�����:GFocalV2
1. ����
����:��ƪ��������֮ǰV1�汾�Ļ�������ǿ��Ŀ�����ж�λ����������������֮ǰ��һЩ�����л��ڷ����֧�ͼ���֧������ͼ������ʵ�ֶ�λ�����Ĺ���(��IoUNet��FCOS),���ǻ����training��infer�ε�gap���Դ���GFocal V1�İ汾�������������֪��Ԥ��ͷ,�Ӷ��ֲ���training��infer��gap������ƪ���¸���һ��ʹ��4���߽��ĸ��ʷֲ���Ϊ������Ϣ����,ʹ��������֪��֧�ܹ���ȡ����߽����Ϣ,�Ӷ���һ������������֪��֧��ȷ�ȡ�
��֮ǰ��һЩ������ʹ�÷�����DZ߽��ع��֧����ͼ��Ϊ�������,���ڴ˻�����ʵ�ֶԼ��������ĸ�֪,��ṹ����ͼ��ͼ��ʾ:
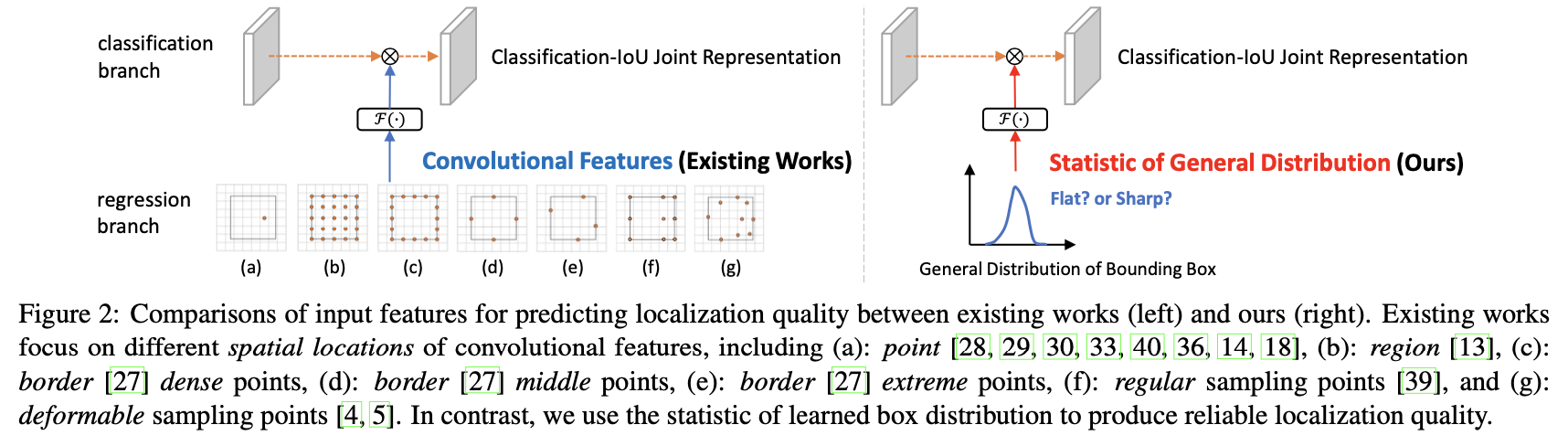
