一、 简介
DataFrame是Pandas中最常用的数据类型,是一个二维表格型的数据结构。DataFrame由Series组成,Series是一个一维的带标签的数据结构,numpy的所有数组运算函数都可以直接用于操作Series。
时间是现实中最常用数据对象之一,常被Pandas用作数据标签(索引)。Pandas也提供了非常丰富的时间处理函数,包括时间点、时间段、时间间隔等相关对象和操作。
Pandas系列将Pandas的知识和重点API,编制成思维导图和重点笔记形式,方便记忆和回顾,也方便应用时参考,初学者也可以参考逐步深入学习。
二、 思维导图
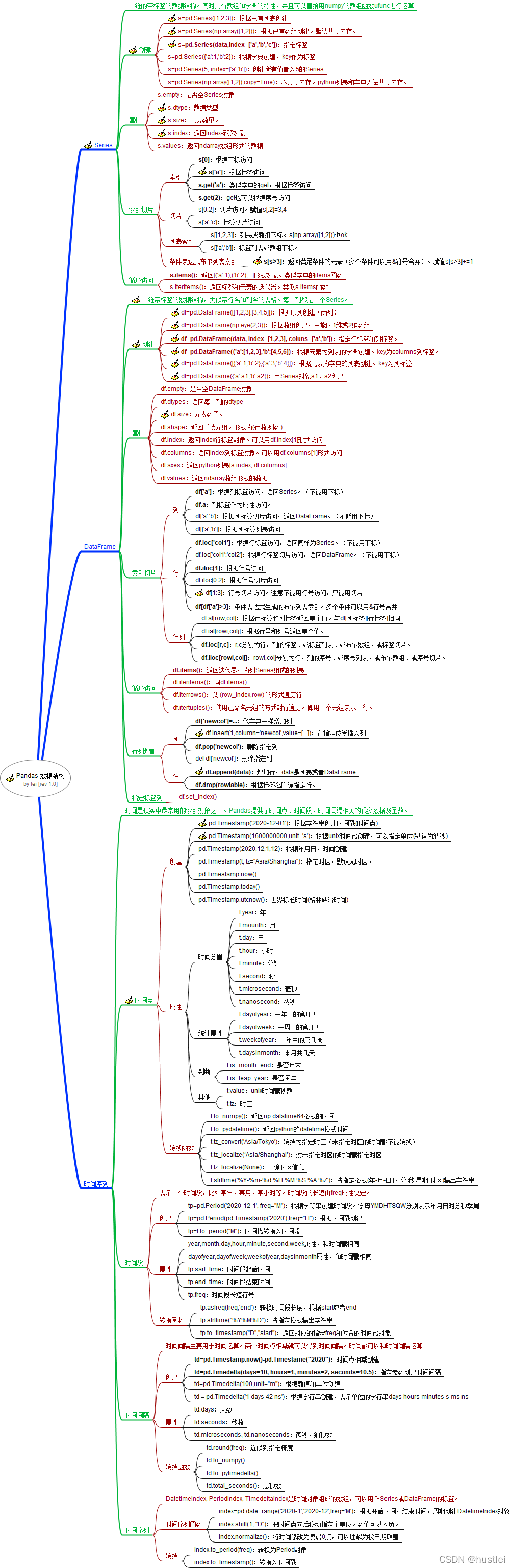
三、 Pandas数据结构
1. Series
1.1 简介
Series是Pandas最基本的对象,Series定义了Numpy的ndarray的接口array(),
所以可以直接用Numpy的数组处理函数直接对Series处理。
Pandas是一个一维的带标签的数据结构。同时具有数组和字典的特性。
1.2 创建Series
可以用已有的列表、数组、字典创建Series。
s=pd.Series([1,2,3]):根据已有列表创建s=pd.Series(np.array([1,2])):根据已有数组创建。默认Series和numpy数组共享内存。s=pd.Series(data,index=['a','b','c']):指定标签s=pd.Series({'a':1,'b':2}):根据字典创建,key作为标签s=pd.Series(5, index=['a','b']):创建所有值都为5的Seriess=pd.Series(np.array([1,2]),copy=True):不共享内存。python列表和字典无法共享内存
- 不指定标签创建Series时,默认的标签为从0到n-1顺序编号。
- 创建Series的时候,可以用dtype参数设置数据类型。
- 用不同的数据类型也可以,比如
pd.Series([1,'a']),但是得到的Series的dtype为object
1.3 Series属性
s.empty:是否空Series对象s.dtype:数据类型s.size:元素数量。s.index:返回Index标签对象s.values:返回ndarray数组形式的数据
s.ndim总是返回1。s.shape总是返回(size,)。s.axes:返回python列表
[s.index]。所以这几个属性较少用。
1.4 索引切片
1.4.1 索引
s[0]:根据下标访问s['a']:根据标签访问。(未指定标签的Series,标签和下标相同)s.get('a'):类似字典的get,根据标签或下标访问(s.get(2)也是可以的)。无值时返回None
1.4.2 切片
s[0:2]:切片访问。s['a':'c']:标签切片访问
1.4.3 列表索引
s[[1,2,3]]:下标列表或数组。s[np.array([1,2]))也oks[['a','b']]:标签列表或数组。
1.4.4 条件表达式布尔列表索引
s[s>3]:返回满足条件的元素(多个条件可以用&符号合并)。实际上就是bool类型列表索引
1.5 循环访问
s.items():返回[('a':1),('b':2),...]形式对象。类似字典的items函数s.iteritems():返回标签和元素的迭代器。类似s.items函数
2. DataFrame
2.1 简介
DataFrame是一个二维带标签的数据结构,类似带行名和列名的表格。典型的DataFrame:
>>> df
语文 数学 计算机
小明 70 80 75
小王 80 75 85
小鱼儿 90 88 83
每一列都是一个Series。DataFrame的行数、列数允许增加或者删除。
2.2 创建
可以根据数组(或列表)、字典创建。
df=pd.DataFrame([[1,2,3],[3,4,5]]):根据序列创建(两列)df=pd.DataFrame(np.eye(2,3)):根据数组创建,只能时1维或2维数组df=pd.DataFrame(data, index=[1,2,3], coluns=['a','b']):指定行标签和列标签。df=pd.DataFrame({'a':[1,2,3],'b':[4,5,6]}:根据元素为列表的字典创建。key为columns列标签。- 用index参数可以指定行标签。
- 用columns参数可以覆盖字典中的列标签,最终采用columns中的标签。
df=pd.DataFrame([{'a':1,'b':2},{'a':3,'b':4}]):根据元素为字典的列表创建。key为列标签- 字典的key不同时,每个key作为一列(某一行数据对应的列无数据时,取值NaN)
df=pd.DataFrame({'a':s1,'b':s2}):用Series对象s1、s2创建。Series的行标签不同时,为每个标签创建单独的行。
可以用dtype参数设置数据类型。
2.3 属性
