窗口函数rolling()
自建数据:
import pandas as pd
df = pd.DataFrame({"a": [10, 20, 10, 60, 40, 20, 50]})
df
输出:
| a | |
|---|---|
| 0 | 10 |
| 1 | 20 |
| 2 | 10 |
| 3 | 60 |
| 4 | 40 |
| 5 | 20 |
| 6 | 50 |
下进行如下操作:
b: 逐三行求和
c: 逐三行求和并放置在中间行(两行的中间行是靠下的那个)
d: 逐三行求最大
e: 逐三行求最小
f: 逐三行求均值
df['b'] = df['a'].rolling(3).sum()
df['c'] = df['a'].rolling(3, center=True).sum()
df['d'] = df['a'].rolling(3).max()
df['e'] = df['a'].rolling(3).min()
df['f'] = df['a'].rolling(3).mean()
df
输出结果:
| a | b | c | d | e | f |
|---|---|---|---|---|---|
| 0 | 10 | NaN | NaN | NaN | NaN |
| 1 | 20 | NaN | 40.0 | NaN | NaN |
| 2 | 10 | 40.0 | 90.0 | 20.0 | 10.0 |
| 3 | 60 | 90.0 | 110.0 | 60.0 | 10.0 |
| 4 | 40 | 110.0 | 120.0 | 60.0 | 10.0 |
| 5 | 20 | 120.0 | 110.0 | 60.0 | 20.0 |
| 6 | 50 | 110.0 | NaN | 50.0 | 20.0 |
format string
避免重复书写的好帮手。
labels = ["{0} - {1}".format(i, i + 9) for i in range(0, 100, 10)]
