?NLP论文解读?原创?作者?|?FLIPPED
研究方向?| 机器翻译

导读
机器翻译是关于如何使用计算机将一种语言翻译成另一种语言的研究。
在方法论上,机器翻译的方法主要分为两类:基于规则的方法和基于语料库的方法。基于规则的机器翻译 (RBMT) 方法使用双语词典和手动编写的规则将源语言文本翻译成目标语言文本,然而手动编写规则是十分繁琐且难以维护的。
随着深度学习技术的发展,基于语料库方法之一的神经机器翻译(NMT)逐渐取代了早期基于规则的机器翻译方法,众多模型包括非自回归模型、无监督 NMT 模型以及 NMT 上的预训练模型(基于bert)等不断涌现。
尤其随着sequence to sequence 的翻译架构的提出和transformer模型的成熟与应用,神经机器翻译方法的翻译质量和效率得到了巨大的提升。本文将针对神经机器翻译目前发展的热点领域,分享最新的研究进展。
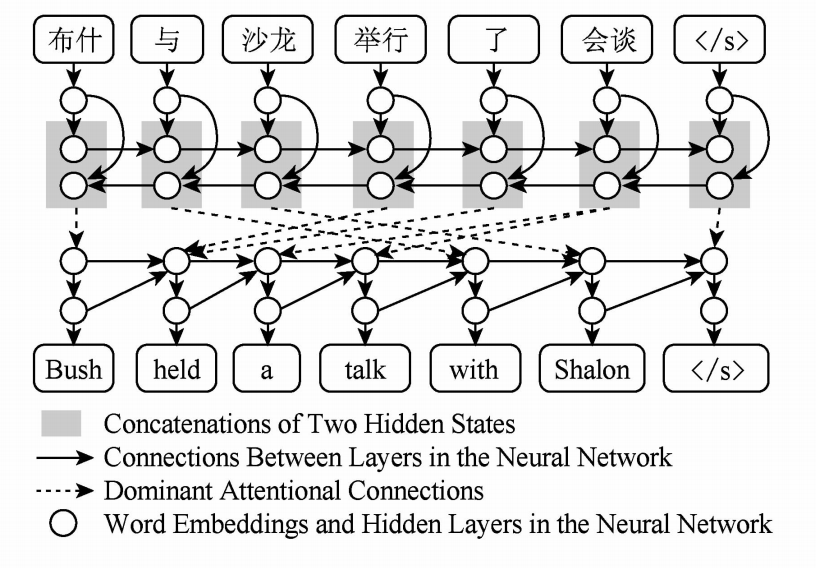
图1.基于注意力机制的神经网络翻译

低资源条件下的机器翻译
在现实世界中,部分小语种的机器翻译问题面临着极大的挑战。由于缺乏大量的平行语料,模型很难有效的学习到对应语言之间的映射关系。在这种情况下,采用迭代的back translation[1]和 self-training来扩充训练数据是一种行之有效的方法。
Back-translation通常训练一个从目标语言翻译成源语言的神经网络,单独利用目标语言的语料来得到源语言对应的文本,把这样得到的pair同时加到已有平行语料中一起训练。
Self-training则首先利用平行语料来训练一个正向的神经网络,然后将大量无标注的源语言数据翻译至目标语言,从而得到带噪的平行语料。将两者生成的语料混合重新训练一个更加准确且鲁棒的模型,进而将上述的过程迭代重复多次即可得到大量的合成数据。
在实际应用中,往往还需要结合质量评估系统(quality estimation system)进一步对合成数据进行清洗过滤,然而对于很多低资源的语言来说,这种评估系统的建立十分困难。
