摘要
作者主要从如下几个方面展开论述:
一、提出了一个新的联邦学习框架。
二、采取后期融合的方法来解决时间序列不连续的问题。
三、实验部分主要与其它的框架进行了比较。
介绍
这一部分首先讲了抑郁症目前的现状,其次介绍了使用机器学习来检测抑郁症的一些限制。
首先,数据集的大小以及质量。传统的机器学习的性能很大程度上取决于数据集的大小以及多样性。
其次,尽管目前有许多机器学习算法用来保护隐私,但是这些隐私保护机制需要增加噪音,对算法的性能造成了一定的影响。
最后,由于不同的机构所拥有的数据存在较大差异,为了处理各种情况,算法和软件需要具有较高的泛化能力,如果没有数据交换,模型很难获得足够的准确性。
通过分析抑郁症患者的按键习惯,如两次按键之间的间隔,作为抑郁症患者的一种生物识别形式来预测抑郁症。抑郁症患者的打字速度通常与正常人不同,这可能是由于发病时的情绪不稳定引起的。
第二部分:后向融合模型
由于使用的数据集存在三个视图下的时间序列具有不同的频率且不能对齐的问题,因此在本节中,引入了模型所采用的后期融合策略,以使数据的时间序列一致。
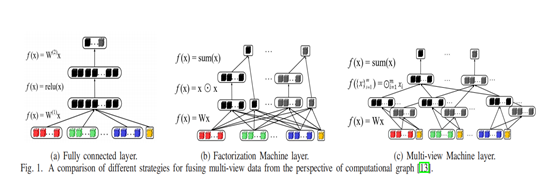
类型一:全连接层
类型二:分解层 (没有使用激活函数,而是直接进行二阶特征交叉组合)
类型三: 多视图层 :不仅考虑二阶特征,而是m阶特征交叉组合。
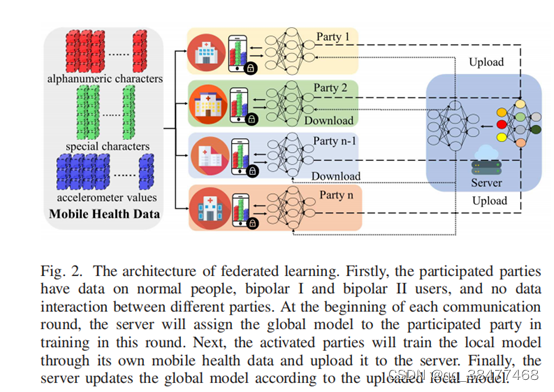
第三部分: 联邦学习框架
第四部分:实验
1)数据
主要由以下三部分组成:
a、 字母数字字符。为了保护用户的隐私,我们不收集特定的字母数字字符。只收集按键开始时间以及持续时间,按下最后一个按钮后的持续时间。(如果5秒之后用户没有按键,那么表示会话结束)
b、特殊字符 。使用one-hot进行编码
c、加速传感器数值:每隔60毫秒进行一次记录
保留了10到100个之间的按键会话,最终生成14960个样本。
2)评价指标
HDRS(汉密顿抑郁量表)
HDRS评分在0-7之间(包括)的患者为阴性样本(正常),HDRS大于或等于8的患者为阳性样本(从轻度到重度抑郁症)。
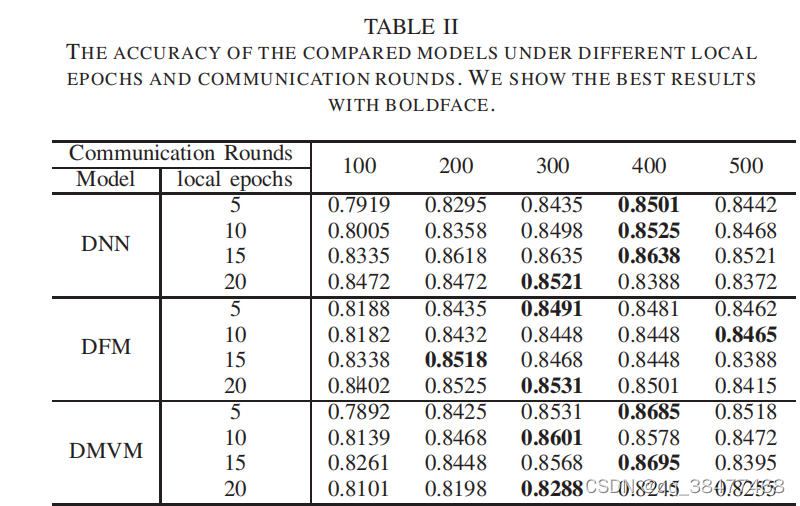
