?NLP论文解读?原创?作者?| 吴雪梦Shinemon
研究方向?| 计算机视觉
导读说明:
NLP任务大致可以分为NLU(自然语言理解)和NLG(自然语言生成)两种,NLU负责根据上下文去理解当前用户的意图,方便选出下一步候选的行为,确定好行动之后,NLG模块会生成出对齐行动的回复;由于BERT引入Pre-train模块,在NLU任务上有很好的效果,但不适合处理生成任务,因为BERT的预训练过程主要使用的是MLM,和生成任务的目标并不一致。
因此对Bert进行改进,让它更好的兼备NLG能力。此论文是典型的一个BERT改进模型BoB,介绍了如何利用多个BERT模型分离对话生成和对话理解,以更少的角色化对话数据训练,得到比使用全量数据训练的强基线方法更好的效果。
论文解读:
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data
论文作者:
宋皓宇,王琰,张开颜,张伟男,刘挺
论文地址:
https://aclanthology.org/2021.acl-long.14.pdf
代码地址:
https://github.com/songhaoyu/BoB
模型亮点:
全新的基于BERT的模型,包含了一个BERT编码器和两个BERT解码器,其中一个解码器用于对话回复生成,另一个则用于角色一致性的理解,将理解能力和生成能力的获取分离开来。

研究背景简述
开放域对话系统需要在对话过程中尽可能地保持一致的人物角色特征,但是在应用上受限于人物角色对话数据的有限规模。在现阶段下,无论是开放域对话生成模型还是开放域对话系统,面临的最大挑战之一就是对话回复的前后不一致。针对这一问题,相关的研究工作开始在对话中明确地引入角色信息[1]。图1展示了基于角色的对话的基本形式。角色信息的引入极大地简化了对话过程一致性的建模,也使得评价过程更容易。
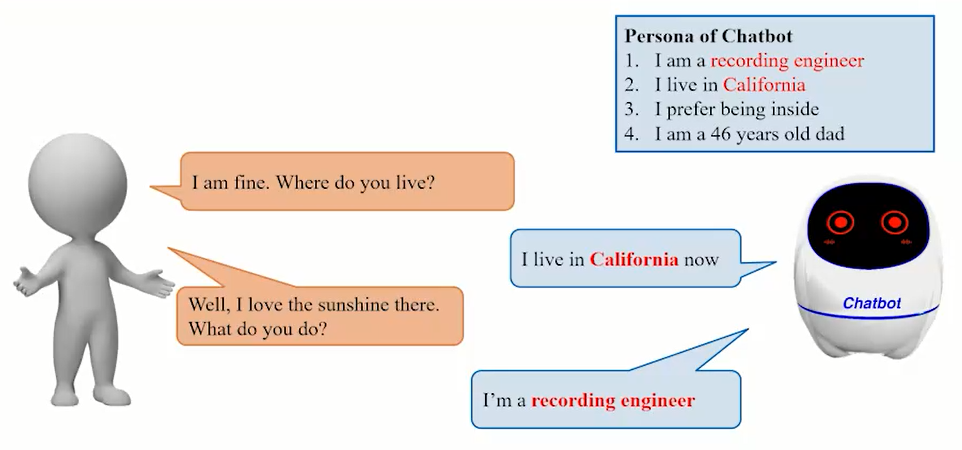
图1.?基于角色的对话的基本形式
Fig1. The basic form of persona-based dialogues
例如图2给定一组角色文本和输入消息,构建一个由角色信息响应的对话模型,且角色信息应该准确地结合到蓝色框中的两个响应中。但是,仅考虑角色的第二个响应与基于角色的对话任务中的给定信息一致。
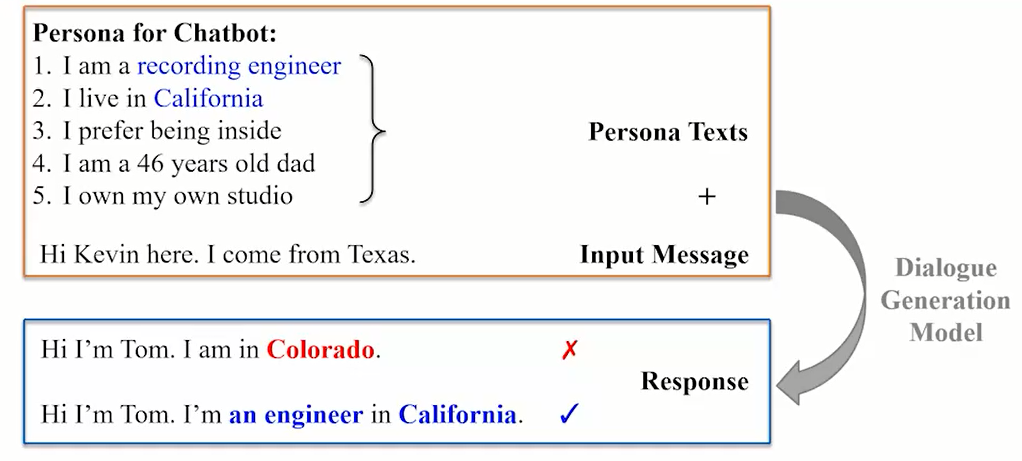
图2.?任务定义图
Fig2.?Figure?of?task definition
然而,这些工作都依赖于带有角色信息的对话数据。论文作者提到这类数据有两种获取形式:人工标注和社交媒体(详细说明见论文原文)。这两种构建角色化对话数据资源的方式带来了共同的资源稀缺问题:角色信息丰富则数据量少;而数据量充足则角色信息稀疏。
为了缓解上述问题,使模型具备理解对话回复和角色信息的一致性关系能力,以及生成带有角色信息的回复能力,论文作者设计了一个全新的基于BERT的模型,如图3所示,对于一致性理解和对话生成,所需要的相关数据集。
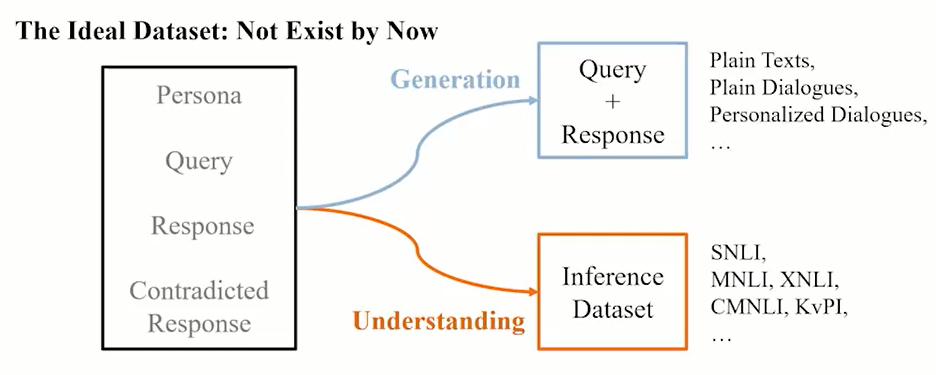
图3.?理想数据集示图
Fig3. Diagram of?the ideal dataset

BoB模型
所提出的模型由编码器E、用于响应对话回复的自回归解码器D1和用于一致性理解的双向解码器D2组成。给定角色P和对话输入Q, E和D1以编码器-解码器的方式共同工作,捕获一个典型的输入到映射FG?(S|Q, P)?的响应,并生成一个粗略的响应表示R1。然后将R1和角色P输入双向解码器D2,将R1映射到最终的响应表示R2?:?FU?(R2|S, P)。由于一致性理解部分R2?:?FU?(R2|S, P)独立于对话输入Q,因此可以在非对话推理数据集上学习。这里在D2引入了Unlikelihood目标函数[2],使用了一个不可能训练目标来降低推理数据中矛盾案例的可能性,从而使D2获得一致性理解能力。BoB模型的整体结构及相应的训练方式如下图4所示,详细推理过程见原论文:
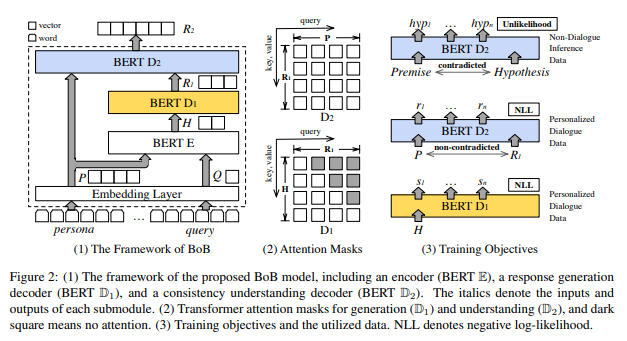
图4.?BoB 模型及注释
Fig4.?BoB model and Annotation

编码器E
它的工作方式类似于一个标准BERT模型,它双向地将嵌入的输入编码为一个隐藏向量序列,下游的任务将在这个序列上执行。在模型中,输入文本包括角色信息P和对话输入Q。为了让模型能够区分角色信息和对话输入,放置一个特殊标记,输入格式如下:
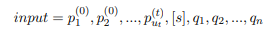
然后嵌入层将输入信息转换为词向量。编码器E将执行多头注意力机制。这里E的工作方式和原始的BERT完全一致。

自回归解码器D1
由BERT初始化,继承了强大的语言特征提取能力,但以自回归解码器方式工作。首先,在E和D1之间插入交叉注意传递上下文信息。其次,为保持自回归生成特性,对D1执行词语自左向右预测掩码,如图4所示的上三角的掩码矩阵,以确保生成的回复词只能依赖已有的信息。由于BERT模型中不存在交叉注意力机制,因此在训练过程中对交叉注意力机制进行随机初始化和更新。交叉注意力机制的query来自D1的前一层信息,key和value来自H:
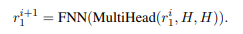
E和D1都有N个相同的层。D1最后一层的输出r1N会进一步送到D2中进行一致性理解处理。

双向解码器D2
与E和D1一样,D2也是从BERT进行初始化的,并由此继承了文本理解任务的良好语义表示。为了减少推理数据中矛盾数据出现的可能性,使D2能够获得一致性理解的能力,D2引入了Unlikelihood目标函数进行训练。在进行一致性理解训练时,D2的输入是数据集N={Premise, Hypothesis, Label},而生成目标同样数据中的Hypothesis。原因在于模拟对话数据的生成方式,从而让模型能够利用非对话的推理数据进行一致性理解训练。在D2的每一层,多头注意力机制执行两次:

每一层的结果 r2i?融合了P和 R1?的信息。D2最后一层的输出是最终表示R2。在R2上通过输出层,例如线性层,我们可以得到生成的响应R?。

实验数据及结果
该实验在角色信息稠密的PersonaChat数据集(英文,人工标注,12万数据量)和角色信息稀疏的PersonalDialog数据集(中文,社交媒体,1200万数据量)上通过大量的实验来验证了BoB模型的有效性。详细模型训练过程见原论文。
如图5中的PersonaChat数据集全量数据实验结果,在所有自动和人工评估指标中都取得了更好的性能,这表明了该模型的有效性。在所有指标中,模型获得了最低PPL(衡量模型拟合数据的能力)和最高?P(不同模型在一致p.Ent和矛盾p.Ctd对话数据上困惑度差值)。最低的测试集PPL意味着我们的模型已经学习了一个适合该数据集的良好的语言模型;最高的?P表明,与其他基线相比,我们的模型能够更有效地区分隐含和矛盾,这表明我们的模型对角色一致性有更好的理解。
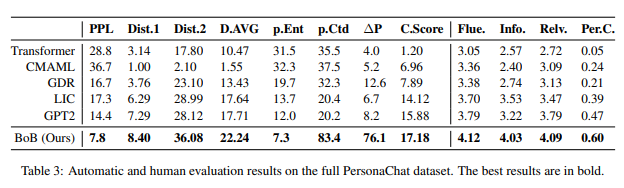
图5.?全量PersonaChat数据集人工评估指标结果
Fig5. Full PersonaChat?dataset?results
此外,如图6所示BoB模型在低资源的条件下仍然表现优秀,只需要八分之一的训练数据模型表现即可超过基线模型。
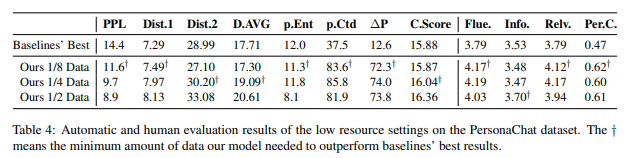
图6.?低资源PersonaChat数据集人工评估指标结果
Fig6.?Low resource?PersonaChat dataset results
如图7中消融实验结果可以看出,在角色稀疏的数据上进行训练,BoB的编码器和两个解码器都是有效的。此外,Random测试集结果没有明显优于基线模型,但是Biased测试集所有指标有明显的优势,这是因为PersonalDialog数据集的角色信息稀疏,在挑选的时候特别筛选了部分带角色信息的数据集。
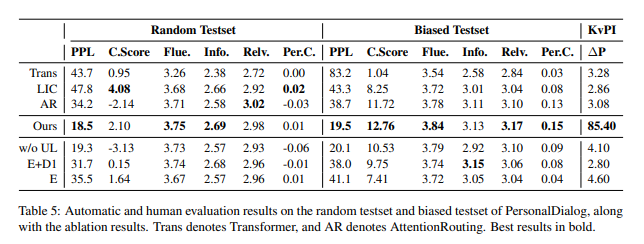
图7. 角色信息稀疏PersonalDialog数据集实验和消融实验结果
Fig7. PersonalDialog?results?and ablation results
如图8是PersonaChat数据集消融实验结果。Unlikelihood目标函数对于一致性理解影响很大。
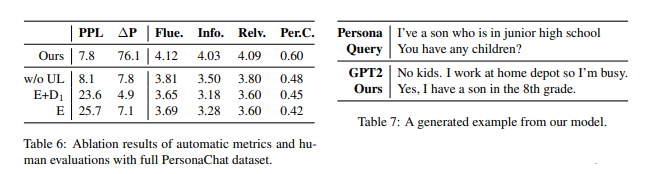
图8. PersonaChat数据集消融实验结果和例子
Fig8.?Full?PersonaChat dataset?ablation results?and a example

结论:
在这项工作中,论文作者提出了一种全新的基于BERT的角色化对话模型,通过分离生成回复和一致性理解,从有限的角色化对话数据中学习。引入非对话推理数据的非可能性训练,提高模型的理解能力。在两个公开数据集上进行的实验表明,该模型可以用有限的角色化对话数据进行训练,同时获得与用全量数据训练的强基线方法相比仍能获得显著的改进。
参考文献:
[1]You?impress me: Dialogue generation via mutual persona perception, ACL 2020
[2]Don’tSayThat!Making?Inconsistent?Dialogue?Unlikely with Unlikelihood Training, ACL?2020