1 补充知识
1.1 相关函数
自相关函数ACF(autocorrelation function)
自相关函数ACF描述的是时间序列观测值与其过去的观测值之间的线性相关性。计算公式如下:
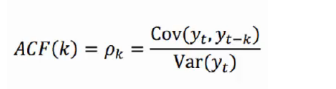 其中k代表滞后期数,如果k=2,则代表yt和yt-2
其中k代表滞后期数,如果k=2,则代表yt和yt-2
偏自相关函数PACF(partial autocorrelation function)
偏自相关函数PACF描述的是在给定中间观测值的条件下,时间序列观测值预期过去的观测值之间的线性相关性。
举个简单的例子,假设k=3,那么我们描述的是yt和yt-3之间的相关性,但是这个相关性还受到yt-1和yt-2的影响。PACF剔除了这个影响,而ACF包含这个影响。
1.2 截尾和拖尾
拖尾指序列以指数率单调递减或震荡衰减,而截尾指序列从某个时点变得非常小:
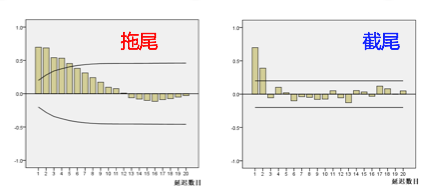
出现以下情况,通常视为(偏)自相关系数d阶截尾:
1)在最初的d阶明显大于2倍标准差范围
2)之后几乎95%的(偏)自相关系数都落在2倍标准差范围以内
3)且由非零自相关系数衰减为在零附近小值波动的过程非常突然

出现以下情况,通常视为(偏)自相关系数拖尾:
1)如果有超过5%的样本(偏)自相关系数都落入2倍标准差范围之外
2)或者是由显著非0的(偏)自相关系数衰减为小值波动的过程比较缓慢或非常连续。

1.3 时间序列差分
时间序列差分的目的是将非平稳序列转化为平稳序列。
2 ARIMA模型原理
2.1p阶自回归模型(AR)
自回归模型描述当前值与历史值之间的关系(即分析数据内部相关关系的方法),用变量自身的历史时间数据对自身进行预测。
自回归模型首先需要确定一个阶数p,表示用几期的历史值来预测当前值。p阶自回归模型AR(p)的公式定义为:
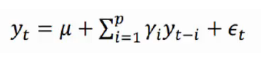
上式中yt是当前值,u是常数项,p是阶数 γi是自相关系数,?t是干扰误差。
自回归模型有很多的限制:
1、自回归模型是用自身的数据进行预测;
2、时间序列数据必须具有平稳性;
3、自回归只适用于预测与自身前期相关的现象;
2.2 q阶移动平均模型 (MA)
移动平均模型关注的是自回归模型中的误差项的累加 ,q阶自回归模型MA(q)的公式定义如下:
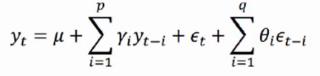
移动平均法能有效地消除预测中的随机波动。
2.3 自回归移动平均模型( ARMA)
如果预测的未来时间序列不仅与过去时刻对应的时间序列相关,还与过去时刻对应的扰动存在一定的相关关系,于是自回归模型AR和移动平均模型MA模型相结合,我们就得到了自回归移动平均模型ARMA(p,q),计算公式如下:
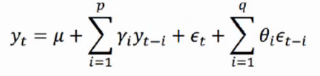
由于MA模型一定是平稳的,所以ARMA模型的平稳性完全取决于AR模型的平稳性。
2.4 差分自回归移动平均模型(ARIMA)
将自回归模型、移动平均模型和差分法结合,我们就得到了差分自回归移动平均模型ARIMA(p,d,q),其中d是需要对数据进行差分的阶数。任何非平稳序列通过差分就可以转化为平稳序列,从而使用ARMA进行模型拟合。
3 ARMIA模型的建立与Python实现
ARIMA模型的建立主要可分为三部分,即预处理,模型拟合和预测。

预处理
3.1 获取时间序列
数据集为风速序列,我们取其中1000个测量值作为原始序列。
"""原始序列检验"""
sale=pd.read_csv('shanghai.csv',index_col='Timestamp')
train_sale=sale[:1000]
# test_sale=sale[-100:10]
# print(sale.info())
# #绘制原始序列
plt.figure(figsize=(10,5))
train_sale.plot()
plt.show()
##自相关性检验
plot_acf(train_sale,lags=80).show()


