????????MNIST数据集是一个非常经典的手写数字识别的数据集,本人很多文章都是拿这个数据集来做示例,MNIST的具体介绍与用法可以参阅:
MNIST数据集手写数字识别(一)![]() https://blog.csdn.net/weixin_41896770/article/details/119576575
https://blog.csdn.net/weixin_41896770/article/details/119576575
MNIST数据集手写数字识别(二)![]() https://blog.csdn.net/weixin_41896770/article/details/119710429
https://blog.csdn.net/weixin_41896770/article/details/119710429
本章在前面介绍卷积层和池化层的基础上,构造一个简单的卷积神经网络来看下这个学习效果怎么样。老规矩,先来一张CNN的网络构造图,直观清晰。我将把所有代码都贴出来分享给大家,算是对2021年整年的一个完美收尾。

在图像处理领域,基本都会使用到CNN,所以说掌握卷积神经网络就显得特别重要了。代码就是解释,有什么疑问的地方,欢迎留言交流。?
simple_convnet.py
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
import pickle
class SimpleConvNet:
'''
input_dim:输入数据形状(MNIST手写数字)
conv_param:卷积层字典的超参数(滤波器数量、滤波器大小、填充、步幅)
weight_init_std:权重的标准差
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
'''
def __init__(self,input_dim=(1,28,28),conv_param={'filter_num':30,'filter_size':5,'pad':0,'stride':1},hidden_size=100,output_size=10,weight_init_std=0.01):
filter_num=conv_param['filter_num']
filter_size=conv_param['filter_size']
filter_pad=conv_param['pad']
filter_stride=conv_param['stride']
input_size=input_dim[1]
conv_output_size=(input_size-filter_size+2*filter_pad) / filter_stride+1
pool_output_size=int(filter_num * (conv_output_size/2) * (conv_output_size/2))
#权重和偏置的初始化
self.params={}
self.params['W1']=weight_init_std * np.random.randn(filter_num,input_dim[0],filter_size,filter_size)
self.params['b1']=np.zeros(filter_num)
self.params['W2']=weight_init_std * np.random.randn(pool_output_size,hidden_size)
self.params['b2']=np.zeros(hidden_size)
self.params['W3']=weight_init_std * np.random.randn(hidden_size,output_size)
self.params['b3']=np.zeros(output_size)
#生成CNN的各层
self.layers=OrderedDict()
self.layers['Conv1']=Convolution(self.params['W1'],self.params['b1'],conv_param['stride'],conv_param['pad'])
self.layers['Relu1']=Relu()
self.layers['Pool1']=Pooling(pool_h=2,pool_w=2,stride=2)
self.layers['Affine1']=Affine(self.params['W2'],self.params['b2'])
self.layers['Relu2']=Relu()
self.layers['Affine2']=Affine(self.params['W3'],self.params['b3'])
self.last_layer=SoftmaxWithLoss()
def predict(self,x):
for layer in self.layers.values():
x=layer.forward(x)
return x
def loss(self,x,t):
y=self.predict(x)
return self.last_layer.forward(y,t)
def accuracy(self,x,t,batch_size=100):
if t.ndim != 1 : t=np.argmax(t,axis=1)
acc=0.0
for i in range(int(x.shape[0] / batch_size)):
tx=x[i*batch_size:(i+1)*batch_size]
tt=t[i*batch_size:(i+1)*batch_size]
y=self.predict(tx)
y=np.argmax(y,axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self,x,t):
'''
数值微分求梯度
'''
loss_w=lambda w: self.loss(x,t)
grads={}
for idx in (1,2,3):