������ͼ����ͼȴ���ڻع��֧�Ƿ���ȷ������������,�Դ��������GFocal V1�汾��4���ߵĸ��ʷֲ���ʵ�ʼ���߽������Ĺ�ϵ,ͨ�����µķ������߽��ĸ��ʷֲ����ּ��ֲ����������ü���߽�Ķ�λ�����ǽϸ���,��֮��Ȼ�������������GFocal V1���ɵļ���߽�ֲ�ȥ����ʵ�ʵļ������,�������ͼ��ͼ�лع��֧���ֽ�����,��õ�����ͼ��ģʽ,����ʹ�ü��߽��ĸ��ʷֲ������ɸ��õļ������������
2. �������
2.1 pipeline
���µ�pipeline����ͼ��ʾ,����Ҫ�ĸĽ����ڼ������������֧��,Ҳ������ʽʹ���˼���ĸ��ʷֲ�����,Ҳ������ͼ�к�ɫ���߲���չʾ�IJ���(DGQP:Distribution-Guided Quality Predictor)��
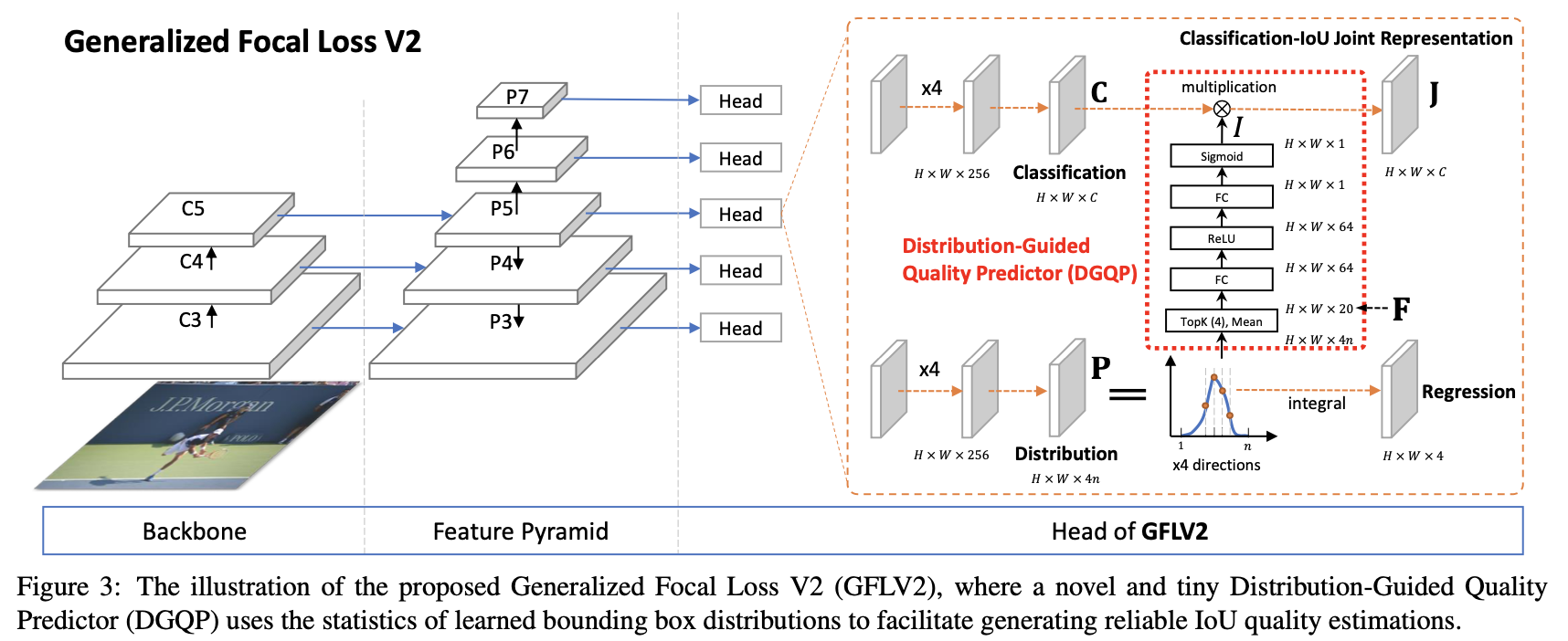
2.2 DGQP�������
ʹ��GFocal���������ļ��߽��ĸ��ʷֲ�����,���Խ�Ŀ�����漰����4���߽�ķֲ�����Ϊ:
P
w
=
[
P
w
(
y
0
)
,
��
,
P
w
(
y
n
)
]
,
?
