首先抓取好评或者差评的数据集
# load dataset
TEXT = data.Field(tokenize='spacy')
LABEL=data.LabelField(dtype=torch.float)
'''
IMDB来自torch test,用来提取文件中相关的文件和数据,比如test和label
test是一个list,包含评论本身的内容,相当于x,此时x是str类型,必须embedding一下,才可以用
label是一个pos的值,相当于y
'''
train_data,test_data=datasets.IMDB.splits(TEXT,LABEL)
print('len of train data:',len(train_data))
print('len of test data:',len(test_data))
# 输出
# len of train data:25000
# len of test data:25000
print(train_data.examples[15].text)
print(train_data.examples[15].label)网络结构
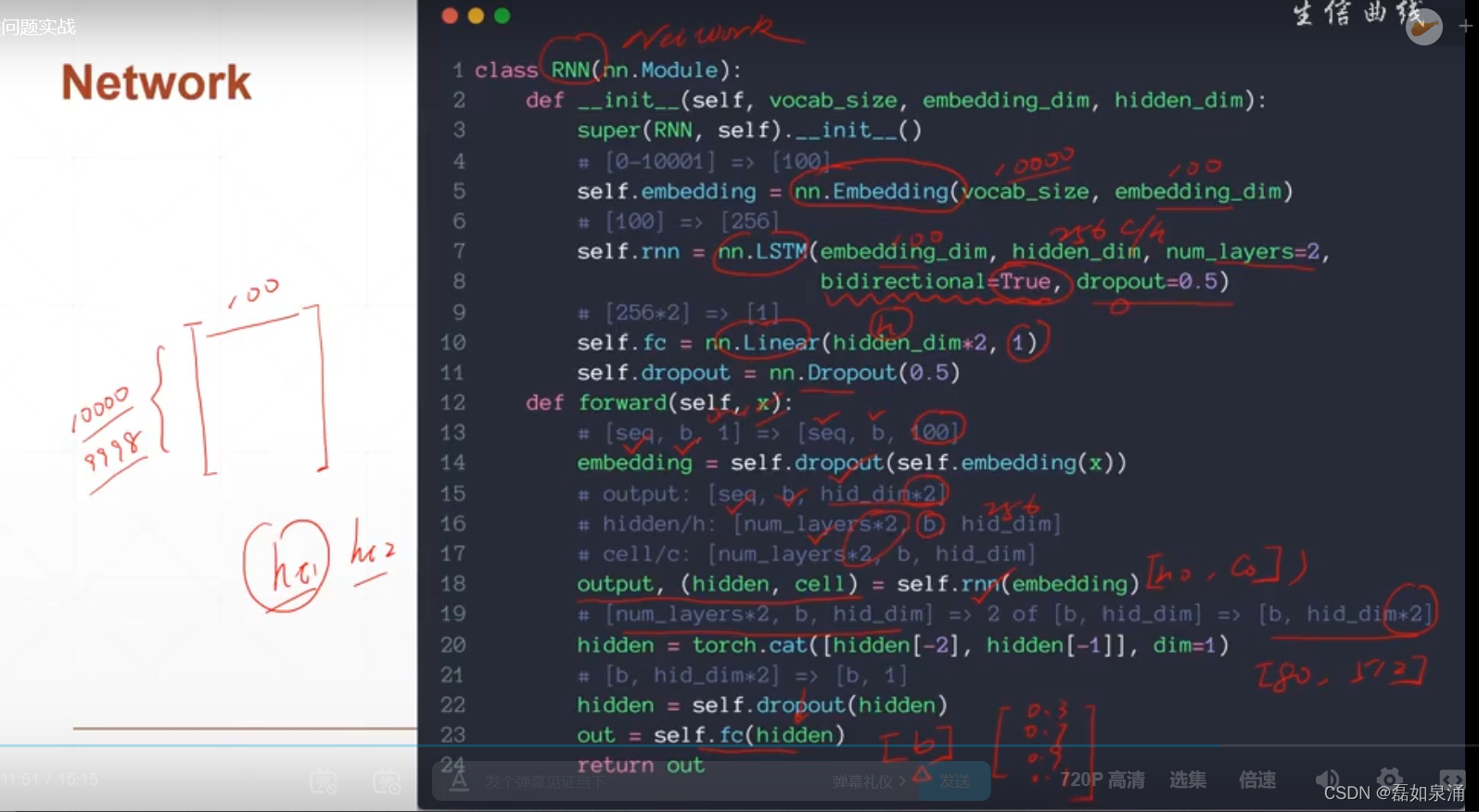
?embedding初始化的例子
embedding层会生成一个表,如下
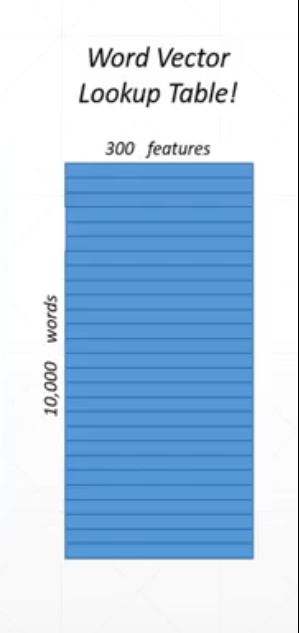
初始化的程序如下
# embedding 初始化的例子
rnn = RNN(len(TEXT.vocab),100,256)