为了解决这一问题,有学者提出了一种数据挑选方法[2]来替代原始的评估系统。该方法根据测试集的领域匹配程度,可对原始的单一语料进行相关性排序,在每一轮迭代中选择最匹配的句子去生成合成数据。采用这种数据挑选的方法,不仅提升了数据合成的效率,并且取得了相似甚至超过原始质量评估系统的翻译结果。
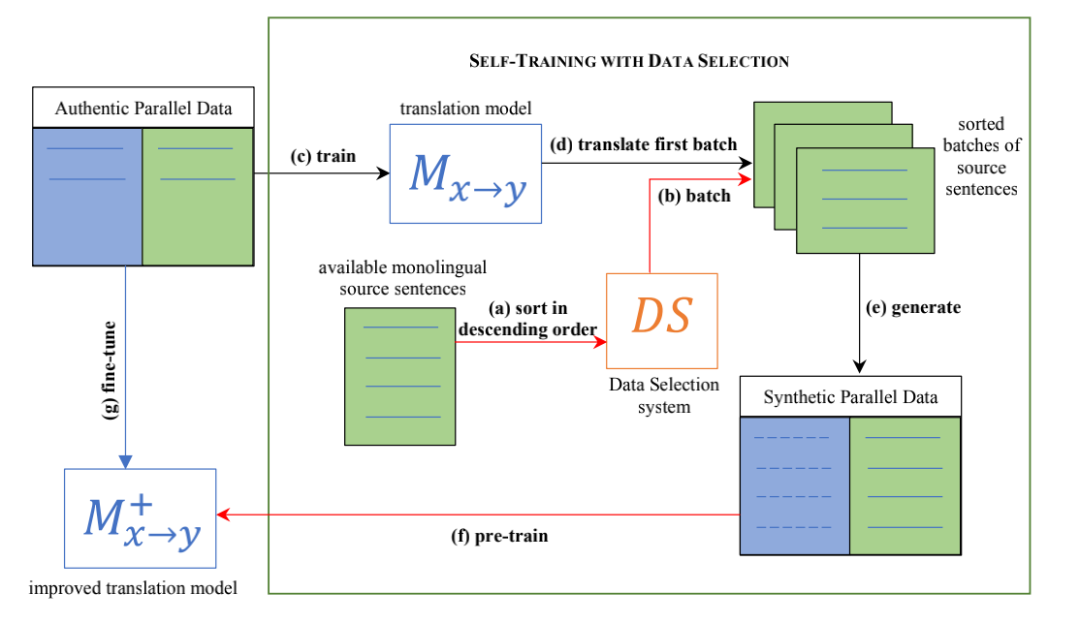
图2.用于self-training的数据选择方法

同声传译
Speech-to-text 的语音翻译问题相比于传统text-to-text的机器翻译问题更加具有挑战。首先source端语音到target文本之间存在着跨模态的语言映射,同时两种语言的不同进一步增加了学习这种映射之间的难度。
因此对于同声传译问题,在中高延迟条件下的模型主要基于级联系统,而级联系统的整个翻译过程涉及到两步预测,一方面增加了模型预测的时间进而造成较高的延迟,另一方面第一步预测结果的准确性将直接影响第二步文本翻译的质量,造成了错误的传播和叠加。
目前基于端到端的语音翻译模型受到了越来越多的关注,随着emformer[3]等模型的提出,长距离依赖的上下文信息可以被压缩到一个增强的存储器中(memory bank),为低延迟条件下的流式解码提供了方便。
目前同传大都采用wait-k[4]的策略进行解码,仍然存在由于重复编码导致的训练慢,以及缺少对未来信息建模的问题。此外如何通过改进wait-k使得模型智能决定解码时机也是目前解决端到端语音翻译面临的巨大挑战。

图3.级联系统示意图
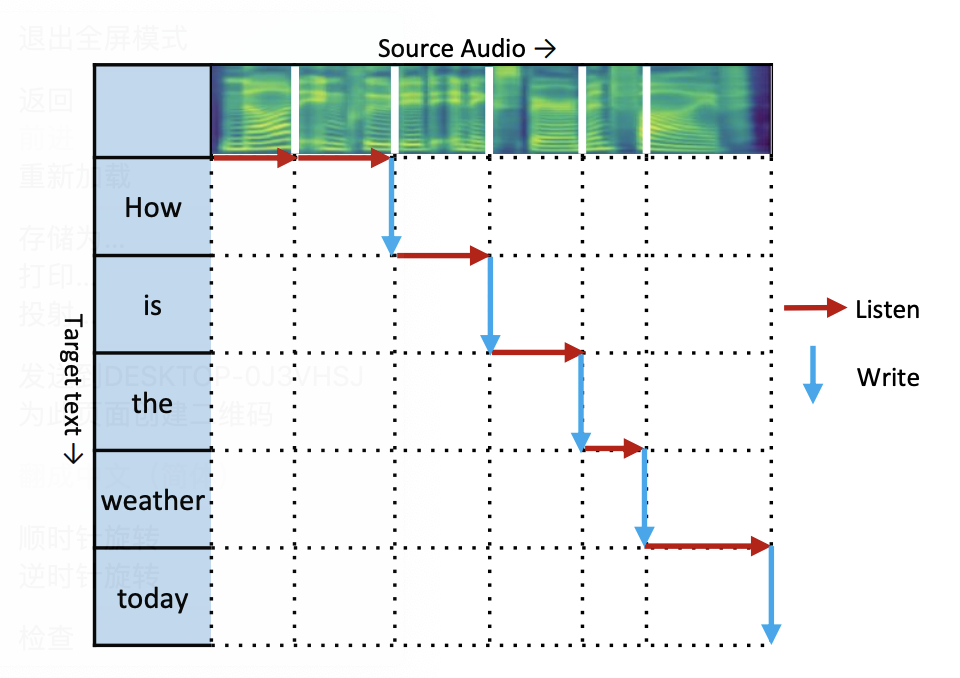
图4 Wait-k解码流程

one-to-many 多语言翻译
随着机器翻译的不断发展,多语言翻译逐渐受到了更多的关注,其中将一种源语言同时翻译成多种不同的目标语言是多语言翻译最常见的场景之一。相对于one-to-one的翻译模式,one-to-many的需求更贴合实际情况且更具商用价值。
