#########update to Lec 10###########################
Ŀ¼
#########update to Lec 10###########################
Belief Networks (Bayesian Networks)
MLE maximum Likelihood Estimation ������Ȼ����
Maximum a posteriori (MAP) Estimation
Fisher's Linear Discriminant Analysis
LDA:Linear Discriminant Functions
Linear Discriminant Functions(�����б�)
Non-separable Example && Convergence of Perceptron Rules
Minimum Squared-Error Procedures
Ensemble Classifiers (���ɷ�����)
Unsupervised Learning(Clustering)
EE4408: Machine Learning:
Lecture1
Types of machine learning
Supervised Learning:
-
example:Regression,*Classification
-
difference: need labels,��Ҫ��ǩ��ѧϰ
Unsupervised Learning:
-
example:Clustering
-
difference:not need labels,����Ҫ��ǩ����ѧϰ
Reinforcement Learning:ǿ��ѧϰ
-
��ɲ���:����,�û�
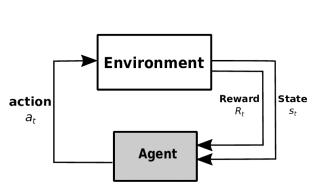
�û�����environment������state����action,������Environment,����reward,����Agent,����action��������,ʹ����һ�ε�action����á�
Probability Review
Discrete Random Variable:
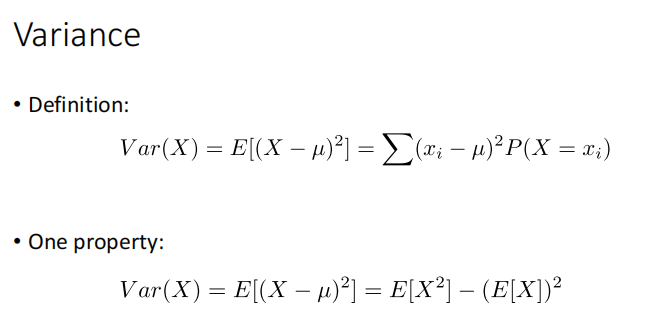

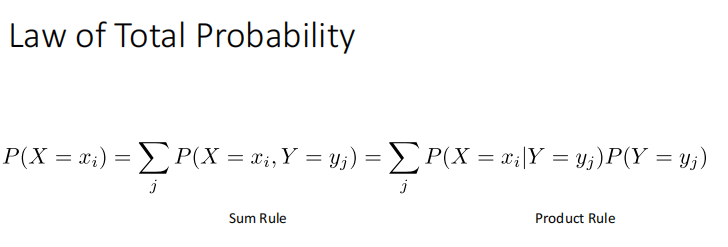
Bayes Rule:
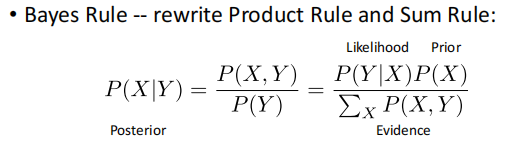
Continuous Random Variable:
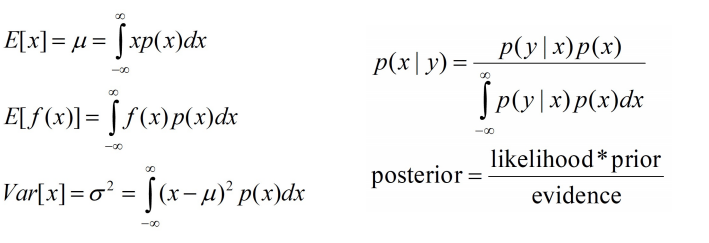
Lecture 2
Graphical Model:
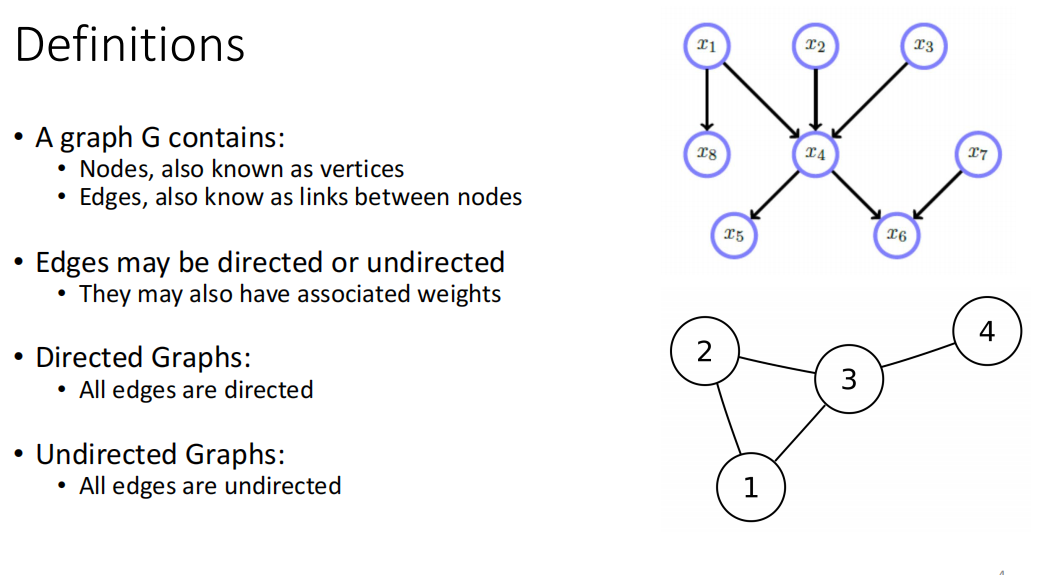