w
��
[
l
,
r
,
b
,
t
]
P^w=[P^w(y_0),\dots,P^w(y_n)],\forall{w}\in[l,r,b,t]
Pw=[Pw(y0?),��,Pw(yn?)],?w��[l,r,b,t]�����������������Ϊ
n
n
n������ͼ,��ô���ѡ��������ߴ����е��������뵽�����������?���¸����ķ�����ʹ��top-k�ķ���,Ҳ����������Ϊ
n
n
n�ķֲ���ѡ�����ֵtop-k������ͼ,֮����concat����Щ����ͼ��mean,�Ӷ�ɸѡ����Ӧ������ͼ,��ɸѡ���̿��Բο���ͼ:
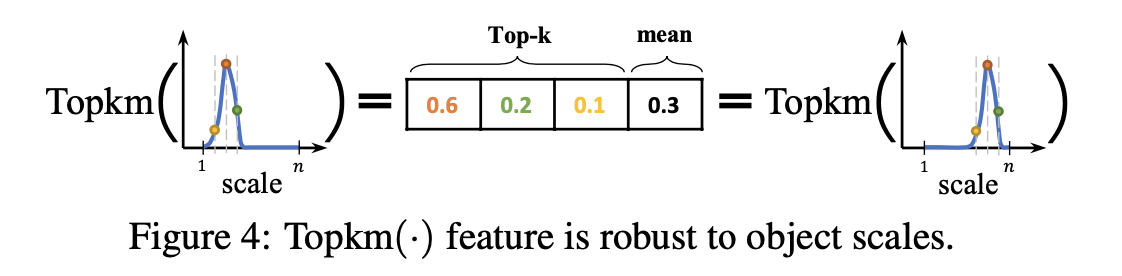
��������concat��mean����var��������ʵ��,��ʵ�������±���ʾ:
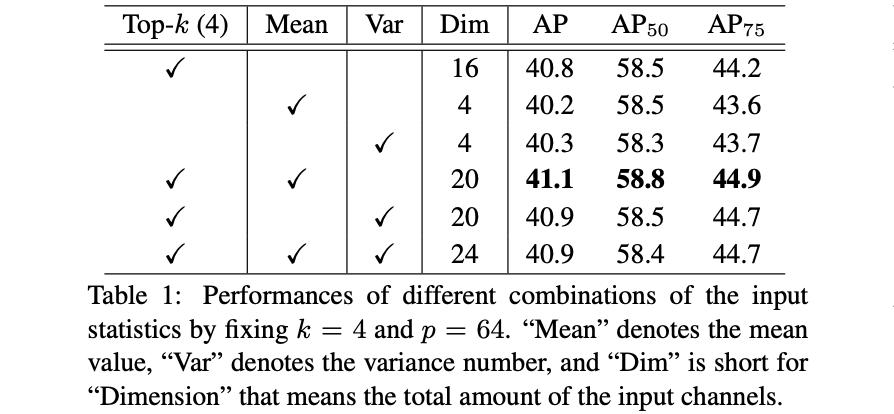
��ô����������4������ij�ȡ����������ͼconcat�����������
F
��
R
4
(
k
+
1
)
F\in R^{4(k+1)}
F��R4(k+1),����Ϊ:
F
=
C
o
n
c
a
t
(
{
T
o
p
k
m
(
P
w
)
�O
w
��
{
l
,
r
,
b
,
t
}
}
)
F=Concat(\{Topkm(P^w)|w\in\{l,r,b,t\}\})
F=Concat({Topkm(Pw)�Ow��{l,r,b,t}})
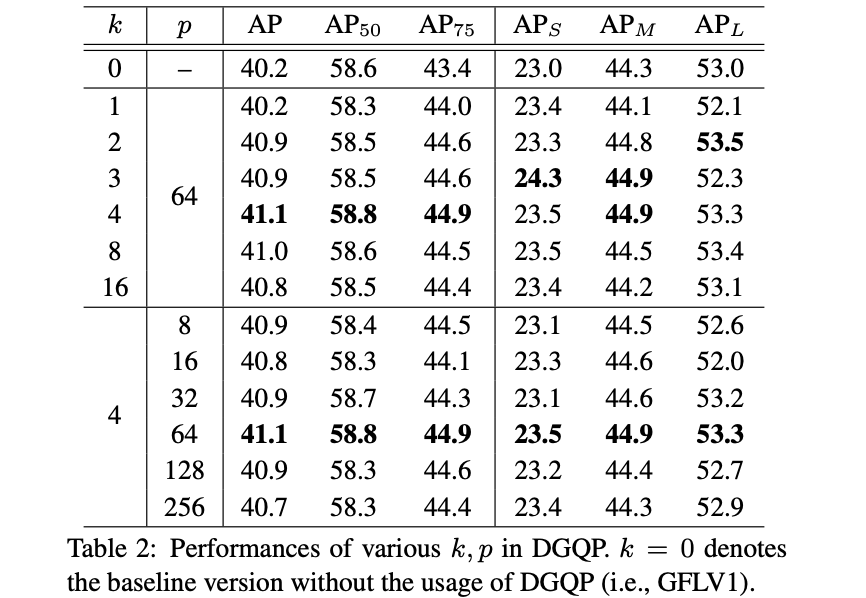
������Ĺ����л��漰��
k
,
p
k,p
k,pֵ��ѡ��,��ѡ��Ҳ���ж�Ӧ��ʵ���,��ʵ�������±���ʾ:
��������������ȫ����ʵ������������ά��ƥ��,�õ��������ᵽ��IoU scalar����
I
��
R
H
?
