��,�����ϲ�,ÿ�ϲ�һ�ξͻ�ѭ�����һ��,���ϲ�20��
�����һ�����Ѿ�������������,��if��ͨ��,�Ϳ�ʼִ������Ĵ���
"""
#ȷ�ϵ�һ���п϶���������������,���������û�а�����������,����ǰ�ϲ�
#��ʱnum_bins�Ѿ�������Ĵ��봦������,���ܱ��ϲ���,Ҳ����û�б��ϲ�
#�������,Ҫ��num_bins�б���,����д��in range(len(num_bins))
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1]=[(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
#����Ե�һ��ͺ�����������ж���,��û�н���ifȥ�ϲ�,����ǰ��������ѭ��
else:
break
"""
�����ڶ���break,ֻ����if������������²Żᱻ����
Ҳ����˵,ֻ�з����˺ϲ�,�Ż���for i in range(len(num_bins))���ѭ��
ΪʲôҪ������ѭ��?��Ϊ����range(len(num_bins))�б���
���ϲ�������,len(num_bins)�����˸ı�,��ѭ��ȴ�������¿�ʼ,ѭ���ͻ���Ϊ����ȡֵ�߽������
���,һ��if������,��һ���ϲ�����,����ѭ�����ƻ�,ʹ��break������ǰѭ��
ѭ���ͻ�ص��ʼ��for i in range(20)��
��ʱ�жϵ�һ���Ƿ������ֱ�ǩ�Ĵ��벻�ᱻ����,��for i in range(len(num_bins))ȴ�ᱻ��������
����������i��ȡֵ�б�,ѭ��Ҳ�Ͳ��ᱨ��
"""
3.3.3 ����WOE��IV����
#����WOE��BAD RATE
#BAD RATE��bad%����һ������
#BAD RATE��һ������,����������ռ�ı���(bad/total);��bad%��һ�����еĻ�����ռ���������еĻ������ı���
def get_woe(num_bins):
#ͨ��num_bins���ݼ���woe
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns = columns)
df["total"] = df.count_0 + df.count_1#һ�����ӵ������е�������
df["percentage"] = df.total/df.total.sum()#һ���������������,ռ�����������ı���
df["bad_rate"] = df.count_1/df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_0.sum()
df["woe"] = np.log(df["good%"]/df["bad%"])
return df
#����IVֵ
def get_iv(bins_df):
rate = bins_df["good%"] - bins_df["bad%"]
iv = np.sum(rate * bins_df.woe)
return iv
get_iv(get_woe(num_bins))
#���:0.35654189808715486
3.3.4 ��������,�ϲ�����,����IV����,ѡ����ѷ������
num_bins_ = num_bins.copy()
import matplotlib.pyplot as plt
import scipy
IV = []
axisx = []
while len(num_bins_) > 2:
pvs = []
#��ȡnum_bins_����֮��Ŀ�����������Ŷ�(��ֵ)
for i in range(len(num_bins_)-1):
x1 = num_bins_[i][2:]
x2 = num_bins_[i+1][2:]
# 0����chi2ֵ,1����pֵ
pv = scipy.stats.chi2_contingency([x1,x2])[1]
#chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
#ͨ��pֵ���д���,�ϲ�pֵ��������
i = pvs.index(max(pvs))
num_bins_[i:i+2] = [(
num_bins_[i][0],
num_bins_[i+1][1],
num_bins_[i][2]+num_bins_[i+1][2],
num_bins_[i][3]+num_bins_[i+1][3])]
bins_df = get_woe(num_bins_)
axisx.append(len(num_bins_))
IV.append(get_iv(bins_df))
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.show

3.3.5 ����ѷ����������,����֤������
