����Ŀ¼
�ο�ת����:
https://www.jianshu.com/p/cede3ae146bb
�ʵı�ʾ
DZ�������������(BOW)
DZ�������������ʹ��BOW(Bog of Words)�ĸ���:ÿ���ʶ����Ա������������ʾ,ÿ���ʶ���һ��ϡ��ı�ʾ;
����������ά�Ⱦ��Ǵʻ���Ĵ�С��
���ij���ʳ�����,��ô���Ǿͻ�������м�����
Countervector ����
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
data_corpus = ['guru99 is the best size for online tutorials. I love to visit guru99 .']
vocabulary = vectorizer.fit(data_corpus)
X = vectorizer.transform(data_corpus)
print(X.toarray())
[[1 1 2 1 1 1 1 1 1 1 1]]
print(vocabulary.get_feature_names())
['best', 'for', 'guru99', 'is', 'love', 'online', 'size', 'the', 'to', 'tutorials', 'visit']
��DZ�����������,ÿһ��(������)��ʾ����ij����,ÿ���б�ʾ���Ǵʳ�������ij���ı��еĴ�����
�����ܶ�ѧ�߷��� Countervector ��������ɴ��ڲ�ͬ�ı��ʿ��еij������, ����˵���ijЩ���ڲ�ͬ���ı��ж���������,��ôӦ�ý��ʹ���ʻ����Ҫ�Ի���á����Ծͳ�����TFIDF������
TF-IDF
�������ĵ���������Ĵ���Ӧ������Щ���ĵ��г���Ƶ�ʸ�,���������ĵ����ϵ������ĵ��г���Ƶ���ٵĴ���,������������ռ�����ϵȡ tf ��Ƶ ��Ϊ���,�Ϳ�������ͬ���ı����ص㡣
���⿼�ǵ���������ͬ��������,tf-idf����Ϊһ�����ʳ��ֵ��ı�Ƶ��ԽС,������ͬ����ı���������Խ��������������ı�Ƶ��idf�ĸ��
TFIDF��,�ִʵ���Ҫ�����������ļ��г��ֵĴ�������������,��ͬʱ�������������Ͽ��г��ֵ�Ƶ�ʳɷ����½�.
TF-IDF �IJ���:
��tf��idf�ij˻���Ϊ�����ռ�����ϵ��ȡֵ���,��������ɶ�Ȩֵtf�ĵ���,����Ȩֵ��Ŀ������ͻ����Ҫ����,���ƴ�Ҫ������
�����ڱ�����idf��һ����ͼ���������ļ�Ȩ,���ҵ�������Ϊ�ı�Ƶ��С�ĵ��ʾ�Խ��Ҫ,�ı�Ƶ�ʴ�ĵ��ʾ�Խ����,��Ȼ�Ⲣ������ȫ��ȷ�ġ�
idf �ļṹ��������Ч�ط�ӳ���ʵ���Ҫ�̶� �� �����ʵ��ֲ����,ʹ�����ܺõ���ɶ�Ȩֵ�����Ĺ���,����tf-idf�������������Ǻܸߡ�
BOW �� TF-IDF ����������
������Countervector���� TF-IDF,���Ƿ������Ƕ��Ǵ�ȫ�ִʻ�ķֲ������ı����б�ʾ,����ȱ��Ҳ����:
�������˵����ı������дʵ�˳��,���� ��this is bad�� ��BOW�еı�ʾ�� 'bad is this����һ����;
�������˴ʵ�������,��������дһ������,��He loved books. Education is best found in books��.
