����Ŀ¼
ǰ��
���˹������ǹ���������У�������ѧԺ�Ĵ��ı�����,Ҳ������Ͷ�ʵij�ѧ�ߡ���Ϊ����ѧУ����������ǰ����ͬ�鼫��,ȱ����ҵ��Ľ���,�ںܳ�һ��ʱ��,���˹�һֱ��Ϊ��������MACD�ȼ���ָ��Ļ�������һЩ�ſ��DLģ����Ԥ��(��Ϊ���ںܶ������鼮���ǡ�Python�����+����ָ��+����ѧϰ��)��
����û�з�������,�����ھ����൱һ��ʱ��Ľ��Ǻ�������,��ʼ��������ҵ���˱ȽϷ��Ͽ۵�����ȫ�����ʶ�����ǿ�������������ϵ�в��͵Ĵ���,���Լ���ѧϰ�ܽᡢ��������,�Ժ���Ҫ��ͬ�齻����
��Ϊ���������;�������,������������������覴������©,��ӭ����ָ����
�������������Ĺ�������Ȥ,��ӭ��ϵ��:cai_jinhang@foxmail.com
ϵ������
����������Ͷ�ʷ�����֮������ѡ��ϵ�����µĵ�һƪ,����������(����Tushare)�͵����Ӽ���ģ�顣
ʸ����ѡ�ɻز����
��ʾ:������̫��,�ɽ�Ϻ���Ĵ�������
Ҫ��1:���ݸ�ʽ
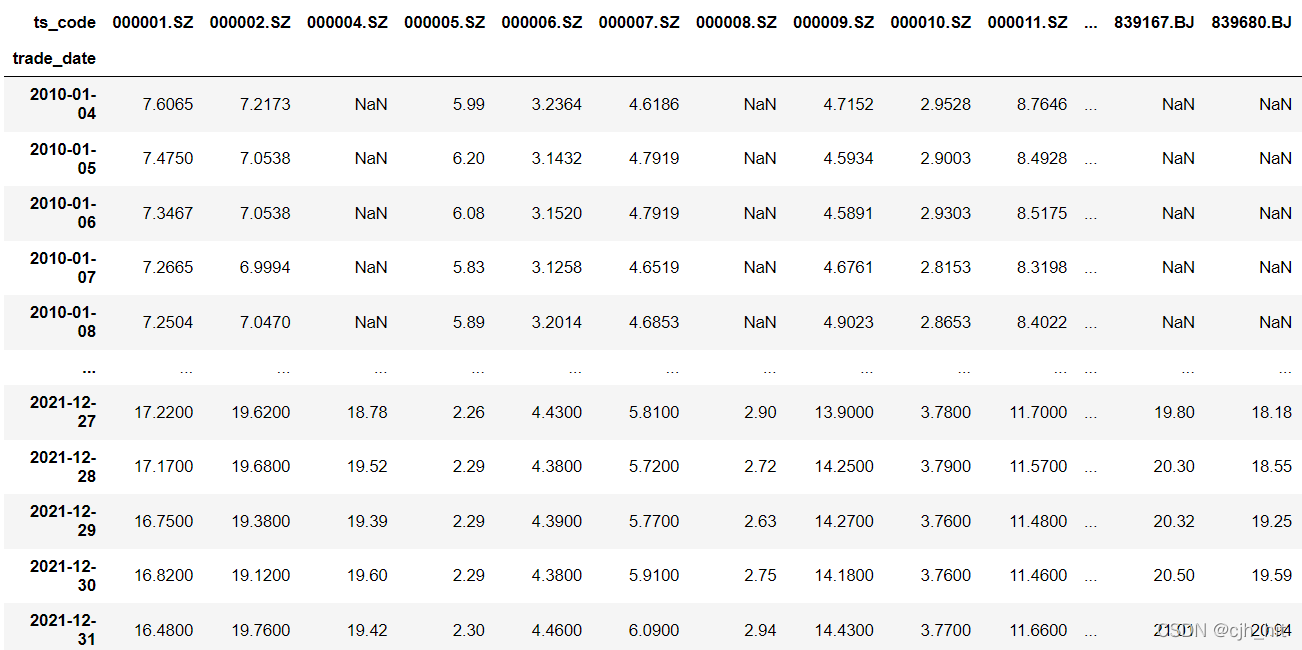
�����ݴ������ض���DataFrame��ʽ:(di,ii)��ʽ,��columnsΪ��Ʊ���롢indexΪ����,valueΪ����(�����̼ۡ��ɽ������������ӵ�),ÿһ��ָ���ǵ�����һ��df��
��Ҳ�����������ݶ�ҪDataFrame,һЩֻ��һά������ʹ��Series����,���ض�ָ�����������С�
����ͼ,��10�굽21��A�ɸ�Ȩ���close���ݡ�
Ҫ��2:��Ʊ��
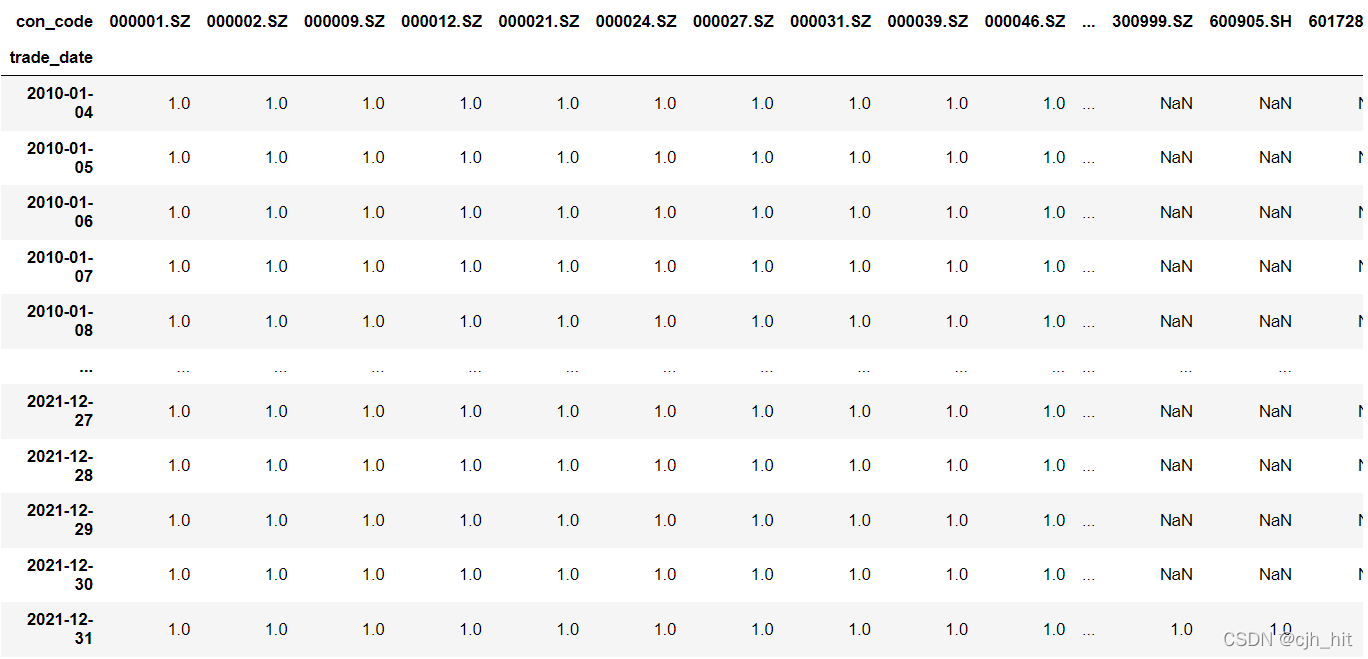