grads['W'+str(idx)]=numerical_gradient(loss_w,self.params['W'+str(idx)])
grads['b'+str(idx)]=numerical_gradient(loss_w,self.params['b'+str(idx)])
return grads
def gradient(self,x,t):
'''
误差反向传播法求梯度
'''
# forward
self.loss(x,t)
# backward
dout=1
dout=self.last_layer.backward(dout)
layers=list(self.layers.values())
layers.reverse()
for layer in layers:
dout=layer.backward(dout)
grads={}
grads['W1'],grads['b1']=self.layers['Conv1'].dW,self.layers['Conv1'].db
grads['W2'],grads['b2']=self.layers['Affine1'].dW,self.layers['Affine1'].db
grads['W3'],grads['b3']=self.layers['Affine2'].dW,self.layers['Affine2'].db
return grads
def save_params(self,file_name="params.pkl"):
params={}
for key,val in self.params.items():
params[key]=val
with open(file_name,'wb') as f:
pickle.dump(params,f)
def load_params(self,file_name="params.pkl"):
with open(file_name,'rb') as f:
params=pickle.load(f)
for key,val in params.items():
self.params[key]=val
for i,key in enumerate(['Conv1','Affine1','Affine2']):
self.layers[key].W=self.params['W'+str(i+1)]
self.layers[key].b=self.params['b'+str(i+1)]layers.py
import numpy as np
from common.functions import *
from common.util import im2col,col2im
class Relu:
def __init__(self):
self.mask=None
def forward(self,x):
self.mask=(x<=0)
out=x.copy()
out[self.mask]=0
return out
def backward(self,dout):
dout[self.mask]=0
dx=dout
return dx
class Sigmoid:
def __init__(self):
self.out=None
def forward(self,x):
out=sigmoid(x)
self.out=out
return out
def backward(self,dout):
dx=dout*(1.0-self.out)*self.out
return dx
class Affine:
def __init__(self,W,b):
self.W=W
self.b=b
self.x=None
self.original_x_shape=None
# 权重和偏置参数的导数
self.dW=None
self.db=None
def forward(self,x):
# 对应张量
self.original_x_shape=x.shape
x=x.reshape(x.shape[0],-1)
self.x=x
out=np.dot(self.x,self.W)+self.b
return out
def backward(self,dout):
dx=np.dot(dout,self.W.T)
self.dW=np.dot(self.x.T,dout)
self.db=np.sum(dout,axis=0)
dx=dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)
return dx
class SoftmaxWithLoss:
def __init__(self):
self.loss=None
self.y=None # softmax的输出
self.t=None # 监督数据
def forward(self,x,t):
self.t=t
self.y=softmax(x)
self.loss=cross_entropy_error(self.y,self.t)
return self.loss
def backward(self,dout=1):
batch_size=self.t.shape[0]
if self.t.size== self.y.size: # 监督数据是one-hot-vector的情况
dx=(self.y-self.t)/batch_size
else:
dx=self.y.copy()
dx[np.arange(batch_size),self.t]-=1
dx=dx/batch_size
return dx
class Dropout:
'''
随机删除神经元
self.mask:保存的是False和True的数组,False的值为0是删除的数据
'''
def __init__(self,dropout_ratio=0.5):
self.dropout_ratio=dropout_ratio
self.mask=None
def forward(self,x,train_flg=True):
if train_flg:
self.mask=np.random.rand(*x.shape)>self.dropout_ratio