���ǻ��ڴ��������仰��ʱ���Dz��ῼ��ǰһ�����ӻ��ߺ�һ��������ʲô��˼,��������֮���Ǵ���ijЩ��ϵ��
�ʵĶ���(One-hot )��ʾ
��ĿǰΪֹ��õĴʱ�ʾ������ One-hot Representation,���ַ�����ÿ���ʱ�ʾΪһ���ܳ������������������ά���Ǵʱ���С,���о������Ԫ��Ϊ 0,ֻ��һ��ά�ȵ�ֵΪ 1,��������ʹ����˵�ǰ�Ĵʡ�
���ɰ�����ʾΪ [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ��]
���������ʾΪ [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ��]
ÿ���ʶ���ãã 0 ���е�һ�� 1��
���� One-hot Representation �������ϡ�跽ʽ�洢,���Ƿdz��ļ��:Ҳ���Ǹ�ÿ���ʷ���һ������ ID��
����ղŵ�������,�ɰ���Ϊ 3,�����Ϊ 8(����� 0 ��ʼ��)��
ȱ�����:
1��������ά�� �����ž��ӵĴʵ��������� ���������;
2������������֮�䶼�ǹ�����,����ʾ��������ϴʻ�֮��������Ϣ,����һ���������ġ�
��������ĸĽ�
���ά�ȹ��������
���ȱ������ά�ȹ����ȱ�㡣�Դ˽������¸Ľ�:
1����vectorÿһ��Ԫ�������θ�Ϊ������,��Ϊ����ʵ����Χ�ı�ʾ;
2����ԭ��ϡ��ľ�ά��ѹ��Ƕ�뵽һ�� ��Сά�ȵĿռ䡣��ͼ��ʾ:

����Ƕ�롱Ҳ�ɴ˵�����
����:��������ѵ��������ʱ������ز��������˵����
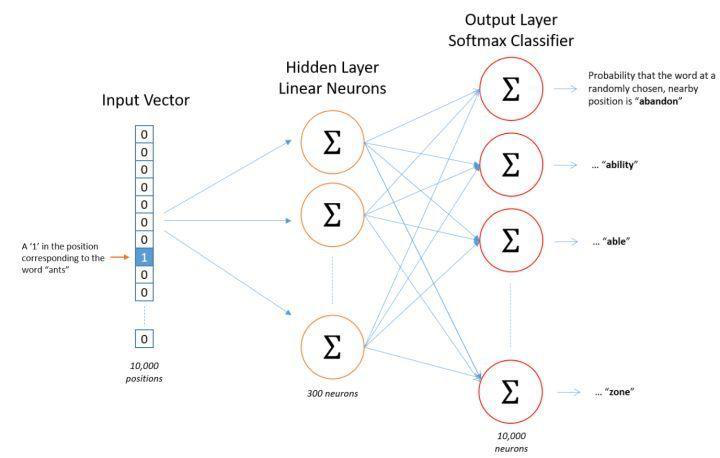
�������������� �C �ʵķֲ�ʽ��ʾ
��ͳ�Ķ��ȱ�ʾ�����������Ż�,�������κ�������Ϣ����ν��������뵽�ʱ�ʾ��?
Harris �� 1954 ������� �ֲ���˵ Ϊ��һ�����ṩ�����ۻ���:���������ƵĴ�,������Ҳ���ơ�
Firth �� 1957��Էֲ���˵�����˽�һ����������ȷ:�ʵ��������������ľ�����
��(CBOW)Ϊ��,�����һ�����ӡ�the cat sits one the mat��,��ѵ����ʱ��,����the cat sits one the����Ϊ����,Ԥ������һ�����ǡ�mat����
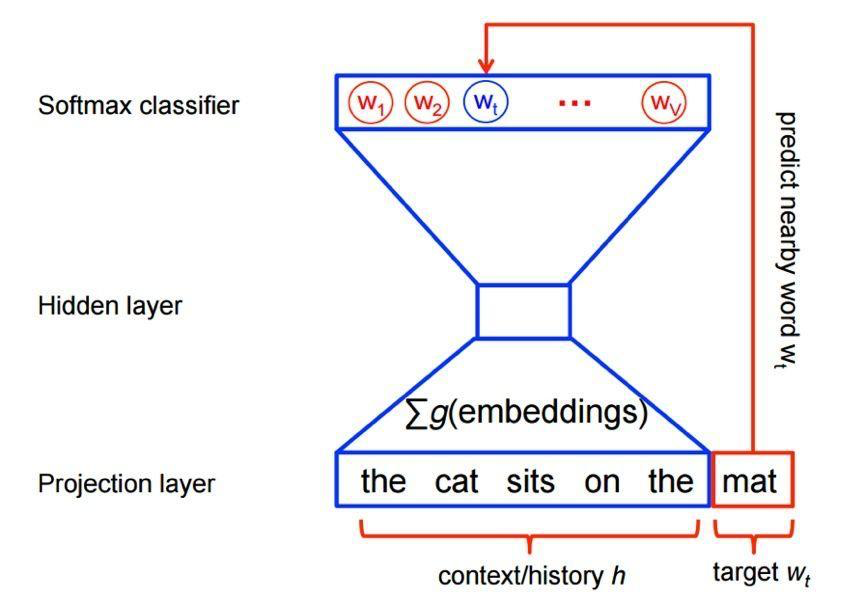
�ֲ�ʽ��ʾ������ŵ����������зdz�ǿ�����������,����nά����ÿάk��ֵ,���Ա���k��n�η������
��ͼ������������ģ��(NNLM)���õľ����ı��ֲ�ʽ��ʾ��
��������(word embedding)��ѵ��������ģ�͵�һ�����Ӳ���,��ͼ�е�Matrix C��
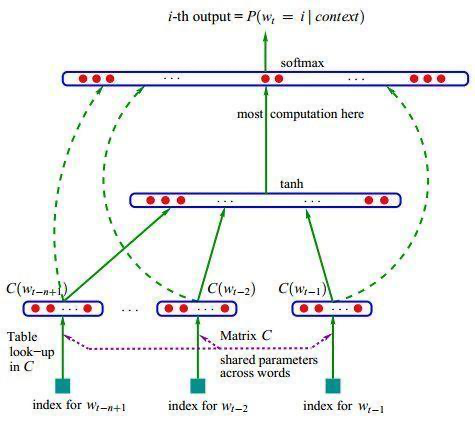
�������ǿ��Խ����ǵ��������������:
һ��ѡ��һ�ַ�ʽ����������;
����ѡ��һ�֡�ģ�͡��̻�ij����(����Ŀ��ʡ�)����������֮��Ĺ�ϵ��
Word Embedding ��Ƕ��
������������ֲ���ʾһ���Ϊ ����������Ƕ��( word embedding)��ֲ�ʽ��ʾ( distributed representation)��
������Ȼ�������ĵı�ʾ �Լ� ��������Ŀ���֮��Ĺ�ϵ �Ľ�ģ��
��Ƕ��(Word Embedding) ͨ���ܶ����ѧϰģ�� �� ԭ�Ȳ�ͬ�Ĵ�ת��Ϊ ��ͬ��ʵ��������
Ŀǰ��Word Embedding �ļ����dz���,����Google �� Word2Vec, Stanford �� Glove, Facebook�� Fastext �ȵȡ�
Word Embedding�е�ʱ��Ҳ������Ϊ�ֲ�ʽ����ģ�� �� �����ռ�ģ�� �ȡ�
���Դ����ֺ���ת���ķ�ʽ���ǿ�������, Word Embedding �������Խ� ��ͬ���͵Ĵ� �鵽һ��;
����ƻ��,â���㽶����ͶӰ֮��������ռ����ͻ����;���鱾,������Щ�����ƻ����Щ�ʵľ�����Խ�Զ��
ʹ�ó���
ĿǰΪֹ,Word Embedding �����õ���������,�ļ�����,�ı��������Ȼ���Դ���������,����:
- �������ƵĴ�:Word Embedding���Ա�����Ѱ����ij��������Ĵʡ�
- ����һȺ��صĴ�:�Բ�ͬ�Ĵʽ��о���,����صĴʾۼ���һ��;
- �����ı����������:���ı�����������,��Ϊ��û��ֱ�����ڻ���ѧϰģ�͵�ѵ��,�������ǽ�����ͶӰ�������ռ�,����֮�����Ի�����Щ�������л���ѧϰģ�͵�ѵ��;
- �����ļ��ľ���
�����оٵ����ı��������,��ȻĿǰ��Ƕ��ģ���Ѿ�����չ���������档���͵�,����:
- ��������,ÿ���˶���һ��������ʾ,��ÿ���˹���Embedding,Ȼ�������֮��������,�õ���ϵ��Ϊ�������;
- ���Ƽ���������,����ÿ���û��Ĺ������Ʒ��¼,��ÿ����Ʒ����Embedding,�Ϳ��Լ�����Ʒ֮��������,�������Ƽ�;
- �ڴ˴���صĺ���������,����ͬ��γ���ϲ�ͬ�Ĵ�����Embedding,�Ϳ��Եõ�ÿ����ֻ������,�Ϳ��Եõ�������ijЩ�������Ĵ�ֻ;
����˵,��Ƕ��ΪѰ������֮������������˾�İ�����
���ڻ���ÿ�����ݾ����������Embedding����������������Ҫ��ע�õ�����Word2Vecģ�͡�
Word embedding��ѵ������
���¿��Է�Ϊ����:
1���ල�����ල��Ԥѵ��
�ŵ�:����Ҫ�������˹���������Ϳ��Եõ�������������embedding����
ȱ��:ȷ���д����
����취:�õ�Ԥѵ����embedding������,�������˹���ע��������ȥ�Ż�����ģ��
���ʹ���:word2vec��auto-encoder
(�������һ��AutoEncoder,AutoEncoderҲ��������ѵ��������,�Ƚ�one hotӳ���һ��hidden state,��ӳ���ԭ����ά��,������������,ȡ�м��hidden vector��Ϊ������,�ڲ����ԭ����������ǰ����ѹ������ά��,�õ�һ��ѹ��������������ʽ��)
2���˶Զ�(end to end)���мලѵ����
�ŵ�:ѧϰ����embedding����Ҳ��������ȷ
ȱ��:ģ���ڽṹ���������Ӹ���
Ӧ��:ͨ��һ��embedding������ɸ����������Ӷ��ɵ������������ʵ�ֶԾ��ӵ���з���,����ѧϰ��������ḻ�Ĵ��������
word2vec�����ĺ�����Ӧ�ó���,��ѧϰ�����Ǿ��Ǹ��ݹ�����Ϣ�õ��ĵ��ʵı���,��n-gram��Ϣ���ල,�ڲ�ͬ����task�䶼����һ��Ч������end2endѵ����embedding��;�����task��ѧϰĿ��������,ֱ��Ǩ�Ƶ���һ����task�������dz�����
���õ�word embedding��Ϊdense��sparse������ʽ:
������sparse�ͱ��� co-occurence ����one-hot����ʽ;��sparse embedding����һЩ��ά�������SVD��PCA�Ϳ��Եõ�dense��