��Ʊ��һ��ȡ����ָ���ijɷֹɾ���(���������,�绦��300+��֤500),һ������Ϊuniv_a\univ_data��univ_a������ֻ�����ڻ���ʷ�������Ǹ�ָ���ɷֹɵĹ�Ʊ���롣
univ_a[stk_code][trade_date]=1����Ʊstk_code��trade_date��һ���Ǹ�ָ���ijɷֹɡ�����univ_a[stk_code][trade_date]=NaN
����һ���ڼ�������ʱ����ȫ����A������,����ѡ�ɻز�ʱ�ٿ��ǹ�Ʊ�ء�����Ϊ:
factor_df = factor_df.reindex_like(univ_a)*univ_a
����factor_dfΪ�������ݡ�reindex_like��factor_df���С�����univ_aͳһ��
����300�Ĺ�Ʊ������ʾ��
Ҫ��3:��ST�ɡ�ͣ�̹ɡ��ǵ�ͣ����
�������ST_valid,ST_valid[stk_code][trade_date]==1��stk_code��trade_date��һ�첻��ST��,ͨ����ST��ɸѡ,������NaN
�������suspend_valid��limit_valid,ͬST��
forbid_days = suspend_valid*limit_valid ֻ�й�Ʊ�ڵ���ͬʱͨ������ɸѡ,����ֵ��Ϊ1
����������ʱ,ֻ��Ҫ����λ����*forbid_days,û��ͨ��ɸѡ�Ĺ�Ʊ�����ݾͳ���NaN
Ҫ��4: ��λ����
step1:���������,���ձ���ɸѡ��Ʊ,�ٽ��в�λȨ�ع�һ��,�õ���ʼ��λpos_1
step2:�����ǵ�������,��������Ƶ�ʵ���,���Ǹ�20�������յ��֡�
pos_2 = pos_1.reindex(pos_1.index[::20]).fillna(0).reindex(pos_1.index).ffill()
����ȡ�����յIJ�λ,�����������ڵIJ�λ������Ϊnan,��ffill().