return x*self.mask
else:
return x*(1.0-self.dropout_ratio)
def backward(self,dout):
return dout*self.mask
class BatchNormalization:
'''批标准化处理'''
def __init__(self,gamma,beta,momentum=0.9,running_mean=None,running_var=None):
self.gamma=gamma
self.beta=beta
self.momentum=momentum
self.input_shape=None # Conv层的情况下为4维,全连接层的情况下为2维
# 测试时使用的平均值和方差
self.running_mean=running_mean
self.running_var=running_var
# backward时使用的中间数据
self.batch_size=None
self.xc=None
self.std=None
self.dgamma=None
self.dbeta=None
def forward(self,x,train_flg=True):
self.input_shape=x.shape
if x.ndim != 2:
N,C,H,W=x.shape
x=x.reshape(N,-1)
out=self.__forward(x,train_flg)
return out.reshape(*self.input_shape)
def __forward(self,x,train_flg):
if self.running_mean is None:
N,D=x.shape
self.running_mean=np.zeros(D)
self.running_var=np.zeros(D)
if train_flg:
mu=x.mean(axis=0)
xc=x-mu
var=np.mean(xc**2,axis=0)
std=np.sqrt(var+10e-7)
xn=xc/std
self.batch_size=x.shape[0]
self.xc=xc
self.xn=xn
self.std=std
self.running_mean=self.momentum*self.running_mean+(1-self.momentum)*mu
self.running_var=self.momentum*self.running_var+(1-self.momentum)*var
else:
xc=x-self.running_mean
xn=xc/((np.sqrt(self.running_var+10e-7)))
out=self.gamma*xn+self.beta
return out
def backward(self,dout):
if dout.ndim != 2:
N,C,H,W=dout.shape
dout=dout.reshape(N,-1)
dx=self.__backward(dout)
dx=dx.reshape(*self.input_shape)
return dx
def __backward(self,dout):
dbeta=dout.sum(axis=0)
dgamma=np.sum(self.xn*dout,axis=0)
dxn=self.gamma*dout
dxc=dxn/self.std
dstd=-np.sum((dxn*self.xc)/(self.std*self.std),axis=0)
dvar=0.5*dstd/self.std
dxc += (2.0/self.batch_size)*self.xc*dvar
dmu=np.sum(dxc,axis=0)
dx=dxc-dmu/self.batch_size
self.dgamma=dgamma
self.dbeta=dbeta
return dx
class Convolution:
def __init__(self,W,b,stride=1,pad=0):
self.W=W
self.b=b
self.stride=stride
self.pad=pad
# 中间数据(backward时使用)
self.x=None
self.col=None
self.col_W=None
# 权重和偏置参数的梯度
self.dW=None
self.db=None
def forward(self,x):
FN,C,FH,FW=self.W.shape
N,C,H,W=x.shape
out_h=1+int((H+2*self.pad-FH)/self.stride)
out_w=1+int((W+2*self.pad-FW)/self.stride)
col=im2col(x,FH,FW,self.stride,self.pad)
col_W=self.W.reshape(FN,-1).T
out=np.dot(col,col_W)+self.b
out=out.reshape(N,out_h,out_w,-1).transpose(0,3,1,2)
self.x=x
self.col=col
self.col_W=col_W
return out
def backward(self,dout):
FN,C,FH,FW=self.W.shape
dout=dout.transpose(0,2,3,1).reshape(-1,FN)
self.db=np.sum(dout,axis=0)
self.dW=np.dot(self.col.T,dout)
self.dW=self.dW.transpose(1,0).reshape(FN,C,FH,FW)
dcol=np.dot(dout,self.col_W.T)
dx=col2im(dcol,self.x.shape,FH,FW,self.stride,self.pad)
return dx
class Pooling:
def __init__(self,pool_h,pool_w,stride=1,pad=0):