实验结果
1)随着通信轮数的增加,准确率呈上升的趋势,然后呈略有下降的趋势
2) 随着本地训练轮数的增加,准确率有所上升。但是当本地轮数增加到20轮次的时候,准确率下降了。这些结果表明,增加本地训练轮数 可以使训练更加稳定,加速收敛速度,但它可能不会使全 局模型收敛到更高的精度水平。也就是说,过度优化本地 数据集可能会导致性能损失。 (个人人为就是过拟合)
3)在前300个轮次,DFM的融合效率高于DNN和DMVM,说明融合层的改善效果,DFM得到了更好的局部损失函数最小值。与中心式学习相比,由于局部数据的急剧减少,多视图和多层次特征的DMVM融合的效果会受到一定程度的影响。
3、比较实验
3.1 IID 实验
- 比较方法:我们将FedAVG与以下方法进行比较,每种方法都代表了不同的数据交互策略。
本地训练:本地训练是指各方只使用它们自己的数据进行训练,无需与其他各方进行任何交互。
CDS:协作数据共享是一种传统的中心式机器学习策略,它要求双方将患者数据上传到中心服务器进行训练。
IIL:机构增量学习是一种串行训练方法。某一 方在训练完成后,将其模型转移给下一个参与者,直到所 有参与方都训练过一次。
CIIL:循环机构增量学习 重复IIL训练过程。
在每个实验中,所比较的模型总结如下:
DMVM:所提出的具有多视图机器层的深度情感架构,用于 数据融合。
DFM:提出的一个因子分解机层,用于数据融合。
DNN:所提出的DeepMood架构与传统的全连接层的数据融 合。
在这项工作中,对于IID设置,随机分配每个客户, 三个数据类别的统一分布:正常用户、I型双相情感障碍 患者和Ⅱ型双相情感障碍患者。
具体处理方法如下:
1.参与者所拥有的数据大小保持不变,参与者的数量在 增加。各方拥有的数据量固定在1500,参加训练的医院 数量逐渐增加 。测试了多达24个参与者的训练效果。
2.保持参与方的数量保持不变,增加了每个参与者所拥有的数据 量。将参与者的数量 设置为8个。各方拥有的数据量从100个逐渐增加,以总数 据的25%(3000)为最大值 。 为了使实验结果稳定,对每组实验进行5次实验, 并取结果平均值。