���ϲ�����IJ��ֶ���Ϊ����,��ʵ�ַ���:
def get_bin(num_bins_,n):
while len(num_bins_) > n:
pvs = []
for i in range(len(num_bins_)-1):
x1 = num_bins_[i][2:]
x2 = num_bins_[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
#chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins_[i:i+2] = [(
num_bins_[i][0],
num_bins_[i+1][1],
num_bins_[i][2]+num_bins_[i+1][2],
num_bins_[i][3]+num_bins_[i+1][3])]
return num_bins_
afterbins = get_bin(num_bins,6)
afterbins
#���:
#[(21.0, 36.0, 14651, 25013),
# (36.0, 54.0, 38850, 51217),
# (54.0, 61.0, 15862, 12499),
# (61.0, 64.0, 6961, 3260),
# (64.0, 74.0, 13433, 4250),
# (74.0, 109.0, 7666, 1346)]
bins_df = get_woe(afterbins)
bins_df
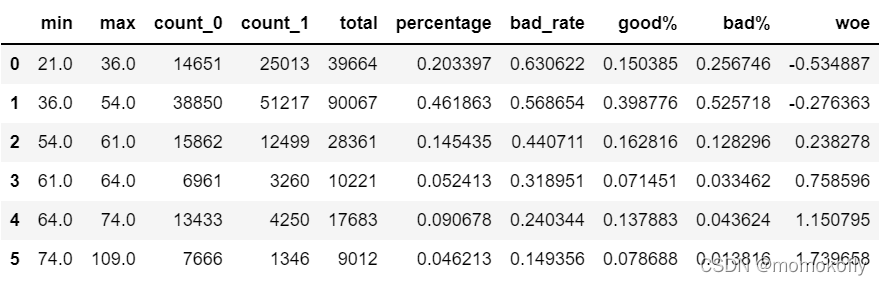
ע:�۲��ϱ�,����ÿ�����bad_rateӦ�������Բ��,˵���������,woeӦ���ǵ����ġ���������,ÿ��bad_rate֮����Ƚ�����,����woe�����为,˵�������Ч�����Dz����ġ�
3.3.6 ��ѡȡ��ѷ�������Ĺ��̰�װΪ����
def graphforbestbin(df, x, y,n = 5,q = 20,graph = True):
"""
�Զ����ŷ��亯��,���ڿ�������ķ���
����:
df:��Ҫ���������
x:��Ҫ���������
y:�������ݶ�Ӧ�ı�ǩY������
n:�����������
q:��ʼ����ĸ���
graph:�Ƿ�Ҫ����IVͼ��
"""
df = df[[x,y]].copy()
df["qcut"],bins = pd.qcut(df[x],retbins = True,q = q,duplicates = "drop")
count_y0 = df.loc[df[y] == 0].groupby(by = 'qcut').count()[y]
count_y1 = df.loc[df[y] == 1].groupby(by = 'qcut').count()[y]
num_bins = [*zip(bins,bins[1:],count_y0,count_y1)]
for i in range(q):
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1] = [(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
else:
break
def get_woe(num_bins):
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns = columns)
df["total"] = df.count_0 + df.count_1#һ�����ӵ������е�������
df["percentage"] = df.total/df.total.sum()#һ���������������,ռ�����������ı���
df["bad_rate"] = df.count_1/df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_0.sum()
df["woe"] = np.log(df["good%"]/df["bad%"])
return df
def get_iv(bins_df):
rate = bins_df["good%"] - bins_df["bad%"]
iv = np.sum(rate * bins_df.woe)
return iv
IV = []
axisx = []
while len(num_bins) > n:
pvs = []
#��ȡnum_bins_����֮��Ŀ�����������Ŷ�(��ֵ)
for i in range(len(num_bins)-1):
x1 = num_bins[i][2:]
x2 = num_bins[i+1][2:]
# 0����chi2ֵ,1����pֵ
pv = scipy.stats.chi2_contingency([x1,x2])[1]
#chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
#ͨ��pֵ���д���,�ϲ�pֵ��������
i = pvs.index(max(pvs))
num_bins[i:i+2] = [(
num_bins[i][0],
num_bins[i+1][1],