������һ��fillna(0),��Ϊ���������չ֮ǰfillna,����ܻ���� ijһ��һֻ��Ʊ��ѡ��,������ֻ��Ʊ�IJ�λԭ����Ӧ����NaN,������ffill֮��ȴ���̳��������λ��
step3:���ǵ����ղ��ɽ���Ʊ(��to_final_position)
������һ��Ҫǿ��,�����ǵ���factor_dfת���ɲ�λpos_dfʱ,��Ҫshift(1).��Ϊfactor�ǵ������̺�;�����˵����֮ǰ�����ݼ����,���������緢���ں�һ�������ա�
Ҫ��5:�ز�
�����õIJ�λfin_pos.shift(1)*rtn_df�ٺ�����;��Dz�λ��������,����rtn_df�ǹ�Ʊ�������.
shift()��ԭ����:rtn_df�ǵ������̼�(���̼�)����ǰһ������̼�(���̼�),�������ǵ����ǰһ���µĵ�,�������dzԲ����µ���һ���rtn��
������
���˳��Ի���tushare(��Ҫ����)��ȡ�о�����Ҫ�ij�������(���Ʊ�������ݡ�ָ���ɷֹ����ݡ�st�ɡ��ǵ�ͣ��)��������ǰ����ʾ��(di,ii)��ʽ��
���������ء��洢����ȡ��صĴ������¡�
��tushare�ĽӿڶԵ�ȡƵ�ʡ����ε�ȡ�����������ơ���������,��û�жԴ��������ȫ���Ż�,�ʲ��ִ���Ƚφ���,����Ч�ʵ͡�
��,��Ϊ���ַ���ʹ���˶���̲�������,������jupyter notebook�Ƚ���ʽ����������,����pycharm��IDE��ִ��main()������
������������Ҫ�������ࡣ
�������ص�DataDownloader,��tushare�ӿڻ�ȡ���ݲ��������ض���ʽ��
���ݸ��´洢��DataWriter,����DataDownloader���������ء����¡��洢�����ء�
���ݶ�ȡ��DataReader,��ȡ���ݡ�
import tushare as ts
import numpy as np
import pandas as pd
from multiprocessing import Manager, Pool
import datetime
import os
import pickle
import warnings
warnings.filterwarnings('ignore')
ts.set_token('')
pro = ts.pro_api(timeout=5)
global dataBase
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = curPath[:curPath.find("�����ӿ��\\")+len("�����ӿ��\\")]
dataBase = rootPath+'\\data\\'
def read_pickle(path):
with open(path, 'rb') as handle:
return pickle.load(handle)
def update_pickle(text, path):
with open(path, 'wb') as handle:
pickle.dump(text, handle)
class DataDownloader:
def __init__(self,start_date='20100101',end_date = None):
self.start_date = start_date
self.end_date = end_date
self.trade_dates = self.get_trade_dates()
self.stk_codes = self.get_stks()
#self.template_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes)
def get_trade_dates(self,start_date = None,end_date = None):
if start_date == None:
start_date = self.start_date
end_date = datetime.datetime.now().strftime('%Y%m%d') if end_date == None else self.end_date
df = pro.trade_cal(exchange='SSE', start_date=start_date,end_date=end_date)
df[df['is_open']==1]['cal_date'].drop_duplicates()
return df[df['is_open']==1]['cal_date'].to_list()
def get_stks(self):
stk_set = set()
for list_status in ['L','D','P']:
stk_set |= set(pro.stock_basic(list_status=list_status,fileds='ts_code')['ts_code'].to_list())
return sorted(list(stk_set))
def get_IdxWeight(self,idx_code):
'''
ָ���ɷֹ�
'''
start_date = pd.to_datetime(self.trade_dates[0]) - datetime.timedelta(days=32)
start_date = start_date.strftime('%Y%m%d')
trade_dates = self.get_trade_dates(start_date)
df_ls = []
while start_date < trade_dates[-1]:
end_date = pd.to_datetime(start_date) + datetime.timedelta(days=32)
end_date = end_date.strftime('%Y%m%d')
raw_df = pro.index_weight(index_code=idx_code, start_date=start_date,end_date=end_date)