DAG:����ͼ,û��cycle(û��һ��·�����·���һ���ڵ�)
Belief Networks (Bayesian Networks)
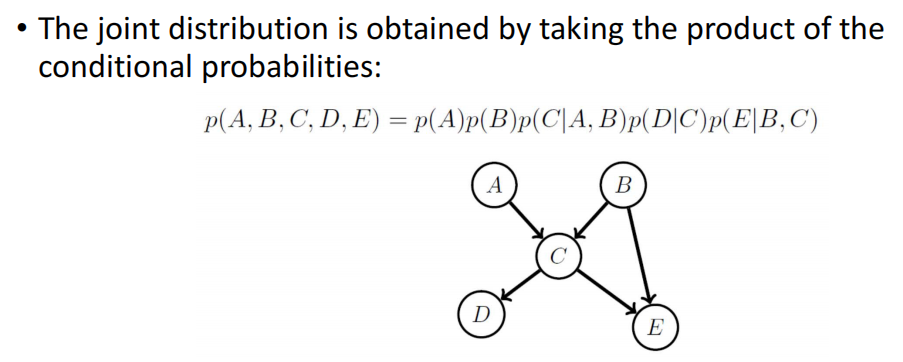
���ø���ͼ��ϵ.��joint probablities
Intro to Linear Algebra:
-
Vectors:����
-
scalars:����
-
Subspace:�ӿռ�
-
Basis of Vector Space:������,��ͼƬ��,������Ϊ:

-
Orthogonal matrices��������,����
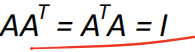
-
Trace:����Խ���֮��
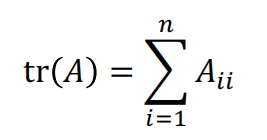
-
Determinant:����ʽ
-
Covariance:����,
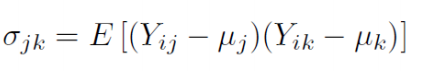
-
Correlation coefficient:���ϵ��:
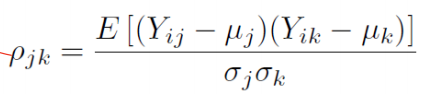
-
Covariance matrix:
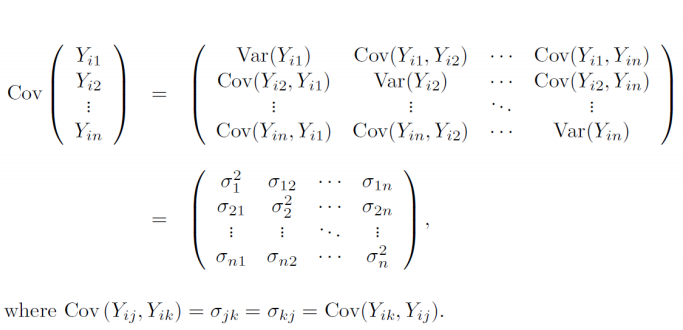
����:COV(X,Y)=E[(X-E(X))(Y-E(Y))]
-
Normal Density:��̬�ֲ�
Eigenvalue and Eigenvector
��
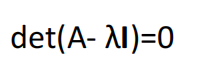
�������
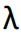
ΪEigenvalue(����ֵ),
��lambda ����
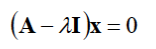
�����xΪeigenvector(��������)
Lecture 3
Bayesian Decision Theory
prior:������� posterior:�������
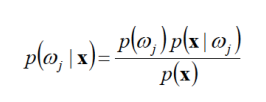

Decision using Posteriors:
-
�жϹ���:

��������ĸ���,�жϳ��ĸ�
-
Error:

Error:����x����,���������ȷ����,����error���Ǹ���С���Ǹ�
-
Loss Function

Conditional Risk:
������ʾ��ߵ�������,�ڽ��о���ǰ,����һ������
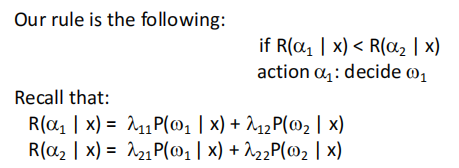

R()�����൱�ڽ� ÿһ��Ĵ��������
MLE maximum Likelihood Estimation ������Ȼ����
question
��:a ��Ϊ����ÿһ����Ȼ����,����һ��ȷ���IJ���,�����˹�ֲ��еľ�ֵ�ͷ���,���Է����е�w��,���������б�������״��ͳһ��.