2) 评价标准: 准确率。中心服务器 可以用自己的测试集来测试最终的全局模型。在局部训练 实验中,局部数据视为一个整体,并将每个参与者 正确预测的样本数与测试集进行比较。
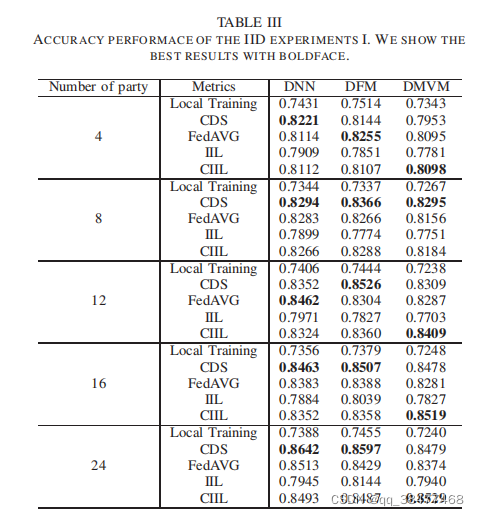
结论:增加参与方。由于本地训练没有交互式学习过程,并且每个参与者所拥有的数据量是恒定的,因此最终结果总是在73%到75%之间波动。在大多数情况下,CDS可以达到最佳的预测效果,但使用CIIL的DMVM模型的最佳效果可以达到85.29%,比不更新模型权重的局部训练高出18%左右。
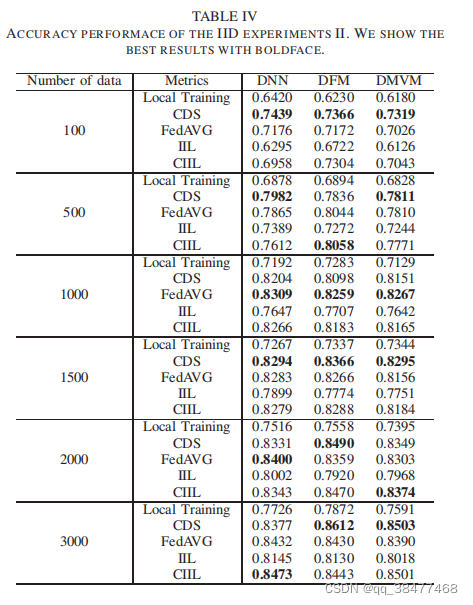
表四显示了每个参与者增加数据量的准确性性能。局部训练和FedAvg训练的准确性同时也在提高。当各方数据量较小(数据<1000)时,FedAvg与本地模型相比的改进效果可达到16.7%。当每个参与者的数据量足够大(数据=3000)时,FedAvg增强效果高达10.5%,与CIIL的结果差异很小。
3.2、 No-IID 实验
非IID实验在真实的医疗环境中,医院所拥有的数据应为非IID实验.
1)比较方法:我们所比较的模型和上述实验一样。对于非IID设置,有8个正常用户的个人数据,6个双相情感障碍Ⅰ患者数据,6个双相情感障碍Ⅱ患者数据。训练过程中共有4家医院参与,不同用户的数据量不一致。每家医院都有两名正常用户数据,1例双相情感障碍Ⅰ患者数据和1例双相情感障碍Ⅱ患者数据。
2)评价标准:准确性仍可作为评价情绪预测的标准。
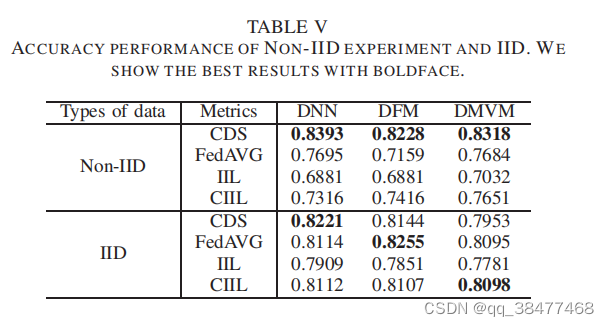
实验结果:如表V所示,non-IID设置下CDS的预测效果远远领先于分布式协作学习方法,三个模型的联邦学习预测精度分别降低了5.2%(DNN)、13.3%(DFM)和5.1%(DMVM)。非IID数据的极端分布的性质是预测效应下降的原因。我们还发现,在非IID数据下,不使用非线性函数进行特征交互的两种模型的预测效果有显著差异。由于各方拥有的患者数据数量差异较大,且患者数据类型完全不一致,二阶特征交互未能很好地拟合所有特征,其预测精度的波动大于DMVM。
4、讨论
