2021SC@SDUSC
? ? ? ?接上篇,继续对posseg中的词性标注部分代码进行分析。
? ? ? ?在__cut_detail函数中,__cut是隐马尔科夫模型进行词性标注的执行函数。
? ? ? ?__cut函数会首先执行Viterbi算法,由Viterbi算法得到状态序列(包含分词及词性标注),也就可以根据状态序列得到分词结果。其中状态以B开头,离它最近的以E结尾的一个子状态序列或者单独为S的子状态序列,就是一个分词。
def __cut(self, sentence):
# 执行Viterbi算法
prob, pos_list = viterbi(
sentence, char_state_tab_P, start_P, trans_P, emit_P)
begin, nexti = 0, 0
for i, char in enumerate(sentence):
# 根据状态进行分词
pos = pos_list[i][0]
if pos == 'B':
begin = i
elif pos == 'E':
yield pair(sentence[begin:i + 1], pos_list[i][1])
nexti = i + 1
elif pos == 'S':
yield pair(char, pos_list[i][1])
nexti = i + 1
if nexti < len(sentence):
yield pair(sentence[nexti:], pos_list[nexti][1])
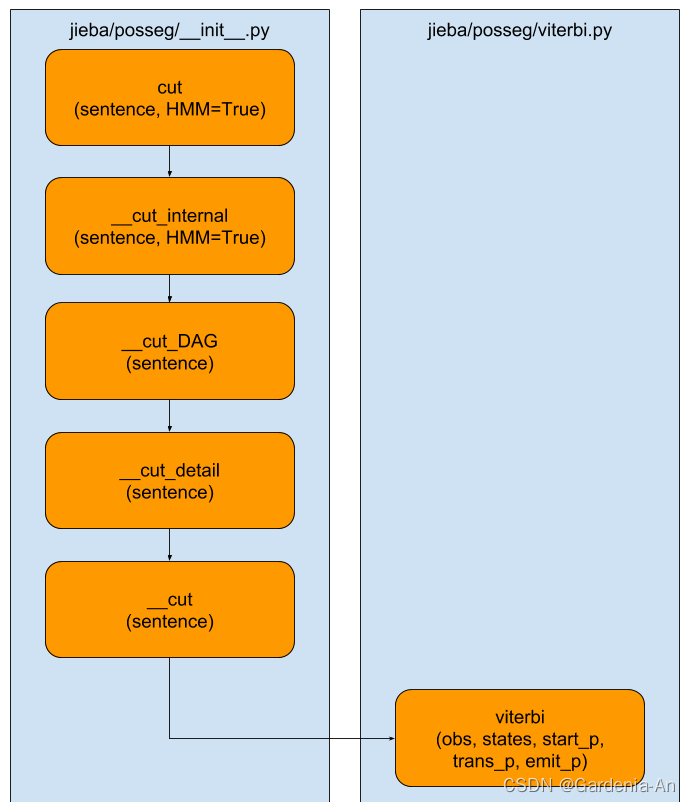
下图为jieba/posseg/__init__.py及jieba/posseg/viterbi.py两个文件中相关函数之间的关系。
在分析viterbi算法之前,我们先来看一下HMM参数的载入。
在jieba/posseg/_init_.py的开头就载入了HMM的参数,包括初始几率向量,状态转移几率矩阵,发射几率矩阵及CHAR_STATE_TAB_P这个字典(记录了各个汉字可能的状态和词性)。
如果是使用Jython的话,需要用到?load_model()这个函数,里面使用pickle 这个方法载入参数。
如果是使用Python的话,直接使用from ... import ...即可。
PROB_START_P = "prob_start.p"
PROB_TRANS_P = "prob_trans.p"
PROB_EMIT_P = "prob_emit.p"
CHAR_STATE_TAB_P = "char_state_tab.p"
re_han_detail = re.compile("([\u4E00-\u9FD5]+)")
re_skip_detail = re.compile("([\.0-9]+|[a-zA-Z0-9]+)")
re_han_internal = re.compile("([\u4E00-\u9FD5a-zA-Z0-9+#&\._]+)")
re_skip_internal = re.compile("(\r\n|\s)")
re_eng = re.compile("[a-zA-Z0-9]+")
re_num = re.compile("[\.0-9]+")
re_eng1 = re.compile('^[a-zA-Z0-9]$', re.U)
def load_model():
# For Jython
start_p = pickle.load(get_module_res("posseg", PROB_START_P))
trans_p = pickle.load(get_module_res("posseg", PROB_TRANS_P))
emit_p = pickle.load(get_module_res("posseg", PROB_EMIT_P))
state = pickle.load(get_module_res("posseg", CHAR_STATE_TAB_P))
return state, start_p, trans_p, emit_p?