main idea
-
�������Ȼ�����������ֵ��Ϊ����ֵ,����������֪���������,�������п���(������)������������IJ���ֵ(ģ����֪,����δ֪)��
-
����д����Ȼ����:

-

-
��������:
-
д����Ȼ����:
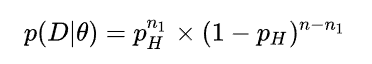
-
ȡ����log

-
����:

-
Lecture 4
MLE Classifier Example
-
����train_data ���������Ȼ����(example�й��Ƶ���var��mean)
-
���ú������ = likehood * ������� �����ж�.
-
���ò��Լ��ı�ǩ������error
Cross Validation (������֤)
��������:
-
ѵ����(train set) ���� ����ģ����ϵ�����������
-
��֤��(validation set)���� ��ģ��ѵ�������е���������������,���������ڵ���ģ�͵ij����������ڶ�ģ�͵��������г��������� ͨ��������ģ�͵���ѵ��ʱ,������֤��ǰģ�ͷ�������(ȷ��,�ٻ��ʵ�),�Ծ����Ƿ�ֹͣ����ѵ����
-
���Լ� ���� ��������ģ����ģ�͵ķ�����������������Ϊ���Ρ�ѡ���������㷨��ص�ѡ������ݡ�
һ������ı���:
ѵ����-----------ѧ���Ŀα�;ѧ�� ���ݿα��������������֪ʶ�� ? ��֤��------------��ҵ,ͨ����ҵ����֪�� ��ͬѧ��ѧϰ������������ٶȿ����� ? ���Լ�-----------����,��������ƽ����û�м���,����ѧ����һ������������
K-fold cross validation
-
�����ѵ�����ݵȷֳ�k��,S1, S2, ��, Sk��
-
����ÿһ��ģ��Mi,�㷨ִ��k��,ÿ��ѡ��һ��Sj��Ϊ��֤��,��������Ϊѵ������ѵ��ģ��Mi,��ѵ���õ���ģ����Sj�Ͻ��в���,����һ��,ÿ�ζ���õ�һ�����E,����k�εõ��������ƽ��,�Ϳ��Եõ�ģ��Mi�ķ�����
-
�㷨ѡ�������С��������ģ����Ϊ����ģ��,����������ѵ�������ٴ�ѵ����ģ��,�Ӷ��õ����յ�ģ�͡�
overfitting �����
ģ�Ͷ���ѵ������˵̫��ȷ��,ʧȥ������
Maximum a posteriori (MAP) Estimation
��������,���Ⱥ������ = ������� * likehood
-
��MLE��,����˼�������likehood,�Dz���Ҫ����֪ʶ��,ֻ��Ҫ����۲�����.ȱ��:�ڸ�����������������,��Ȼ���ƵIJ�����һ����
-
������MAP��,�����������,��ʵ���ۺ��˸���������������֪ʶ
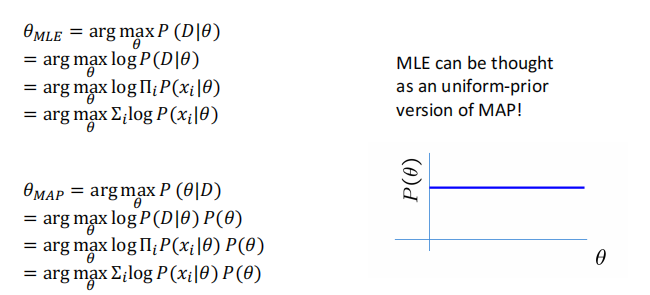
���ܻῼ��������֪ʶ prior =1(��������֪ʶ),��MLE��MAP�ȼ�
Non-parametric Classification
�ŵ�:������������ֲ�,�Ҳ���Ҫ֪�������ܶȺ�������ʽ
Density Estimation
��ʵ������������ֱ��ͼ
Dimensionality Reduction(��ά)
Lecture 5
Data Scaling
�����ݽ���Ԥ����,��һ��,��ֹ����features��ֵ����,�����ں�������
Dimensionality Reduction
Greedy Forward Feature Selection:�ӿյ�features�����в��ϼ���õ�����
Greedy Backward Feature Selection:�����е�features�����в���ɾ���������
PCA
һ�����ݽ�ά�ķ���,
question
maxmize the variance from the new data
minimize reconstruction error
main idea
��������ֵ�ֽ�Э�������ʵ��PCA�㷨
-
������������
-
���������ֽⷽ����Э������������ֵ����������
-
ȡ������ֵ����k��������������µĿռ�
����SVD�ֽ�Э�������ʵ��PCA�㷨
-
ȥƽ��ֵ,��ÿһλ������ȥ���Ե�ƽ��ֵ��
-
�����������
-
ͨ��SVD����Э������������ֵ������������
-
������ֵ�Ӵ�С����,ѡ����������k����Ȼ�����Ӧ��k�����������ֱ���Ϊ���������������������
-
������ת����k�����������������¿ռ��С�
Eigenfaces
-
��PCA �ֽ�� ��ͼ��(Eigenfaces)
-
��ͼ���û�ͼ���ʾ:

-
���������ľ��������ʾ�Ƿ���һ����:

Lecture 6
Fisher's Linear Discriminant Analysis
�ѷ��༯��ͶӰ��һ�����Ͻ��з���
question:
explain why maximizing the distance between the projected class means is not sufficient for separating?
���ܼ���һ��ά�ȵľ�ֵȥ����
maybe have many overlapping parts,such like:
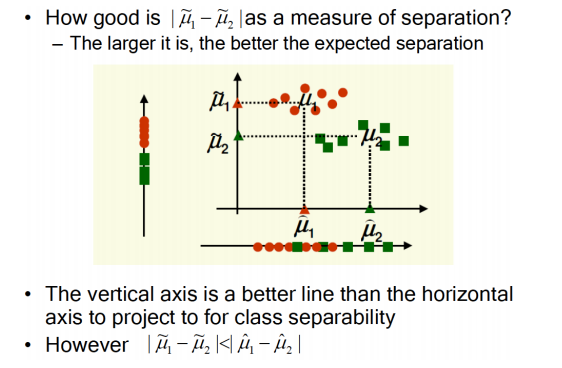
main idea
-
maximum objective function:
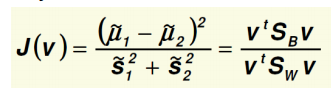
-
details:

-
use v to separate different classes
LDA:Linear Discriminant Functions
��Fisher ��ͬ,Fisher ��ͶӰ��һ�����Ͻ��з���,LDA�Ǹ������ߵ���һ�߽��з���.