df_ls.append(raw_df.pivot(index = 'trade_date',columns = 'con_code',values='weight'))
start_date = end_date
res_df = pd.concat(df_ls)
res_df = res_df[~res_df.index.duplicated(keep='first')]
res_df = res_df.reindex(trade_dates)
res_df = res_df.ffill().reindex(self.trade_dates)
return res_df.sort_index()
def get_ST_valid(self):
'''
ST��
'''
res_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes).fillna(1)
df = pro.namechange(fields='ts_code,name,start_date,end_date')
df = df[df.name.str.contains('ST')]
for i in range(df.shape[0]):
ts_code = df.iloc[i,0]
if ts_code not in self.stk_codes:
continue
s_date = df.iloc[i, 2]
e_date = df.iloc[i, 3]
if e_date == None:
res_df[ts_code].loc[s_date:]=np.nan
else:
res_df[ts_code].loc[s_date:e_date]=np.nan
return res_df.sort_index()
def get_suspend_oneDate(self,trade_date,m_ls):
'''
tushare�Ľӿ�һ������5000������,�������ȡ���ò��м��١�
'''
try:
df = pro.suspend_d(suspend_type='S',trade_date=trade_date)
m_ls.append([trade_date,df])
except:
df = pro.suspend_d(suspend_type='S',trade_date=trade_date)
m_ls.append([trade_date,df])
def get_suspend_valid(self):
'''
ͣ�ƹ�
'''
res_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes).fillna(1)
m_ls = Manager().list()
pools = Pool(4)
for date in self.trade_dates:
pools.apply_async(self.get_suspend_oneDate,
args=(date,m_ls)
)
pools.close()
pools.join()
m_ls = list(m_ls)
for date,df in m_ls:
print(date,df)
res_df.loc[date,df['ts_code'].to_list()] = np.nan
return res_df.sort_index()
def get_limit_oneDate(self,trade_date,m_ls):
'''
tushare�Ľӿ�һ������5000������,�������ȡ���ò��м��١�
'''
try:
df = pro.limit_list(trade_date=trade_date)
m_ls.append([trade_date,df])
except:
df = pro.suspend_d(trade_date=trade_date)
m_ls.append([trade_date,df])
def get_limit_valid(self):
'''
ͣ�ƹ�
'''
res_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes).fillna(1)
m_ls = Manager().list()
pools = Pool(3)
for date in self.trade_dates:
pools.apply_async(self.get_limit_oneDate,
args=(date,m_ls)
)
pools.close()
pools.join()
m_ls = list(m_ls)
for date,df in m_ls:
res_df.loc[date,df['ts_code'].to_list()]=np.nan
return res_df.sort_index()
def get_dailyMkt_oneStock(self,ts_code,m_ls):
'''
ǰ��Ȩ����������
��Ϊtushare���ظ�Ȩ����ӿ�һ��ֻ�ܻ�ȡһֻ��Ʊ
����ʹ�ö���в���
'''
try:
#ż������Ϊ������������ʧ��,������������
df = ts.pro_bar(ts_code=ts_code, adj='qfq', start_date=self.start_date,end_date=self.end_date)
m_ls.append(df)
except:
df = ts.pro_bar(ts_code=ts_code, adj='qfq', start_date=self.start_date,end_date=self.end_date)
m_ls.append(df)
def get_dailyMkt_mulP(self):
m_ls = Manager().list()
pools = Pool(3)#��̫����з���Ƶ������
for ts_code in self.stk_codes:
pools.apply_async(self.get_dailyMkt_oneStock,
args=(ts_code,m_ls))
pools.close()
pools.join()
m_ls = list(m_ls)
raw_df = pd.concat(m_ls)
res_dict = {}
for data_name in ['open','close','high','low','vol','amount']:
res_df = raw_df.pivot(index='trade_date',columns='ts_code',values=data_name)