W
?
1
I\in R^{H*W*1}
I��RH?W?1:
I
=
F
=
��
(
W
2
��
(
W
1
F
)
)
I=\mathcal{F}=\sigma(W_2\delta(W_1F))
I=F=��(W2?��(W1?F))
֮������������
C
��
R
H
?
W
?
C
m
C\in R^{H*W*C_m}
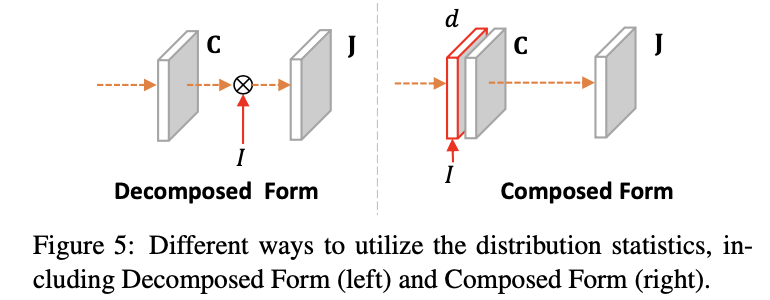
C��RH?W?Cm?,֮�����element-wise mul�õ���֪��������
J
J
J����ʵ�����������ںϲ����������ֵ�,����ͼ:
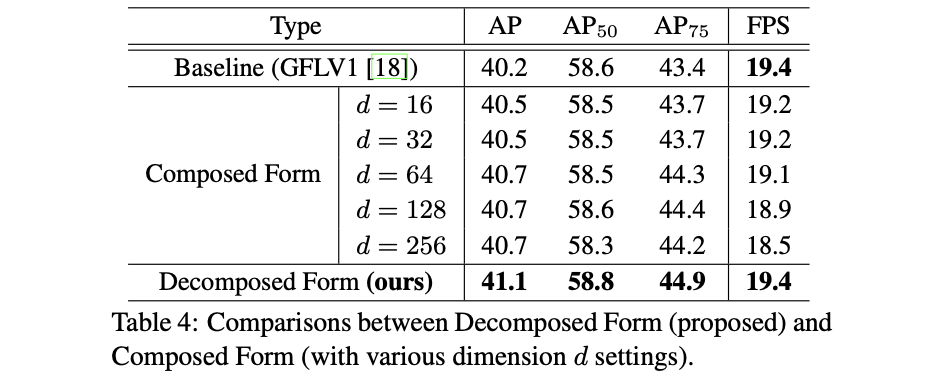
��ô���Ƿֱ�����ܵ�Ӱ����±���ʾ:
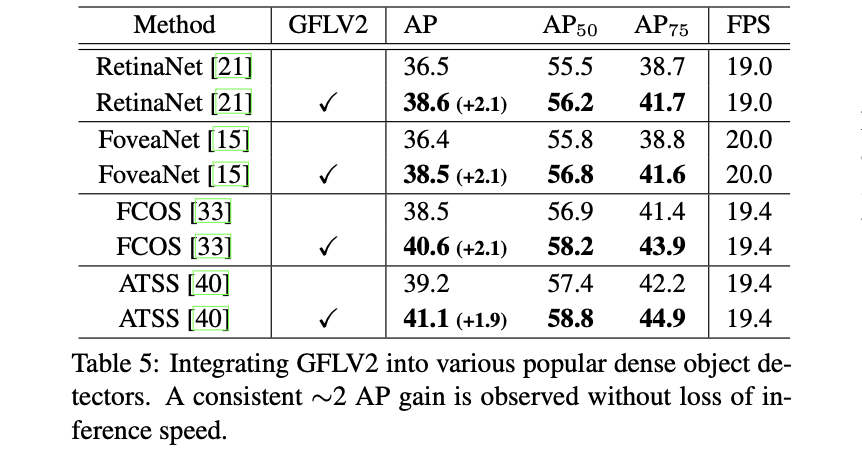
3. ʵ����
��������ķ������ڼ�����������Ӱ����±�: