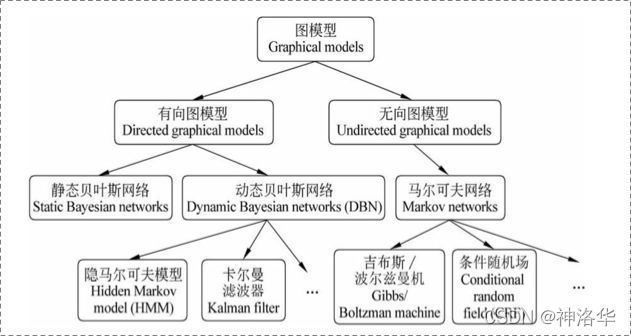
����Ŀ¼
һ������ͼģ��
1.1 ����
��ͳ�Ƹ���ͼ(probability graph models)��,�ο��ڳ�����ʦ����,����������ϵ�ṹ:
�ڸ���ͼģ����,����(����)��ͼ
G
=
(
V
,
E
)
G=(V,E)
G=(V,E)��ģ��ʾ:
- V:�ڵ�v�ļ��ϡ�v��V��ʾ������� Y v Y_v Yv?��
- E:��e�ļ��ϡ�e��E��ʾ�������֮��ĸ���������ϵ��
- P(Y):��ͼ��ʾ�����ϸ��ʷֲ�
����ͼ������ͼ���������������ʷֲ�P(Y)��
1.2 ����ͼ
����ͼģ��,��ô�����ϸ���:
P
(
x
1
.
.
.
x
n
)
=
��
i
=
0
P
(
x
i
�O
��
(
x
i
)
)
P(x_{1}...x_{n})=\prod_{i=0}P(x_{i}|\pi (x_{i}))
P(x1?...xn?)=i=0��?P(xi?�O��(xi?))
������ͼ�������:
P
(
x
1
.
.
.
x
n
)
=
P
(
x
1
)
?
P
(
x
2
�O
x
1
)
?
P
(
x
3
�O
x
2
)
?
P
(
x
4
)
�O
P
(
x
2
)
P
(
x
5
�O
x
3
,
x
4
)
P(x_{1}...x_{n})=P(x_{1})\cdot P(x_{2}| x_{1})\cdot P(x_{3}| x_{2})\cdot P(x_{4})|P(x_{2})P(x_{5}|x_{3},x_{4})
P(x1?...xn?)=P(x1?)?P(x2?�Ox1?)?P(x3?�Ox2?)?P(x4?)�OP(x2?)P(x5?�Ox3?,x4?)
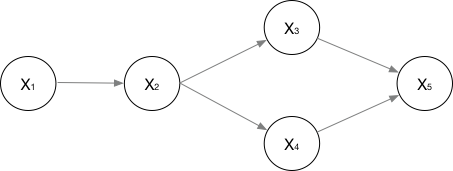
1.3 ����ͼ
��������:
- ��:�ڵ��Ӽ�,�Ӽ����κ������ڵ���б�����
- �����:�����ټ���ڵ�ʹ��������
- ���ӷֽ�:���ϸ��ʷֲ�P(Y)��ʾΪ
�����������������������ij˻�����ʽΪ���ӷֽ⡣
������:���ϸ��ʷֲ�Ϊ������ƺ����ij˻���
P
(
Y
)
=
1
Z
��
C
��
C
(
Y
C
)
=
1
Z
��
C
e
x
p
?
E
(
Y
C
)
P(Y)=\frac{1}{Z}\prod_{C}\psi _{C}(Y_{C})=\frac{1}{Z}\prod_{C}exp^{-E(Y_{C})}
P(Y)=Z1?C��?��C?(YC?)=Z1?C��?exp?E(YC?)