self.pool_h=pool_h
self.pool_w=pool_w
self.stride=stride
self.pad=pad
self.x=None
self.arg_max=None
def forward(self,x):
N,C,H,W=x.shape
out_h=int(1+(H-self.pool_h)/self.stride)
out_w=int(1+(W-self.pool_w)/self.stride)
col=im2col(x,self.pool_h,self.pool_w,self.stride,self.pad)
col=col.reshape(-1,self.pool_h*self.pool_w)
arg_max=np.argmax(col,axis=1)
out=np.max(col,axis=1)
out=out.reshape(N,out_h,out_w,C).transpose(0,3,1,2)
self.x=x
self.arg_max=arg_max
return out
def backward(self,dout):
dout=dout.transpose(0,2,3,1)
pool_size=self.pool_h*self.pool_w
dmax=np.zeros((dout.size,pool_size))
dmax[np.arange(self.arg_max.size),self.arg_max.flatten()]=dout.flatten()
dmax=dmax.reshape(dout.shape+(pool_size,))
dcol=dmax.reshape(dmax.shape[0]*dmax.shape[1]*dmax.shape[2],-1)
dx=col2im(dcol,self.x.shape,self.pool_h,self.pool_w,self.stride,self.pad)
return dxtrainer.py
import numpy as np
from common.optimizer import *
class Trainer:
'''把前面用来训练的代码做一个类'''
def __init__(self,network,x_train,t_train,x_test,t_test,epochs=20,mini_batch_size=100,optimizer='SGD',optimizer_param={'lr':0.01},evaluate_sample_num_per_epoch=None,verbose=True):
self.network=network
self.verbose=verbose#是否打印数据(调试或查看)
self.x_train=x_train
self.t_train=t_train
self.x_test=x_test
self.t_test=t_test
self.epochs=epochs
self.batch_size=mini_batch_size
self.evaluate_sample_num_per_epoch=evaluate_sample_num_per_epoch
optimizer_dict={'sgd':SGD,'momentum':Momentum,'nesterov':Nesterov,'adagrad':AdaGrad,'rmsprop':RMSprop,'adam':Adam}
self.optimizer=optimizer_dict[optimizer.lower()](**optimizer_param)
self.train_size=x_train.shape[0]
self.iter_per_epoch=max(self.train_size/mini_batch_size,1)
self.max_iter=int(epochs*self.iter_per_epoch)
self.current_iter=0
self.current_epoch=0
self.train_loss_list=[]
self.train_acc_list=[]
self.test_acc_list=[]
def train_step(self):
batch_mask=np.random.choice(self.train_size,self.batch_size)
x_batch=self.x_train[batch_mask]
t_batch=self.t_train[batch_mask]
grads=self.network.gradient(x_batch,t_batch)
self.optimizer.update(self.network.params,grads)
loss=self.network.loss(x_batch,t_batch)
self.train_loss_list.append(loss)
if self.verbose:print('训练损失值:'+str(loss))
if self.current_iter%self.iter_per_epoch==0:
self.current_epoch+=1
x_train_sample,t_train_sample=self.x_train,self.t_train
x_test_sample,t_test_sample=self.x_test,self.t_test
if not self.evaluate_sample_num_per_epoch is None:
t=self.evaluate_sample_num_per_epoch
x_train_sample,t_train_sample=self.x_test[:t],self.t_test[:t]
train_acc=self.network.accuracy(x_train_sample,t_train_sample)
test_acc=self.network.accuracy(x_test_sample,t_test_sample)
self.train_acc_list.append(train_acc)