���ܻῼ!
LDF ���� �������ľ�����������������
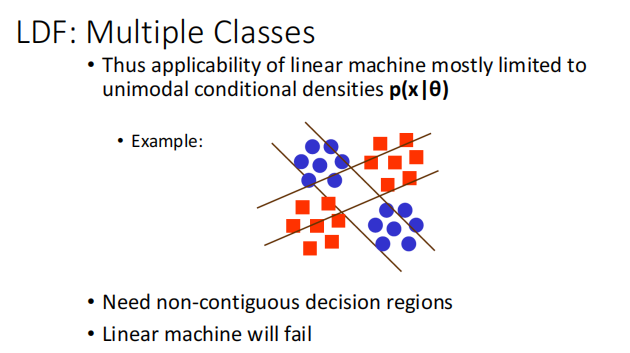
Lecture 7
Linear Regression
����:
-
Assume a linear model: Y = ��0 + ��1 X
-
Find the line which ��best�� fits the data, i.e. estimate parameters ��0 and ��1(ѵ��:����С���������)
-
Check assumptions of model(��֤)
-
Draw inferences and make predictions(����)
Five Assumptions of Linear Regression
-
Existence: for each fixed value of X, Y is a random variable with finite mean and variance (����ÿһ��������X,Y��������ĵ�����һ�����ľ�ֵ�ͷ���)
-
Independence: the set of Yi are independent random variables given Xi(���ڸ���Xi,Yi�Ƕ������������,��Xû�й�ϵ)
-
Linearity: the mean value of Y is a linear function of X(Y�ľ�ֵ����x��һ�����Եĺ���)
-
Homoscedasticity: the variance of Y is the same for any X(��������X,Y��ͬ�����)
-
Normality: For each fixed value of X, Y has a normal distribution (by assumption 4, ��2 does not depend on X)(��������X,Y��һ����̬�ֲ�)
Estimating ��0 and ��1
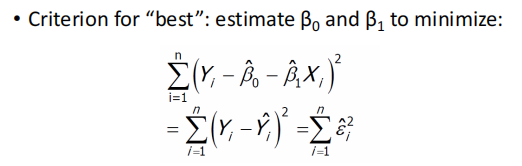
ʵ���Ͼ������ Ԥ��ֵ�ͱ�ǩֵ�IJ� ��ƽ���� ��С��(MSE��С������----Lec8)
Logistic Regression
Aim: to learn Learn P(Y|X) directly by using the way like Linear Regression
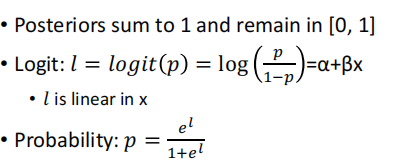
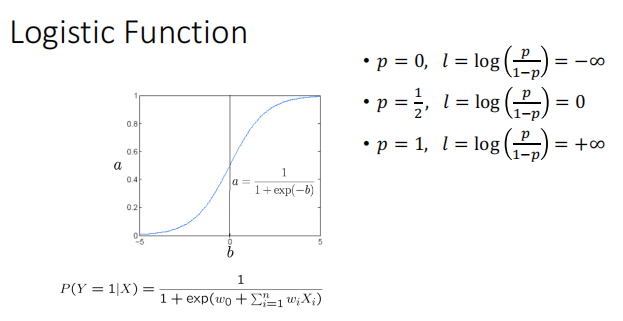
ʵ��:���� l = a+bx �����Իع�,Ȼ�� l ���� logistic function��ʾ����p
��ʧ����:
���ü�����Ȼ������,������ع��еIJ���(a,b)
���ع�ģ�͵���ѧ��ʽȷ����,ʣ�¾������ȥ���ģ���еIJ�������ͳ��ѧ��,����ʹ�ü�����Ȼ���Ʒ������,���ҵ�һ�����,ʹ�������������,���ǵ����ݵ���Ȼ��(����)���
��:
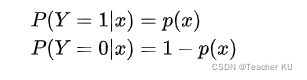
��Ȼ����:
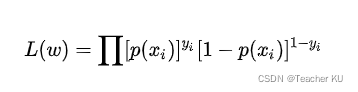
Ϊ�˸��������,���ǶԵ�ʽ����ͬȡ����,д�ɶ�����Ȼ����:
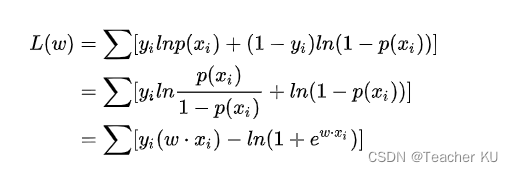 ?
?
�ڻ���ѧϰ����������ʧ�����ĸ���,���������ģ��Ԥ�����ij̶ȡ����ȡ�������ݼ��ϵ�ƽ��������Ȼ��ʧ,���ǿ��Եõ�:
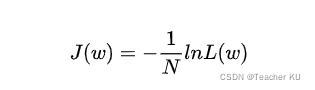
�������ع�ģ����,���������Ȼ��������С����ʧ����ʵ�����ǵȼ۵ġ�
���ع����ʧ������:(���㷽�������ú��潲�����ݶ��½�)
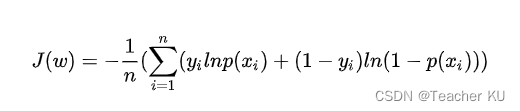 ?
?
Linear Discriminant Functions(�����б�)
Augmented Feature Vector:
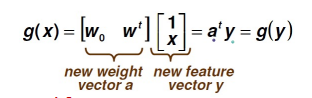
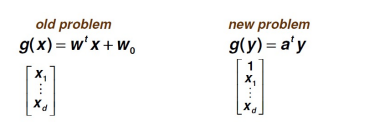
�൱�ڶ�������һά������
�б���ʽ:
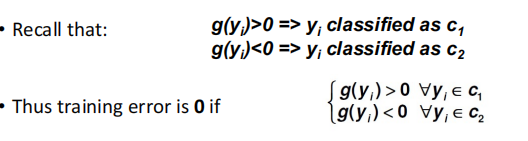
Normalization:

���ڶ����������ԭ����ķ���,��������Ϊ��,����,ֻҪ����
���Ƿ�����ȷ��.