res_dict[data_name] = res_df.sort_index()
return res_dict
class DataWriter:
@staticmethod
def commonFunc(data_path,getFunc,cover,*args,**kwds):
if not os.path.exists(data_path) or cover:
t1 = datetime.datetime.now()
print(f'--------{data_path},��һ�����ظ�����,���ܺ�ʱ�ϳ�')
newData_df = eval(f'DataDownloader().{getFunc}(*args,**kwds)')
newData_df.to_pickle(data_path)
t2 = datetime.datetime.now()
print(f'--------�������,��ʱ{t2-t1}')
else:
savedData_df = pd.read_pickle(data_path)
savedLastDate = savedData_df.index[-1]
print(f'---------{data_path}�ϴθ�����{savedLastDate},���ڸ��������½�����')
lastData_df = eval(f'DataDownloader(savedLastDate).{getFunc}(*args,**kwds)')
newData_df = pd.concat([savedData_df,lastData_df]).sort_index()
newData_df = newData_df[~newData_df.index.duplicated(keep='first')]
newData_df.to_pickle(data_path)
print(f'---------�Ѹ�������������{newData_df.index[-1]}')
newData_df.index = pd.to_datetime(newData_df.index)
return newData_df
@staticmethod
def update_IdxWeight(stk_code,cover=False):
data_path = dataBase+f'daily/idx_cons/{stk_code}.pkl'
return DataWriter.commonFunc(data_path,'get_IdxWeight',cover,stk_code)
@staticmethod
def update_ST_valid(cover=False):
data_path = dataBase+f'daily/valid/ST_valid.pkl'
return DataWriter.commonFunc(data_path,'get_ST_valid',cover)
@staticmethod
def update_suspend_valid(cover=False):
data_path = dataBase+'daily/valid/suspend_valid.pkl'
return DataWriter.commonFunc(data_path,'get_suspend_valid',cover)
@staticmethod
def update_limit_valid(cover=False):
data_path = dataBase+'daily/valid/limit_valid.pkl'
return DataWriter.commonFunc(data_path,'get_limit_valid',cover)
@staticmethod
def update_dailyMkt(cover=False):
'''
��Ҫ��֤�Ѵ洢��ochlv���ݵ�����һ��
'''
if not os.path.exists(dataBase+f'daily/mkt/open.pkl') or cover:
print(f'--------Mkt,��һ�����ظ�����,���ܺ�ʱ�ϳ�')
res_dict = DataDownloader().get_dailyMkt_mulP()
for data_name,df in res_dict.items():
data_path = dataBase+f'daily/mkt//{data_name}.pkl'
df.to_pickle(data_path)
else:
savedData_df = pd.read_pickle(dataBase+f'daily/mkt/open.pkl')
savedLastDate = savedData_df.index[-1]
print(f'---------Mkt,�ϴθ�����{savedLastDate},���ڸ��������½�����')
res_dict = DataDownloader(savedLastDate).get_dailyMkt_mulP()
new_df = pd.DataFrame()
for data_name,last_df in res_dict.items():
data_path = dataBase+f'daily/mkt//{data_name}.pkl'
new_df = pd.concat([savedData_df,last_df]).sort_index()
new_df = new_df[~new_df.index.duplicated(keep='first')]
new_df.to_pickle(data_path)
print(f'---------�Ѹ�������������{new_df.index[-1]}')
class DataReader:
@staticmethod
def commonFunc(data_path):
if not os.path.exists(data_path):
print(f'{data_path}������,���ȵ���DataWriter().update_xx')
return
df = pd.read_pickle(data_path)
df.index = pd.to_datetime(df.index)
return df
@staticmethod
def read_IdxWeight(stk_code):