self.test_acc_list.append(test_acc)
if self.verbose:print('epoch:'+str(self.current_epoch)+',train acc:'+str(train_acc)+' | test acc:'+str(test_acc))
self.current_iter+=1
def train(self):
for i in range(self.max_iter):
self.train_step()
test_acc=self.network.accuracy(self.x_test,self.t_test)
if self.verbose:print('最终测试的正确率:'+str(format(test_acc,'.2%')))util.py
import numpy as np
def smooth_curve(x):
'''使得图形变得更光滑'''
window_len=11
s=np.r_[x[window_len-1:0:-1],x,x[-1:-window_len:-1]]
w=np.kaiser(window_len,2)
y=np.convolve(w/w.sum(),s,mode='valid')
return y[5:len(y)-5]
def shuffle_dataset(x,t):
'''打乱数据集'''
permutation=np.random.permutation(x.shape[0])
x=x[permutation,:] if x.ndim == 2 else x[permutation,:,:,:]
t=t[permutation]
return x,t
def conv_output_size(input_size,filter_size,stride=1,pad=0):
return (input_size+2*pad-filter_size) / stride+1
def im2col(input_data,filter_h,filter_w,stride=1,pad=0):
'''
四维转二维
input_data : 由(数据量,通道,高,长)的4维数组构成的输入数据
filter_h : 滤波器的高
filter_w : 滤波器的长
stride : 步幅
pad : 填充
'''
N,C,H,W=input_data.shape
out_h=(H+2*pad-filter_h)//stride+1
out_w=(W+2*pad-filter_w)//stride+1
img=np.pad(input_data,[(0,0),(0,0),(pad,pad),(pad,pad)],'constant')
col=np.zeros((N,C,filter_h,filter_w,out_h,out_w))
for y in range(filter_h):
y_max=y+stride*out_h
for x in range(filter_w):
x_max=x+stride*out_w
col[:,:,y,x,:,:]=img[:,:,y:y_max:stride,x:x_max:stride]
col=col.transpose(0,4,5,1,2,3).reshape(N*out_h*out_w,-1)
return col
def col2im(col,input_shape,filter_h,filter_w,stride=1,pad=0):
'''
input_shape : 输入数据的形状(例:(10,1,28,28))
'''
N,C,H,W=input_shape
out_h=(H+2*pad-filter_h)//stride+1
out_w=(W+2*pad-filter_w)//stride+1
col=col.reshape(N,out_h,out_w,C,filter_h,filter_w).transpose(0,3,4,5,1,2)
img=np.zeros((N,C,H+2*pad+stride-1,W+2*pad+stride-1))
for y in range(filter_h):
y_max=y+stride*out_h
for x in range(filter_w):
x_max=x+stride*out_w
img[:,:,y:y_max:stride,x:x_max:stride] += col[:,:,y,x,:,:]
return img[:,:,pad:H+pad,pad:W+pad]optimizer.py
import numpy as np
class SGD:
'''随机梯度下降法,lr是学习率'''
def __init__(self,lr=0.01):
self.lr=lr
def update(self,params,grads):
for i in params.keys():
params[i]-=self.lr*grads[i]
class Momentum:
'''动量SGD,模拟小球在地面滚动'''
def __init__(self,lr=0.01,momentum=0.9):
self.lr=lr
self.momentum=momentum
self.v=None
def update(self,params,grads):
if self.v is None:
self.v={}
for k,v in params.items():
self.v[k]=np.zeros_like(v)
for k in params.keys():
self.v[k]=self.momentum*self.v[k]-self.lr*grads[k]
params[k]+=self.v[k]
class AdaGrad:
'''调节学习率的SGD'''
def __init__(self,lr=0.01):
self.lr=lr
self.h=None
def update(self,params,grads):
if self.h is None:
self.h={}
for k,v in params.items():
self.h[k]=np.zeros_like(v)
