1.摘要
随着社交网络的兴起,更多人选择在网络上发表自己对影视作品的观点,这为影视投资人了解观众对电影的反馈提供了更方便的途径.例如,豆瓣影评中包含了海量用户或积极或消极的情感观点,而分析豆瓣影评的情感倾向能够辅助投资人进行决策,提升作品质量.大量数据分析必须借助计算机技术手段完成,其中情感分析是自然语言处理(natural language processing,NLP)的一个方向,常用来分析判断文本描述的情绪类型,因此也被称为情感倾向分析.为了提高影评情感分类的准确率,本文实现了Spatial Dropout-GRU和TextCNN模型用于情感分析,由其实验结果可得,在迭代5次的情况下Spatial Dropout-GRU模型情感分析的准确率达到了84%,TextCNN模型得到了82%.
2.数据集介绍
预训练词向量。中文维基百科词向量word2vec。
| 数据集 | 积极 | 消极 |
| 训练集 | 10000 | 9999 |
| 测试集 | 10000 | 9999 |
3.模型设计
2014年,Yoon Kim针对CNN的输入层做了一些变形,提出了文本分类模型textCNN。与传统图像的CNN网络相比, textCNN 在网络结构上没有任何变化(甚至更加简单了), 从图可以看出textCNN 其实只有一层卷积,一层max-pooling, 最后将输出外接softmax 来n分类。

开发环境:python3.6.5、tensorflow==1.12、keras==2.2.4、Numpy 1.13.1、jieba 0.39
Spatial Dropout-GRU模型如下:

代码实现:
model = Sequential()
model.add(embedding_layer)
model.add(SpatialDropout1D(0.4))
model.add(GRU(64, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(n_class, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])?TextCNN模型结构如下:
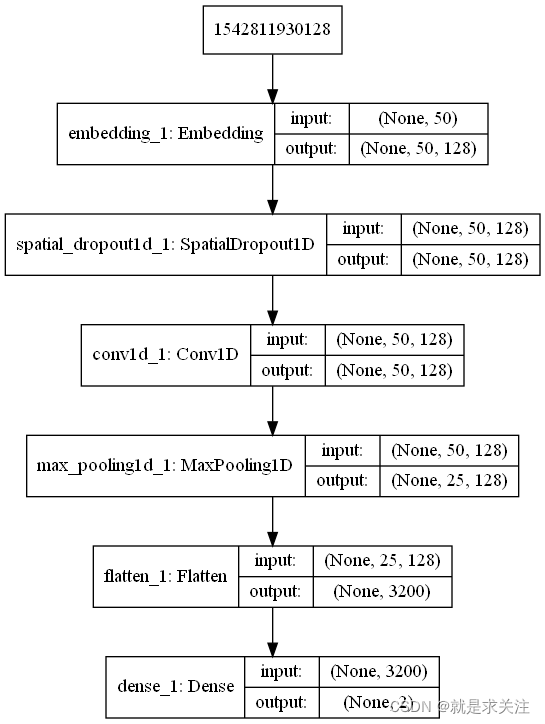
?4.实验结果对比
TextCNN模型:

?Spatial Dropout-GRU模型:
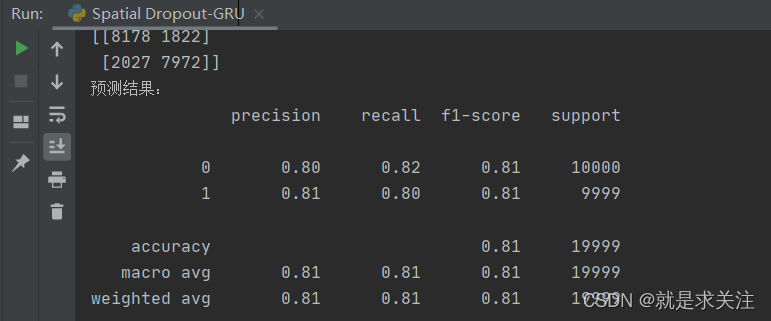
5.总结
自然语言处理包括自动问答、机器翻译、信息抽取等技术, 而情感分析是自然语言处理的一个方向. 自然语言处理可以从文本的不同层面进行, 包括字符级、词语级和句子级等. 词嵌入向量的提出使得词语可通过学习得到词的语义表达, 从而为基于积极或消极语义的情感分类提供更有效的方法. 本文工作实现了两个模型: Spatial Dropout-GRU模型TextCNN模型,并分别测试了其情感分类效果。这为影视投资人了解观众对电影的反馈提供了更方便的途径及能够辅助投资人进行决策,提升作品质量。
代码链接:(包含数据集4万条)