目录
1.线性回归
为了解释线性回归,我们举一个实际的例子: 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。在机器学习的术语中,该数据集称为训练数据集(training data set) 或训练集(training set)。 每行数据(比如一次房屋交易相对应的数据)称为样本(sample), 也可以称为数据点(data point)或数据样本(data instance)。 我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。 预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
给定训练数据特征X和对应的已知标签y, 线性回归的目标是找到一组权重向量w和偏置b: 当给定从X的同分布中取样的新样本特征时, 这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。
1.1损失函数
?损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。?
平方误差函数:?当样本ii的预测值为y^(i)y^(i),其相应的真实标签为y(i)y(i)时, 平方误差可以定义为以下公式:

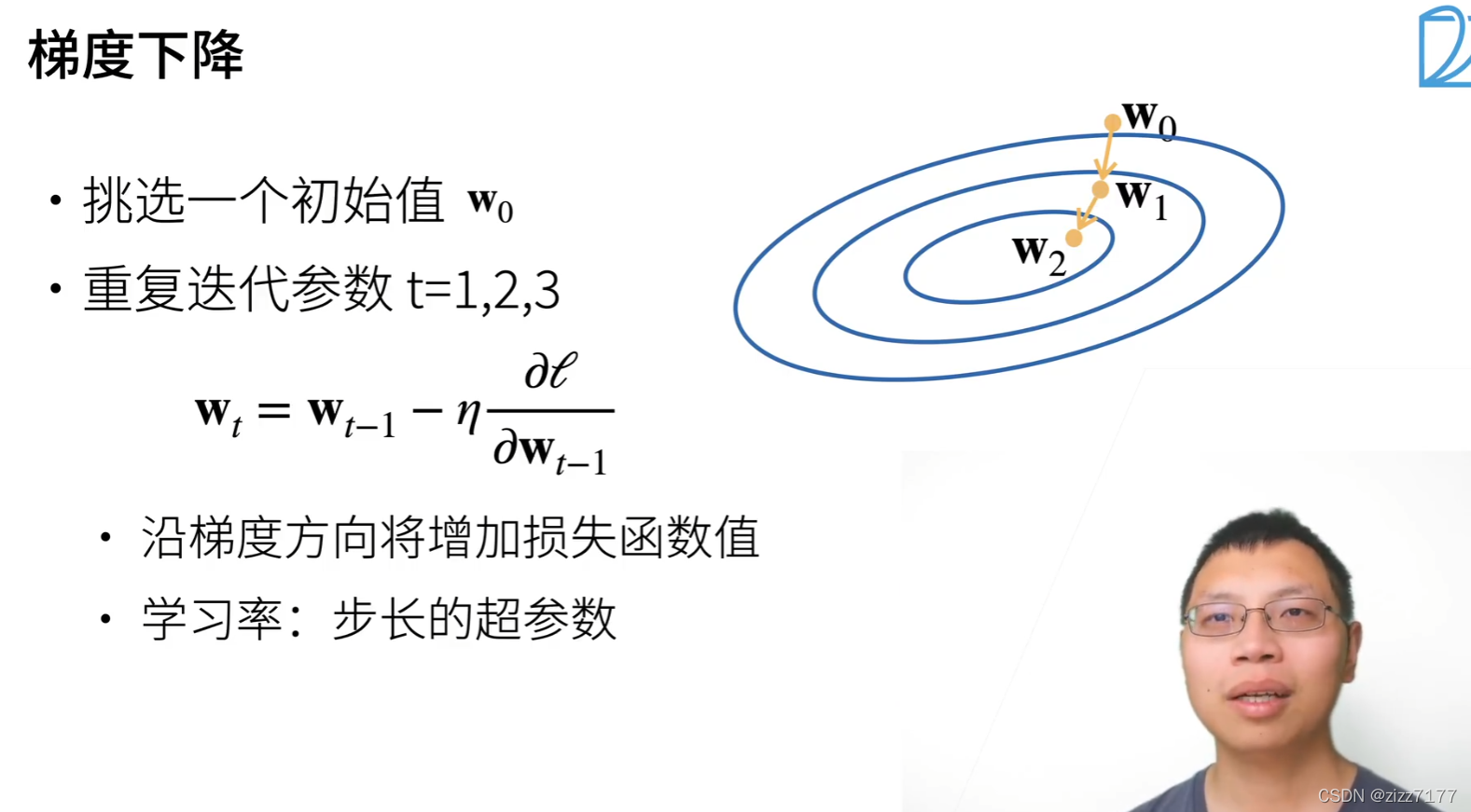
?1.2梯度下降
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。它通过不断地在损失函数递减的方向上更新参数来降低误差。但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。在每次迭代中,我们首先随机抽样一个小批量B, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数η,并从当前参数的值中减掉。
2.softmax回归
全连接层:每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。
softmax回归的输出层也是全连接层
softmax运算将输出层的每个输出转化为总和为1的概率