- C:����ͼ�������
- Y C Y_{C} YC?:�����C�ϵĽڵ�(�������)
- Z:�淶�����ӡ� Z = �� Y �� C �� C ( Y C ) Z=\sum_{Y}\prod_{C}\psi _{C}(Y_{C}) Z=��Y?��C?��C?(YC?),ʹ�����P(Y)���и������塣
- �� C ( Y C ) \psi _{C}(Y_{C}) ��C?(YC?):�ϸ������ƺ���,ͨ��Ϊָ������ �� C ( Y C ) = e x p ? E ( Y C ) \psi _{C}(Y_{C})=exp^{-E(Y_{C})} ��C?(YC?)=exp?E(YC?)��
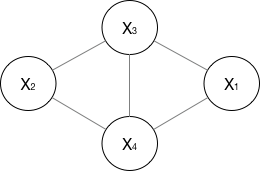
�����Ʒ���,��֤����ͼΪ��������ͼ:
- �ɶ������Ʒ���:u��vû�б�����,OΪ�������нڵ�, Y u �� Y v Y_u��Y_v Yu?��Yv?���������
- �ֲ������Ʒ���:��������ڵ�v�������ڵ㼯��W���ޱ���������O,���� Y W Y_W YW?�����, Y v �� Y O Y_v��Y_O Yv?��YO?�������:
- ȫ�������Ʒ���:�ڵ�A��B���ڵ㼯��C�ָ�, Y A �� Y B Y_A��Y_B YA?��YB?�������:
��֮����û�б������Ľڵ���ʻ��������
����һ������ͼ,��������:
P
(
Y
)
=
1
Z
��
C
��
(
X
1
,
X
3
,
X
4
)
��
(
X
2
,
X
3
,
X
4
)
P(Y)=\frac{1}{Z}\prod_{C}\psi( _{X_{1},X_{3},X_{4}})\psi( _{X_{2},X_{3},X_{4}})
P(Y)=Z1?C��?��(X1?,X3?,X4??)��(X2?,X3?,X4??)
1.4 ����ʽģ�ͺ��б�ʽģ��
1.4.1����ʽģ�ͺ��б�ʽģ������
�мලѧϰ��,ѵ�����ݰ�������X�ͱ�ǩY������ģ�������X��Y�ĸ��ʷֲ������ݸ����۵�֪ʶ����֪��,��Ӧ�ĸ��ʷֲ�(�Ը����ܶȺ���ָ�����ʷֲ�)������:
- ���ϸ��ʷֲ�: P �� ( X , Y ) P_{\theta }(X,Y) P��?(X,Y),��ʾ���ݺͱ�ǩͬʱ���ֵĸ���,��Ӧ������ʽģ�͡�
- �������ʷֲ�:P_{\theta }(Y|X),��ʾ��������������,��Ӧ��ǩ�ĸ���,��Ӧ���б�ʽģ�͡�
��һ������:
- ����ʽģ��:�����ܹ������������� X ��Ԥ���Ӧ�ı�ǩ Y ,���ܸ���ѵ���õ���ģ�Ͳ�������ѵ�����ݼ��ֲ�������( X ,Y),�൱������һ���µ�����,���Գ�֮Ϊ����ʽģ�͡�
- �б�ʽģ��:��������X���������� P �� ( Y �O X ) P_{\theta }(Y|X) P��?(Y�OX)��Ԥ���ǩY���������������ݵ�����,���DZ�����ʽģ�͵�Ԥ��ȷ�ʸߡ�
1.4.2 Ϊɶ�б�ʽģ��Ԥ��Ч������
ԭ������:��ȫ���ʹ�ʽ����Ϣ�ع�ʽ���Եõ�:
P
(
X
,
Y
)
=
��
P
(
Y
�O
X
)
P
(
X
)
d
X
P(X,Y)=\int P(Y|X)P(X)dX
P(X,Y)=��P(Y�OX)P(X)dX
������ȫ���ʹ�ʽ
P
(
X
,
Y
)
P(X,Y)
P(X,Y)ʱ�������������ݵĸ��ʷֲ�
P
(
X
)
P(X)
P(X),��������������ǹ��ĵġ�����ֻ���ĸ���X�����Y�ķֲ�,������������ģ�͵�Ԥ��������
