Ŀ¼
����ģʽ�ھ���
����ģʽ�ĸ�����������Agrawal��Srikant����ġ�
����:�����������еĽ���������һϵ�е��û��������ݿ�,ÿһ����¼�����û���ID,��������ʱ��������漰����Ŀ��������������ھ��漰����������ϵ��ģʽ,���û����ι�����Ϊ�����ϵ,���Բ�ȡ��������Ե�Ӫ����ʩ��
�������ݿ�ʵ�� ��:һ���������ݿ�,һ���������һ�ʽ���,һ���������������Ʒ,���������е����ּ�¼������ƷID

�������ݿ�
һ��Ϊ�˷��㴦��,��Ҫ�����ݿ�ת��Ϊ�������ݿ⡣�����ǰ��û�ID��ͬ�ļ�¼�ϲ�,��ʱÿ������ķ���ʱ����Ժ���,������������ƫ���ϵ��

���ⶨ��
�(Itemset)���������������ݿ���ֹ��ĵ�����ɵļ���
��:��һ���û������¼���������ݿ���˵,������û������������Ʒ,һ����Ʒ����һ�����ͨ��ÿ��������һ��Ψһ��ID,�����ݿ��м�¼���ǵ����ID��
Ԫ��(Element)�ɱ�ʾΪ(x1x2...Xm),X k(1 <=k<= m)Ϊ��ͬ�ĵ��Ԫ���ڵĵ������˳���ϵ,һ��Ĭ�ϰ���ID���ֵ������С�
���û��������ݿ���,һ���������һ��Ԫ�ء�
����(Sequence)�Dz�ͬԪ��(Element)����������,����s���Ա�ʾΪs =<S, S2.��.Sl>,s(1 <=j<=l)Ϊ����s��Ԫ��
һ�����а��������е���ĸ�����Ϊ���еij��ȡ�����Ϊl�����м�Ϊl-���� ��:һ������<(10,20) 30(40, 60,70)>��3��Ԫ��,�ֱ���(10 20),30,(40 60 70)
3������ķ���ʱ������ǰ��������������һ��6-���С�
�����Ц� = <a1a2...an>,���Ц�=<b,b2.. .bm>,ai��bi,����Ԫ�ء�
�����������1<=j1<j2<...<jn<= m,ʹ��a1?bj1,a2?bj2,..., an?bjn,������Ц�Ϊ���Цµ�������,�ֳ����Ц°�������a,��Ϊ��?�¡�
���Ц����������ݿ�S�е�֧�ֶ�Ϊ�������ݿ�S�а������Ц������и���,��ΪSupport(��) ����֧�ֶ���ֵx,������Ц����������ݿ��е�֧����������x,������Ц�Ϊ����ģʽ ����Ϊl������ģʽ��Ϊl-ģʽ��
����:���������ݿ�����ͼ��ʾ,�����û�ָ������С֧�ֶ�min-support = 2��

����<a(bc)df>������<a(abc)(ac)d(cf)>��������
����<(ab)c>�dz���Ϊ3������ģʽ
����ģʽ�ھ��Ӧ�ñ���
Ӧ�ð���:�ͻ�������Ϊģʽ����
B2C����������վ���Ը��ݿͻ������¼�������ͻ�������Ϊģʽ,�Ӷ�����������Ե�Ӫ�����ԡ�

Ӧ�ð���:�������
ҽ�������ר��ϵͳ������Ϊ������ϵĸ��������ֶΡ���Ӧ�ض��ļ���,�ڶ���ಡ�˵�֢״��ʱ��˳��¼���Զ������ü�¼���Է��ֶ�Ӧ���༲�����ʵ�֢״ģʽ��ÿ�ּ����Ͷ�Ӧ��һϵ��֢״ģʽ�����뵽֪ʶ���,ר��ϵͳ�Ϳ�����������������ר�ҽ��м�����ϡ�
��:ͨ��������������A�༲���IJ��˷�����¼,��������֢״����������ģʽ:<(ѣ��)(��������37-38��)>
������˾�������֢״,���п��ܻ�A�༲��
����ģʽ�ھ��㷨����
��Apriori�㷨
�����㷨����Apriori����,������ģʽ����һ������Ҳ������ģʽ���㷨�����Ե����ϵĸ��ݽ϶̵�����ģʽ���ɽϳ��ĺ�ѡ����ģʽ,Ȼ������ѡ����ģʽ��֧�ֶȡ����͵Ĵ�����GSP�㷨,spade�㷨��
���ڻ��ֵ�ģʽ�����㷨
�����㷨���ڷ��ε�˼��,�����Ľ�ԭʼ���ݼ����л���,�������ݹ�ģ,ͬʱ�ڻ��ֵĹ����ж�̬���ھ�����ģʽ,�����·��ֵ�����ģʽ��Ϊ�µĻ���Ԫ�����͵Ĵ�����FreeSpan�㷨,prefixSpan�㷨��
GSP�㷨
�㷨˼��
1��ɨ���������ݿ�,�õ�����Ϊ1������ģʽ,��Ϊ��ʼ�����Ӽ�L1��
2�����ݳ���Ϊi�����Ӽ�Li,ͨ�����Ӳ��������������ɳ���Ϊi+1 �ĺ�ѡ����ģʽCi+1;Ȼ��ɨ���������ݿ�,����ÿ����ѡ����ģ ʽ��֧�ֶ�,��������Ϊi+1������ģʽLi+1,����Li+1��Ϊ�µ� ���Ӽ���
3���ظ��ڶ���,ֱ��û���µ�����ģʽ���µĺ�ѡ����ģʽ���� Ϊֹ��
������ѡ����ģʽ�IJ���
?1�����ӽ�:���ȥ������ģʽS1�ĵ�һ����Ŀ��ȥ������ģʽ S2�����һ����Ŀ���õ���������ͬ,����Խ�S1��S2�������� ,����S2�����һ����Ŀ���ӵ�S1�С�
2�����н�:��ij��ѡ����ģʽ��ij�������в�������ģʽ, ��˺�ѡ���в�����������ģʽ,�����Ӻ�ѡ����ģʽ��ɾ����
��ϣ��
GSP���ù�ϣ���洢��ѡ����ģʽ����ϣ���Ľڵ��Ϊ����: 1�����ڵ� 2���ڲ��ڵ� 3��Ҷ�ӽڵ� ���ڵ���ڲ��ڵ��д�ŵ���һ����ϣ��,ÿ����ϣ��ָ�������Ľڵ㡣��Ҷ�ӽڵ��ڴ�ŵ���һ���ѡ����ģʽ?��

ʱ��Լ������
���������֧�ֶȼ���ʹ�õ�,GSP�㷨��֧�ֶȼ��㲻����ô��,���������ж�<2, <3, 4>>�Ƿ�������<(1,5), 2 , <3, 4>, 2>,��Ͳ��ܽ����ж��������Ƿ�ֻ����2,<3, 4>������,��Ҫ����ʱ����Լ��,���Ҫ��2,��<3,4>�����г���ʱ�䶼�ҳ���,Ȼ���������ҳ�һ������ʱ��Լ����·�����������ʱ��Ķ����Ǵ���������1.2,3...����,��1���Ϊ��λ,����2��ʱ����2���ֱ�Ϊt=2��t=4,Ȼ��ͬ��,��Ϊ<3,4>��������ֻ��1��,����ʱ��Ϊt=3,��������ͱ�Ϊ������һ�����������
2 ?4
3
��ʱ�������������,ͨ���Զ��ʱ������,�ҳ�1������ʱ��Լ���ķ���,����ķ���ֻ��2-3,4-3,Ȼ���ж�ʱ����,������������ķ�ʽ,�����������֧������������,֧�ֶ�ֵ��1,����㷨�ڳ����ʵ�����DZȽϸ��ӵġ�
ʱ��Լ�����㰸������
�ּ����������ʱ����maxgap=30,��С����ʱ����mingap=5,�����ѡ��������s=<(1,2)(3)(4)>�Ƿ�����ڸ�����������

?
?GSP�㷨��ȱ��
�ŵ�: 1)GSP������ʱ��Լ��,������ɨ���Լ������,��Ч�ؼ�������Ҫɨ��ĺ�ѡ���е�����,���ٶ��������ģʽ�IJ����� 2)GSP���ù�ϣ�����洢��ѡ����,��С����Ҫɨ�����������
ȱ��: 1)����������ݿ��ģ�ϴ�,���п��ܲ��������ĺ�ѡ����ģʽ; 2)��Ҫ���������ݿ����ѭ��ɨ��; 3)��������ģʽ�ij��ȱȽϳ������,�㷨���Դ�����
PrefixSpan�㷨
���ڻ��ֵ�ģʽ�����㷨
�����㷨���ڷ��ε�˼��,�����Ľ�ԭʼ���ݼ����л���,�������ݹ�ģ,ͬʱ�ڻ��ֵĹ����ж�̬���ھ�����ģʽ,�����·��ֵ�����ģʽ��Ϊ�µĻ���Ԫ�����͵Ĵ�����FreeSpan�㷨��prefixSpan�㷨
PrefixSpan�㷨��һЩ����
ǰ�ö�������A={a1,a2,.��.an}������B={b1,b2,.��. bm} n<=m,����a1=b1,a2= b2��an-1 = bn-1,��an?bn,���A��B��ǰ�������������B=<a(abc)(ac)d(cf)>,��A=<a(abc)a>,��A��B��ǰ����ȻB��ǰ��ֹһ��,����<a>,<aa>, <a(ab)>Ҳ����B��ǰ��
ͶӰ:�������Ц��ͦ�,������Ǧ���������,��������ڦµ�ͶӰ������������: ���Ǧ�����ǰ, �����Ǧ�������������������������С� ? ? ?
����:���Ц� =<(ab)(acd)>,�������Ц�=<(b)>��ͶӰ�Ǧ���= <(b)(acd)>; <(ab)>��ͶӰ��ԭ����<(ab)(acd)>��
ǰͶӰ(��)�U����ijһ��ǰ,������ǰ����ʣ�µ������м�Ϊ�������ǰ�����������һ����,����һ����_����ռλ��ʾ��
����С֧�ֶ�Ϊ25%,����С֧�ּ��� ? ?(5x25%=1.25,ȡ����Ϊ2)
����<a,(abc),(ac),d,(cf)>��ǰ��ǰͶӰǰ
| ǰ | ǰͶӰ |
| <a> | <(abc),(ac),d,(cf)> |
| <a,a> | <(_bc),(ac),d,(cf)> |
| <a,b> | <(_c),(ac),d,(cf)> |
PrefixSpan�㷨˼��
���ӳ���Ϊ1��ǰ��ʼ�ھ�����ģʽ,������Ӧ��ͶӰ���ݿ�õ�����Ϊ2��ǰ����������Ϊ2��ǰ��Ӧ��ͶӰ���ݿ�,�õ�����Ϊ3��ǰ��...�Դ�����,һֱ�ݹ鵽�����ھ�����ǰ,�ھ�Ϊֹ��
�㷨����
1 )�����ݿ������е������֧�ֶ�ͳ��,��֧�ֶȵ�����ֵ��������ݿ���ɾ��,�õ�����Ϊ1��ǰ
2)����ÿ������Ϊi����֧�ֶ�Ҫ���ǰ���еݹ��ھ�� ? ? ? ?
? ? ? ?a)�ҳ�ǰ����Ӧ��ͶӰ���ݿ⡣���ͶӰ���ݿ�Ϊ��,��ݹ鷵�ء� ? ? ? ?
? ? ? ?b)ͳ�ƶ�ӦͶӰ���ݿ��и����֧�ֶȼ���������������֧�ֶȼ�����������ֵ��,��ݹ鷵�ء� ? ? ? ?
? ? ? ?c)������֧�ֶȼ����ĸ�������͵�ǰ��ǰ���кϲ�,�õ������µ�ǰ�� ? ? ?
? ? ? ?d)��i=i+1,ǰΪ�ϲ������ĸ���ǰ,�ֱ�ݹ�ִ�е�2����
����:
| SID | ���� |
| 1 | <(AB),B,C> |
| 2 | <(AC),(ABC),B> |
| 3 | <A,B> |
| 4 | <(AB),A,B> |
����֧�ֶ���ֵΪ:3
(1)�����ݿ������е������֧�ֶ�ͳ��,��֧�ֶȵ�����ֵ��������ݿ���ɾ��,�õ�����Ϊ1��ǰ
| A | B | C |
| 4 | 4 | 2 |
| SID | ���� |
| 1 | <(AB),B> |
| 2 | <(A),(AB),B> |
| 3 | <A,B> |
| 4 | <(AB),A,B> |
(2)����ÿ������Ϊ1����֧�ֶ�Ҫ���ǰ���еݹ��ھ�:
| A | |
| 1 | <(_B),B> |
| 2 | <(AB),B> |
| 3 | <B> |
| 4 | <(_B),A,B> |
| A | B | _B |
| 2 | 4 | 3 |
?��ǰ:<A,B> ? <(AB)>
| B | |
| 1 | <B> |
| 2 | <B> |
| 3 | <B> |
| 4 | <A,B> |
| A | B |
| 1 | 3 |
��ǰ:<B,B>
(3)�ظ��ڶ���
| <(AB)> | |
| 1 | <B> |
| 2 | <B> |
| 3 | <> |
| 4 | <A,B> |
| A | B |
| 1 | 3 |
��ǰ:<(AB),B>
PrefixSpan�㷨�ܽ�
PrefixSpan�㷨���ڲ��ò�����ѡ����,��ͶӰ���ݿ���С�ĺܿ�,�ڴ����ıȽ��ȶ�,��Ƶ������ģʽ�ھ��ʱ��Ч���ܸߡ����������������ھ��㷨����GSP,FreeSpan�нϴ�����,������������������õ��㷨��
PrefixSpan����ʱ���������ڵݹ�Ĺ���ͶӰ���ݿ⡣����������ݼ��ϴ�,��������϶�ʱ,�㷨�����ٶȻ��������½��������һЩPrefixSpan�ĸĽ����㷨�������Ż�����ͶӰ���ݿ���һ�顣����ʹ��αͶӰ������
��Ȼʹ�ô�����ƽ̨�ķֲ�ʽ��������Ҳ�Ǽӿ�PrefixSpan�����ٶ�һ���ð취������Spark��MLlib��������PrefixSpan�㷨��
����scikit-learnʼ�ղ�̫���ӹ����㷨,һֱ����������һ����㷨����,����е������ˡ�
�ŵ�: 1)�������κεĺ�ѡ��,���ٿռ�; 2)ͶӰ���ݿ��ģ���ϼ���(��ΪͶӰ����������ǰ��صĺ�����);
ȱ��: 1)�㷨��Ҫ��������ͶӰ���ݿ�Ĺ���; 2)ʵ���ѶȽϴ�
Spade�㷨
GSP�㷨��ÿ�μ������е�֧�ֶ�ʱ,����Ҫɨ��һ�����ݿ⡣
�ɲ�����ͨ������һ�����ݿ�ľ���֪ʶ�����Ͷ�ζ����ݿ��ɨ����?
Spade�����ID_LIST�ĸ���,�������ζ����ݿ����ȫ��ɨ������⡣ID_LIST��һ��(SID, EID)��ɵı�
SPADE�㷨��GSP�㷨�ĸĽ�,����ɨ���ʱ����ɨ���������ݿ�,����ɨ��ID_LIST��
�㷨����
ɨ���������ݿ�,�������е�1-����,��������ת�ɴ�ֱ�Ĵ洢��ʽ��ͳ�Ƹ����ж�Ӧ��֧�ֶȼ���,С�ڹ涨֧�ֶȵ��ų���
��ǰ1-���й���2-���е�ԭ����,ͨ��Ƶ��1-���е������Ӳ�������2-���еĺ�ѡ����,����һ���õ�Ƶ��2-���С�
��ǰƵ��2-���й�����3-���е�ԭ����,ͨ��Ƶ��2-���е������Ӳ�������3-���еĺ�ѡ����,����һ���õ�Ƶ��3-���С�
ʵ�ʰ���


NOTE:��EID����ʾ������ʱ��
?����:֧�ֶ���ֵ��Ϊ3
1-���е�ID_LIST



? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?note:��ɫ�������Ƶ������
?2-���е�ID_LIST
?




<A,A> ����1Ƶ������A��ID_list���ɵ�;
<A,B> ����1Ƶ������A��ID_list��1Ƶ������B��ID_list���ɵ�;
<(A,B)> Ҳ����1Ƶ������A��ID_list��1Ƶ������B��ID_list���ɵ�
?3-���е�ID_LIST



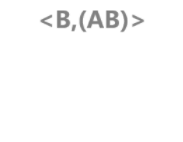
<A,(AB)> û������ID_list,��Ϊ<A,A> �Ƿ�Ƶ����; <B,(AB)> û������ID_list,��Ϊ <B,A> �Ƿ�Ƶ����;
SPADE�㷨�ܽ�
SPADE�㷨ͨ������һ�����ݿ�õ��ľ���֪ʶ�����Ͷ�ζ����ݿ��ɨ�衣
�ŵ�:
1)�����ԭʼ���ݽ���ɨ��,����Խ��,�����ٶ�Խ��;
2)SPADE����ͨ�����ٶ����ݿ��ɨ�轵��I/O�ɱ�,����ͨ������ID_list���ͼ���ɱ�;
3)û�в��ù�ϣ��,��˾��кܺõľ����ԡ�
ȱ��:
1)��ѡ������;
2)ʵ���Ѷ������GSP�㷨��˵Ҫ��һЩ
?
?
?
?
?
?
?
?
?