3.2 平稳性检验
【ADF检验】
的全称是Augmented Dickey-Fuller test,它是Dickey-Fuller(DF)检验的扩展。DF检验只能应用于一阶AR模型的情况。当序列为高阶时,存在滞后相关性,于是可以使用更适用的ADF检验。具体可见
时间序列学习(4):平稳性检验(单位根检验、ADF检验)
在python中,一般用
from statsmodels.tsa.stattools import adfuller
adfuller(prices.close)
结果如下:
(-1.932446672214747, # t-检验值;
0.3169544458085871, #P-Value 滞后阶数(lags)
9,
465,
{'1%': -3.4444914328761977, #样本数 1%,5%,10%的边界值
'5%': -2.8677756786103683,
'10%': -2.570091378194011},
4819.095453869604) #最大信息准则(参数中autolag需不为None)
对于ADF,一般有两种判别方法:
1 t-检验值大于某个临界值,那么在这个临界值以内序列的不平稳性比较显著;
2 p-Value大于某个临界值的百分位(即1%,5%,10%),那么序列的不平稳性比较显著。
在这里,我们判断p-value小于5%为稳定。
#平稳性检验:判断p是否小于0.05;是则为平稳序列
print('原始序列的ADF检验结果为:',ADF(train_sale.Price)) #p=0.24 显著大于0.05故不平稳序列
原始序列的ADF检验结果为: (-1.991162087283564, 0.29046161027915296, 0, 999, {'1%': -3.4369127451400474, '5%': -2.864437475834273, '10%': -2.568312754566378}, 9979.084487404141)
于是,我们认为原始时间序列不稳定,需要对其进行差分计算。
【差分运算】
对于非平稳序列,通过差分运算使其转化为平稳序列。
"""一阶差分序列检验"""
d1_sale=train_sale.diff(periods=1, axis=0).dropna() #dropna删除NaN
#时序图
plt.figure(figsize=(10,5))
d1_sale.plot()
plt.show()
#自相关图
plot_acf(d1_sale,lags=20).show()
#解读:有短期相关性,但趋向于零。
#平稳性检验
print('原始序列一阶差分的ADF检验结果为:',ADF(d1_sale.Price))
#解读:P值小于显著性水平α(0.05),拒绝原假设(非平稳序列),说明一阶差分序列是平稳序列。


原始序列一阶差分的ADF检验结果为: (-32.38094077090129, 0.0, 0, 998, {'1%': -3.4369193380671, '5%': -2.864440383452517, '10%': -2.56831430323573}, 9973.154155945356)
经过差分运算后,得到平稳序列。
3.3 白噪声检验
**#白噪声检验
print('一阶差分序列的白噪声检验结果为:',acorr_ljungbox(d1_sale,lags=1))#返回统计量、P值
#解读:p值小于0.05,拒绝原假设(纯随机序列),说明一阶差分序列是非白噪声。**
一阶差分序列的白噪声检验结果为: lb_stat lb_pvalue
1 0.660875 0.416251
至此,获得平稳非白噪声序列。将该序列放入ARMA模型中获得预测模型。
模型拟合
3.4 模型定阶
模型的定阶主要有2种方法:相关图(ACF和PACF)和信息准则函数(AIC和BIC)。
【相关图】

根据前面所说判定截尾和拖尾的准则,p,q的确定基于如下的规则:
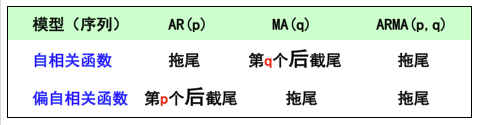
"""定阶"""
##1 人工识图
d1_sale=train_sale.diff(periods=1, axis=0).dropna()
#自相关图
plot_acf(d1_sale,lags=34).show()
#解读:有短期相关性,但趋向于零。
#偏自相关图
plot_pacf(d1_sale,lags=20).show()
#偏自相关图
plot_pacf(d1_sale,lags=34).show()
#解读:自相关图,1阶截尾;偏自相关图,拖尾。则ARIMA(p,d,q)=ARIMA(0,1,1)