num_bins[i][2]+num_bins[i+1][2],
num_bins[i][3]+num_bins[i+1][3])]
bins_df = get_woe(num_bins)
axisx.append(len(num_bins))
IV.append(get_iv(bins_df))
if graph:
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.show()
model_data.columns
#���:
# Index(['SeriousDlqin2yrs', 'RevolvingUtilizationOfUnsecuredLines', 'age',
# 'NumberOfTime30-59DaysPastDueNotWorse', 'DebtRatio', 'MonthlyIncome',
# 'NumberOfOpenCreditLinesAndLoans', 'NumberOfTimes90DaysLate',
# 'NumberRealEstateLoansOrLines', 'NumberOfTime60-89DaysPastDueNotWorse',
# 'NumberOfDependents', 'qcut'],
# dtype='object')
for i in model_data.columns[1:-1]:
print(i)
graphforbestbin(model_data,i,"SeriousDlqin2yrs",n = 2,q = 20)
���Ƶ�ͼ����,�в��ֱ�����ͼ���������쳣,�������������Զ�����,��Ҫ�ֶ����䡣
3.3.7 �������������з���ѡ��
#����ʹ���Զ�����ı���
auto_col_bins = {"RevolvingUtilizationOfUnsecuredLines":6
,"age":5
,"DebtRatio":4
,"MonthlyIncome":3
,"NumberOfOpenCreditLinesAndLoans":5}
#����ʹ���Զ�����ı���
hand_bins = {"NumberOfTime30-59DaysPastDueNotWorse":[0,1,2,13]
,"NumberOfTimes90DaysLate":[0,1,2,17]
,"NumberRealEstateLoansOrLines":[0,1,2,4,54]
,"NumberOfTime60-89DaysPastDueNotWorse":[0,1,2,8]
,"NumberOfDependents":[0,1,2,3]}
#��֤���串��ʹ��ʹ��np.inf�滻���ֵ,��-np.inf�滻��Сֵ
hand_bins={k:[-np.inf,*v[:-1],np.inf] for k,v in hand_bins.items()}
hand_bins
#���:
#{'NumberOfTime30-59DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfTimes90DaysLate': [-inf, 0, 1, 2, inf],
# 'NumberRealEstateLoansOrLines': [-inf, 0, 1, 2, 4, inf],
# 'NumberOfTime60-89DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfDependents': [-inf, 0, 1, 2, inf]}
bins_of_col = {}
#�����Զ�����ķ�������ͷ�����IVֵ
for col in auto_col_bins:
bins_df = graphforbestbin(model_data,col
,"SeriousDlqin2yrs"
,n = auto_col_bins[col]#ʹ���ֵ��������ȡ��ÿ����������Ӧ���������
,q = 20
,graph = False)
bins_list = sorted(set(bins_df["min"]).union(bins_df["max"]))
#��֤���串��ʹ��np.inf�滻���ֵ,-np.inf�滻��Сֵ
bins_list[0],bins_list[-1] = -np.inf,np.inf
bins_of_col[col] = bins_list
#�ϲ��ֶ���������
bins_of_col.update(hand_bins)
bins_of_col
#���:
#{'RevolvingUtilizationOfUnsecuredLines': [-inf,
