Log
2021.12.31寒假开始,开个新坑,记录一些机器学习的笔记,还是老样子放上本次资源,学习视频传送门:[中英字幕]吴恩达机器学习系列课程
2022.01.01感觉加上总结部分思路会比较清晰
前言
- 机器学习:
- 从人工智能(AI)发展出来的一个领域
- 为计算及开发的一项新功能
- 例子:
- 数据挖掘:
- 网络和自动化技术的发展产生了大量的数据集
- e.g. 网络点击数据(分析用户喜爱,精准推送)、医疗记录(电子医疗记录分析更好地理解疾病)、计算生物学(DNA序列,理解人类基因组)、工程学领域(理解数据集)
- 无法手动编写的程序 :
- e.g. 直升机自己飞行(无法编程实现,只能让飞机自己学习如何飞)、手写识别(跨国邮寄,学习算法自动识别地址、自动规划路线)、NLP自然语言处理、计算机视觉
- 私人订制程序:
- e.g. 机器自我学习,根据用户偏好量身定制内容(短视频、电影、商品)推送算法
- 理解人类学习过程(人类大脑)
- 数据挖掘:
一、什么是机器学习?
一些现有的定义:
- Arthur Samuel(1959):在没有明确设置的情况下,使计算机具有学习能力的领域研究
- Tom Mitchell(1998):计算机程序从经验E中学习,解决某一任务T,进行某一性能度量P,通过P测定在T上的表现因经验E而提高。(人话:就是奖励机制,做的好了奖励多,奖励多了就多做)
用一个例子来解释一下:- 经验E――自己多次下棋
- 任务T――下棋
- 性能度量P――与新对手下棋时获胜的概率
二、课程学习内容
- 机器学习算法:
- 监督学习――教计算机怎么做
- 无监督学习――计算机自己学习
- 其他算法: 强化学习、推荐系统
- 应用学习算法时的实际建议
三、监督学习

- 监督学习(Supervised learning): 给算法一个数据集,其中包含正确答案,算法的目的就是给出更多的正确答案,如房子的价格、肿瘤是恶性的还是良性的。
- 回归问题(Regression problem): 回归是指我们的目标是预测的一个连续值输出 ,如根据已有信息预测目标房子的价格。
- 分类问题(Classification problem): 目的是预测离散值输出,如根据给出的一系列特征(恶性肿瘤和良性肿瘤患者的年龄、肿瘤大小等信息)来预测患者肿瘤为恶性或良性。
四、无监督学习
-
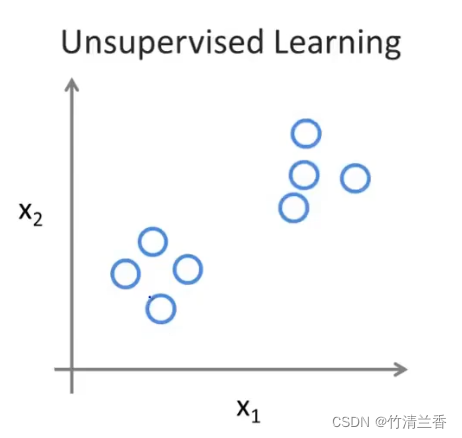
无监督学习(Unsupervised learning): 与监督学习不同,监督学习中数据集中的每个数据都有明确的标签(如一个肿瘤为良性或者位恶性[a benign or a malignant tumor]),即被清楚地告知什么是“正确答案”,无监督学习中的数据没有任何标签(都有相同的标签或都没有标签),即不把数据集的正确答案给算法,通过算法来找出数据的结构 。
-
聚类算法(Clustering algorithm): 如上图中的例子可以被分为两个簇(cluster)。聚类算法应用广泛,如谷歌新闻收集大量新闻合成为一个个新闻专题 、基因组学中的DNA微阵列数据(即检测不同的个体特定基因的表达程度)。
-
聚类算法应用:
- 组织大型的计算机集群(Organize computing clusters): 将趋向协同工作的计算机放到一起,以此实现数据中心更高效的工作
- 社交网络的分析(Social network analysis): 通过email、社交软件中的联系人来自动识别同属一个圈子的朋友,判断那些人互相认识。
- 市场细分(Market segmentation): 将庞大的客户信息数据集(预先不知道有哪些细分市场,客户属于那些细分市场)自动找出不同的市场分割,并将客户分到不同的细分市场,从而高效的在不同的细分市场中进行销售。
- 天文数据分析(Astronomical data analysis): 聚类算法带来了惊人的有趣且实用的星系形成理论。
-
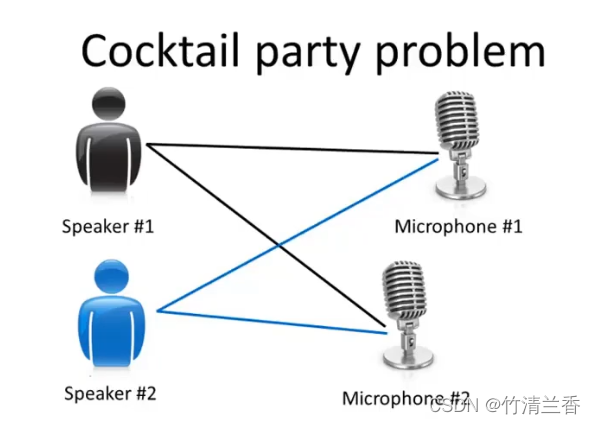
鸡尾酒舞会算法: 鸡尾酒会问题如下图,两个人的站位对于两个麦克风的距离各不相同,随后二人同时说话的音频将会被这两台设备捕获,鸡尾酒算法就是将这两个被叠加的音频分离开来 。
- 实现的代码:
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');(看似简单但是想出来不容易,如果使用正确的编程环境,学习算法都可以是简短的程序,因此在这门课程中要使用Octave的编程环境) - svd函数――奇异值分解(singular value decomposition)
- 实现的代码:
-
使用Octave建立原型,再用其它的编程语言会更有效率。因为作为开发者,时间是最宝贵的资源之一,例如上述函数已经内置在Octave中,而如果要用c++、java等来编写则需要花费大量的时间来导入库。
-
另补充一下,Octave是一款免费开源软件。
总结
- 本文简单地介绍了一下监督学习和无监督学习两个算法的概念以及应用,两个算法的区别就在于监督学习从一开始给出了数据的“正确答案”而无监督学习则不会给出。
- 同时还着重介绍了监督学习中的回归问题和分类问题,二者都是对数据进行预测,区别在于回归问题预测的是连续的数据,而分类问题预测的是离散的数据
- 无监督学习中的聚类算法和鸡尾酒舞会算法,聚类算法应用广泛,简而言之就是通过算法将数据集划分成不同的集合,鸡尾酒舞会算法则作为例子引出了Octave在开发过程中的重要性。