?模型建立与评估
导入模块读取文件
#数据建模
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
%matplotlib inline
a=pd.read_csv('train.csv')
b=pd.read_csv('clear_data.csv')
b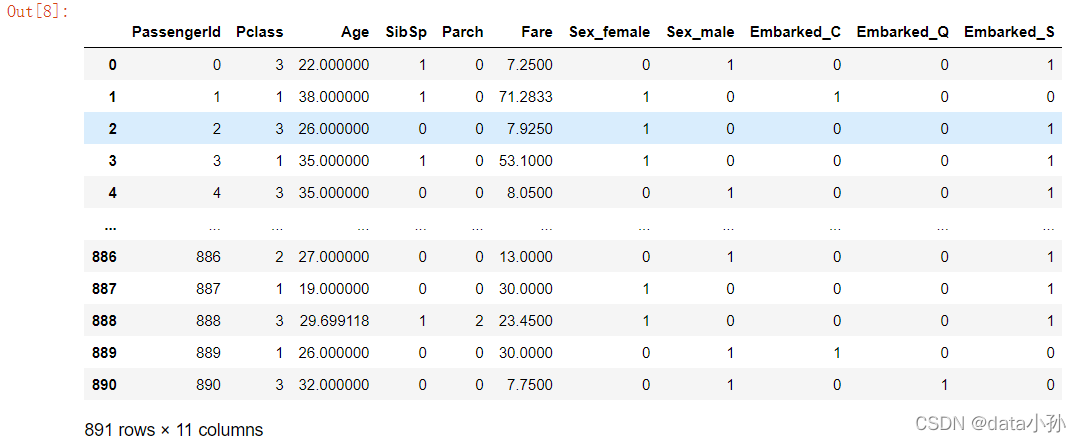
?数据集分割
#分割数据集
from sklearn.model_selection import train_test_split
X = b
y = a['Survived']
X_train,X_test,y_train,y_test = train_test_split(X,y,stratify=y,random_state=0)
X_train.shape,X_test.shape?切割数据集是为了后续评估模型泛化能力

?random_state表示随机种子数,随机种子数是为了保证模型结果可以复现
stratify是为了爆保持split前类的分布
模型搭建
处理完前面的数据我们就得到建模数据,下一步选择合适模型预测
在进行模型选择之前我们需要知道数据集最终是进行监督学习还是无监督学习
除了根据我们任务来选择模型外,还可以根据数据量以及特征的稀疏性来决定
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
逻辑回归
lr = LogisticRegression()
lr.fit(X_train,y_train)
随机森林模型
lr = RandomForesClassifer()
lr.fit(X_train,y_train)
?在监督模型里面sklearn里面predict能输出预测标签,predict_proba输出标签概率,输出标签概率是为了判断标签可信度,接近1的可信度越高。
#输出模型结果
pred = lr.predict(X_train)
pred[:10]
pred_proba = lr.predict_proba(X_train)
pred_proba[:10]模型评估
K折交叉验证-----下面是10折交叉验证?

lr = LogisticRegression(C=100)
score = cross_val_score(lr,X_train,y_train,cv=10)混淆矩阵
还有一个评估模型方法----混淆矩阵
pred = lr.predict(X_train)
confusion_matrix(y_train,pred)
from sklearn.metrics import classification_report
print(classification_report(y_train,pred))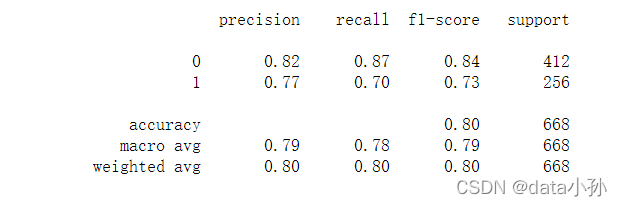
?ROC曲线
ROC曲线在sklearn.metrics
ROC曲线下面包围面积越大越好
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")
# 找到最接近于0的阈值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)

?tpr(召回率)fpr(假正率)