# 0.0989579085,
# 0.29729511700000005,
# 0.724130660095638,
# 0.9826874216115066,
# 0.9999999,
# inf],
# 'age': [-inf, 36.0, 54.0, 61.0, 74.0, inf],
# 'DebtRatio': [-inf,
# 0.017195179893425287,
# 0.360410730948662,
# 1.505985184207865,
# inf],
# 'MonthlyIncome': [-inf, 0.1, 6896.729169638697, inf],
# 'NumberOfOpenCreditLinesAndLoans': [-inf, 1.0, 3.0, 5.0, 15.0, inf],
# 'NumberOfTime30-59DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfTimes90DaysLate': [-inf, 0, 1, 2, inf],
# 'NumberRealEstateLoansOrLines': [-inf, 0, 1, 2, 4, inf],
# 'NumberOfTime60-89DaysPastDueNotWorse': [-inf, 0, 1, 2, inf],
# 'NumberOfDependents': [-inf, 0, 1, 2, inf]}
3.4 ��������WOE��ӳ�䵽������
��������Ҫ��������WOE,���Ұ�WOE�滻��ԭʼ����model_data�С���Ϊ��ʹ��WOE���Ǻ����������ģ,����ϣ����ȡ���ǡ������䡱�ķ�����,�����ֿ��ϸ���������Ŀ�ķ�������
data = model_data.copy()
#����pd.cut���Ը�����֪�ķ����������ݷ���
#����Ϊpd.cut(����,���б���ʾ�ķ�����)
data = data[["age","SeriousDlqin2yrs"]].copy()
data["cut"] = pd.cut(data["age"],[-np.inf, 36.0, 54.0, 61.0, 74.0, np.inf])
data
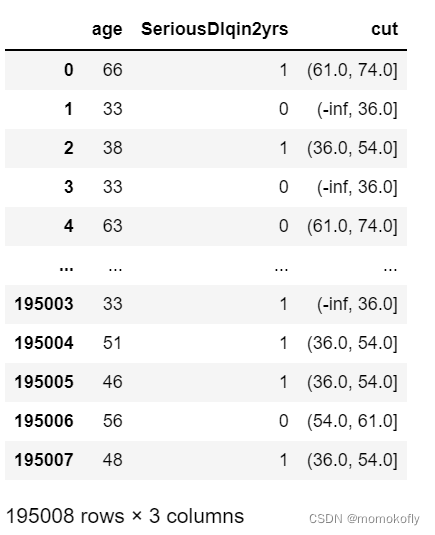
#�����ݰ��������ۺ�,��ȡ�����еı�ǩֵ
data.groupby("cut")["SeriousDlqin2yrs"].value_counts()
#���:
#cut SeriousDlqin2yrs
#(-inf, 36.0] 1 25013
# 0 14651
#(36.0, 54.0] 1 51217
# 0 38850
#(54.0, 61.0] 0 15862
# 1 12499
#(61.0, 74.0] 0 20394
# 1 7510
#(74.0, inf] 0 7666
# 1 1346
#Name: SeriousDlqin2yrs, dtype: int64
#ʹ��unstack()������״�ṹ��ɱ�װ�ṹ
data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
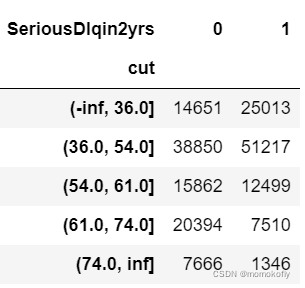
bins_df = data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
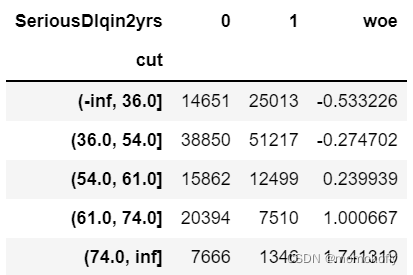
bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
bins_df
�����Ϲ��̰�װ�ɺ���:
def get_woe(df,col,y,bins):
df = df[[col,y]].copy()
df["cut"] = pd.cut(df[col],bins)
bins_df = df.groupby("cut")[y].value_counts().unstack()
woe = bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
return woe
#������������WOE�洢���ֵ䵱��
woeall = {}
for col in bins_of_col:
woeall[col] = get_woe(model_data,col,"SeriousDlqin2yrs",bins_of_col[col])
woeall
"""
���:
{'RevolvingUtilizationOfUnsecuredLines': cut
(-inf, 0.099] 2.224258
(0.099, 0.297] 0.661049
(0.297, 0.724] -0.496930
(0.724, 0.983] -1.353231
(0.983, 1.0] -0.468322
(1.0, inf] -2.074375
dtype: float64,
'age': cut
(-inf, 36.0] -0.533226
(36.0, 54.0] -0.274702
(54.0, 61.0] 0.239939
(61.0, 74.0] 1.000667
(74.0, inf] 1.741319
dtype: float64,
'DebtRatio': cut
(-inf, 0.0172] 1.454800
(0.0172, 0.36] 0.057854
(0.36, 1.506] -0.349860
(1.506, inf] 0.179866
dtype: float64,
'MonthlyIncome': cut
(-inf, 0.1] 1.416447
(0.1, 6896.729] -0.200153
(6896.729, inf] 0.313653
dtype: float64,
