运行爬虫程序的时候报错了,报错情况如下: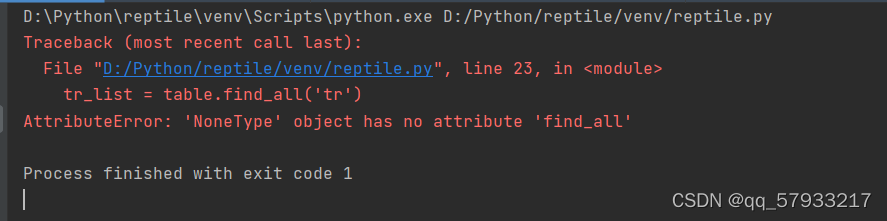
?有没有大神可以告诉我这是什么引起的,具体应该怎么解决
爬虫主要实现的是爬取国内GDP生产总值,并实现数据可视化,把源代码放在下面
源代码:
from bs4 import BeautifulSoup
import csv
import requests
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
}
with open('中国国内生产总值.csv', 'w', newline='') as csv_out_file:
head_list = ['季度', '国内生产总值-绝对值(亿元)', '国内生产总值-同比增长', '第一产业-绝对值(亿元)', '第一产业-同比增长',
'第二产业-绝对值(亿元)', '第二产业-同比增长', '第三产业-绝对值(亿元)', '第三产业-同比增长']
filewriter = csv.writer(csv_out_file)
filewriter.writerow(head_list)
for page in range(1, 4):
url = 'https://data.eastmoney.com/cjsj/gdp.html' + str(page)
response = requests.get(url=url, headers=headers)
page_text = response.text
soup = BeautifulSoup(page_text, 'html.parser')
table = soup.find('table', attrs={'class':'table-model'})
tr_list = table.find_all('tr')
tr_list.pop(-1)
for i in range(2):
tr_list.pop(0)
for tr in tr_list:
info = tr.text.replace(' ', '').replace('\r', '').replace('\n', ' ').lstrip().rstrip()
info_list = info.split()
filewriter.writerow(info_list)
from pyecharts import Line
Quarter = []
GDP = []
Primary_industry = []
Secondary_industry = []
Tertiary_industry = []
with open('中国国内生产总值.csv', 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
head = next(filereader)
for row_list in filereader:
Quarter.append(row_list[0])
gdp = round(eval(row_list[2][:-1]) / 100, 3)
GDP.append(gdp)
pri = round(eval(row_list[4][:-1]) / 100, 3)
Primary_industry.append(pri)
sec = round(eval(row_list[6][:-1]) / 100, 3)
Secondary_industry.append(sec)
ter = round(eval(row_list[8][:-1]) / 100, 3)
Tertiary_industry.append(ter)
Quarter = Quarter[::-1]
GDP = GDP[::-1]
Primary_industry = Primary_industry[::-1]
Secondary_industry = Secondary_industry[::-1]
Tertiary_industry = Tertiary_industry[::-1]
Quarter = Quarter[::-1]
GDP = GDP[::-1]
Primary_industry = Primary_industry[::-1]
Secondary_industry = Secondary_industry[::-1]
Tertiary_industry = Tertiary_industry[::-1]
line = Line('中国国内生产总值同比增长率', '时间:2006年第1季度-2021年第3季度 数据来源:东方财富网', width=1280, height=720)
line.add('国内生产总值', Quarter, GDP, is_smooth=False, mark_point=['max'], mark_line=['average'], legend_pos='right')
line.add('第一产业', Quarter, Primary_industry, is_smooth=False, mark_point=['max'], mark_line=['average'],
legend_pos='right')
line.add('第二产业', Quarter, Secondary_industry, is_smooth=False, mark_point=['max'], mark_line=['average'],
legend_pos='right')
line.add('第三产业', Quarter, Tertiary_industry, is_smooth=False, mark_point=['max'], mark_line=['average'],
legend_pos='right')
line.render('中国国内生产总值.html')