�������Ϣ�صĽǶȽ��ж���������
- X����Ϣ�ض���Ϊ:
H ( X ) = ? �� P ( X ) l o g P ( X ) d X H(X)=-\int P(X)logP(X)dX H(X)=?��P(X)logP(X)dX - ������ɢ������� X �� Y �������� (Joint Entropy) ��ʾ���¼�ͬʱ����ϵͳ�IJ�ȷ����:
H ( X , Y ) = ? �� P ( X , Y ) l o g P ( X , Y ) d X d Y H(X,Y)=-\int P(X,Y)logP(X,Y)dXdY H(X,Y)=?��P(X,Y)logP(X,Y)dXdY - ������ (Conditional Entropy) H(Y|X)��ʾ����֪�������X���������������Y�IJ�ȷ����:
H ( Y �O X ) = ? �� P ( Y �O X ) l o g P ( Y �O X ) d X H(Y|X)=-\int P(Y|X)logP(Y|X)dX H(Y�OX)=?��P(Y�OX)logP(Y�OX)dX
�����Ƶ����� H ( Y �O X ) = H ( X , Y ) ? H ( X ) H(Y|X)=H(X,Y)-H(X) H(Y�OX)=H(X,Y)?H(X).һ��H(X)>0(������ɢ�ֲ��ͺܶ������ֲ������������),����֪�������ֲ�����Ϣ��С�����Ϸֲ�,���б�ģ�ͱ�����ʽģ�ͺ��и������Ϣ,����ͬ�����±�����ʽģ��Ч�����á�
������ʽ�����Ʒ�ģ��HMM
2.1 HMM����
- �������ɷ�ģ���ǹ���ʱ��ĸ���ģ��
- ������һ��
���ص������ɷ�������������ɹ۲��״̬�������(state sequence),���ɸ���״̬����һ���۲�������۲��������(observation sequence )�Ĺ���,���е�ÿһ��λ���ֿ��Կ�����һ��ʱ�̡�
��Q�����п���״̬�ļ���,V�����п��ܹ۲�ļ���:
Q
=
(
q
1
,
q
2
,
.
.
.
q
N
)
��
V
=
(
v
1
,
v
2
,
.
.
.
v
M
)
Q=(q_{1},q_{2},...q_{N})��V=(v_{1},v_{2},...v_{M})
Q=(q1?,q2?,...qN?)��V=(v1?,v2?,...vM?)
���ڳ���ΪT��״̬����I�۲�����O��:
i
=
(
i
1
,
i
2
,
.
.
.
i
T
)
��
O
=
(
o
1
,
o
2
,
.
.
.
o
T
)
i=(i_{1},i_{2},...i_{T})��O=(o_{1},o_{2},...o_{T})
i=(i1?,i2?,...iT?)��O=(o1?,o2?,...oT?)
����:
- ״̬ת�Ƹ��ʾ��� A = ( a i j ) N �� N i , j ? ( 1 , N ) A=(a_{ij})_{N\times N}\qquad i,j\epsilon (1,N) A=(aij?)N��N?i,j?(1,N)�� a i j a_{ij} aij?��ʾtʱ��״̬ q i q_i qi?ת�Ƶ�t+1ʱ�� q j q_j qj?�ĸ���
- �۲����(�������)���� B = [ b j ( k ) ] N �� M j ? ( 1 , N ) k ? ( 1 , M ) B=[b_{j}(k)]_{N\times M} \quad j\epsilon (1,N)k\epsilon (1,M) B=[bj?(k)]N��M?j?(1,N)k?(1,M)�� b j ( k ) b_{j}(k) bj?(k)��ʾtʱ��״̬ q i q_i qi?���ɹ۲� v k v_k vk?�ĸ��ʡ�
- ��ʼ״̬��������
��
=
(
��
i
)
=
P
(
i
1
=
q
i
)
i
?