'NumberOfOpenCreditLinesAndLoans': cut
(-inf, 1.0] -0.846486
(1.0, 3.0] -0.341287
(3.0, 5.0] -0.058515
(5.0, 15.0] 0.120179
(15.0, inf] 0.370470
dtype: float64,
'NumberOfTime30-59DaysPastDueNotWorse': cut
(-inf, 0.0] 0.355435
(0.0, 1.0] -0.883450
(1.0, 2.0] -1.375498
(2.0, inf] -1.535304
dtype: float64,
'NumberOfTimes90DaysLate': cut
(-inf, 0.0] 0.235365
(0.0, 1.0] -1.756769
(1.0, 2.0] -2.281914
(2.0, inf] -2.388741
dtype: float64,
'NumberRealEstateLoansOrLines': cut
(-inf, 0.0] -0.401039
(0.0, 1.0] 0.199083
(1.0, 2.0] 0.631953
(2.0, 4.0] 0.382872
(4.0, inf] -0.335461
dtype: float64,
'NumberOfTime60-89DaysPastDueNotWorse': cut
(-inf, 0.0] 0.123312
(0.0, 1.0] -1.381946
(1.0, 2.0] -1.772126
(2.0, inf] -1.652897
dtype: float64,
'NumberOfDependents': cut
(-inf, 0.0] 0.658801
(0.0, 1.0] -0.519028
(1.0, 2.0] -0.529047
(2.0, inf] -0.499650
dtype: float64}
"""
������,������WOEӳ�䵽ԭʼ������:
#��ϣ�����ǵ�ԭ��������,����һ���µ�DataFrame,������ԭʼ����model_dataһģһ��
model_woe = pd.DataFrame(index = model_data.index)
#��ԭ���ݷ����,����Ľ����WOE�����map����ӳ�䵽������
model_woe["age"] = pd.cut(model_data["age"],bins_of_col["age"]).map(woeall["age"])
#��������������,�����:
for col in bins_of_col:
model_woe[col] = pd.cut(model_data[col],bins_of_col[col]).map(woeall[col])
#����ǩ���䵽������
model_woe["SeriousDlqin2yrs"] = model_data["SeriousDlqin2yrs"]
#��������յĽ�ģ������
model_woe.head()#ԭ�������ݶ���ɷ�����������һ�����WOEֵ
3.5 ��ģ��ģ����֤
���ϴ�����ѵ����,�������������Լ�,���Ѿ��з���������,���Լ��Ĵ����ͷdz���,ֻ��Ҫ���Ѿ�����õ�WOEӳ�䵽���Լ���ȥ���ɡ�
#�������Լ�
vali_woe = pd.DataFrame(index = vali_data.index)
for col in bins_of_col:
vali_woe[col] = pd.cut(vali_data[col],bins_of_col[col]).map(woeall[col])
vali_woe["SeriousDlqin2yrs"] = vali_data["SeriousDlqin2yrs"]
vali_x = vali_woe.iloc[:,:-1]
vali_y = vali_woe.iloc[:,-1]
������,�Ϳ��Կ�ʼ��ģ�ˡ�
x = model_woe.iloc[:,:-1]
y = model_woe.iloc[:,-1]
from sklearn.linear_model import LogisticRegression as LR
lr = LR().fit(x,y)
lr.score(vali_x,vali_y)
#���:0.771286015123959
���ص�Ч��һ��,��������ʹ��C��max_iter��ѧϰ���߰����ع��Ч������ȥ��
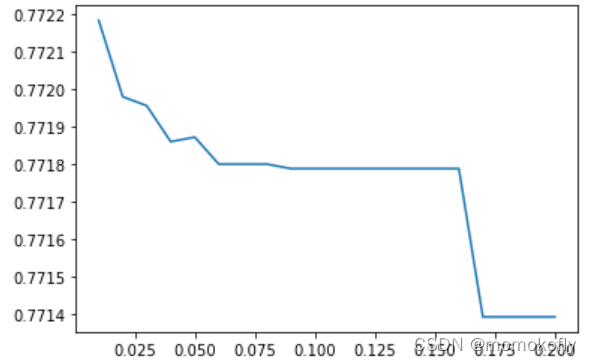
c_1 = np.linspace(0.01,1,20)
c_2 = np.linspace(0.01,0.2,20)
score = []
for i in c_2:
lr = LR(solver = "liblinear",C = i).fit(x,y)
score.append(lr.score(vali_x,vali_y))
plt.figure()
plt.plot(c_2,score)
plt.show()
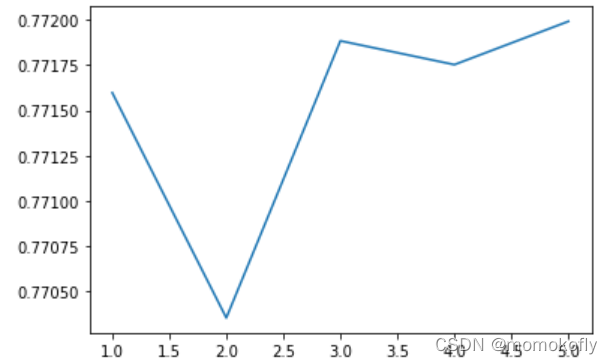
lr.n_iter_