如表三所示,当各方持有的数据量不变时,我们可以发 现,在大多数情况下,CDS对DNN和DFM模型的效果始终最 好,但在DMVM模型中,CIIL的效果最好。从表四可以看 出,当数据量为1000时,各方数据不重复,联邦学习框架 在三种模型下取得了最佳效果。当数据量为1500时,模型 第一次受到重复数据的影响。而FedAVG的预测性能略有下 降,而CIIL的预测效果仍在上升。 由于CIIL的预测精度主要取决于最后一个训练的方模型 的影响,我们推测重复的输入数据将严重影响多视图机器 层的融合交互模式。与CDS相比,CIIL最后一次参与的重复数据较少,由于最后一轮全球模型权重更新,联邦框架 会受到重复数据的影响。因此,CIIL的影响小于两种方 法,准确率最终达到85.29%。
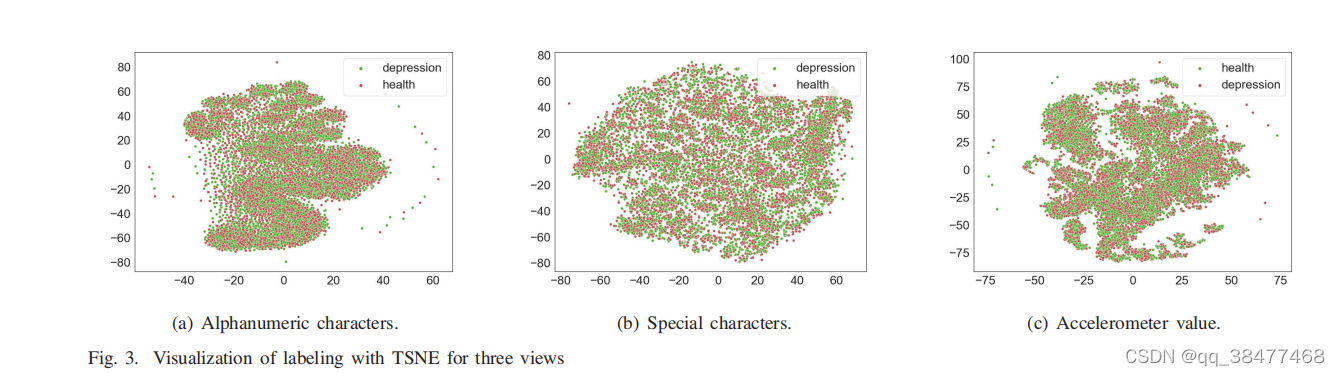
对于非IID实验,CDS仍能保持在83%左右的预测精度, 而联邦学习和CIIL的精度下降都不充分。而在非IID设置 下,联邦学习框架在DMVM模型上超过了CIIL,证明了多视 图机器层在联邦框架下的优越性。同时,non-IID实验,我们还发现在一家医院,验证集的准确性分布在50%到75% 在培训过程中,而其他医院的培训日志显示,验证集的准 确性几乎超过90%后每一轮本地培训。然而,我们还没有 处理在训练中表现不佳的参与者的权重。我们的下一个工 作是考虑构建一个适当的激励机制,以削弱贡献不良的参 与者对整体预测效果的影响,从而充分减少非IID数据的影响 模型重量。 此外,为了检验不同视图对模型预测效果的影响,如图 3所示,对每个视图的数据进行了可视化。我们发现Spec.的分布过于分散,在退格、空格、键盘切换等特殊操作中很难区分正常人和患者。(知识点补充: 数据分布越发散,离散程度越大,方差越大,模型越不稳定)。
Alph和Accel从单个视图中获得更好的可分类结果。这也从另一方面说明了正常人和抑郁症患者在打字习惯上有明显的差异,包括按键的持续时间。总之,有必要将来自不同视图
5、总结
对于数据量不同的IID数据,联邦学习的 准确率比没有进行权重更新的本地训练高出10%-15%左 右。对于非IID数据,准确率最多只能降低13%。从保护用 户隐私的角度来看,这是完全可以接受的。