(
1
,
N
)
\pi =(\pi _{i})=P(i_{1}=q_{i})\quad i\epsilon (1,N)
��=(��i?)=P(i1?=qi?)i?(1,N)����ʾ��ʼʱ�̴���״̬
q
i
q_i
qi?�ĸ��ʡ�

- ��״̬�ڵ� i t i_t it?��A��ָ����������һ����״̬�ڵ� i t + 1 i_{t+1} it+1?,���� i t i_t it?��B��ָ�������ɹ۲�ڵ� o t o_t ot? , ������ֻ�ܹ۲����O��
- ���ݸ���ͼ����,���Կ���HMM��������ͼ,����������ʽģ��,ֱ�Ӷ����ϸ��ʷֲ���ģ:
ֻ�����Ƕ�ȥ��ô����ʾHMM�Ǹ�����ʽģ��,ʵ�ʲ���ô���㡣
2.2 HMM��Ҫ�غ�������������
- HMM��
��ʼ״̬���������С�״̬ת�Ƹ��ʾ���A�� �۲���ʾ���B��Ԫ�ع��ɡ�
����HMMģ�� �� \lambda ������д��: �� = ( A , B , �� ) \lambda =(A,B,\pi) ��=(A,B,��)�����߹�ͬ���������ص������ɷ������ɲ��ɹ۲��״̬��������״̬���к;���B�ۺϲ����۲����С� - HMMģ�ͻ�������
- ��������Ʒ��Լ���:�������ɷ�������ʱ��t��״ֻ̬����ǰһʱ��t-1��״̬,�� P ( i t �O i i ? 1 ) P(i_{t}|i_{i-1}) P(it?�Oii?1?)��
- �۲�����Լ���:����ʱ�̵Ĺ۲�ֻ������ǰʱ�̵�״̬,�� P ( o t �O i i ) P(o_{t}|i_{i}) P(ot?�Oii?)��
2.3 HMM������������
- ���ʼ���:����ģ�� �� = ( A , B , �� ) \lambda =(A,B,\pi) ��=(A,B,��)�۲�����O,����۲�����O���ֵĸ��� P ( O �O �� ) P(O|\lambda) P(O�O��)��
- ѧϰ����:��֪�۲�����O,�������Ȼ���Ƶķ�������ģ�� �� = ( A , B , �� ) \lambda =(A,B,\pi) ��=(A,B,��)�IJ�����(��ģ���¹۲�����O�ĸ������)
- Ԥ��(����)����:��֪ģ�� �� = ( A , B , �� ) \lambda =(A,B,\pi) ��=(A,B,��)�۲�����,�����п��ܵĶ�Ӧ״̬���С�
- HMM�����������б��,�۲�����OΪtokens,״̬����IΪ���Ӧ�ı�ǡ���ʱ�����Ǹ�������OԤ���Ӧ����I��
- ����2��Ӧģ�ͽ�������,����3 ��Ӧ�������(crf.decode)
2.4 HMM�����ⷨ
2.4.1 ������Ȼ����(����I��O���)
һ����NLP�����б�ע������,��ѵ���ο϶�������״̬���е�,�����ݹ۲�����O��״̬����I��ģ�� �� = ( A , B , �� ) \lambda =(A,B,\pi) ��=(A,B,��)�IJ���,��һ���мලѧϰ��
- ����״̬������״̬ת�ƾ���A:
a i j = A i j �� j = 1 N A i j \mathbf{a_{ij}=\frac{A_{ij}}{\sum_{j=1}^{N}A_{ij}}} aij?=��j=1N?Aij?Aij?? - ����״̬����I�۲�����O��۲���ʾ���B:
b j ( k ) = B j k �� k = 1 M B j k \mathbf{b_{j}(k)=\frac{B_{jk}}{\sum_{k=1}^{M}B_{jk}}} bj?(k)=��k=1M?Bjk?Bjk?? - ֱ�ӹ��Ʀ�
2.4.2 ǰ������㷨(û��I)
ֻ�й۲�����O,û��״̬����I,�ල���̡��������һ����EM�Ĺ��̡�

2.4.3 ���б�ע(����)����
- ѧϰ����HMM�ķֲ�����,Ҳ��ȷ����һ��HMMģ�͡����б�ע����Ҳ���ǡ�Ԥ����̡�(�������)����Ӧ�����н�ģ����3��
- ѧϰ����֪�� ���ϸ���P(I,O),����Ҫ�����������P(I|O):
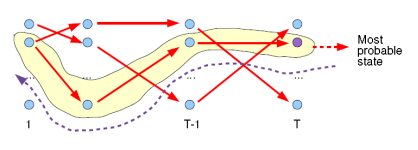
I m a x = a r g m a x a l l I P ( I , O ) P ( O ) I_{max}=\underset{all I}{argmax}\frac{P(I,O)}{P(O)} Imax?=allIargmax?P(O)P(I,O)? - ��Viterbi�㷨����,�ڸ����Ĺ۲��������ҳ�һ������������״̬���С�
- Viterbi����������ͼ��һ�����·��,��DP˼������ظ��ļ��㡣��ͼ:
��������������Ʒ�MEMMģ��
3.1 MEMMԭ��������
MEMM���б�ʽģ��,ֱ�Ӷ��������ʽ�ģ:
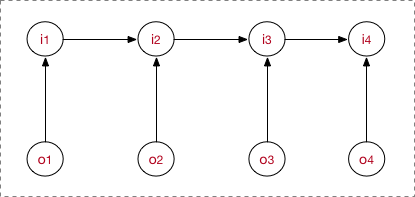
MEMM��Ҫע��:
-
HMM�� o t o_t ot?ֻ������ǰʱ�̵�����״̬ i t i_t it?,HEMM�ǵ�ǰʱ����״̬ i t i_t it?�����۲�ڵ� o t o_t ot?����һʱ��״̬ i t ? 1 i_{t-1} it?1?��
-
�б�ʽģ�����ú���ֱ���б�,ѧϰ�߽�,MEMM��ͨ�������������綨��HMM������ʽģ��,������Ϊ���ָ��ʷֲ�Ԫ����,�������㹻�����������Ȼ���ơ���ͬ��,MEMMҲ�м�����Ȼ���Ʒ������ݶ��½���ţ�ٵ���������ţ���½���BFGS��L-BFGS�ȵ� -
��Ҫע��,֮����ͼ�ļ�ͷ��ô��,����MEMM�Ĺ�ʽ������,����ʽ��creator��������ġ�
-
���б�ע����ʱ,һ����ά�ر��㷨�����������״̬���С�
- HMM��,�۲�ڵ� o t o_t ot?ֻ������ǰʱ�̵�����״̬ i t i_t it?��
- �����ʵ�ʳ�����,�۲���������Ҫ�ܶ���������̻��ġ�����˵,������NERʱ,�ҵı�ע i t i_t it?��������ǰ״̬ o t o_t ot?���,���һ���ǰ���ע i j ( j �� i ) i_{j}(j��i) ij?(j��?=i)���,������ĸ��Сд�����Եȵȡ�
- MEMMģ��:����������������,ֱ��ѧϰ��������,��:

- Z ( o , i �� ) Z(o,i{}') Z(o,i��):��һ��ϵ��
- f ( o , i ) f(o,i) f(o,i):��������,��Ҫ�Զ���,������������ƶ�
- ��:��������ϵ��,��Ҫѵ���õ�
3.2 ��עƫ��
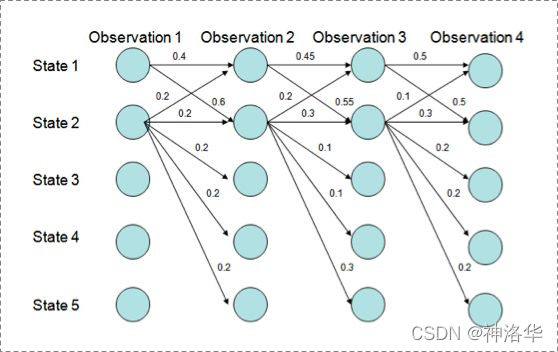
��Viterbi�㷨����MEMM,״̬1������ת����״̬2,ͬʱ״̬2�����ڱ�����״̬2�� ����ϸ��:
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 ,
P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018,
P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06,
P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066
���ǵõ������ŵ�״̬ת��·����1->1->1->1,
Ϊʲô��?��Ϊ״̬2����ת����״̬��״̬1Ҫ��,�Ӷ�ʹת�Ƹ��ʽ���,��MEMM������ѡ��ӵ�и���ת�Ƶ�״̬��ԭ������:

�ġ����������CRF
4.1 CRF����
-
���������:�����������X������,����������Y����������ģ��,����Y��������ͼG=(V,E)��ʾ�������Ʒ��������
������ڵ�v,�������������:
P ( Y v �O X , Y w , w �� v ) = P ( Y v �O X , Y w , w �� v ) P(Y_{v}|X,Y_{w},w\neq v)=P(Y_{v}|X,Y_{w},w\sim v) P(Yv?�OX,Yw?,w��?=v)=P(Yv?�OX,Yw?,w��v)
w�� v��ʾv֮������н��,w~v��ʾ��v�б����������н�㡣�� P ( Y v P(Y_{v} P(Yv?֮����v�б����ӵĽ���йء� -
���������������,������������������ļ��������������Ʒ���(��״ֻ̬��ǰ��ʱ��״̬�й�):
P ( Y i �O X , Y 1 , Y 2 . . . Y n ) = P ( Y i �O X , Y i + 1 , Y i ? 1 ) P(Y_{i}|X,Y_{1},Y_{2}...Y_{n})=P(Y_{i}|X,Y_{i+1},Y_{i-1}) P(Yi?�OX,Y1?,Y2?...Yn?)=P(Yi?�OX,Yi+1?,Yi?1?) -
������CRF���б�ģ��,ѧϰ����������ѵ�����ݵ�(����)������Ȼ���Ƶõ���������ģ��P(Y|X)�����������б�ע���⡣��ʱ��������P(Y|X)��:
- YΪ�������,���������(״̬����)
- XΪ�������,����Ҫ��ע��״̬���С�
-
Ԥ��ʱ,���ڸ�����������x,����������������������y��
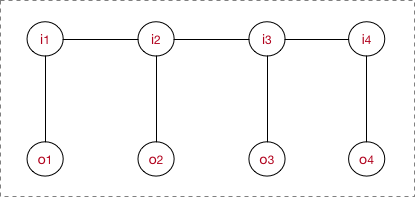
4.2 ������CRF�ļ���
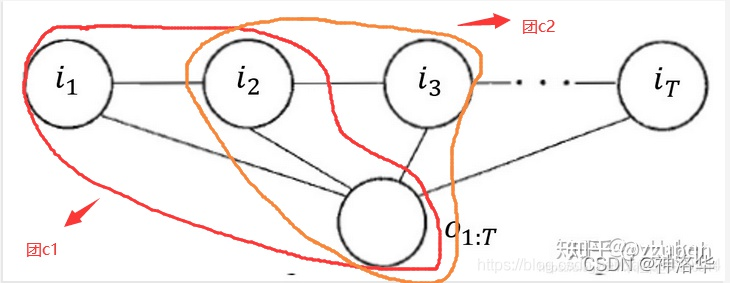
��������ͼ�����ϸ��ʷֲ����������ӷֽ��±�ʾΪ:
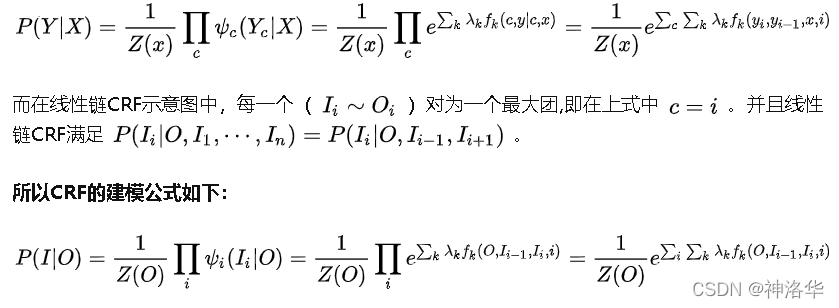
- �±�i��ʾ�ҵ�ǰ���ڵĽڵ�(token)λ�á�
- �±�k��ʾ�����ǵڼ�����������,����ÿ����������������һ��Ȩ�� �� k \lambda_{k} ��k? ����ÿ��������,�ҽ�Ϊ t o k e n i token_i tokeni?����M������,ÿ������ִ��һ����������,Ȼ��ģʱ����Ϊÿ������������Ȩ��͡�
- Z(O)��������һ����,�γɸ���ֵ��
- P ( I �O O ) P(I|O) P(I�OO)��ʾ���ڸ�����һ���۲����� O��������,����CRF�����������״̬���� I = ( i 1 , i 2 , . . . i T ) I=(i_{1},i_{2},...i_{T}) I=(i1?,i2?,...iT?)�ĸ��ʡ������ڹ۲����� O,��������һ����ѵ�����ϵ����еĹ۲�����;Ҳ���������ƶϽε�һ��sample���������б�ע����Ԥ��,����ѡ���������ʵ�����(by viterbi)��
- ����CRF,����Ϊ������������������:ת������&״̬������ ���ǽ���ģ�ܹ�ʽչ��:

ת��������Ե���ǰ��token֮�������
Ϊ�˼����,��ת��������״̬��������Ȩֵ��ͳһ���ű�ʾ�������������ʽ����:
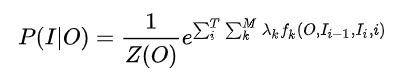
�ٽ�һ������Ļ�,������Ҫ�������������ֿٳ���:
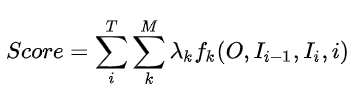
����Ϊ
t
o
k
e
n
i
token_i
tokeni?���,���������ľ��������ס�������õķ�������log���Ա�ʾ,��ͺ��һ��,���ɵõ�����ֵ��
����Ӧ�����ο�������ü��������ӽ������������(CRF)ģ��?����HMM��ʲô����?����
4.3 �ӹ�ʽ�����������
ʵ�ʼ���ʱ,���ø��ʵĶ�����ʽ,��logP(Y)��ʹ�������Ȼ����������ֲ��IJ���,�����ǵ�Ŀ��������ogP(Y)��
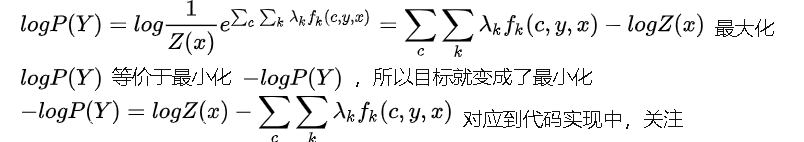
��
?
l
o
g
P
(
Y
)
=
l
o
g
Z
(
x
)
?
s
c
o
r
e
-logP(Y)=logZ(x)-score
?logP(Y)=logZ(x)?score��
��Ӧ��������,forward_score ����
l
o
g
Z
(
x
)
logZ(x)
logZ(x),gold_score���������������ֵ�score��
def neg_log_likelihood(self, sentence, tags):
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
- ��Ϊģ�ͽ����ij��Ծ���Ҫ���ǵ� i k ? 1 i_{k-1} ik?1?�� i k i_{k} ik?��Ӱ���X�Թ۲����е�Ӱ��.�������ǽ�ͼ�ֽ�����ɸ� ( i k ? 1 , i k , X ) (i_{k-1},i_{k},X) (ik?1?,ik?,X)��
- ����
i
k
i_{k}
ik?��ʾ�۲������״ֵ̬,������BIO��ע��״̬ȡֵ��Χ��{B,I,O,START,STOP},��k���ȡ5,
i
k
i_{k}
ik?��5��״ֵ̬��ȡ��
ֻ��ע���е�ijһ���� C i C_i Ci?,�����������ֵ�gold_score��ʾ��������X��,���ֳ��� ( i k ? 1 , i k ) (i_{k-1},i_{k}) (ik?1?,ik?)�ķѹ�һ������,�����������й�:
- ��������X�³��� i k i_{k} ik?�ĸ���,�� h ( i k , X ) h(i_{k},X) h(ik?,X)��ʾ���������ʹ��lstm��cnn��ģX�� i k ) i_{k}) ik?)ӳ��Ϳ��Եõ�,��Ӧ����ϵ�״̬������
- ��������X���� i k ? 1 i_{k-1} ik?1?ת�Ƶ� i k i_{k} ik?�ĸ���,�� g ( i k ? 1 , i k ; X ) g(i_{k-1},i_{k};X) g(ik?1?,ik?;X)��ʾ,��Ӧ���ϵ�ת����������CRF��,�۲����ֻ���ٽ��ڵ��Ӱ�졣
- ���ǵ����ѧϰģ���Ѿ��ܱȽϳ�ֲ����� i k i_{k} ik?��X ����ϵ,���Լ��� i k ? 1 i_{k-1} ik?1? ת�Ƶ� i k i_{k} ik?�ĸ�����X��,������: g ( i k ? 1 , i k ; X ) = g ( i k ? 1 , i k ) g(i_{k-1},i_{k};X)=g(i_{k-1},i_{k}) g(ik?1?,ik?;X)=g(ik?1?,ik?)
�������ϼ���,���Եõ�:
g
o
l
d
?
s
c
o
r
e
=
��
c
��
k
��
k
f
k
(
c
,
y
,
x
)
=
��
c
��
k
(
g
(
i
k
?
1
,
i
k
)
+
h
(
i
k
,
X
)
)
gold-score=\sum_{c}\sum_{k}\lambda _{k}f_{k}(c,y,x)=\sum_{c}\sum_{k}(g(i_{k-1},i_{k})+h(i_{k},X))
gold?score=c��?k��?��k?fk?(c,y,x)=c��?k��?(g(ik?1?,ik?)+h(ik?,X))
ʣ�¼�����̲ο�:�����������CRF֮�ӹ�ʽ�����롷
�塢 HMM vs. MEMM vs. CRF
5.1 HMM vs MEMM
HMMģ���д�����������:һ������۲�ֵ֮���ϸ����,����״̬��ת�ƹ�������ǰ״ֻ̬��ǰһ״̬�й�����ʵ�������б�ע���ⲻ���͵��������,���Һ۲����еij���,���ʵ�������,�ȵ���ء�MEMM�����HMM��������Լ������������ΪHMMֻ�����˹۲���״̬֮�������,��MEMM�����Զ�����������,�������Ա���۲�֮�������,���ɱ�ʾ��ǰ�۲���ǰ����״̬֮��ĸ���������
5.2 MEMM vs CRF
CRF���������HMM��������Լ��������,�������MEMM�ı�עƫ������,MEMM��������ֲ���������Ϊֻ�ھֲ�����һ��,��CRFͳ����ȫ�ָ���,������һ��ʱ������������ȫ�ֵķֲ�,�����ǽ����ھֲ���һ��,�����ͽ����MEMM�еı��ƫ�õ����⡣ʹ�����б�ע�Ľ��������Ž⡣HMM��MEMM��������ͼ,���Կ�����x��y��Ӱ��,��û��x�������忼�ǽ�ȥ(�������Ӧ��ֻ��HMM)��CRF��������ͼ,û������������,�˷������⡣