解决这种多任务学习的通用框架如图5所示,首先通过大量的源语言数据训练一个共享的encoder, 然后根据不同的目标语言训练各自独立的decoder。然而这类方法在解码过程中不能充分利用翻译模型信息,如语内和语间的未来信息,因此可能会产生一些unbalanced output。
此外,尽管采用了多个decoder的模型构造,但在实际解码过程中,同一时刻只能针对一对语言的decoder进行解码,效率较低。在最新的研究中,有学者提出了同步交互式多语言神经机器翻译的新方法。
通过在解码的过程中有效利用到所有待翻目标语言的当前和未来的信息,它不仅能够同时产生多个目标语言翻译结果,并且相比于目前其他双语模型取得了更优的翻译结果。
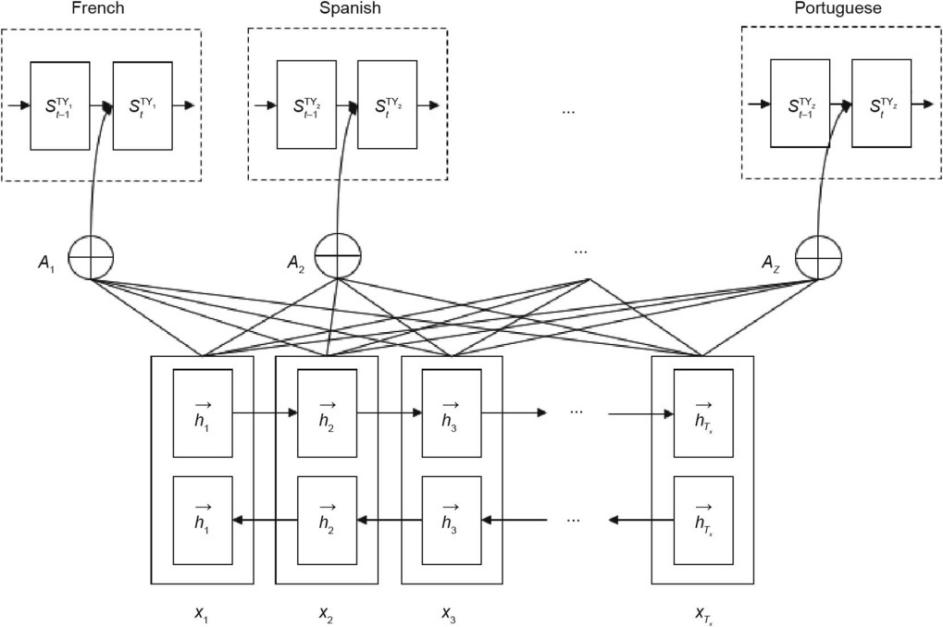
图5. one-to-many多任务学习的通用框架
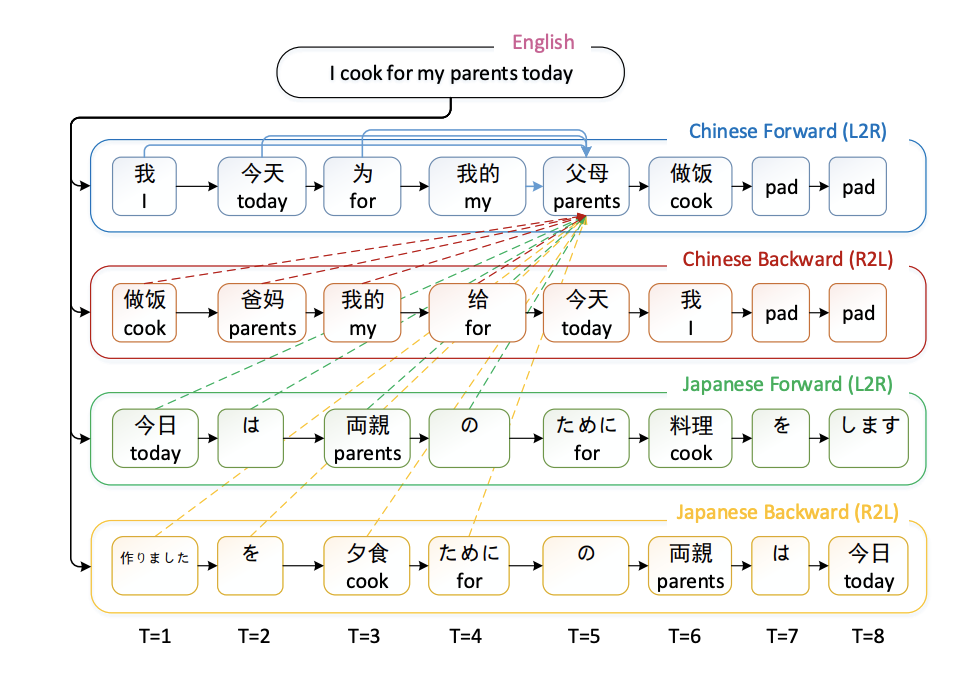
图6. 利用不同解码信息的多语言交互式解码框架[5]

模型的压缩与加速
为了提升机器翻译的性能,以transformer为主的翻译模型往往需要更深的网络以及更大的词表,然而这样庞大的计算模型不仅极大的增加了训练的代价和时间,也给模型的终端部署造成了巨大的困难。Partial Vector Quantization (P-VQ)[6]为轻量化和加速计算提供了一种新的解决方法。
首先将原始的词嵌入矩阵拆分为两个低维的矩阵,一个可共享一个独占。通过部分矢量量化的方法将共享的矩阵进行压缩,保持独占的矩阵不变以保持每个单词的唯一性,通过这种操作可极大减小词嵌入矩阵所占的存储空间。
同时在softmax层计算每个单词的概率分布时,将大多数的乘法操作转换为查找操作,从而显著加快计算速度。GPKD[7]方法从压缩模型的角度提出了新的解决方法。传统的深层transformer模型不仅计算昂贵而且极大消耗资源,该方法提出了一种新的基于group-permutation的知识蒸馏方法来将深层模型压缩为浅层模型。