labels
输出:
[‘0 - 9’,
‘10 - 19’,
‘20 - 29’,
‘30 - 39’,
‘40 - 49’,
‘50 - 59’,
‘60 - 69’,
‘70 - 79’,
‘80 - 89’,
‘90 - 99’]
格式二:
[f'x is {x}' for x in range(10) ]
输出:
[‘x is 0’,
‘x is 1’,
‘x is 2’,
‘x is 3’,
‘x is 4’,
‘x is 5’,
‘x is 6’,
‘x is 7’,
‘x is 8’,
‘x is 9’]
一个方框‘[]’是Series, 两个方框‘[[]]’是DataFrame
例如已有如下DataFrame,名字叫‘df’:
| a | b | c | d | e | f |
|---|---|---|---|---|---|
| 0 | 10 | NaN | NaN | NaN | NaN |
| 1 | 20 | NaN | 40.0 | NaN | NaN |
| 2 | 10 | 40.0 | 90.0 | 20.0 | 10.0 |
| 3 | 60 | 90.0 | 110.0 | 60.0 | 10.0 |
| 4 | 40 | 110.0 | 120.0 | 60.0 | 10.0 |
| 5 | 20 | 120.0 | 110.0 | 60.0 | 20.0 |
| 6 | 50 | 110.0 | NaN | 50.0 | 20.0 |
取a列:
-
一个‘[]’:
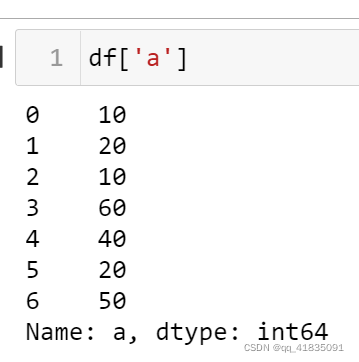
-
两个‘[[]]’:

某个结构后面想用函数可以按‘ tab’键
DadaFrame中取值一般是‘[]’,取函数一般是‘()’
存文件可以考虑pickle或者parquet
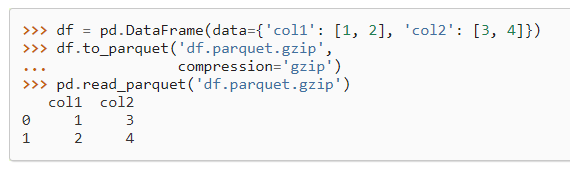
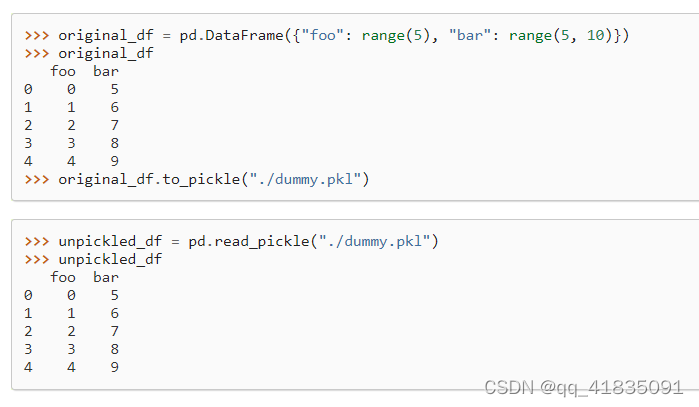