data_path = dataBase+f'daily/idx_cons/{stk_code}.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_ST_valid():
data_path = dataBase+f'daily/valid/ST_valid.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_suspend_valid():
data_path = dataBase+'daily/valid/suspend_valid.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_limit_valid():
data_path = dataBase + 'daily/valid/limit_valid.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_dailyMkt(data_name):
data_path = dataBase+f'daily/mkt/{data_name}.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_index_dailyRtn(index_code,start_date = '20100101'):
df = pro.index_daily(ts_code=index_code, start_date= start_date).set_index('trade_date').sort_index()
df.index = pd.to_datetime(df.index)
return df['pct_chg']/100
@staticmethod
def read_dailyRtn():
df = DataReader.read_dailyMkt('close')
return df.pct_change()
if __name__ == '__main__':
DataWriter.update_ST_valid(cover=True)
DataWriter.update_suspend_valid(cover=True)
DataWriter.update_IdxWeight('399300.SZ',cover=True)
DataWriter.update_dailyMkt(cover=True)
DataWriter.update_limit_valid(cover=True)
�����Ӽ��
��Ҫ��
1.���ա��껯�����س���ָ���ʵ�֡�
2.to_finnal_position����,��ѡ���Ĺ�Ʊ���й�Ʊ�ء�st�ɡ�limit�ȴ���,��ע�͡�
3.factor_group����ز�,Ĭ�Ͻ���ʮ�ȷ�,������ֵͼ����������״ͼ��
4.ICIR���,����IC��IR,�����ۼ�ICͼ��
5.calc_daily_pnl�����λ���档
6.factor_stats�ۺ�,����ֱ�ӵ��øú�����
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def Col_zscore(df, n, cap=None, min_periods=1, check_std=False):
df_mean = df.rolling(window=n,min_periods=min_periods).mean()
df_std = df.rolling(window=n, min_periods=min_periods).std()
if check_std:
df_std = df_std[df_std >= 0.00001]
target = (df - df_mean) / df_std
if cap is not None:
target[target > cap] = cap
target[target < -cap] = -cap
return target
def Row_zscore(df, cap=None, check_std=False):
df_mean = df.mean(axis=1)
df_std = df.std(axis=1)
if check_std:
df_std = df_std[df_std >= 0.00001]
target = df.sub(df_mean, axis=0).div(df_std, axis=0)
if cap is not None:
target[target > cap] = cap
target[target < -cap] = -cap
return target
def MaxDrawdown(asset_series):
return asset_series - np.maximum.accumulate(asset_series)
def Sharpe_yearly(pnl_series):
return (np.sqrt(250) * pnl_series.mean()) / pnl_series.std()
def AnnualReturn(pos_df, pnl_series, alpha_type):
temp_pnl = (1+pnl_series).prod()
if alpha_type == 'ls_alpha':
temp_pos = pos_df.abs().sum().sum() / 2
else:
temp_pos = pos_df.abs().sum().sum()
if temp_pos == 0:
return .0
else:
return round(temp_pnl ** (250 / temp_pos) - 1,2)
def IC(signal, pct_n, min_valids=None, lag=0):
signal = signal.shift(lag)
corr_df = signal.corrwith(pct_n, axis=1,method='spearman').dropna()
if min_valids is not None:
signal_valid = signal.count(axis=1)
signal_valid[signal_valid < min_valids] = np.nan
signal_valid[signal_valid >= min_valids] = 1
corr_signal = corr_df * signal_valid
else:
corr_signal = corr_df
return corr_signal
def IR(signal, pct_n, min_valids=None, lag=0):