for k in params.keys():
self.h[k]=self.h[k]+grads[k]*grads[k]
params[k]-=self.lr*grads[k]/(np.sqrt(self.h[k])+1e-7)#加一个微小值防止为0
class Adam:
'''融合Momentum和AdaGrad'''
def __init__(self,lr=0.01,beta1=0.9,beta2=0.999):
self.lr=lr
self.beta1=beta1
self.beta2=beta2
self.iter=0
self.m=None
self.v=None
def update(self,params,grads):
if self.m is None:
self.m,self.v={},{}
for k,v in params.items():
self.m[k]=np.zeros_like(v)
self.v[k]=np.zeros_like(v)
self.iter+=1
lr_t=self.lr*np.sqrt(1.0-self.beta2**self.iter)/(1.0-self.beta1**self.iter)
for k in params.keys():
self.m[k]=self.beta1*self.m[k]+(1-self.beta1)*grads[k]
self.v[k]=self.beta2*self.v[k]+(1-self.beta2)*(grads[k]**2)
params[k]-=lr_t*self.m[k]/(np.sqrt(self.v[k])+1e-7)
class Nesterov:
def __init__(self,lr=0.01,momentum=0.9):
self.lr=lr
self.momentum=momentum
self.v=None
def update(self,params,grads):
if self.v is None:
self.v={}
for k,v in params.items():
self.v[k]=np.zeros_like(v)
for k in params.keys():
self.v[k]=self.v[k]*self.momentum
self.v[k]-=self.lr*grads[k]
params[k]+=self.momentum*self.momentum*self.v[k]
params[k]-=(1+self.momentum)*self.lr*grads[k]
class RMSprop:
def __init__(self,lr=0.01,decay_rate=0.99):
self.lr=lr
self.decay_rate=decay_rate
self.h=None
def update(self,params,grads):
if self.h is None:
self.h={}
for k,v in params.items():
self.h[k]=np.zeros_like(v)
for k in params.keys():
self.h[k]=self.h[k]*self.decay_rate
self.h[k]+=(1-self.decay_rate)*grads[k]*grads[k]
params[k]-=self.lr*grads[k]/(np.sqrt(self.h[k])+1e-7)?最后来测试下这个CNN的最终效果如何:
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from simple_convnet import SimpleConvNet
from common.trainer import Trainer
#加载MNIST数据集,保持输入数据的形状,不做一维处理
(x_train,t_train),(x_test,t_test)=load_mnist(flatten=False)
#减少数据训练测试,节省时间
#x_train,t_train=x_train[:5000],t_train[:5000]
#x_test,t_test=x_test[:1000],t_test[:1000]
max_epochs=20
network=SimpleConvNet(input_dim=(1,28,28),conv_param={'filter_num': 30,'filter_size': 5,'pad': 0,'stride': 1},hidden_size=100,output_size=10,weight_init_std=0.01)
trainer=Trainer(network,x_train,t_train,x_test,t_test,epochs=max_epochs,mini_batch_size=100,optimizer='Adam',optimizer_param={'lr': 0.001},evaluate_sample_num_per_epoch=1000)
trainer.train()
#保存参数
network.save_params("params.pkl")
print("保存参数成功")
#绘制图形
markers={'train': 'o','test': 's'}
x=np.arange(max_epochs)
plt.plot(x,trainer.train_acc_list,marker='o',label='train',markevery=2)
plt.plot(x,trainer.test_acc_list,marker='s',label='test',markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0,1.0)
plt.legend(loc='lower right')
plt.show()
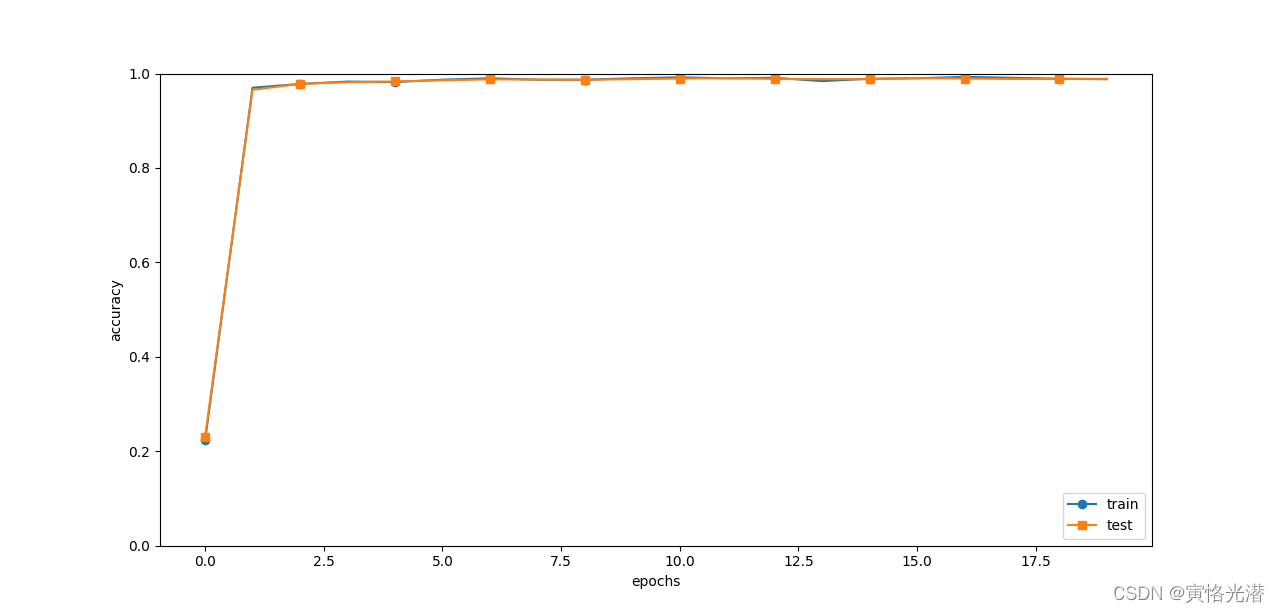
测试的正确率达到了99%左右,这在一个小型的卷积神经网络里面,已经是很不错的识别率了!?