df.empty:是否空DataFrame对象df.dtypes:返回每一列的dtypedf.size:元素数量。- df.ndim总是返回2。
df.shape:返回形状元组。形式为(行数,列数)df.index:返回Index行标签对象。可以用df.index[1]形式访问df.columns:返回Index列标签对象。可以用df.columns[1]形式访问df.axes:返回python列表[s.index, df.columns]df.values:返回ndarray数组形式的数据
2.4 索引切片
2.4.1 列
- 标签访问(单列)
df['a']:根据列标签访问,返回Series。(不能用下标)df.a:列标签作为属性访问。
- 标签切片(多列)
df['a':'b']:根据列标签切片访问,返回DataFrame。(不能用下标)df[['a','b']]:根据列标签列表访问
2.4.2 行
- loc函数根据行标签访问
df.loc['col1']:根据行标签访问,返回同样为Series。(不能用下标)df.loc['col1':'col2']:根据行标签切片访问,返回DataFrame。(不能用下标)
- iloc根据行下标访问
df.iloc[1]:根据行号访问df.iloc[0:2]:根据行号切片访问df[1:3]:行号切片访问。注意不能用行号访问,只能用切片(建议用iloc)
- 条件下标访问
df[df['a']>3]:条件表达式生成的布尔列表索引。多个条件可以用&符号合并
2.4.3 行列同时访问
- 单个元素访问
df.at[row,col]:根据行标签和列标签返回单个值。与df[列标签][行标签]相同df.iat[rowi,colj]:根据行号和列号返回单个值。
- 多个元素(也可以单个元素访问)
df.loc[r,c]:r,c分别为行,列的标签、或标签列表、或布尔数组、或标签切片。df.iloc[rowi,colj]:rowi,colj分别为行,列的序号、或序号列表、或布尔数组、或序号切片。
2.5 循环访问
df.items():返回迭代器,为列Series组成的列表df.iteritems():同df.items()df.iterrows():以 (row_index,row) 的形式遍历行df.itertuples():使用已命名元组的方式对行遍历。即用一个元组表示一行。
2.6 行列增删
2.6.1 列
- 增加列
df['newcol']=[1,2,3]:像字典一样增加列df.insert(1,column='newcol',value=[1,2,3]):在指定位置插入列- column和value都必须指定。
- value的元素个数也必须与df的行数相同。
- 删除列
df.pop('newcol'):删除指定列del df['newcol']:删除指定列
2.6.2 行
df.append(data):增加行,data是DataFrame。- 不能直接append numpy数组、Series和列表。
- 列表和Series需要处理转换为二维可以append,但是不建议用。
df.drop(rowlabel):删除指定行(用标签)- df.drop([row1,row2]):删除多行
2.7 指定标签列
通常我们不直接设置行标签,而是把某个数据列指定为列标签。比如姓名,日期,学号等等。
df.set_index("日期"):把指定列设置为行索引标签,参数为列名称。- drop参数(默认为True),即把列直接转换为索引。drop为False时,则索引和数据中都保留指定的列数据。
df.set_index(["姓名","日期"]):设置多个索引标签df.reset_index(drop=False):还原索引,重新变为默认的整型索引。- drop为False则索引列会被还原为普通列,否则会丢失。
>>> df
a b c
0 1 2 3
1 4 5 6
2 7 8 9
>>> df.set_index('a')
b c
a
1 2 3
4 5 6
7 8 9
>>> df.set_index('a', drop=False)
a b c
a
1 1 2 3
4 4 5 6
7 7 8 9
3. 时间序列
3.1 时间点
Timestamp从python的datetime继承。
3.2.1 创建Timestamp
pd.Timestamp('2020-12-01'):根据字符串创建时间戳(时间点)pd.Timestamp("2020-1-2 12:23"):根据字符串创建时间戳。pd.Timestamp("2020-1-2T12:23")效果相同pd.Timestamp(1600000000,unit='s'):根据unix时间戳创建,可以指定单位(默认为纳秒)pd.Timestamp(2020,12,1,12):根据年月日,时间创建pd.Timestamp(t, tz="Asia/Shanghai"):指定时区,默认无时区。pd.Timestamp.now()pd.Timestamp.today()pd.Timestamp.utcnow():世界标准时间(格林威治时间)
