
���ĵ�ַ:
��Դ:CVPR 2021
����Ŀ¼
1. ����֪ʶ
����������Ա༭ģ��������������Ҫ��:(1)������ȷ�ԡ���Ŀ������Ӧ����ȷ�����ڱ༭�������ͼ����; (2) ����ر��桪���κβ���ص���Ϣ(������)�ڱ༭��Ӧ���ġ�
-
���з���һ:���ڿռ�ע����
������ÿ�����Զ��оֲ�֧������,����ʹ�ñ�����-������ GAN ��ܵ�����ͼ�ϵ�ע����ģ�����Щ������н�ģ�� һ��ȷ������Щ֧������,�Ϳ��Խ�ͼ������������Щ����,�Ӷ���ֹ��������������Ҫ�ı仯�� ����������һЩ�ֲ���������Ч��,�����������۾��� Ȼ��,���漰������Ц/�Ա�/����֮���ȫ������ʱ,�����������,��Ϊ֧��������ȫ�ֵ�,��������֮����ص��Dz��ɱ���ġ� -
���з�����:DZ�ڿռ�ֽ�Ϊ��������ص�DZ�ڴ���
����һ���̶���Ԥѵ�� GAN,DZ�ڿռ�����ͨ���ӿռ�ͶӰӳ�䵽ÿ�����ԡ� ����,���ַ���������������:(a)�������ڹ̶���Ԥѵ�� GAN ���ṩDZ�ڿռ䡣 ���û��ʹ�÷ֽ�ģ�ͽ��ж˵��˵�ѵ��,���DZ�ڿռ�����Ǵ��ŵġ� (b) �������ǩ��������,��ֻ�ܽ���ͬ�������������� Ȼ��,����ͼ����һЩ��������û����һ��Ԥ���������������,�������ݺ���������
��ع���:
- GAN
- �������Ա༭:
- �༭����ͼ:STGAN �������Բ���ָ��,Ȼ�������ͼ����ѡ����ת�� �������Ա༭�ı�����-�������� MaskGAN ��������ͼ�������������б���ȱ��ֵ�����沿������ WrapGANѧϰ��������Ƭ��������Ա༭��ƽ���������� PA-GAN �� CAFEGAN Ӧ�ÿռ�ע�����������������صľֲ�֧������,Ȼ������Щ�����ڽ������Ա༭�� ���,����ͨ�����ʺϾֲ�����(��������)������ȫ������(����Ц)��
- DZ�ڿռ�༭:Fader Network���öԿ���ѵ����DZ�ڿռ��з������������ص�DZ������/���롣 AttGAN �������� GAN ѧϰ��DZ�ڿռ�֮��Ĺ�ϵ���н�ģ�� GeneGAN �� ELEGANT ͨ��������������ص�DZ�ڴ�������������֮�佻�����ԡ� InterfaceGAN �� In-Domain GAN Inversion רע��ͨ���ӿռ�ͶӰ���� GAN DZ�ڿռ�����塣
����������㷨���ڵڶ��֡�
2. �����㷨
2.1 �㷨����
X �� Y �ֱ��ʾ��ʵ����ͼ��ļ��ϺͿ�����ļ���(������Ե�ֵ)�� ����һ������ͨ���ж��ֵ(����),Y �Ĵ�С�������Ե������� ����,����һ������{Ц,�Ա�},���ܵ�����{Ц������,��Ц������,Ц��Ů��,��Ц��Ů��}�� ����ÿ������/Դͼ�� x �� X,��Դ��(��Դ����ֵ)��ʾΪ y �� Y������Ŀ���� ?y �� Y,�沿���Ա༭ģ�͵�Ŀ����ѵ��ͼ���� ��ʾΪ T ��ת������,���ںϳ��µ�/Ŀ��ͼ�� ~x,������� y ����Ϊ ~y,�����������ص���Ϣ(����,���ݻ���������)�� �������������Ա༭ģ�Ϳ�����ʽ����Ϊ ?x = T(x, y, ?y)��
L2MGANģ��������ģ�����:��ʽ����������ʽת��������������Ϊ�˸������������ǵ�L2M-GANģ���Լ����ŵļ���,��������|Y|=2,��ֻ����һ�����ԡ�
-
��ʽ������:����һ������ͼ��x �� X,��Դ��y �� Y,���ǵ���ʽ������SE��ȡ����ʽ�����ʾΪs = SEy(x) �� Rd(��ʽ),����d����ʽ�����ά��

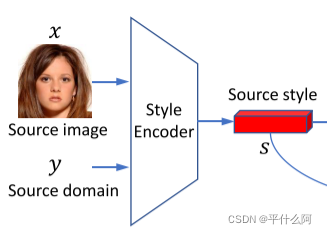
-
��ʽת����:����ʽ������SE��ȡ����ʽ����s �� Rd��������ͼ��x�ķḻ������Ϣ����Щ��Ϣ�����Ȥ���������,����һЩ����ء����,�б�Ҫ��dάDZ�ռ������ʽ�ֽ�,�Խ���ֽ�Ϊ�����������������,��ʽ����s���Էֽ�Ϊsre �� Rd��sun �� Rd,����sre��ʾ��y��ص���ʽ����,sun��ʾ��y��/�ص���ʽ�����������ڱ༭�����н���ת��������ص���ʽ����sre,������DZ���ΪĿ����?y���������ʽ����?s,�������������ͼ�������������ֻ�е�sre��sun�ʱ,����п��ܡ�Ϊ��,��������������������������������ʧ����ע��,����ǰ�Ļ����ӿռ�ͶӰ��DZ�ռ�ֽⷽ����Ҳ������������ ������,����רע������֮��Ľ����,�����ǽ���������ص���ʽ�����벻��صĴ��� (��,������������,�������������Լ�������Ϣ,����������) �ֿ�������ڲ���صı���������Ҫ,��Ϊ�������Բ��Ḳ������ͼ������в������Ϣ��
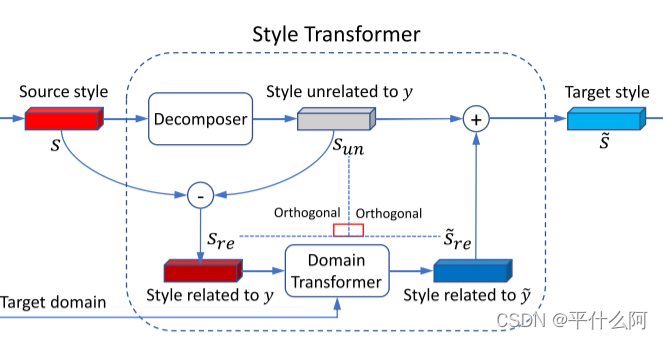

P������ȡ�����ԡ� -
������:StarGAN v2
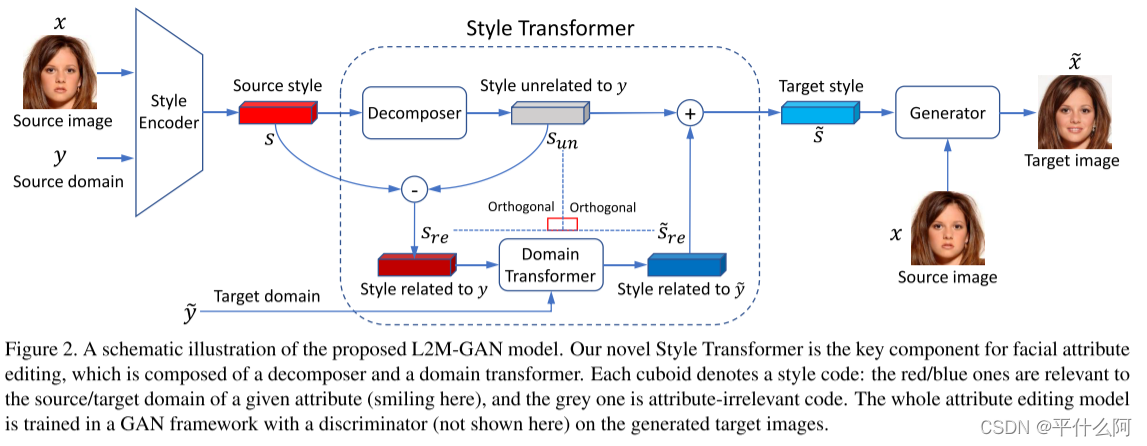
2.2 ��ʧ����
-
�Կ�����ʧ:

-
ѭ��һ����ʧ: ����ȱ����ԵIJο�ͼ��(����,ͬһ���˼�Ц�ֲ�Ц)��Ϊ�ල,����ѡ������ѭ��һ������ʧ

-
��ʽ�ع���ʧ:Ϊ�˸��õ�ѧϰ����ͼ��ϳ� w.r.t. �ķ������� SE �������� G�� ������ʽ���� ?s,���ǶԴ� ?x ����ȡ����ʽ����ʩ������ʽ�ع�Լ��

-
ͼ���֪��ʧ:F����ResNet18

-
��������ʧ:Ϊ�˱�֤��ʽ���� sun �� sre(�� ?sre)����,���Ƕ�������������ʧ��ֱ�Ӻ�������֮���������ϵ

������ʧ:

2.3 Ӧ��
- ��ͬǿ�ȱ༭
������ص���ʽ����:sre
����:~sre-sre


- ʹ�ø���ͼ�����
Դͼ��:xs,��y,������ss
�ο�ͼ��:xr,��~y,������sr

3. ʵ��
���ݼ�:CelebA-HQ
3.1 ����ʵ��

3.2 ����ʵ��
��������ָ��:���Բ���ȷ�Ժ�����ͼ���������
����,���ṩ�û��о���������������ۡ�
- ���Բ�������
���Բ����������������ض������ڲ������Ƿ���ȷ���������ɵ�ͼ���ϡ� Ϊ�˻���������,����ʹ�� ResNet18 ��ѵ������ΪЦ����ѵ����һ����Ԫ������,�������ڲ��Լ��ϴﵽ 95% ���ϵ�Ԥ�⾫�ȡ� �� 1 ��ʾ���ǵ� L2M-GAN �ڴ˹�����ȷ�Զ������������о�������,������ѵ�����ǵ�ģ��ʱû��ʹ�����Է������� StarGAN ʵ������Խϸߵ����Բ�������,��������ͼ�������½�(����һ��)�� PA-GAN ��ȷ�����(ֻ�� 48.2%),���� PA-GAN �ڱ༭��˾�����ս�Ե�����ʱ��ͼ����IJ��㡣
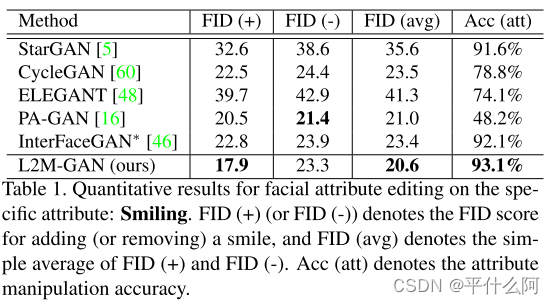
- ͼ������
���Dz���FID]���������ɵ�ͼ���������FID����ѵ�����е���ʵͼ�������ɵ�ͼ��(�����в���ͼ��ϳ�)�ķֲ�֮��ļ��㡣��1��ʾ�����ֱȽϷ��������ǵ�L2M-GAN��FID�÷֡����ǿ��Թ۲쵽,���ǵ�L2M-GAN������õ�ƽ��FIDscoreֵ,��������������ɳ�������ߵ�ͼ���ر���,���ǵ�L2M-GAN�����еľ������ֶ����������ĸĽ�����������������ԵĶ�����������ڲ���������ҵ���
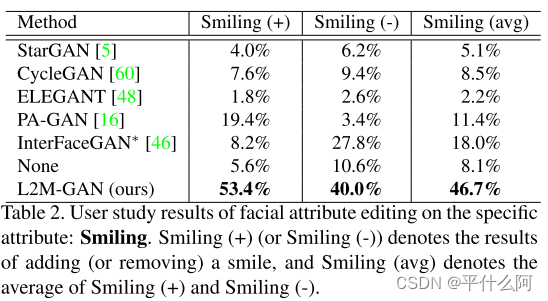
- �û��о����
���ǻ��������û��о�,�����������֪�µ����Ա༭����� ������˵,���ǽ�����Ц��ȥ��Ц��Ϊ�����༭����,��Ϊÿ���������ѡ�� 50 �Ų���ͼ��(���з���ʹ����ͬ������)�� ����ÿ�Ų���ͼ��,Ҫ�� 10 ��־Ը�������з�����õ�ͼ����ѡ����õ�����ͼ��,����:1) �����Ƿ���ȷ����; 2)�������Ƿ����; 3)���ɵ�ͼ���Ƿ���Ȼ���档 ��Ϊ����Ц���Էdz�������ս��,���ǻ��ṩ�ˡ���Щ������û�б��ֺá���ѡ��,�Ա������û���˿��Ժܺõز������Զ�־Ը�߱���ѡ����õ������ Ϊ�˹�ƽ�Ƚ�,��ͬ�������ɵ�ͼ�������˳����ʾ�� �� 2 ��ʾ������ 10 ��־Ը�ߵ�ƽ���û��о������ ��������ؿ���,���ǵ� L2M-GAN ���û��о����������ھ������֡�
3.3 ����ʵ��
�����о�����ʾ���ǵĸ�֪��ʧ����������ʧ�Ĺ���
(1) BL (Baseline) �C StarGAN v2;
(2) BL+PL �C ���и�֪��ʧ (PL) �� StarGAN v2;
(3) BL+PL+OL (Single) �C StarGAN v2 �ĸ�֪��ʧ����������ʧֻ�з��̵ĵ�һ�
(4) BL+PL+OL (Inner) �C StarGAN v2,��֪��ʧ����������ʧ���з��̵����
(5) BL+OL (L1) �C StarGAN v2 ֻ����������ʧ���з��̵����� L1norm �
(6)���������� L2M-GAN ���Ա�ʾΪ BL+PL+OL (L1),�� StarGAN v2,���֪��ʧ����������ʧ���з��̵����� L1 �����

eq6��������ʧ����
3.4 �������Բ�������Ľ��
-
����ǿ�Ȳ���

-
ʹ�òο�ͼ����в���

-
�����Բ���

-
�������������ķ���

�ܽ�
���ǵ���Ҫ������������:
(1) �����״������һ�ֶ˵��˵� GAN ģ��,�� L2MGAN �����沿���Ա༭,�����ǽ� GAN ��DZ�ڿռ�������ʽ�ֽ�Ϊ������غͲ���صĴ��� .
(2) Ϊ�˱���DZ�ڿռ�ֽ�,���������һ����ӱ��ת����,ͨ���ڱ༭/ת��֮ǰ��֮��Էֽ��������غͲ���ش���ʩ��������Լ����
(3) CelebAHQ [23] �ϵĴ���ʵ�����,���ǵ� L2M-GAN �����Ƚ��ļ���ȡ�������ŵĸĽ��� ��Ҫ����,һ��ѧϰ,���ǵ� L2M-GAN �Ϳ��Թ㷺�����������Բ�������(����,����ǿ�Ȳ�����ʹ�òο�ͼ��IJ���)����������ѵ��,���һ����Ժܺõش���Ƭ����������������
������ GAN �������һ�ֻ���DZ�ڿռ�ֽ�������沿���Ա༭ģ�͡� ������� L2M-GAN �ǵ�һ������DZ�ڿռ�ֽ�������沿���Ա༭�Ķ˵��� GAN ģ��,�Ծֲ���ȫ�����Ա༭����Ч�� ��������һ�����͵�ת����,��ͨ����ת��֮ǰ��֮��ǿ��ִ��������,��DZ�ڴ���ֽ�Ϊ������غͲ���صIJ��֡� ����ʵ�����,���ǵ� L2M-GAN �����Ƚ��ļ���ȡ�������ŵĸĽ���