【信息准则函数】
通过拖尾和截尾对模型进行定阶的方法,往往具有很强的主观性。回想我们之前在参数预估的时候往往是怎么做的,不就是损失和正则项的加权么?我们这里能不能结合最终的预测误差来确定p,q的阶数呢?在相同的预测误差情况下,根据奥斯卡姆剃刀准则,模型越小是越好的。那么,平衡预测误差和参数个数,我们可以根据信息准则函数法,来确定模型的阶数。预测误差通常用平方误差即残差平方和来表示。
常用的信息准则函数法有下面几种:
AIC准则
AIC准则全称为全称是最小化信息量准则(Akaike Information Criterion),计算公式如下:
AIC = =2 *(模型参数的个数)-2ln(模型的极大似然函数)
BIC准则
AIC准则存在一定的不足之处。当样本容量很大时,在AIC准则中拟合误差提供的信息就要受到样本容量的放大,而参数个数的惩罚因子却和样本容量没关系(一直是2),因此当样本容量很大时,使用AIC准则选择的模型不收敛与真实模型,它通常比真实模型所含的未知参数个数要多。BIC(Bayesian InformationCriterion)贝叶斯信息准则弥补了AIC的不足,计算公式如下:
BIC = ln(n) * (模型中参数的个数) - 2ln(模型的极大似然函数值),n是样本容量
##2参数调优:BIC
pmax=int(len(d1_sale)/600) #一般阶数不超过length/10
qmax=int(len(d1_sale)/600) #一般阶数不超过length/10
bic_matrix=[]
for p in range(pmax+1):
tmp=[]
for q in range(qmax+1):
try:
tmp.append(ARIMA(train_sale,order=(p,1,q)).fit().bic)
print("times", "p", p, "q", q)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix=pd.DataFrame(bic_matrix)
fig,ax=plt.subplots(figsize=(10,8))
ax=sns.heatmap(bic_matrix,
mask=bic_matrix.isnull(),
ax=ax,
annot=True,
fmt='.2f')
ax.set_title('Bic')
bic_matrix.stack()
p,q=bic_matrix.stack().idxmin() #最小值的索引
print('用BIC方法得到最优的p值是%d,q值是%d'%(p,q))
##3 参数调优:AIC
pmax=int(len(d1_sale)/1200)
qmax=int(len(d1_sale)/1200)
aic_matrix=[]
for p in range(pmax+1):
tmp=[]
for q in range(qmax+1):
try:
tmp.append(ARIMA(train_sale,order=(p,1,q)).fit().aic)
print("times", "p", p, "q", q)
except:
tmp.append(None)
aic_matrix.append(tmp)
aic_matrix=pd.DataFrame(aic_matrix)
p,q=aic_matrix.stack().idxmin() #最小值的索引
print('用AIC方法得到最优的p值是%d,q值是%d'%(p,q))
3.5 模型检验
建立模型后,需要对擦查序列进行检验。若残差序列为白噪声序列,则说明时间序列中的有用信息已经被提取完毕,剩下的全是随机扰动,是无法预测和使用的。
"""建模及预测"""
model=ARIMA(sale,order=(3,1,3)).fit()
##残差检验
resid=model.resid
##1
#自相关图
plot_acf(resid,lags=35).show()
#解读:有短期相关性,但趋向于零。
#偏自相关图
plot_pacf(resid,lags=20).show()
#偏自相关图
plot_pacf(resid,lags=35).show()
#2 qq图
qqplot(resid, line='q', fit=True).show()
#3 DW检验
print('D-W检验的结果为:',sm.stats.durbin_watson(resid.values))
#解读:不存在一阶自相关
#4 LB检验
print('残差序列的白噪声检验结果为:',acorr_ljungbox(resid,lags=1))#返回统计量、P值
#解读:残差是白噪声 p>0.05
# confint,qstat,pvalues = sm.tsa.acf(resid.values, qstat=True)
3.6 预测
###预测
print('未来6小时的预测:')
forecastdata=model.forecast(6) #预测、标准差、置信区间
# forecastdata=forecastdata[:]
# forecast=pd.Series(np.array(forecastdata),index=pd.date_range('2019/02/28',periods=70,freq='D'))
# forecast=forecast.to_frame()
# forecast2=forecast.reindex(columns=["Price"])
forecast=pd.DataFrame(np.array(forecastdata),index=pd.date_range('1994/11/22',periods=6,freq='D'),columns=["Price"])
data=pd.concat((train_sale,forecast),axis=0)
# data.columns=['历史值','未来预测值']
print(data)
plt.figure(figsize=(10,6))
# data.plot()
plt.plot(np.array(train_sale),)
plt.show()