为了进一步增强性能,文章还提出了一种Skipping Sub-Layer的正则化方法,通过随机删除某一子层进而增强扰动训练,两种方法均作用于encoder端。在多个基准(benchmark)上的实验结果验证了两种方法有效性。采用GPKD压缩模型比深度模型浅8倍,而BLEU几乎没有损失,这也为工业化的生产使用提供了可能。
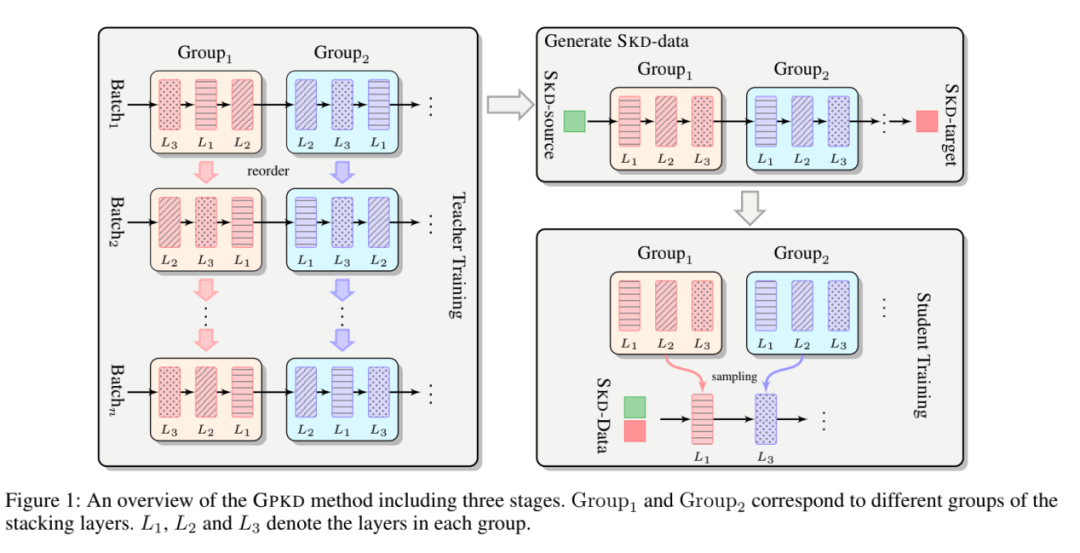
图7?GPKD方法
本文简要介绍了神经机器翻译部分领域的研究进展,可以看出尽管MT已经取得了很大的进步,但仍然有不少的问题需要解决。首先,MT需要更好的评价指标来评估真正重要的东西,尽管BLEU作为常用的评价指标已经能够对翻译的完整与准确性做出客观的评价,但在很多应用场景中可能没有标准的译文,或是在同传问题上还有必要考虑延迟的奖惩。
其次,MT 的鲁棒性需要进一步提高。有时源语言的细微变化(例如单词或标点符号)可能会导致翻译发生巨大变化。但是人类在翻译时具有很强的容错能力,可以灵活地处理各种不规范的语言现象和错误。
最后,NMT 方法在资源匮乏的语言对和领域中面临着严重的数据稀疏问题。目前的MT系统往往使用数千万甚至数亿句句对数据进行训练,否则翻译质量会很差,然而人类却能从少数样本中学习。
尽管已经提出了许多数据增强方法、多任务学习方法和预训练方法来缓解这个问题,但如何提高低资源语言对的翻译质量仍然是一个悬而未决的问题。综上所述,实现高质量的MT还有很长的路要走,未来有必要开发能够结合符号规则、知识和神经网络的新方法,以进一步提高翻译质量。
参考文献:
[1] Liao B, Khadivi S, Hewavitharana S. Back-translation for Large-Scale Multilingual Machine Translation[J]. arXiv preprint arXiv:2109.08712, 2021.
[2] Abdulmumin I, Galadanci B S, Ahmad I S, et al. Data Selection as an alternative to Quality Estimation in Self-Learning for Low Resource Neural Machine Translation[J].
[3] Shi Y, Wang Y, Wu C, et al. Emformer: Efficient memory transformer based acoustic model for low latency streaming speech recognition[C]//ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021: 6783-6787.
[4] Elbayad M, Besacier L, Verbeek J. Efficient wait-k models for simultaneous machine translation[J]. arXiv preprint arXiv:2005.08595, 2020.
[5] He H, Wang Q, Yu Z, et al. Synchronous Interactive Decoding for Multilingual Neural Machine Translation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(14): 12981-12988.
[6] Zhang F, Tu M, Yan J. Accelerating Neural Machine Translation with Partial Word Embedding Compression[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(16): 14356-14364.
[7] Li B, Wang Z, Liu H, et al. Learning light-weight translation models from deep transformer[J]. arXiv preprint arXiv:2012.13866, 2020.
?