k-means
- 用于无监督学习
- 用于分类
- 思想:我们假设相似的事物之间的距离也会比较近,即:“物以类聚,人以群分”的思想。因此对于给定的样本集, 按照样本之间的距离,将样本集划分为k个簇。然后让簇内尽量紧密,簇间尽量距离大,从而实现分类。
- 特点:
- 优点
- 思路比较简单
- 实现简单
- 聚类效果不错
- 可解释性强
- 缺点
- 对于噪点很敏感。如果在远处有一个早点,那么簇中心的位置就可能有很大的偏移
- k 值很难确定
- 如果两个簇间的距离比较近,此时效果也不好
- 初始值对结果影响很大,因此容易出现每次聚类的结果均不一样
- 优点
- 过程:
- 随机选择 k 个样本作为簇心
- 计算各个样本到簇中心的距离,将最小的距离的作为此类别
- 迭代计算,直至类别(簇心)不再发生变化
- 输出类别
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs # 选择内置的生成聚类的数据集
from sklearn.cluster import KMeans
# make_blobs:生成聚类的数据集
# n_samples:生成的样本点个数,n_features:样本特征数,centers:样本中心数
# cluster_std:聚类标准差,shuffle:是否打乱数据,random_state:随机种子
# 300数据,3个样本特征,四个中心点(k=4),
x, y = make_blobs(n_samples=300, n_features=3,centers=4, cluster_std=0.5,shuffle=True, random_state=0)
plt.scatter(x[:, 0], x[:, 1], c='green', marker='o', edgecolors='black', s=50)
plt.show()
x, y = make_blobs(n_samples=300, n_features=3,centers=10, cluster_std=0.5,shuffle=True, random_state=0)
plt.scatter(x[:, 0], x[:, 1], c='green', marker='o', edgecolors='black', s=50)
plt.show()
X, y = make_blobs(n_samples=150, n_features=2,centers=3, cluster_std=0.5,shuffle=True, random_state=0)
# 散点图
# c:点的颜色,marker:点的形状,edgecolor:点边缘的形状,s:点的大小
plt.scatter(X[:, 0], X[:, 1],c='white', marker='o',edgecolor='black', s=50)
plt.show()
?
?
?由上可以看出,即使是手动生成的数据,当k值过大的时候,效果有时候也会不尽如人意。 下面我使用k为3的数据集做训练,分类
# 定义模型
# n_clusters:要形成的簇数,即k均值的k,init:初始化方式,tot:Frobenius 范数收敛的阈值
model = KMeans(n_clusters=3, init='random',n_init=10, max_iter=300, tol=1e-04, random_state=0)
# 训练加预测
y_pred = model.fit_predict(X)
# 画出预测的三个簇类
plt.scatter(
X[y_pred == 0, 0], X[y_pred == 0, 1],
s=50, c='lightgreen',
marker='s', edgecolor='black',
label='cluster 1'
)
plt.scatter(
X[y_pred == 1, 0], X[y_pred == 1, 1],
s=50, c='orange',
marker='o', edgecolor='black',
label='cluster 2'
)
plt.scatter(
X[y_pred == 2, 0], X[y_pred == 2, 1],
s=50, c='lightblue',
marker='v', edgecolor='black',
label='cluster 3'
)
# 画出聚类中心
plt.scatter(
model.cluster_centers_[:, 0], model.cluster_centers_[:, 1],
s=250, marker='*',
c='red', edgecolor='black',
label='centroids'
)
plt.legend(scatterpoints=1)
plt.grid()
plt.show()?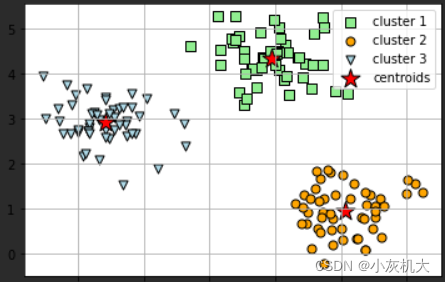
?
# 计算inertia随着k变化的情况
distortions = []
for i in range(1, 10):
model = KMeans(
n_clusters=i, init='random',
n_init=10, max_iter=300,
tol=1e-04, random_state=0
)
model.fit(X)
distortions.append(model.inertia_)
# 画图可以看出k越大inertia越小,追求k越大对应用无益处
plt.plot(range(1, 10), distortions, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()?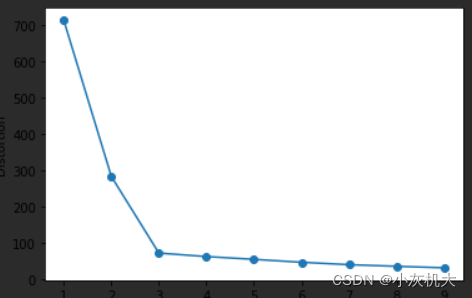
?