4 完整源码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf #自相关图、偏自相关图
from statsmodels.tsa.stattools import adfuller as ADF #平稳性检验
from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验
import statsmodels.api as sm #D-W检验,一阶自相关检验
from statsmodels.graphics.api import qqplot #画QQ图,检验一组数据是否服从正态分布
from statsmodels.tsa.arima.model import ARIMA
"""原始序列检验"""
sale=pd.read_csv('shanghai.csv',index_col='Timestamp')
train_sale=sale[:1000]
# test_sale=sale[-100:10]
# print(sale.info())
# #绘制原始序列
plt.figure(figsize=(10,5))
train_sale.plot()
plt.show()
# ##自相关性检验
# plot_acf(train_sale,lags=80).show()
# #平稳性检验:判断p是否小于0.05;是则为平稳序列
# print('原始序列的ADF检验结果为:',ADF(train_sale.Price)) #p=0.24 显著大于0.05故不平稳序列
"""一阶差分序列检验"""
d1_sale=train_sale.diff(periods=1, axis=0).dropna() #dropna删除NaN
#时序图
plt.figure(figsize=(10,5))
d1_sale.plot()
plt.show()
#自相关图
plot_acf(d1_sale,lags=20).show()
#解读:有短期相关性,但趋向于零。
#平稳性检验
print('原始序列一阶差分的ADF检验结果为:',ADF(d1_sale.Price))
#解读:P值小于显著性水平α(0.05),拒绝原假设(非平稳序列),说明一阶差分序列是平稳序列。
#白噪声检验
print('一阶差分序列的白噪声检验结果为:',acorr_ljungbox(d1_sale,lags=1))#返回统计量、P值
#解读:p值小于0.05,拒绝原假设(纯随机序列),说明一阶差分序列是非白噪声。
# """定阶"""
# ##1 人工识图
# d1_sale=train_sale.diff(periods=1, axis=0).dropna()
# #自相关图
# plot_acf(d1_sale,lags=34).show()
# #解读:有短期相关性,但趋向于零。
# #偏自相关图
# plot_pacf(d1_sale,lags=20).show()
# #偏自相关图
# plot_pacf(d1_sale,lags=34).show()
#解读:自相关图,1阶截尾;偏自相关图,拖尾。则ARIMA(p,d,q)=ARIMA(0,1,1)
# ##2参数调优:BIC
# pmax=int(len(d1_sale)/10) #一般阶数不超过length/10
# qmax=int(len(d1_sale)/10) #一般阶数不超过length/10
# bic_matrix=[]
# for p in range(pmax+1):
# tmp=[]
# for q in range(qmax+1):
# try:
# tmp.append(ARIMA(sale,order=(p,1,q)).fit().bic)
# print("times", "p", p, "q", q)
# except:
# tmp.append(None)
# bic_matrix.append(tmp)
#
# bic_matrix=pd.DataFrame(bic_matrix)
# fig,ax=plt.subplots(figsize=(10,8))
# ax=sns.heatmap(bic_matrix,
# mask=bic_matrix.isnull(),
# ax=ax,
# annot=True,
# fmt='.2f')
# ax.set_title('Bic')
# bic_matrix.stack()
# p,q=bic_matrix.stack().idxmin() #最小值的索引
# print('用BIC方法得到最优的p值是%d,q值是%d'%(p,q))
##3 参数调优:AIC
pmax=int(len(d1_sale)/200)
qmax=int(len(d1_sale)/200)
aic_matrix=[]
for p in range(pmax+1):
tmp=[]
for q in range(qmax+1):
try:
tmp.append(ARIMA(sale,order=(p,1,q)).fit().aic)
print("times", "p", p, "q", q)
except:
tmp.append(None)
aic_matrix.append(tmp)
aic_matrix=pd.DataFrame(aic_matrix)
p,q=aic_matrix.stack().idxmin() #最小值的索引
print('用AIC方法得到最优的p值是%d,q值是%d'%(p,q))
##测试
# data=pd.DataFrame([1,2,1,2])
# sale_arima=sale.iloc[:,[0]]
# model=ARIMA(sale,order=(0,0,1)).fit().aic
"""建模及预测"""
model=ARIMA(train_sale,order=(3,1,3)).fit()
##残差检验
resid=model.resid
##1
#自相关图
plot_acf(resid,lags=35).show()
#解读:有短期相关性,但趋向于零。
#偏自相关图
plot_pacf(resid,lags=20).show()
#偏自相关图
plot_pacf(resid,lags=35).show()
#2 qq图
qqplot(resid, line='q', fit=True).show()
#3 DW检验
print('D-W检验的结果为:',sm.stats.durbin_watson(resid.values))
#解读:不存在一阶自相关
#4 LB检验
print('残差序列的白噪声检验结果为:',acorr_ljungbox(resid,lags=1))#返回统计量、P值
#解读:残差是白噪声 p>0.05
# confint,qstat,pvalues = sm.tsa.acf(resid.values, qstat=True)
###预测
print('未来6小时的预测:')
forecastdata=model.forecast(6) #预测、标准差、置信区间
# forecastdata=forecastdata[:]
# forecast=pd.Series(np.array(forecastdata),index=pd.date_range('2019/02/28',periods=70,freq='D'))
# forecast=forecast.to_frame()
# forecast2=forecast.reindex(columns=["Price"])
forecast=pd.DataFrame(np.array(forecastdata),index=pd.date_range('1994/11/22',periods=6,freq='D'),columns=["Price"])
data=pd.concat((train_sale,forecast),axis=0)
# data.columns=['历史值','未来预测值']
print(data)
plt.figure(figsize=(10,6))
# data.plot()
plt.plot(np.array(train_sale),)
plt.show()
#
# ###
# # test_sale_plot=test_sale.iloc[:,[0]].values.T
# plt.figure(figsize=(16,10))
# forecast.plot()
# # test_sale.plot(color="red")
# # plt.plot(test_sale_plot)
# plt.show()