corr_signal = IC(signal, pct_n, min_valids, lag)
ic_mean = corr_signal.mean()
ic_std = corr_signal.std()
ir = ic_mean / ic_std
return ir, corr_signal
# def to_weighted_position(selected_df,weights_df = None):
# if weights_df is None:
# weights_df = pd.DataFrame().reindex_like(selected_df).fillna(1)
#
# weights_df = weights_df.reindex_like(selected_df)
# selected_weights_df = selected_df * weights_df
# weighted_position_df = selected_weights_df.div(selected_weights_df.sum(axis=1), axis=0)
# return weighted_position_df
def to_final_position(factor_score, forbid_day):
'''
factor_score:DataFrame,����������ֵ,Ҳ�����Ǹ�������ֵ����ѡ�����ij�ʼ��λ����
forbid_day:DataFrame,�Ƿ�ɽ���(��ST�ɡ�ͣ����˵õ�),1�����ù�Ʊ���տ��Խ���,���ɽ�������NaN
return:
pos_fin:DataFrame,���ղ�λ
'''
#��Ϊ����df��,indexΪx����ֵ����x�����̺���µ����ݼ����,����x�ղ��ܽ���,��Ҫ�ȵ���һ�콻��,����Ҫshift(1)
pos_fin = factor_score.shift(1).replace(np.nan, 0) * forbid_day
#�����ffill��Ч����,��ijֻ��Ҫ���Ĺ�Ʊ�ڵ�����������,��ô������һ�������,���Ӧλ����nan,��ffill���������ȼ̳�ǰһ�������յIJ�λ
pos_fin = pos_fin.ffill()
return pos_fin
def calc_daily_pnl(factor_df, univ_data, rtn_df, idx_rtn,forbid_days,method):
'''
:param factor_df: ����/�����
:param univ_data: ��Ʊ�ؾ���(�绦��300�ɷֹɡ���֤500�ɷֹɵȵ�)
:param idx_rtn: ָ��rtn����
:param forbid_days: �Ϸ�������
:param rtn_df: ��Ʊrtn����
:param method_func: feature/factor/ls_alpha/hg_alpha
:return: ��λ����+ÿ�ղ�λ����������
'''
factor_sel = factor_df.copy()
factor_sel = factor_sel.reindex_like(univ_data)*univ_data
forbid_days = forbid_days.reindex_like(factor_sel)
return_df = rtn_df.reindex_like(factor_sel)
if method == 'feature' or method == 'factor':
factor_z = Row_zscore(factor_sel, cap=4.5)
pos_final = to_final_position(factor_z, forbid_days)
daily_pnl_final = (pos_final.shift(1) * return_df).sum(axis=1)
return pos_final,daily_pnl_final
elif method == 'ls_alpha':
pos_final = to_final_position(factor_sel, forbid_days)
daily_pnl_final = (pos_final.shift(1) * return_df).sum(axis=1)
return pos_final,daily_pnl_final
elif method == 'hg_alpha':
pos_final = to_final_position(factor_sel, forbid_days)
daily_pnl_final = (pos_final.shift(1) * return_df).sum(axis=1) - idx_rtn
return pos_final,daily_pnl_final
def factor_group(factor_df,forb_day,rtn_df,idx_rtn,univ_data,split_pct_ls):
'''
����ز�
'''
factor_df = factor_df.reindex_like(univ_data)*univ_data
factor_score = factor_df
factor_rank_pct = factor_score.rank(ascending=False, pct=True, axis=1)
annual_rtn_ls = list()
plt.figure(figsize=(12, 6))
for split_pct in split_pct_ls:
pos_selected = factor_score[(factor_rank_pct > split_pct[0])&(factor_rank_pct <= split_pct[1])]
pos_selected = pos_selected.where(pd.isnull(pos_selected), 1)
pos = pos_selected.div(pos_selected.sum(axis=1), axis=0)
pos = to_final_position(pos, forb_day).reindex(factor_df.index)
daily_rtn = (pos.shift(1) * rtn_df).sum(axis=1).reindex(factor_df.index)
