2021SC@SDUSC
之前博客都是介绍生信方面的文章,最后一篇就写一点关于传统会议的介绍文章了。
CVPR 2021 | PLM:用于不平衡多标签分类的部分标签掩膜方法
这篇博客介绍的是佛罗里达大学大学Kevin Duarte等人发表在CVPR2021上的一篇文章 ”PLM: Partial Label Masking for Imbalanced Multi-label Classification”。作者在这篇文章中指出用具有长尾标签分布的数据训练神经网络有着向高频类别的倾向并且在低频类别上表现较差。作者提出了部分标签掩膜PLM方法,通过在损失计算时随机掩膜标签平衡了每个类别的比率,在绝大多数类上实现了召回率和精度的提高。目前绝大多数存在方法处理数据不平衡主要聚焦于单标签分类并且在多标签情况下并不能泛化很好,PLM解决了这样一个长尾数据不平衡的问题,其能用于绝大多数目标函数并且能够和其它类别不平衡的方法一起使用。PLM相比目前在多标签和单标签图像分类上实现了更好的效果。

一、研究背景
深度学习方法优异的表现导致了大规模的数据集的创建,由于真实世界的对象自然而然的不平衡分布,使得这些数据集包含了不同类别不平衡的样本数目。这些数据集的类标签来自于一个长尾分布,仅仅有几个类别包含更多的样本作为高频类,然而许多类包含较少的样本作为低频类。这个不平衡造成了分类表现较差,尤其是在不通常的类别上。目前绝大多数工作聚焦于单标签假设,LDAM-DRW在单标签设置上表现的非常好,主要是对于提出的损失计算类边距,此外还有其它方法。作者的实验表明,在多标签数据集上,基于每种形式的样本数量的倒数进行权重加权的效果不好。而且由于单个样本的共同出现是非常困难的对于多标签数据重新采样。考虑到标签不平衡应用场景丰富,作者坚信类别不平衡应该被研究作用于为多标签和单标签分类。于是作者在这个工作中提出了一种用于长尾不平衡的通用解决方案。
在不平衡多标签数据机上训练的分类器倾向于预测高频的类别使得输出的概率得分倾向于1,低频的类别概率得分较低。这些输出的概率分布不同于负样本被标记为0正样本被标记为1的理想分布。作者指出原因不仅仅是因为正样本的类别不平衡,而且和正负样本的比例有关。作者指出负样本和正样本的比例越大的类导致错误的正样本预测数增大。假设存在最优的比率能减少这种预测情况,一个算法能评估和利用这个比率去提高网络性能。
作者提出了部分标签掩膜PLM:一个新颖的在不平衡多标签数据集上训练分类器的方法,通过利用比率提高了模型的泛化能力。如图1所示通过部分的掩膜正负标签的类别,作者的方法减少了分类器输出概率分布和真值分布的差异。作者的方法对每个样本随机地掩膜并且持续调整目标比例。这样提高了多数样本的准确率和少数样本的召回率。此外,无论样本的数目有多少作者的方法都提高了难以区分类别的性能。
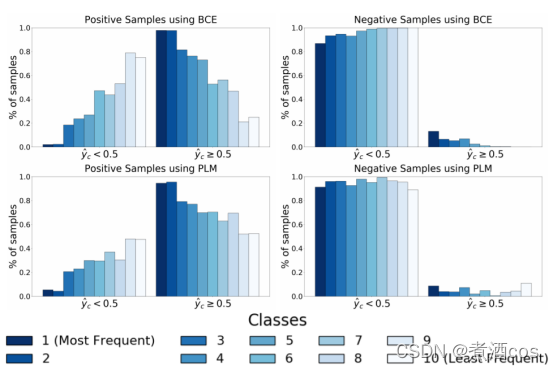
图1.输出的概率分布
二、模型与方法
作者假设数据集有N个样本和C个类别,xi是第i个输入,yi是对应的二值标签向量,如果某个样本对应的类别标签是1,那么这个类别对应的样本数加1。
2.1 部分标签掩膜
给定一个网络的预测,总的损失为C个类别的损失可以用如下二值交叉熵来计算:
通过部分标签掩膜PLM仅仅计算某几个类的损失,于是对于每张图像i作者产生一个二值掩膜g掩膜损失计算用于某几个类:
2.2 掩膜生成
这样的公式能产生掩膜,使得通常类别样本在损失计算中被忽视,类别相同数目的样本是被用来训练网络。作者指出下采样采样带来的问题是通常和不通常的类能共同出现在同一个样本中,因此移除这样的样本对于类别不平衡是没有意义的。PLM的优点是单个的正负补签能被掩膜从而确保每个类别的标签有一个特定的数目用于训练网络而不用在乎标签的共现。作者在采样的过程中考虑到了每个类别rc正负样本的比例。假设存在理想的比率作者能产生掩膜g(i)作为一个标签函数:
2.3 比率选择
每个类别正负样本的比例应该被设置最小化头类的高估和尾类的低估情况。因为减少了正样本数目的比例,增加了负样本数目的比例,头类被选择的理想比率应该被减少。另一方面,尾类的理想比率应该被增加。
一个简单的设置比率的方式应该被设置为全部类别的平均比率。这确保了头类比率的减少,尾类比率的增加。尽管这使得在某些数据集上有了改善,但是它对数据集中不同程度的不平衡和各种类别的相对难度比较敏感。理想的超参应该随着分类器的性能而改变。为此,作者提出了一种基于分类器输出概率分布的方法评估比率。
2.4 比率适应
对于一个类别c,和分别表示正负样本输出概率的集合。相应地和表示真值集合用1和0表示。这些集合能被定义如下:
通过将这些概率以宽度为1/τ的τ箱子中能够形成一个离散的分布。对每个集合,我们假设这些分布为。当数据不平衡出现时,分类器的输出概率向着真值分布。那么对于头类负样本的概率分布增加,对于尾类正样本的概率分布增加。作者使用KL散度去更好地将输出分布近似于真值分布:
作者正则化分布:
作者指出在训练过程中调整直到和相等。在每一次迭代后比率应该按照如下变化:
其中Dc为和的差值。
三、实验结果
3.1 多标签分类
作者在两个多标签数据集上MultiMNIST和MSCOCO上评估方法。作者通过叠加两个MNIST数字成单张图像构建不平衡MultiMNIST数据。作者使用多个标准的多标签分类指标,每类的准确度,每类召回率,F1-得分和0-1精确匹配精度评估分类器性能。此外,作者使用一些指标的平均评估长尾类别的性能。图2展示了在MultiMNIST上的结果,可以看到在训练过程中使用PLM提高了在各个指标上的结果。
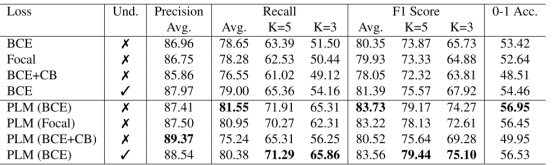
图2. 在MultiMNIST上的分类结果
在MSCOCO上的结果在图3上可以看到,作者发现为单标签数据不平衡设计的传统方法像focal loss倾向于表现不佳的二值交叉熵训练,尽管在尾类上有所提高,但是在头类的性能下降导致了整体的性能下降。PLM实现了在Recall和f1-score上的全面提高。
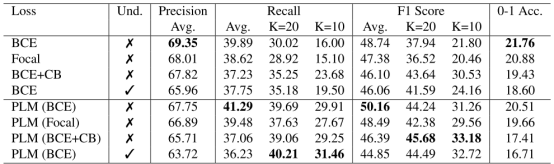
图3. 在MSCOCO上的分类结果
3.2 单标签分类
作者使用的数据集是CIFAR-10和CIFAR-100,图4和图5展示了PLM在两个数据集上的结果。对于5个不平衡的因素,PLM相比于通用的数据不平衡的方法实现了提高。尽管LDAM-DRW有一个更低的错误在单标签评估上,但该方法并不能应用于多标签分类。可以看到作者的方法在单标签和多标签上实现了更强的性能。
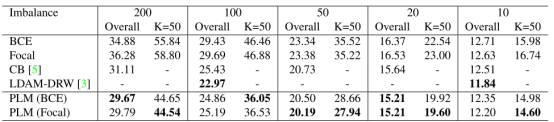
图4. 在CIFAR-10上的分类结果的错误率
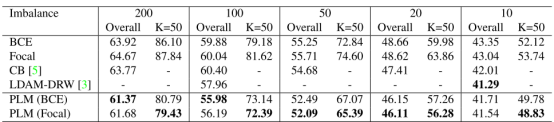
图5. 在CIFAR-100上的分类结果的错误率
四、总结
在这个工作中,作者提出了一种通用的方法PLM用于长尾数据不平衡问题。作者的部分标签掩膜算法利用每个类别正负样本的比例极大的提高了在不通常和困难类的性能。不像绝大多数数据不平衡方法,PLM成功的用于多标签设置。此外,PLM能和绝大多数已存在的数据不平衡方法共同使用。作者在多个数据集评估PLM并且进行额外的分析验证有效性。
参考资料
Duarte, Kevin, Yogesh S. Rawat, and Mubarak Shah. “PLM: Partial Label Masking for Imbalanced Multi-label Classification.” arXiv preprint arXiv:2105.10782 (2021).