#���:array([5], dtype=int32)
score = []
for i in [1,2,3,4,5]:
lr = LR(solver = "liblinear",C = 0.025,max_iter = i).fit(x,y)
score.append(lr.score(vali_x,vali_y))
plt.figure()
plt.plot([1,2,3,4,5],score)
plt.show()
lr = LR(solver = "liblinear",C = 0.025,max_iter = 5).fit(x,y)
lr.score(vali_x,vali_y)
#���:0.7719919594141859
���ܴ�ȷ������,ģ��Ч������һ��,�����Կ���ROC�����ϵĽ����
import scikitplot as skplt
#�������,�Ȱ�װscikit-plot:pip install scikit-plot
vali_proba_df = pd.DataFrame(lr.predict_proba(vali_x))
skplt.metrics.plot_roc(vali_y,vali_proba_df
,plot_micro = False,figsize = (6,6)
,plot_macro = False)
3.6 �������ֿ�
��ģ���,ʹ��ȷ�ʺ�ROC������֤��ģ�͵�Ԥ������(Ч����̫��)������������Ҫ�����ع�ת��Ϊ�����ֿ��ˡ����ֿ��еķ���,�����¹�ʽ����:
S
c
o
r
e
=
A
?
B
?
l
o
g
(
o
d
d
s
)
Score=A-B*log(odds)
Score=A?B?log(odds)
����
A
A
A��
B
B
B�dz���,
A
A
A������������,
B
B
B�������̶ȡ�,
l
o
g
(
o
d
d
s
)
log(odds)
log(odds)������һ����ΥԼ�Ŀ����ԡ���ʵ���ع�Ľ��ȡ����������ʽ��õ�
a
T
x
\textbf{a}^T\textbf{x}
aTx,������*��������,����
l
o
g
(
o
d
d
s
)
log(odds)
log(odds)��ʵ���Dz�����������������ͨ����������ķ�ֵ���빫ʽ���,����������ֱ���:
(1)ij��������ΥԼ�����µ�Ԥ�ڷ�ֵ
(2)ָ����ΥԼ���ʷ����ķ���(PDO)
�������
B
B
B��
A
A
A�ֱ�Ϊ(28.85390081777927, 481.8621880878296)������
B
B
B��
A
A
A,�����ͺ����õ��ˡ����в������ֿ��и�����Ӱ��Ļ�����,���ǽ��ؾ���Ϊ
l
o
g
(
o
d
d
s
)
log(odds)
log(odds)���빫ʽ���м���,�������������������ֵ��ķ���,Ҳ�ǽ�ϵ��������м���:
base_score = A - B*lr.intercept_
base_score
#���:array([481.75070042])
score_age = woeall["age"] * (-B*lr.coef_[0][1])
score_age
#���:
#cut
#(-inf, 36.0] -11.588079
#(36.0, 54.0] -5.969833
#(54.0, 61.0] 5.214366
#(61.0, 74.0] 21.746526
#(74.0, inf] 37.842413
#dtype: float64
����ͨ��ѭ��,���������������ֿ�����ȫ��һ����д��һ�������ļ�ScoreData.csv:
file = "C:/Users/86188/Desktop/coding/Kaggle-give me some credit/ScoreData.csv"
#open���������ļ���python����,��һ���������ļ���·��+�ļ���,����ļ��Ƿ��ڸ�Ŀ¼��,��ֻ��Ҫ�ļ����ͺ�
#�ڶ��������Ǵ��ļ������;,��w����ʾ����д��,ͨ��ʹ�õ��ǡ�r��,��ʾ�����Ķ�
#����������
#֮��ʹ��ѭ��,ÿ������һ��score_age���Ƶķֵ��ͷ���,����д���ļ�֮��
with open(file,"w") as fdata:#����������������ļ�,���½����ļ�
fdata.write("base_score,{}\n".format(base_score))
for i,col in enumerate(x.columns):
score = woeall[col] * (-B*lr.coef_[0][i])
score.name = "Score"
score.index.name = col
score.to_csv(file,header = True,mode = "a")
�����:https://www.bilibili.com/video/BV1Ch411x7xB?p=87&spm_id_from=pageDriver