pretrained_embedding = TEXT.vocab.vectors # 首先要得到权值,是根据glove编码方式下载得到的
print('pretrained_embedding:',pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding) # 用这个权值的weight覆盖掉(copy)embedding的weight
print('embedding layer inited.')train的程序
def train(rnn,iterator,optimizer,criteon):
avg_acc=[]
rnn.train()
for i,batch in enumerate(iterator): # 次数
# [seq,b]=>[b,1]=>[b]
pred=rnn(batch.text).squeeze(1) # text信息送到rnn里面 得到一个预测值【b】
loss = criteon(pred,batch.label) # 也是【b】和上面的pred做一个binary loss
acc=binary_acc(pred,batch,label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward() # 不停的更新,然后pred越来越接近与真实的label
optimizer.step()test的程序
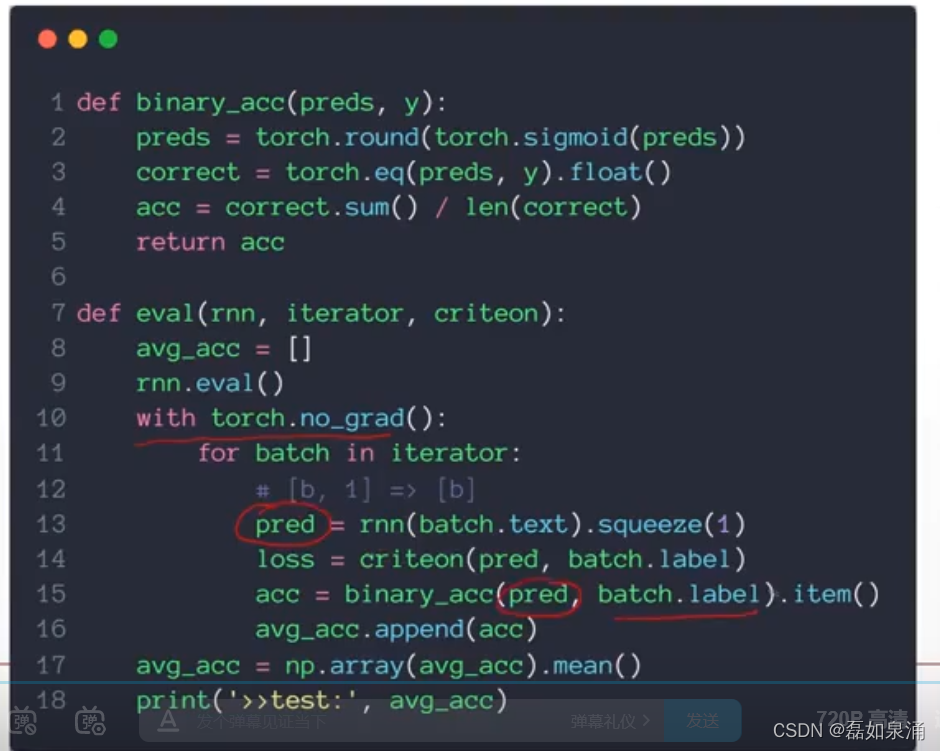
?