它是存成二进制文件,读写比csv快。
Catogorical 类别变量
- 无序的
不用举例了吧,猫 啊,狗的,无序。 - 有序的

分箱操作
-
cut()
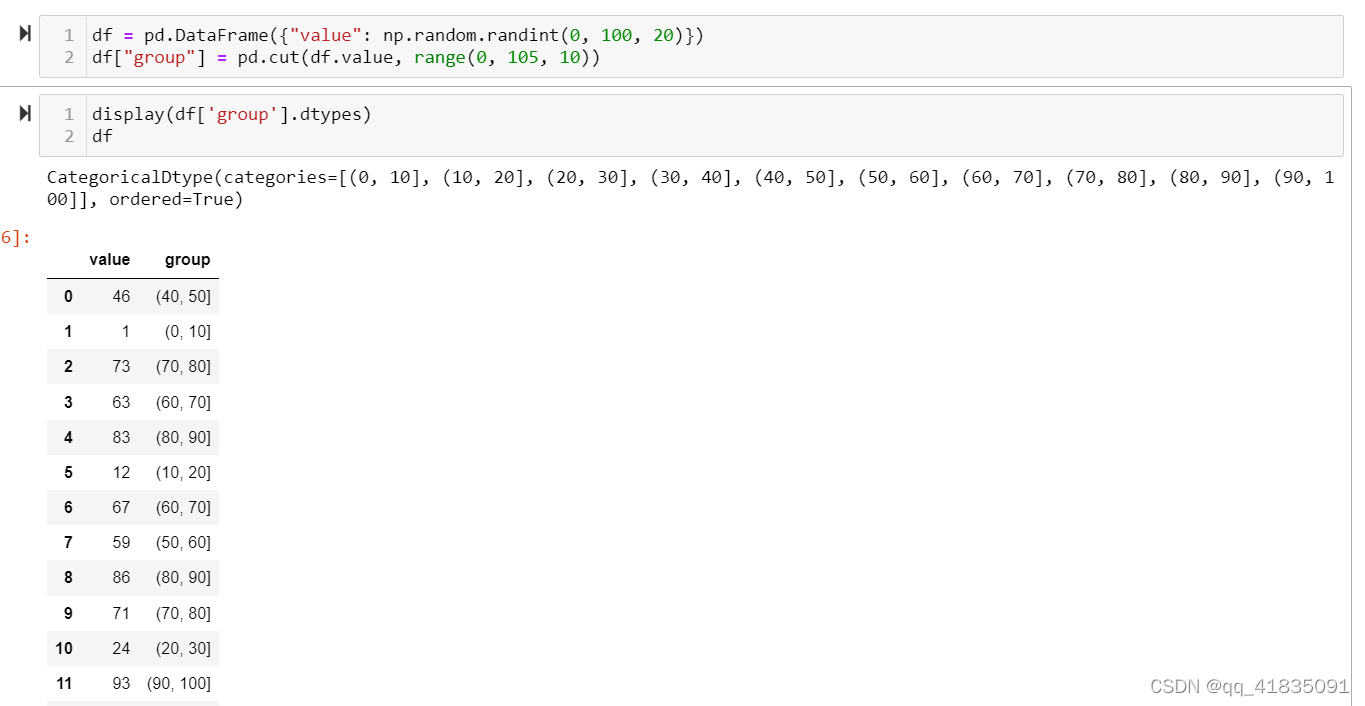
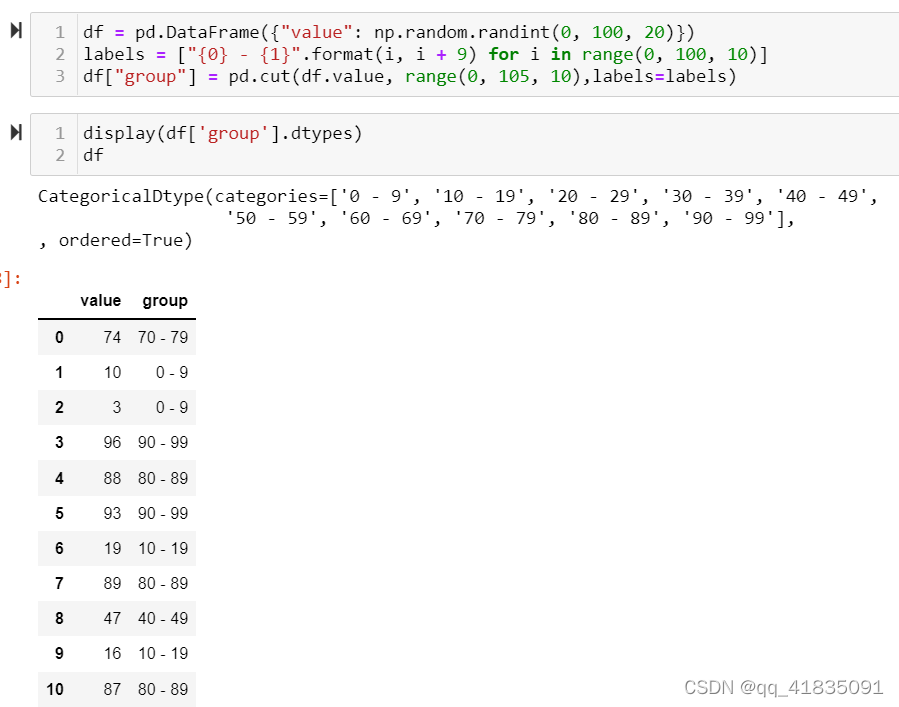
-
qcut()

DataFrame自带画图方法,无需导入seaborn或matplotlib
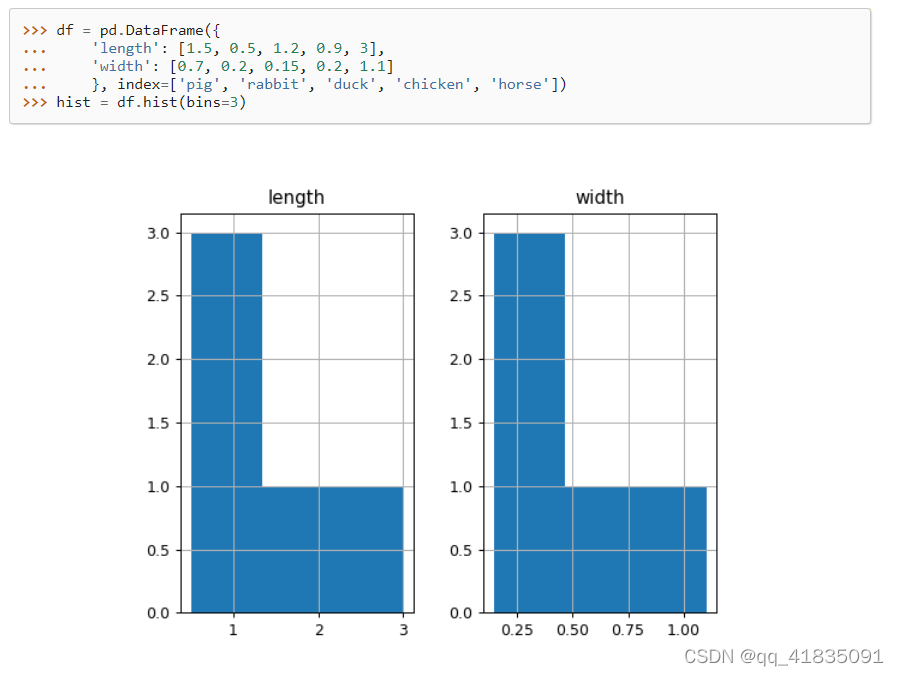
还可以是这些:
apply()
- Series的apply()
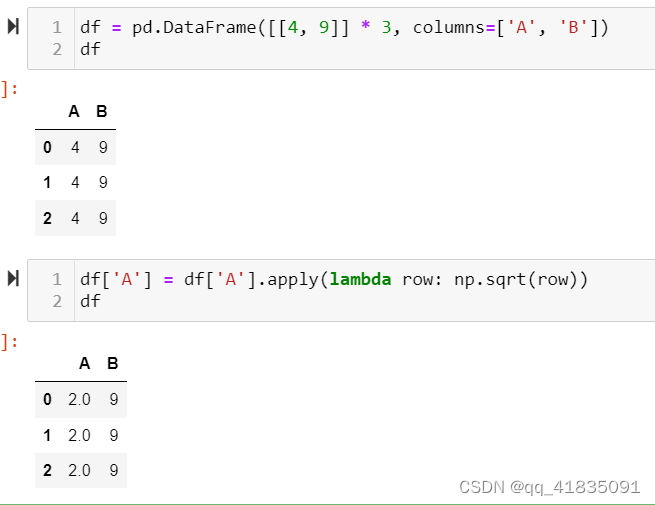
- DataFrame的apply()
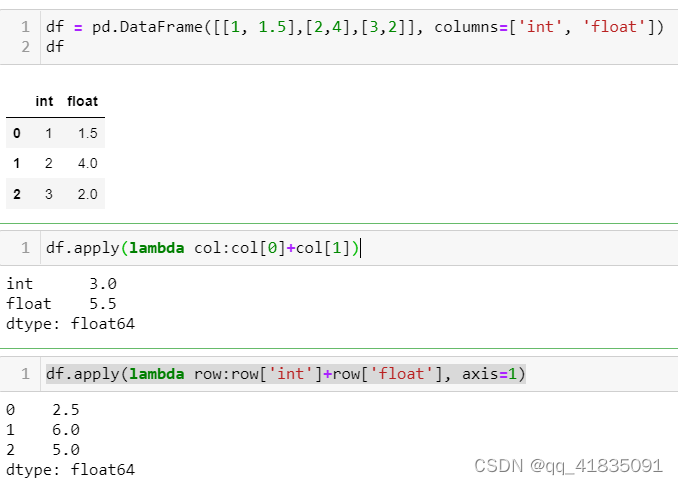
axis=0是index间操作,axis=1是columns间操作