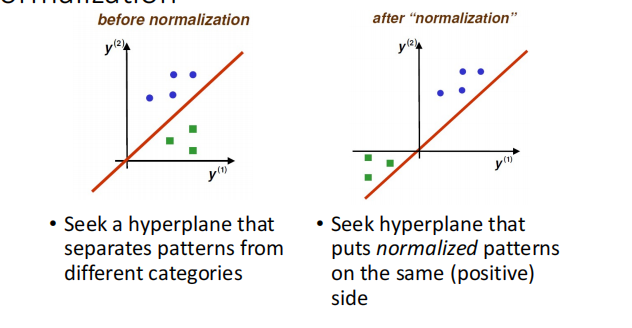
Solution Region

������ⷽ��
Optimization:
��Ŀ�꺯��������,�㵼������0��ʱ��,ȱ��:�ⷽ�̸���,�Ҷ������ڵ�һЩ����(���ѧϰ),��̫����д�����̡�
Gradient Descent(�ݶ��½�)
����weight vector����:����ǰһ�ε��������Ŀ�꺯���ĵ���,��Ŀǰ��weight vector���������
����:�ݶȿ��Ա�ʾΪĿ�꺯���½��ķ���,����ֻ��Ҫ���Ͽ���weight vector���������ǰ��,����ͼ��
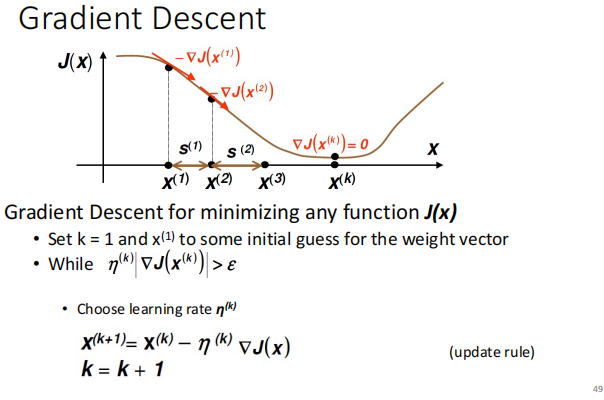
�ŵ�:�����õķdz��㷺,�����ʺ������Ŀ�꺯��
LDF Criterion Function
��û�п���
Perceptron(��֪��)
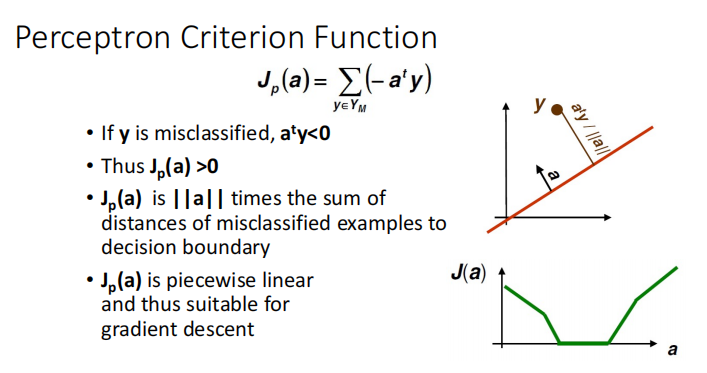
��֪����Ŀ�꺯��Ϊ���зִ������ľ����,Ŀ�ľ�����С�����Ŀ�꺯����
�����ݶȸ��·���:

��ΪĿ�꺯������y��֮��ֻʣ��y��,�����ݶ���aû�й�ϵ
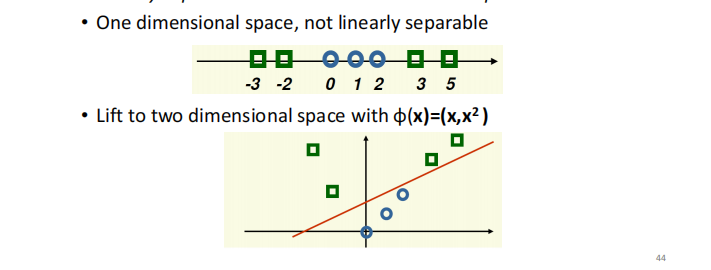
Non-separable Example && Convergence of Perceptron Rules
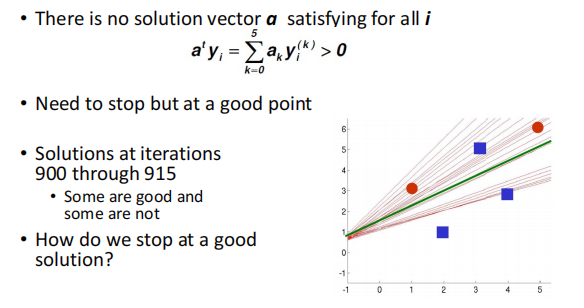
������������û�а취�ҵ�һ�����ʵķ����ߵ����,���ڻ�����֪�����������б������,����һֱ��������,û�а취������
��ʱ���ǿ������ú��ʵ�ѧϰ��

,�൱�ڸ��´���Խ��,�ݶȻ�Խ��Խ������¡�
Lecture 8
Minimum Squared-Error Procedures
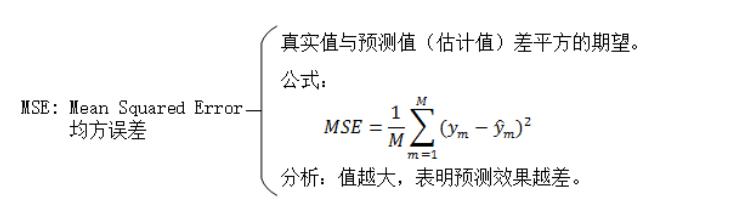
MSE ֻ��һ������Ŀ�꺯��(��ʧ)��һ�����̶��ѡ�
MSE:��ⷽ��:
-
������Ϊ0(Optimization)
-
�ݶ��½�Gradient Descent
Support Vector Machines
Support Vector Machines
LDF���ֵ�����:����ֻ�Ǻܺõ������ѵ����,������һ���µ�����(ʮ�ֽӽ����ǵľ���ƽ��),���Ǿͺ��������ִ���
��˾���ҪSVM(? Idea: maximize distance to the closest example)ʹ��ӽ�����ƽ���������֮��ľ������
��ʽ:
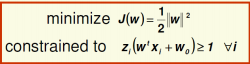
(������ѧ����:)
���||w||,��Ҫ�����������պ���,��ԭ������ʽת���:
������ú˺���:



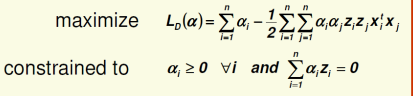
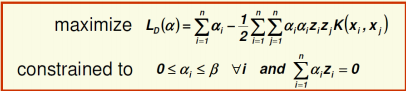
SVM: Non-Separable Case
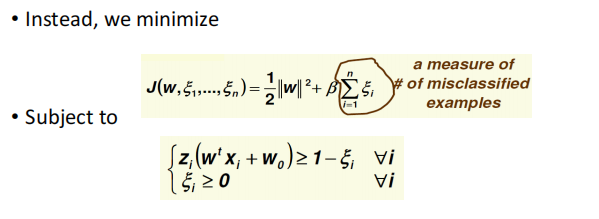
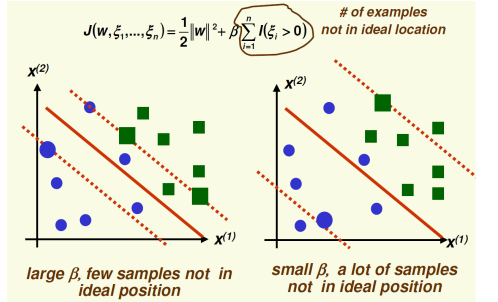
ͨ������ b �Ĵ�С���ɳڼ��(�������ٵ��������������)
Nonlinear Mapping
����ת������ʵ�ַ�����ӳ��:
Kernels(SVM�ĺ˺���)
��Ϊ�����������������Կɷֵ�(��һ���߾��ܹ��ֳ���),�����Ҫ�õ��˺���(�ı����ƽ�����״)
�˺���һ���ǰ�������
�˺�������(�˽�):

Nonlinear SVM Step-by-Step
��֮ǰ������һ����,ֻ�Ǹı��˺˺���(����Ȥ���Կ���ѧ�Ƶ�����)
One-Against-All
�����������о� SVM���ԴӶ���������ת��Ϊ���������:

Lecture 9
Ensemble Classifiers (���ɷ�����)
���ö����������������߷���Ч��
��Ҫ��Ϊ Bagging �� boosting,����random forest ���� bagging(�о��ῼ)
Bagging:
������ͶƱ����:���ѡȡ����,����ÿһ�����ѡȡ��ѵ����ѵ��һ��������,���ͨ�����з���������ͶƱ��������ķ���Ч����
Decision Tree(������)
��һ����״�ķ�����,ÿһ���ڵ��ѡ���Ǹ�����Ϣ������ѡ���
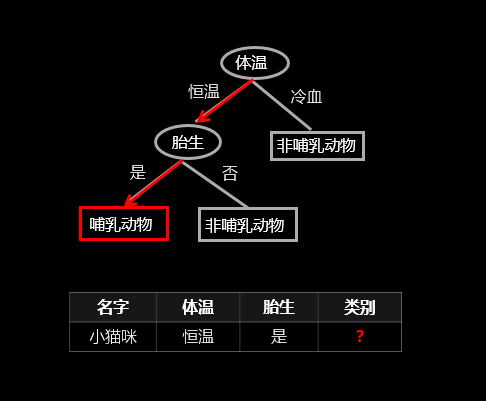
����Ȥ���Կ�:(����Ӧ�ò���)
������(decision tree)(һ)�����������������_����28��ר��-CSDN����_������
Random Forest:(���ɭ��)
���ǰѾ�����������������,Ȼ������Bagging����,ͶƱ�������ķ��ࡣ
Advantages of Random Forests
-
Very high accuracy �C not easily surpassed by other algorithms
-
Efficient on large datasets
-
Can handle thousands of input variables without variable deletion
-
Effective method for estimating missing data, also maintains accuracy when a large proportion of the data are missing
-
Robust to label noise
-
Can be used in clustering, locating outliers and semi-supervised learning
Boosting
��bagging��ͬ������,���������ѡ��ÿһ�ε�ѵ������(�й����)
��AdaBoost��:

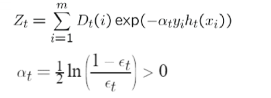
-
��һ�ξ��ȵ�ѡȡ����
-
֮��������һ��ѡȡ�������Ĵ�����������,������Խ�������ѡȡ����(Ϊ�����ܹ����õ�ѵ���ֲ��Եĵ�)
-
���ط�����ÿһ���������Լ��÷������ش��������Ͼ���(sign��һ�������)
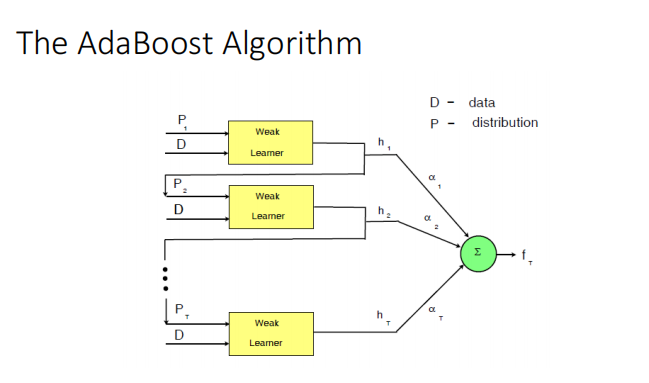
Random Forests vs. Boosting

