1.摘 要
经典的 LSTM 分类模型,一种是利用 LSTM 最后时刻的输出作为高一级的表示,而另一种是将所有时刻的LSTM 输出求平均作为高一级的表示.这两种表示都存在一定的缺陷,第一种缺失了前面的输出信息,另一种没有体现每个时刻输出信息的不同重要程度.为了解决此问题,引入Attention 机制,对 LSTM 模型进行改进,设计了LSTM-Attention 模型.实验结果表明: LSTM 分类模型比传统的机器学习方法分类效果更好,而引入 Attention 机制后的 LSTM 模型相比于经典的文本分类模型,分类效果也有了一定程度的提升.
2.数据集
本文的实验数据集来源于搜狗实验室中的搜狐新闻 数据,从中提取出用于训练中文词向量的中文语料, 大小约为 4GB 左右.然后选取了10 个类别的新闻数据,分别为体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐.每个类别 新闻为5000 条,共 50000 条新闻,利用这 50000 条 数据来训练模型.其测试集和验证集如下
- 验证集: 500*10
- 测试集: 1000*10
3. 模型实现
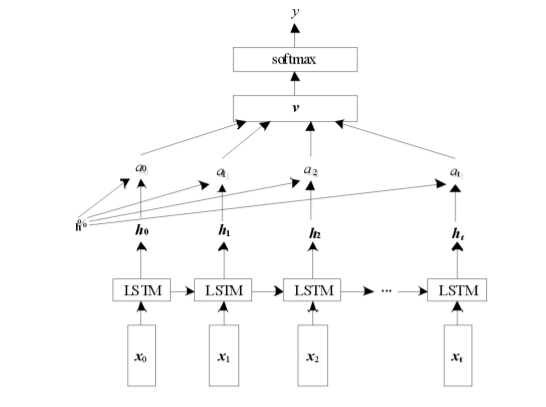
?代码如下:
model_input = keras.layers.Input((seq_length,), dtype='float64')
embedding = keras.layers.Embedding(vocab_size+1, 256, input_length=seq_length(model_input)
LSTM = keras.layers.LSTM(256,return_sequences=True)(embedding)
ATT= Attention(name="weights")(LSTM )
FC1 = keras.layers.Dense(256, activation="relu")(ATT)
droped = keras.layers.Dropout(0.5)(FC1)
FC2 = keras.layers.Dense(num_classes, activation="softmax")(droped)
model = keras.models.Model(inputs=model_input, outputs=FC2)模型讲解链接:
基于LSTM-Attention的中文新闻文本分类-深度学习文档类资源-CSDN下载
4.结果分析
实验环境:开python3.6.5、tensorflow==1.12、keras==2.2.4
| 模型 | P | R | F |
| LSTM | 0.97 | 0.97 | 0.97 |
| LSTM-Attention | 0.98 | 0.98 | 0.98 |
LSTM-Attention 分类模型的分类效果要比传统的机器学习分类模型好,原因在于 Attention 计算了
文本中每个词分配的注意力概率分布值,这样可以有效地提取出文本中的关键词,而关键词对文本的语义表达起到了重要的作用,说明 Attention 对文本分类性能的提升起到了一定的作用.
5.总结
本文利用 word2vec 训练大规模中文新闻语料,从大量的文本信息中得到中文词的词向量,作为文
本的特征表达.相比于传统的机器学习提取特征的方法,word2vec 可以自动将语义信息浓缩进数学向量中.基于词向量的文本表示方法,本文对 LSTM 分类模型进行了改进,引入了 Attention 机制.Attention的计算是可微的,可以通过反向传播训练,适用于深度学习中的网络结构,由此设计了 LSTM-Attention模型.从实验结果也可以看出,引入 Attention 机制后的 LSTM 模型对文本的分类效果有了一定程度的提升.但是,Attention 机制的应用也有一定的限制,它需要耗费一定的计算成本,因为需要为每个输入输出组合分别计算注意力分配的概率值,一旦输入输出序列增加,Attention 计算量随之呈指数级增长.
完整代码链接: