1、预备知识-python核心用法常用数据分析库(上)
文章目录
概述
Python 是当今世界最热门的编程语言,而它最大的应用领域之一就是数据分析。在python众多数据分析工具中,pandas是python中非常常用的数据分析库,在数据分析,机器学习,深度学习等领域经常被使用。使用 Pandas 我们可以 Excel/CSV/TXT/MySQL 等数据读取,然后进行各种清洗、过滤、透视、聚合分析,也可以直接绘制折线图、饼图等数据分析图表,在功能上它能够实现自动化的对大文件处理,能够实现 Excel 的几乎所有功能并且更加强大。
本实验将通过实战的方式,介绍pandas数据分析库的基本使用,让大家在短时间内快速掌握python的数据分析库pandas的使用,为后续项目编码做知识储备
实验环境
- Python 3.7
- PyCharm
任务一:环境安装与配置
【实验目标】
本实验主要目标为在Windows操作系统中,完成本次实验的环境配置任务,本实验需要的软件为PyCharm+Python 3.7
【实验步骤】
1、安装Python 3.7
2、安装Pycharm
3、安装jupyter、pandas、numpy、notebook
打开CMD,并输入以下命令,安装jupyter、notebook、pandas和numpy
pip install jupyter notebook pandas numpy
安装完成后会有类似如下文字提示:
以上步骤完成后,实验环境配置工作即已完成,关闭CMD窗口
任务二:Pandas数据分析实战
【任务目标】
本任务主要目标为使用pandas进行数据分析实战,在实战过程中带大家了解pandas模块的一下功能:
- 准备工作
- 检查数据
- 处理缺失数据
- 添加默认值
- 删除不完整的行
- 删除不完整的列
- 规范化数据类型
- 重命名列名
- 保存结果
【任务步骤】
1、打开CMD,执行如下命令,开启jupyter
jupyter notebook
成功执行以上命令后,系统将自动打开默认浏览器,如下图所示:
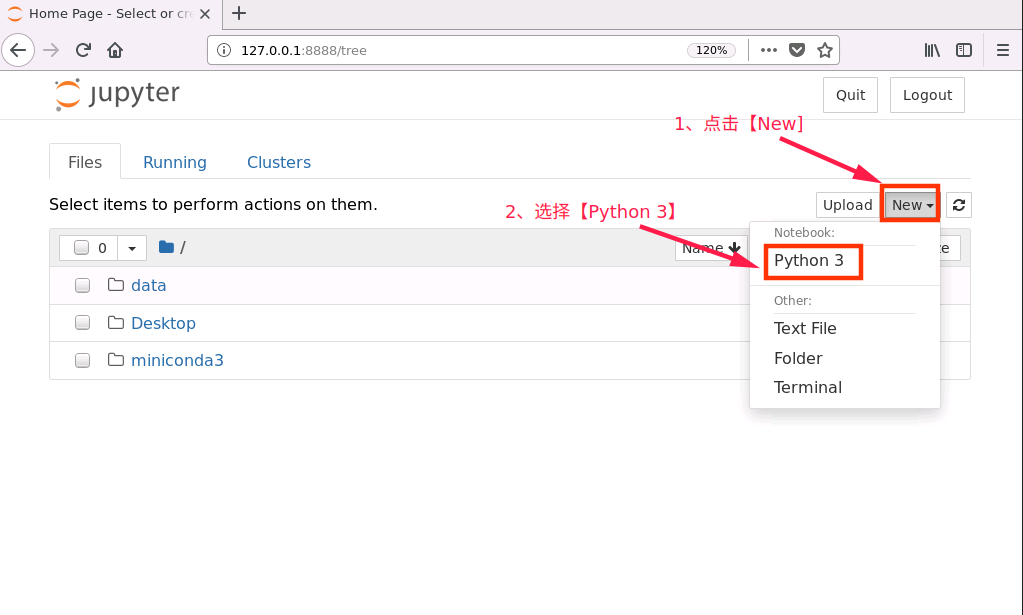
成功打开浏览器后,按如下流程创建 notebook 文件
对新建notebook进行重命名操作
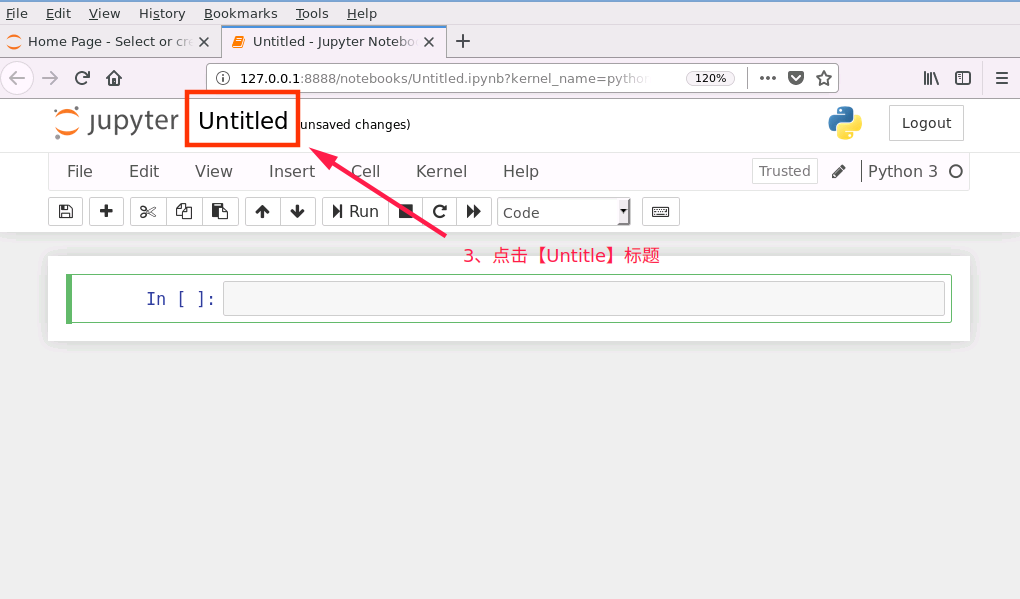
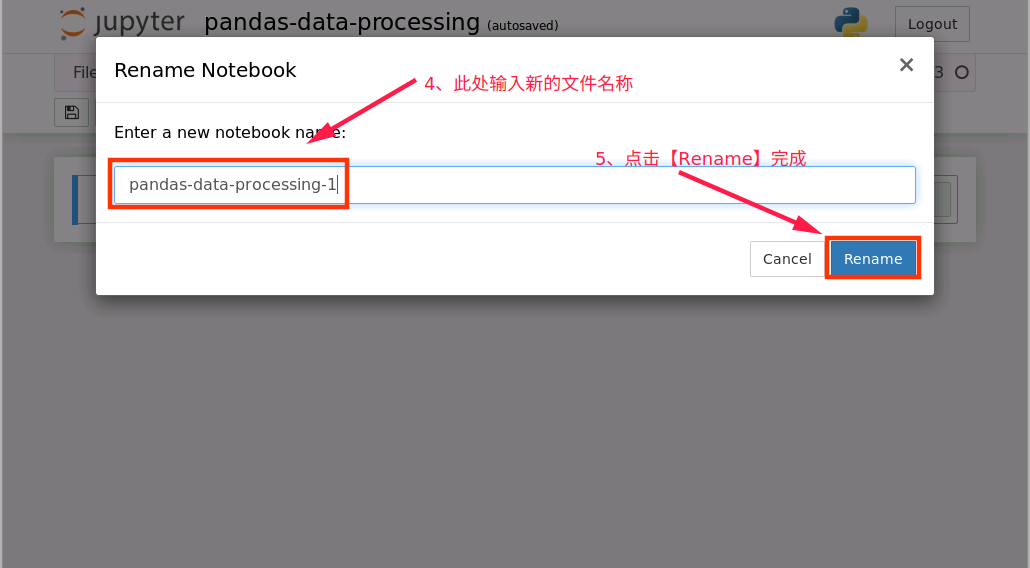
2、notebook 文件新建完成后,接下来在新建的 notebook 中编写代码
导入 Pandas 到我们的代码中,代码如下
import pandas as pd
小提示:输入完成代码后,按下【Shift + Enter】组合键即可运行该单元格中的代码,后面输入完每个单元格的代码后都需要进行类似操作,代码才会运行
加载数据集,代码如下:
data = pd.read_csv('./data/movie_metadata.csv')
3、检查数据
查看数据集前5行
data.head()
运行结果如下图所示:
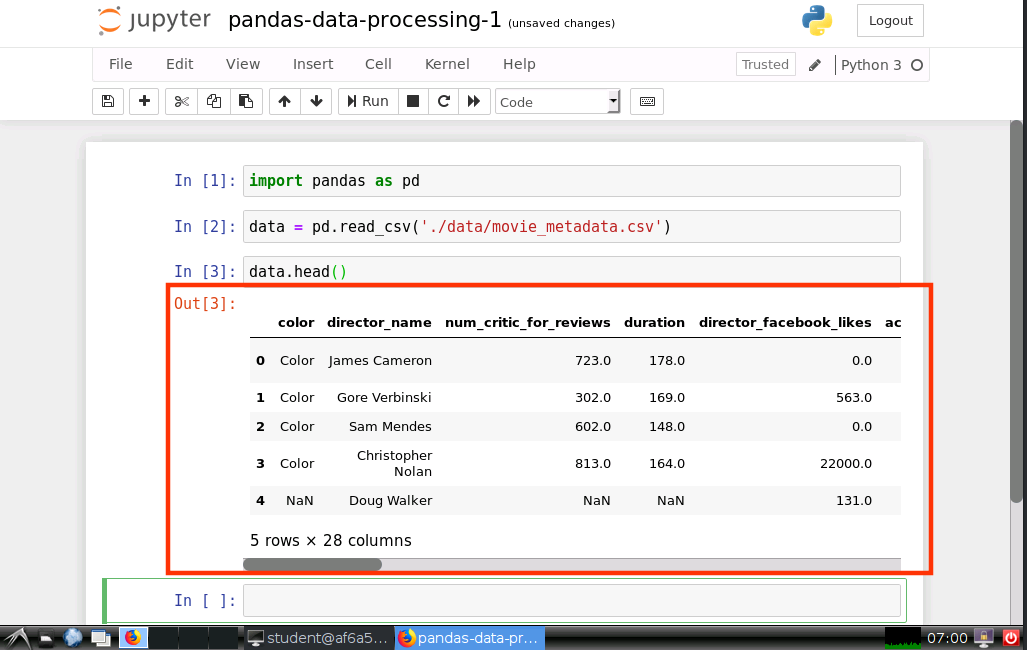
我们可以通过上面介绍的 Pandas 的方法查看数据,也可以通过传统的 Excel 程序查看数据
Pandas 提供了一些选择的方法,这些选择的方法可以把数据切片,也可以把数据切块。下面我们简单介绍一下:
- 查看一列的一些基本统计信息:data.columnname.describe()
- 选择一列:data[‘columnname’]
- 选择一列的前几行数据:data[‘columnsname’][:n]
- 选择多列:data[[‘column1’,‘column2’]]
- Where 条件过滤:data[data[‘columnname’],condition]
4、处理缺失数据
缺失数据是最常见的问题之一。产生这个问题有以下原因:
- 从来没有填正确过
- 数据不可用
- 计算错误
无论什么原因,只要有空白值得存在,就会引起后续的数据分析的错误。下面介绍几个处理缺失数据的方法:
- 为缺失数据赋值默认值
- 去掉/删除缺失数据行
- 去掉/删除缺失率高的列
4.1、添加默认值
使用空字符串来填充country字段的空值
data.country= data.country.fillna('')
使用均值来填充电影时长字段的空值
data.duration = data.duration.fillna(data.duration.mean())
4.2、删除不完整的行
data.dropna()
运行结果如下(由于输出内容给较多,结果中省略了中间部分数据,只显示开头和结尾部分):
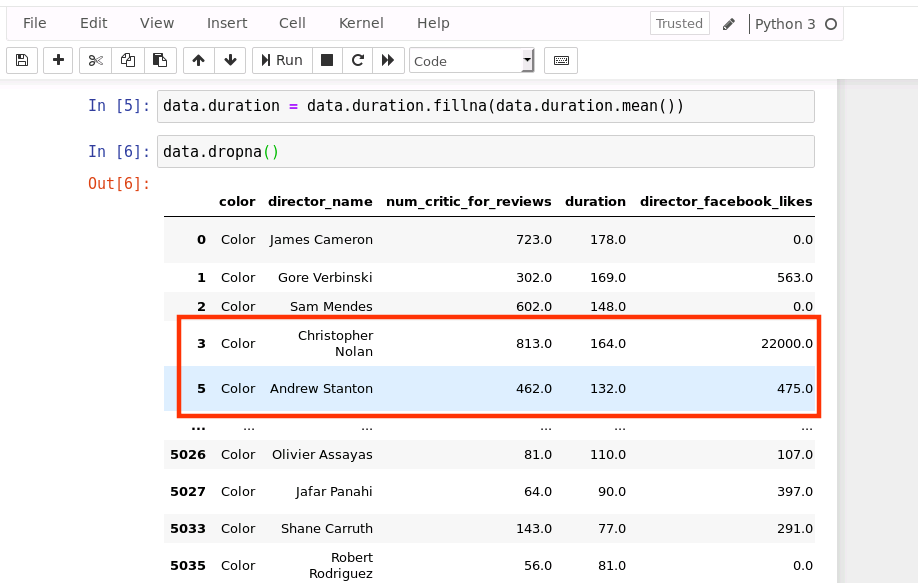
由上图可以看出,由于第4行数据存在缺失值,因此被删除
提示:dropna操作并不会在原始数据上做修改,它修改的是相当于原始数据的一个备份,因此原始数据还是没有变
删除一整行的值都为 NA:
data.dropna(how='all')
运行结果如下:
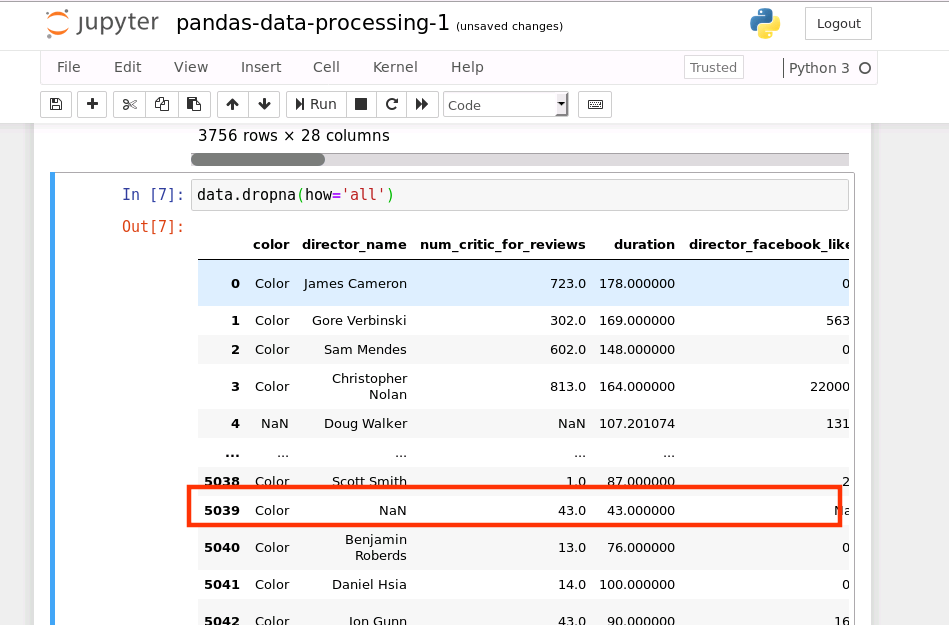
从上图可知,由于限定条件为:删除一整行都为NA的数据,因此不满足此条件的数据行还是会被保留
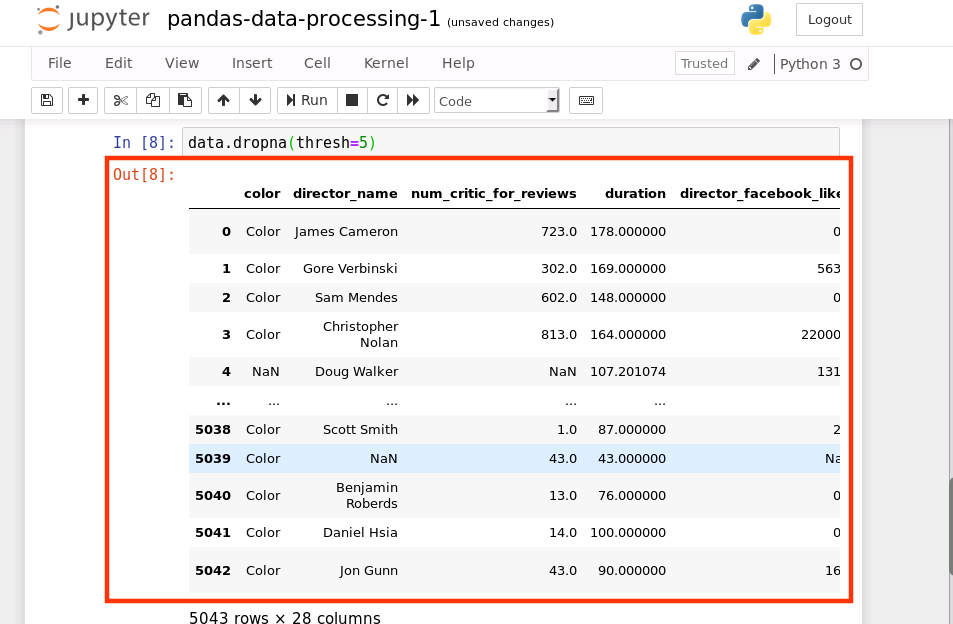
我们也可以增加一些限制,在一行中有多少非空值的数据是可以保留下来的(在下面的代码中,行数据中至少要有 5 个非空值)
data.dropna(thresh=5)
运行结果如下:
也可指定需要删除缺失值的列
我们以 title_year 这一列为例,首先查看 title_year 这一列中存在的缺失值:
data['title_year'].isnull().value_counts()
结果如下:
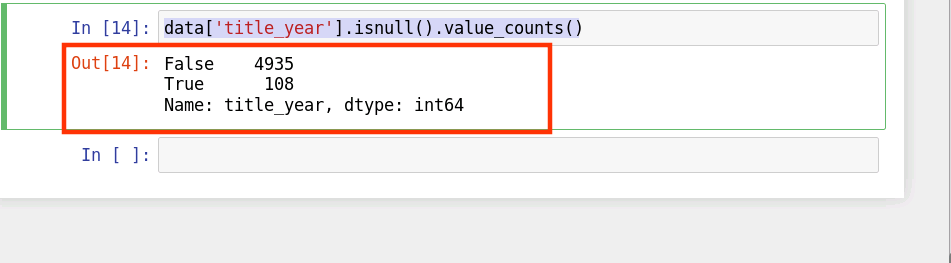
由上图可知,title_year 这一列中存在108个缺失值
接下来查看 title_year 删除完缺失值后的情况
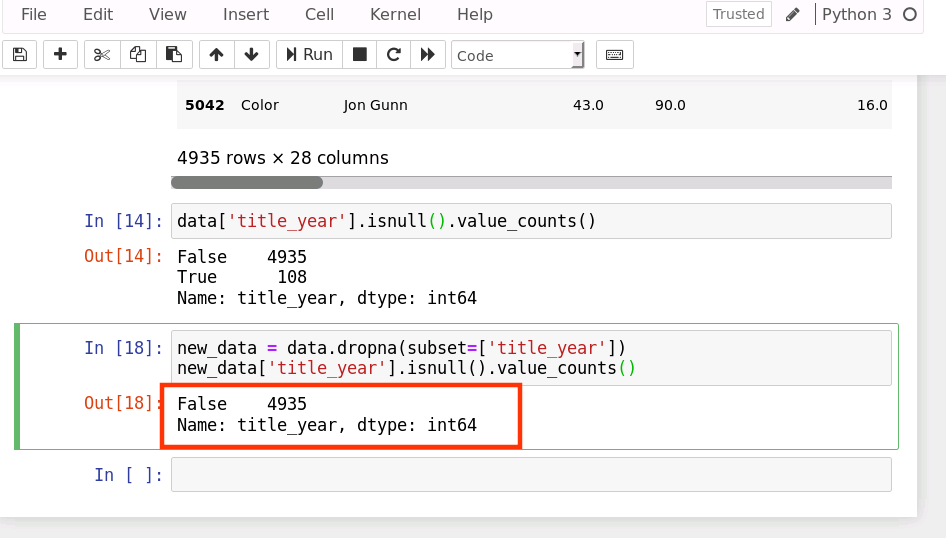
new_data = data.dropna(subset=['title_year'])
new_data['title_year'].isnull().value_counts()
上面的 subset 参数允许我们选择想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
运行结果如下:
4.3、删除不完整的列
我们可以上面的操作应用到列上。我们仅仅需要在代码上使用 axis=1 参数。这个意思就是操作列而不是行。(我们已经在行的例子中使用了 axis=0,因为如果我们不传参数 axis,默认是axis=0)
删除一整列为 NA 的列:
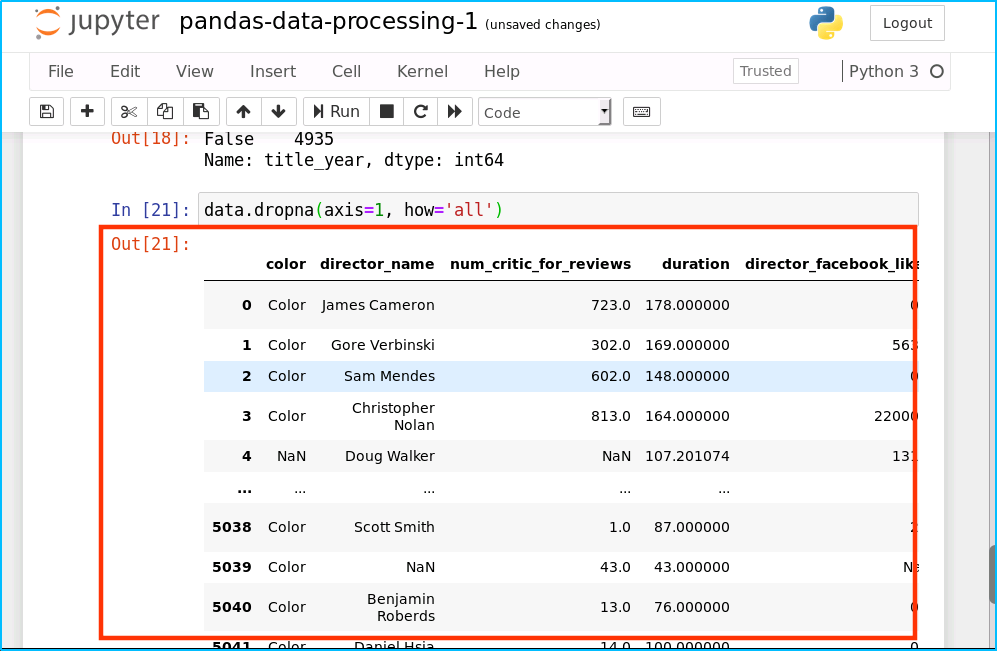
data.dropna(axis=1, how='all')
运行结果如下:
删除任何包含空值的列:
data.dropna(axis=1,how='any')
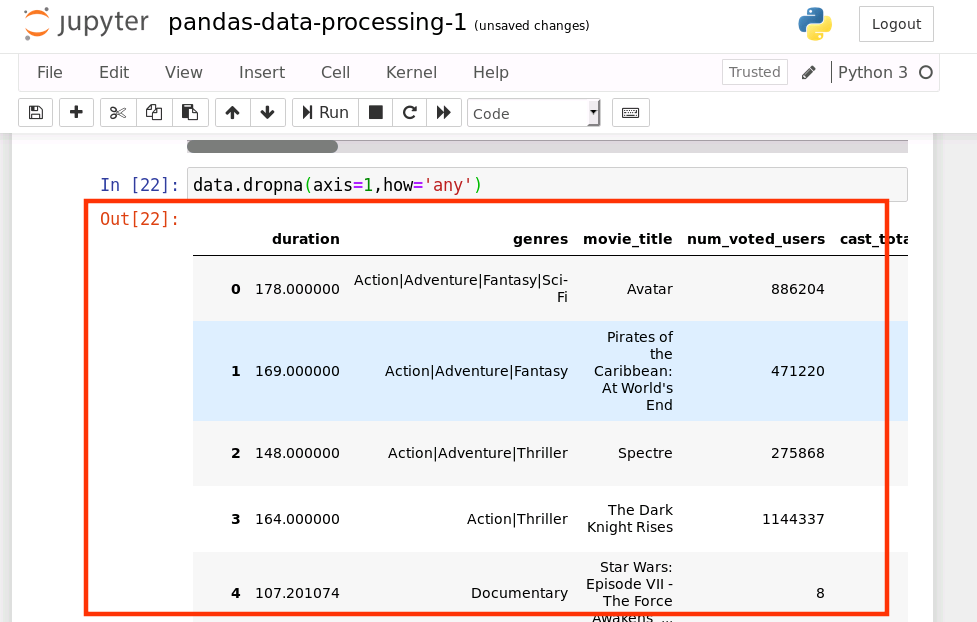
这里也可以使用像上面一样的 threshold 和 subset
5、规范化数据类型
加载数据集时指定字段数据类型
data = pd.read_csv('./data/movie_metadata.csv', dtype={'title_year':str})
这就是告诉 Pandas ‘duration’列的类型是数值类型。查看加载后各数据列的类型
data.info()
运行结果如下:
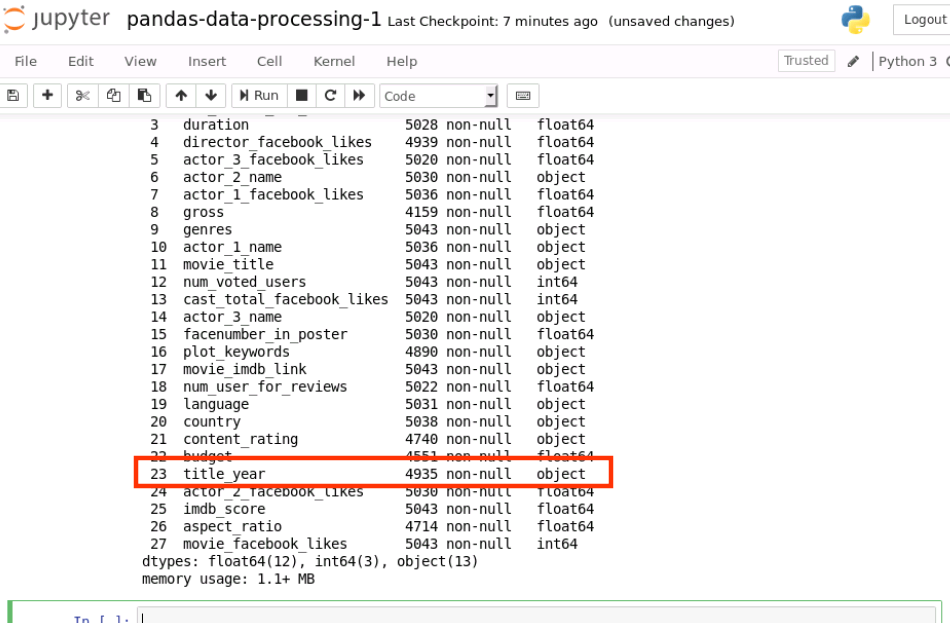
object 即代表数据类型为字符串类型
6、必要的变换
人工录入的数据可能都需要进行一些必要的变换,例如:
- 错别字
- 英文单词时大小写的不统一
- 输入了额外的空格
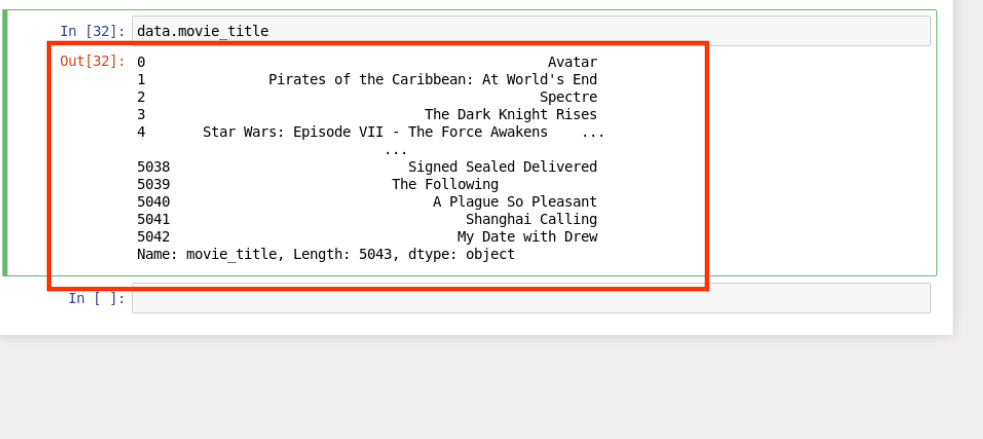
首先查看 movie_title 列数据
data.movie_title
结果如下:
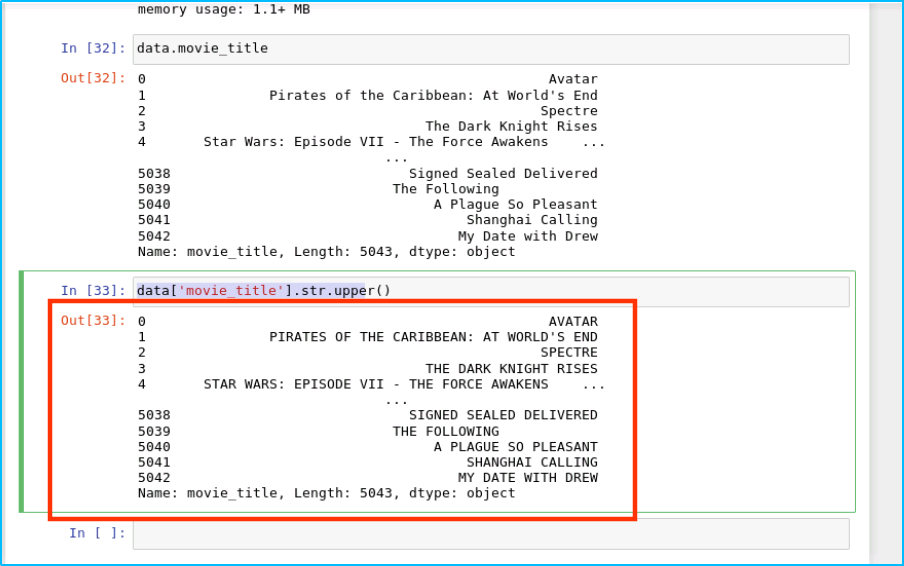
我们数据中所有的 movie_title 改成大写:
data['movie_title'].str.upper()
结果如下:
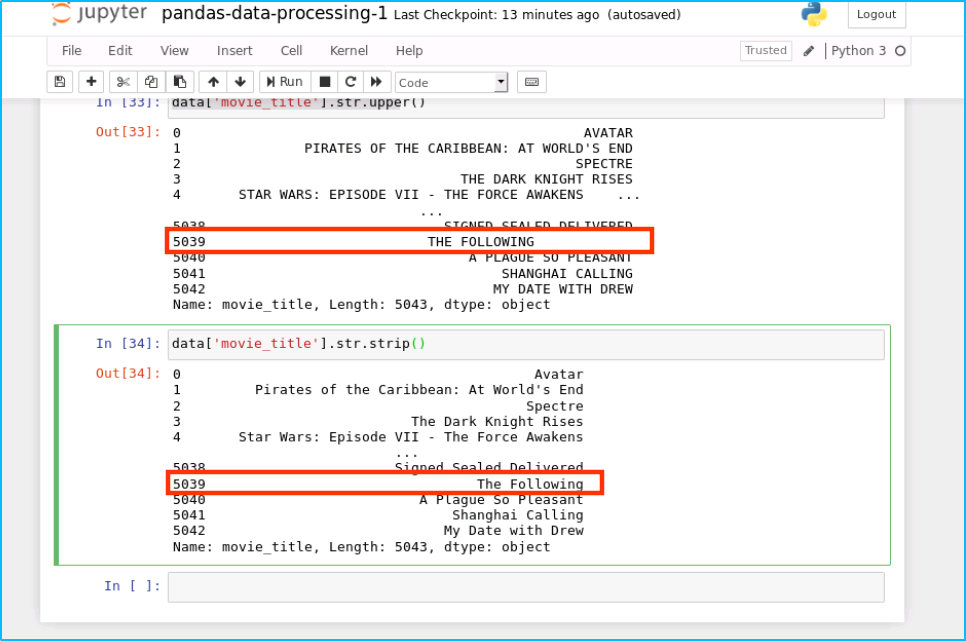
同样的,我们可以去掉末尾余的空格:
data['movie_title'].str.strip()
运行结果如下:
7、重命名列名
我们需要进行重新赋值才可以:
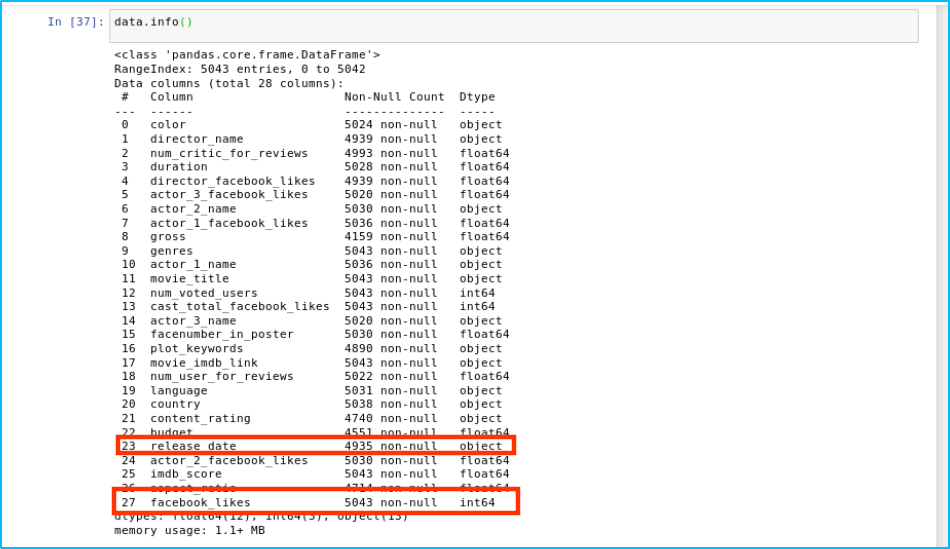
data = data.rename(columns={'title_year':'release_date',
'movie_facebook_likes':'facebook_likes'})
查看重命名后的数据列名称
data.info()
输出结果如下:
8、保存结果
完成数据清洗之后,一般会把结果再以 csv 的格式保存下来,以便后续其他程序的处理。同样,Pandas 提供了非常易用的方法:
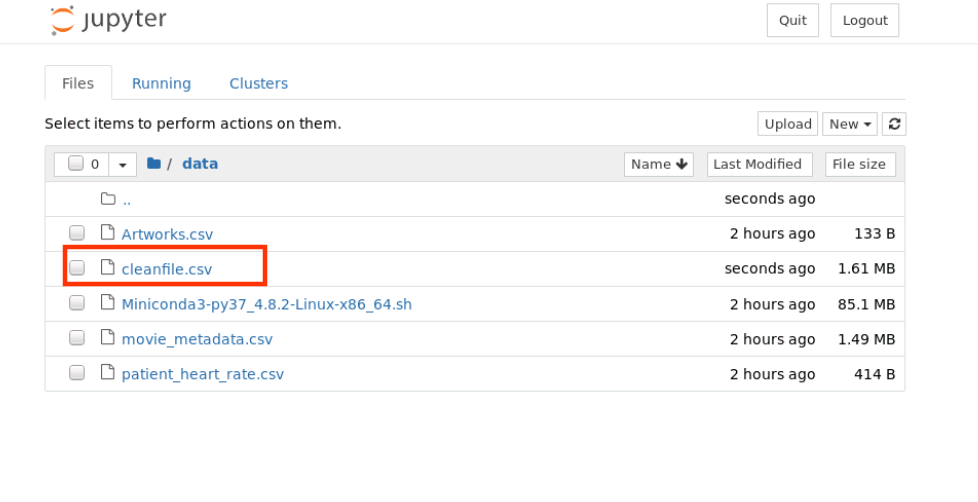
data.to_csv('./data/cleanfile.csv',encoding='utf-8')
查看 /home/student/data 目录内容如下,新增保存的 cleanfile.csv 文件