Lecture 10
Unsupervised Learning(Clustering)
ΪʲôҪ�÷Ǽලѧϰ:

Distance Measures:
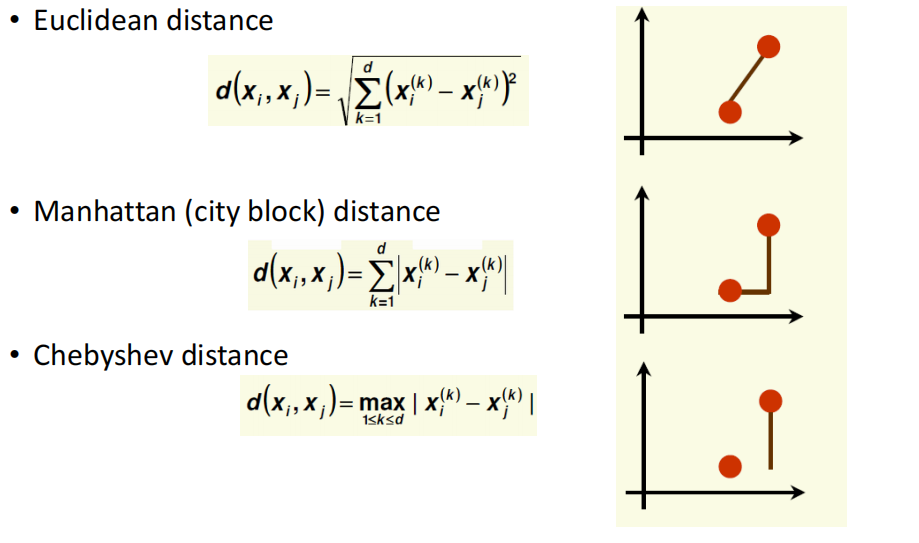
��������:
-
Fix the number of clusters to k(�ֳɼ���)
-
Find the best clustering according to the criterion function (number of clusters may vary)(��ô��)
K-means Clustering
һ�ֵ������㷨 Iterative optimization algorithms
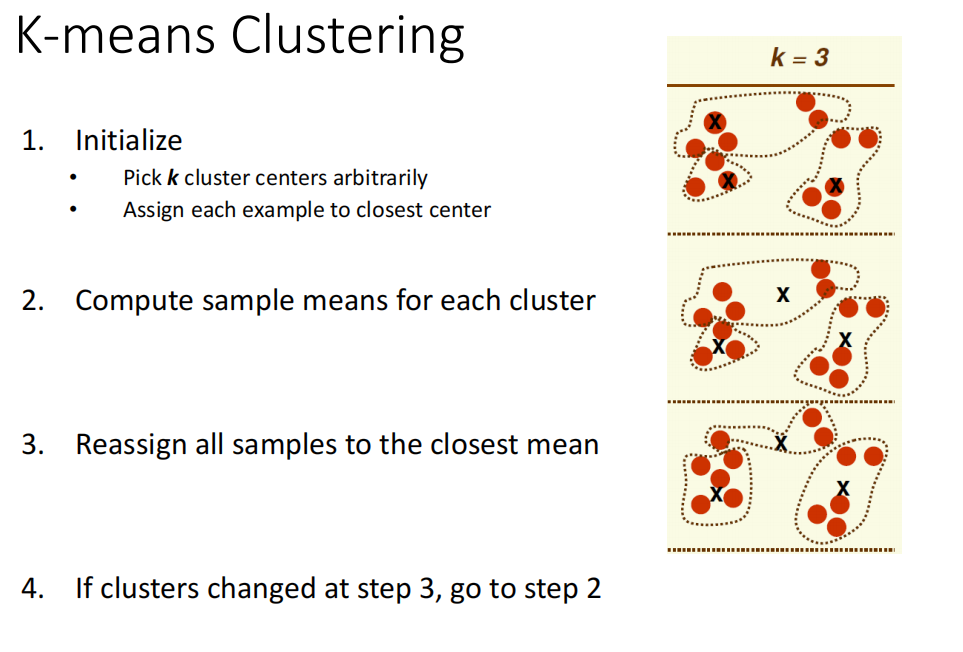
-
��ΪѡȡҪ�ֵ�����,��ͼk=3,���������ʼ���������ĵ�,�Զ�����,�����ĸ����ĵ��������һ��
-
����ÿһ�������mean(��ֵ)
-
���½����еĵ����ݵڶ����ؾ�ֵ���ࡣ
-
�ظ�2 3 ���� ֱ�����е㲻��
�ڶ����ؾ�ֵ�����þ���(Distance Measures)������
-----------------------------------------------------------------------------------------��л���¹���,��˽����