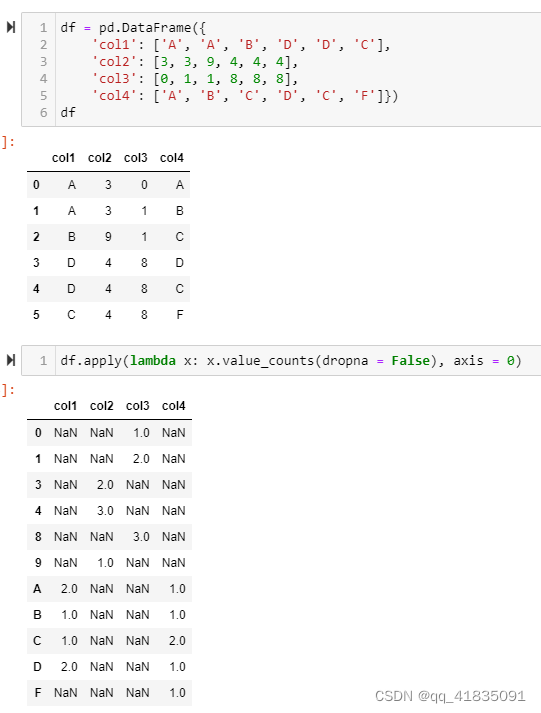
每列都统计value_counts()
按某列排序

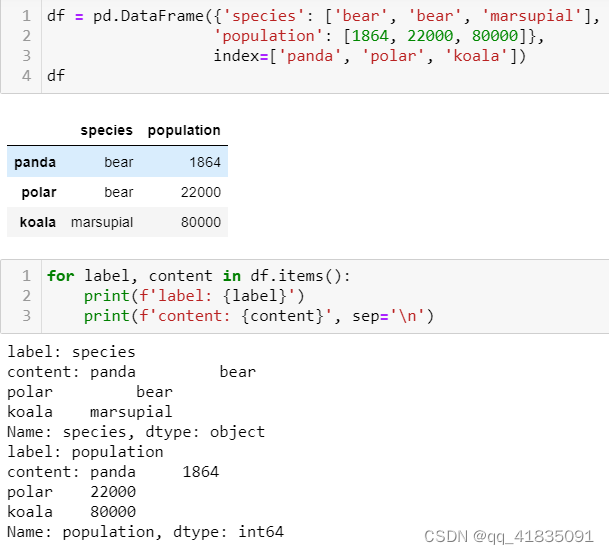
DataFrame迭代
- 按列迭代
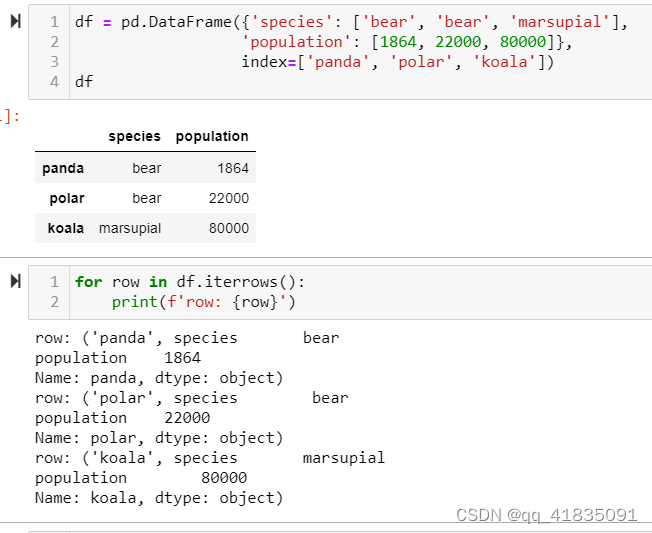
- 按行迭代
pivot()
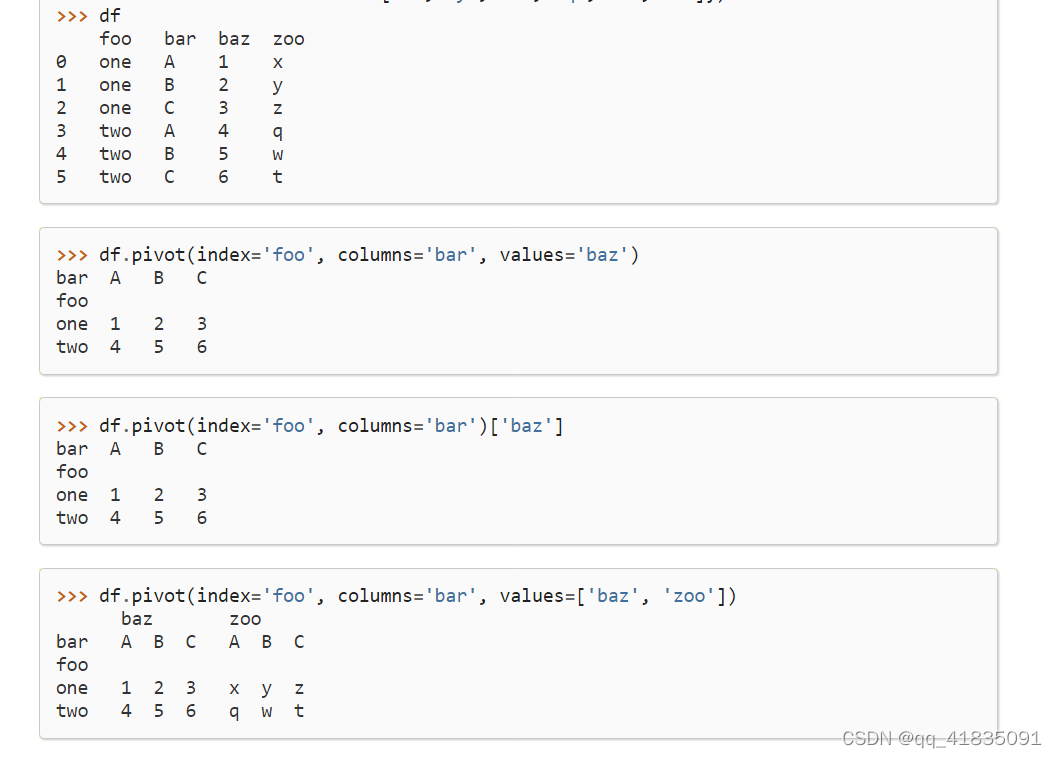
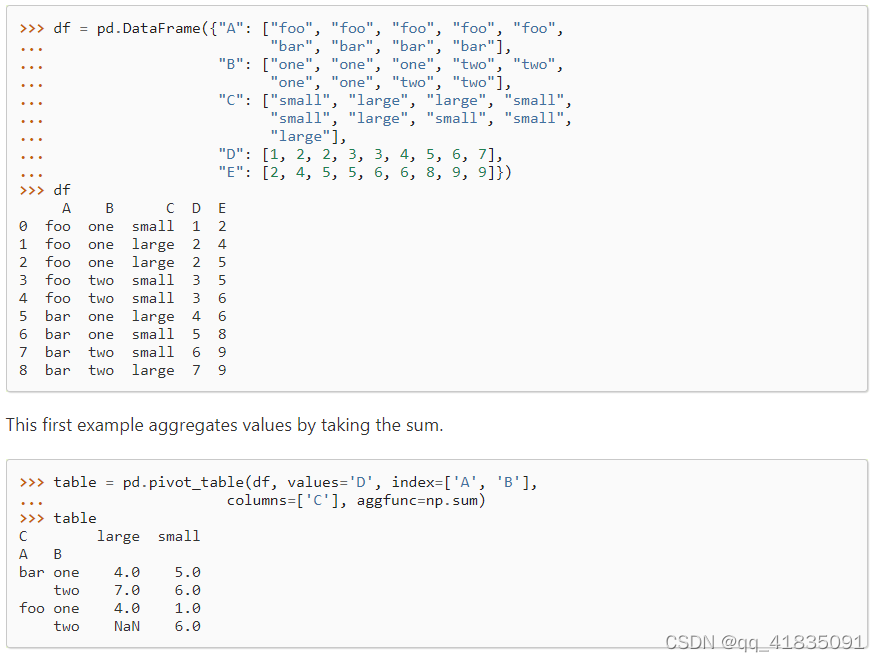
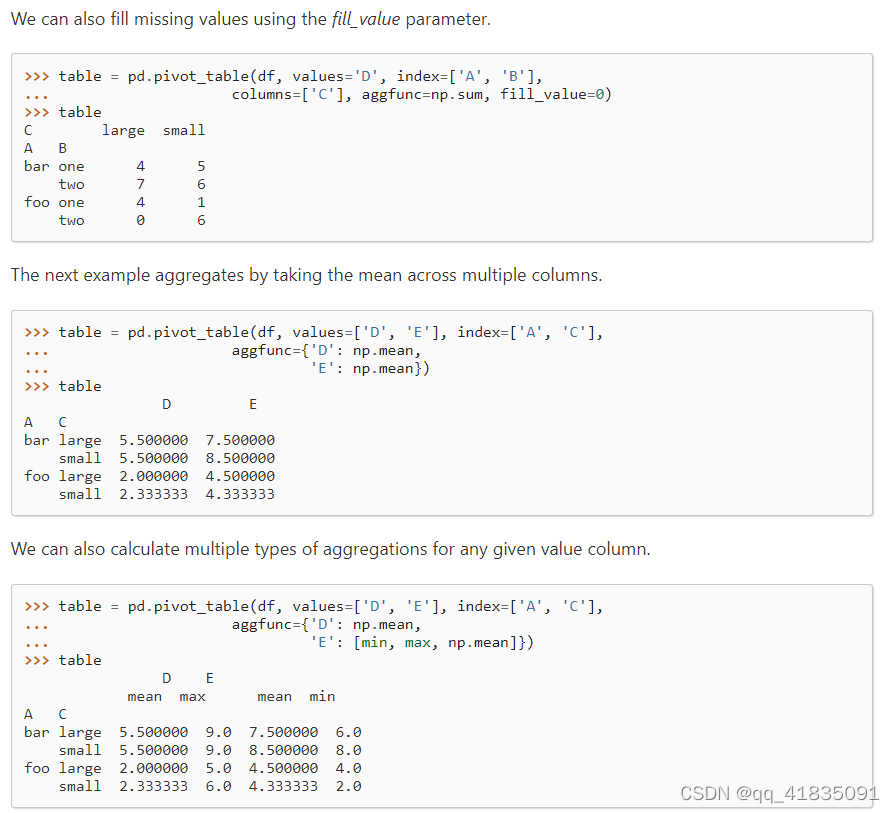
pivot_table()
crosstab()

正则表达式
df['url'] = df['url'].apply(lambda x: re.sub(':4443',':4442',x))
apply默认是行间的操作,这里把每行url列的3替换成了2
待更新:时间模块 datetime()