unix时间戳是从1970年1月1日开始经过的时间,通常用秒做单位。
3.2.2 属性
- 时间分量
- t.year:年
- t.mounth:月
- t.day:日
- t.hour:小时
- t.minute:分钟
- t.second:秒
- t.microsecond:毫秒
- t.nanosecond:纳秒
- 统计属性
- t.dayofyear:一年中的第几天
- t.dayofweek:一周中的第几天
- t.weekofyear:一年中的第几周
- t.daysinmonth:本月共几天
- 判断
- t.is_month_end:是否月末
- t.is_leap_year:是否闰年
- 其他
- t.value:unix时间戳秒数
- t.tz:时区
3.2.3 转换函数
t.to_numpy():返回np.datatime64格式的时间t.to_pydatetime():返回python的datetime格式时间t.tz_convert('Asia/Tokyo'):转换为指定时区(未指定时区的时间戳不能转换)t.tz_localize('Asia/Shanghai'):对未指定时区的时间戳指定时区t.tz_localize(None):删除时区信息t.strftime('%Y-%m-%d:%H:%M:%S %A %Z'):按指定格式(年-月-日:时:分:秒 星期 时区)输出字符串
3.3 时间段
3.3.1 简介
Period用于表示一个时间段,比如某年、某月、某小时等。时间段的长短由freq属性决定。
3.3.2 创建
tp=pd.Period('2020-12-1', freq="M"):根据字符串创建时间段。- 字母"YMDHTSQW"分别表示年月日时分秒季周。A也表示年
- A-DEC,W-SUN,Q-DEC表示年周季中的月天等。一般默认都是12月或星期天。
tp=pd.Period(pd.Timestamp('2020'),freq="H"):根据时间戳创建tp=t.to_period("M"):时间戳转换为时间段
3.3.3 属性
- 与Timestamp相同的属性
- year,month,day,hour,minute,second,week
- dayofyear,dayofweek,weekofyear,daysinmonth
tp.sart_time:时间段起始时间tp.end_time:时间段结束时间tp.freqstr:时间段长短符号- tp.freq:返回一个表示时间段的对象
3.3.4 转换函数
tp.asfreq(freq,'end'):转换时间段长度,根据start或者endtp.strftime("%Y%M%D"):按指定格式输出字符串tp.to_timestamp("D","start"):返回对应的指定freq和位置的时间戳对象
3.4 时间间隔
3.4.1 简介
时间间隔主要用于时间运算。两个时间点相减就可以得到时间间隔。时间戳可以和时间间隔运算。
3.4.2 创建
td=pd.Timestamp.now()-pd.Timestame("2020"):时间点相减创建td=pd.Timedelta(days=10, hours=1, minutes=2, seconds=10.5):指定参数创建时间间隔td=pd.Timedelta(100,unit="m"):根据数值和单位创建td = pd.Timedelta('1 days 42 ns'):根据字符串创建,表示单位的字符串days hours minutes s ms ns
3.4.3 属性
- td.days:天数
- td.seconds:秒数
- td.microseconds:微秒
- td.nanoseconds:纳秒数
3.4.4 转换函数
td.round(freq):近似到指定精度td.to_numpy():转换为numpy格式td.to_pytimedelta():转换为python的timedelta格式td.total_seconds():时间间隔总秒数
3.5 时间序列
3.5.1 简介
DatetimeIndex, PeriodIndex, TimedeltaIndex 是时间对象组成的数组,可以用作Series或DataFrame的标签,也可以直接作为DataFrame的列数据。
3.5.2 时间序列函数
index=pd.date_range('2020-1','2020-12',freq='M'):根据开始时间,结束时间,周期创建DatetimeIndex对象index.shift(1, "D"):把时间点向后移动指定个单位。数值可以为负。index.normalize():将时间修改为凌晨0点,可以理解为按日期取整
3.5.3 转换
index.to_period(freq):转换为Period对象index.to_timestamp():转换为时间戳
个人总结,部分内容进行了简单的处理和归纳,如有谬误,希望大家指出,持续修订更新中。