annual_rtn = AnnualReturn(pos,daily_rtn,'factor')
annual_rtn_ls.append(annual_rtn)
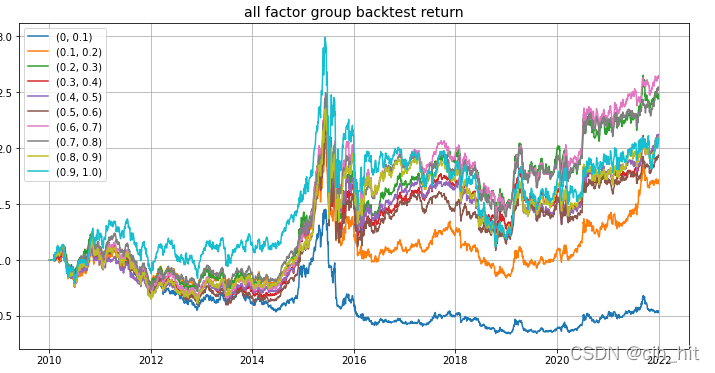
plt.plot((daily_rtn+1).cumprod(), label=str(split_pct))
plt.title('all factor group backtest return',fontsize = 14)
plt.legend()
plt.grid()
plt.show()
xticks = range(len(split_pct_ls))
plt.figure(figsize=(12, 6))
p = plt.subplot(111)
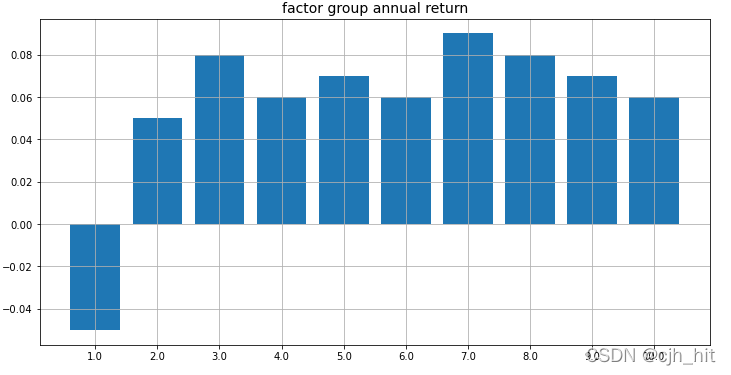
p.bar(x = xticks,height = annual_rtn_ls)
p.set_xticks(xticks)
p.set_xticklabels([x[1]*10 for x in split_pct_ls])
plt.title('factor group annual return',fontsize = 14)
plt.grid()
plt.show()
def factor_stats(
factor_df=None,
chg_n=1,#����ʱ����
univ_data=None,
rtn_df=None,
idx_rtn=None,
forbid_days = None,
method='factor',#factor\ls_alpha\hg_alpha
group_split_ls=[(0,0.1),(0.1,0.2),(0.2,0.3),(0.3,0.4),(0.4,0.5),(0.5,0.6),(0.6,0.7),(0.7,0.8),(0.8,0.9),(0.9,1.0)]
):
if method=='factor':
# plt.figure(figsize=(16, 12))
plt.figure(figsize=(12, 6))
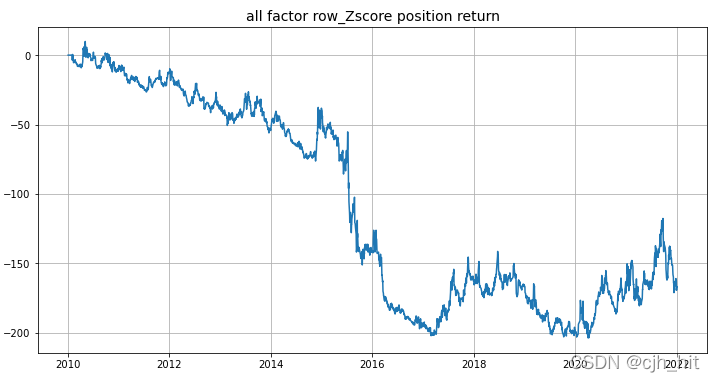
pos_final,daily_pnl = calc_daily_pnl(factor_df, univ_data, rtn_df, idx_rtn,forbid_days,method)
plt.plot(daily_pnl.cumsum())
plt.title('all factor row_Zscore position return',fontsize = 14)
plt.grid(1)
plt.show()
factor_group(
factor_df,
forbid_days,
rtn_df,
idx_rtn,
univ_data,
split_pct_ls=group_split_ls
)
pct_n = rtn_df.rolling(window=chg_n).sum()
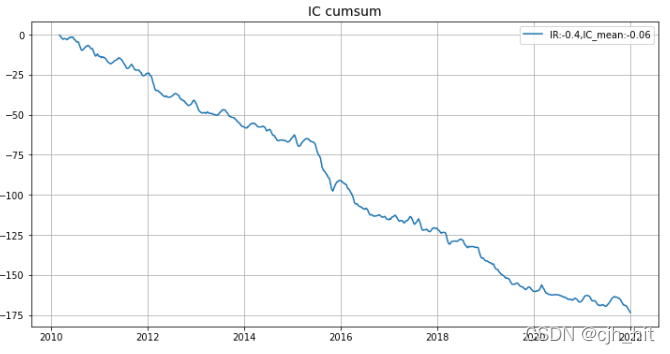
ir,IC_series = IR(factor_df, pct_n, lag=chg_n)
plt.figure(figsize=(12, 6))
plt.plot(IC_series.cumsum(),label=f'IR:{round(ir,2)},IC_mean:{round(IC_series.mean(),2)}')
plt.title('IC cumsum',fontsize = 14)
plt.legend()
plt.grid(1)
plt.show()
else:
plt.figure(figsize=(16, 6))
p1 = plt.subplot(111)
pos = factor_df.reindex(factor_df.index[::chg_n])#������λ,û����St��Ʊ Ҳû��shift
pos = pos.reindex(factor_df.index).ffill()
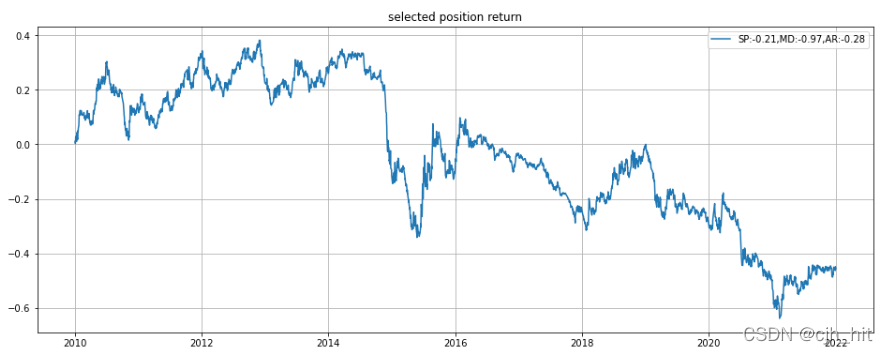
pos_final,daily_pnl = calc_daily_pnl(pos, univ_data, rtn_df, idx_rtn,forbid_days,method)
sharpe = round(Sharpe_yearly(daily_pnl),2)
max_drawdown = round(MaxDrawdown((daily_pnl+1).cumprod()),2)
annual_return = round(AnnualReturn(pos_final,daily_pnl,method),2)
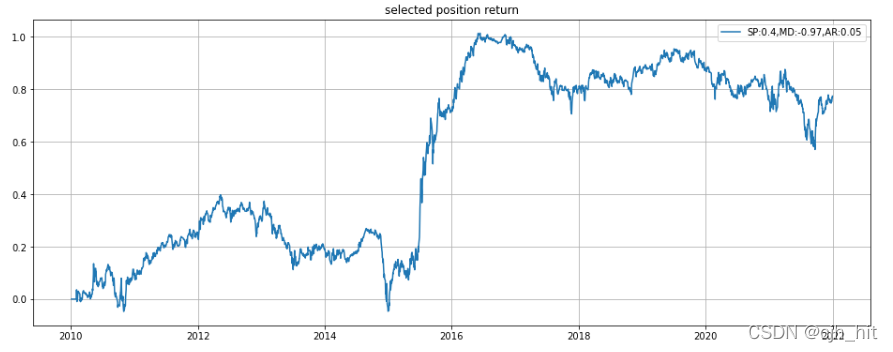
p1.plot(daily_pnl.cumsum(),label=f'SP:{sharpe},MD:{max_drawdown.min()},AR:{annual_return}')
p1.set_title('selected position return')
p1.grid(1)
p1.legend()
plt.show()
����
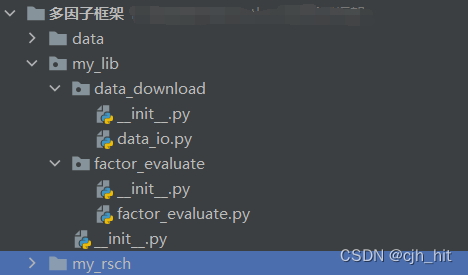
��20������������Ϊ��,չʾ�����Ӽ�����ݡ�
���˱��ص�Ŀ¼����ͼ��ʾ��
from my_lib.data_download.data_io import DataReader
from my_lib.factor_evaluate.factor_evaluate import factor_stats
import pandas as pd
import numpy as np
def calc_factor():
#�����Ǽ������ӵ�,�����Ӵ������ض���(di,ii)��ʽ��
close_df = DataReader.read_dailyMkt('close')
return close_df.pct_change(20)
��������
factor_df = calc_factor()
factor_df.tail(5)
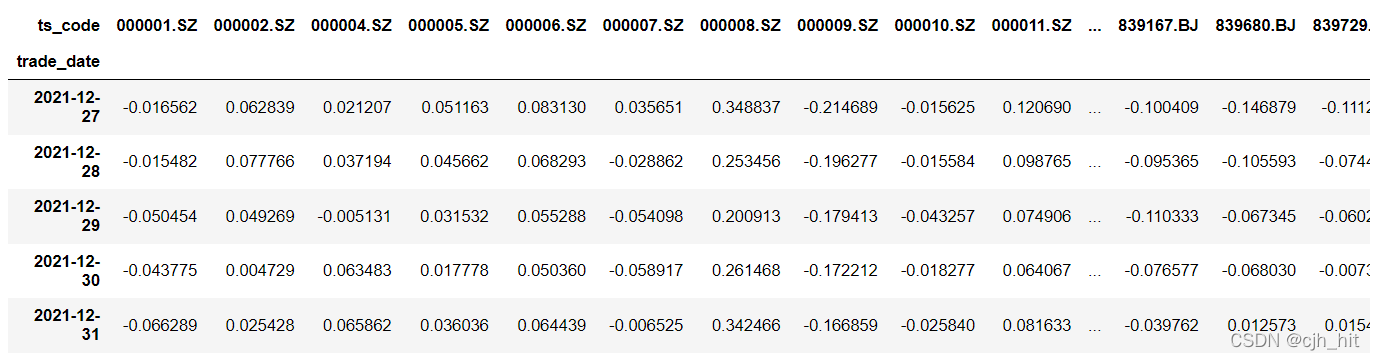
��Ʊ��
univ_a = DataReader.read_IdxWeight('399300.SZ')#����300
univ_a = univ_a.where(pd.isnull(univ_a),1)
univ_a
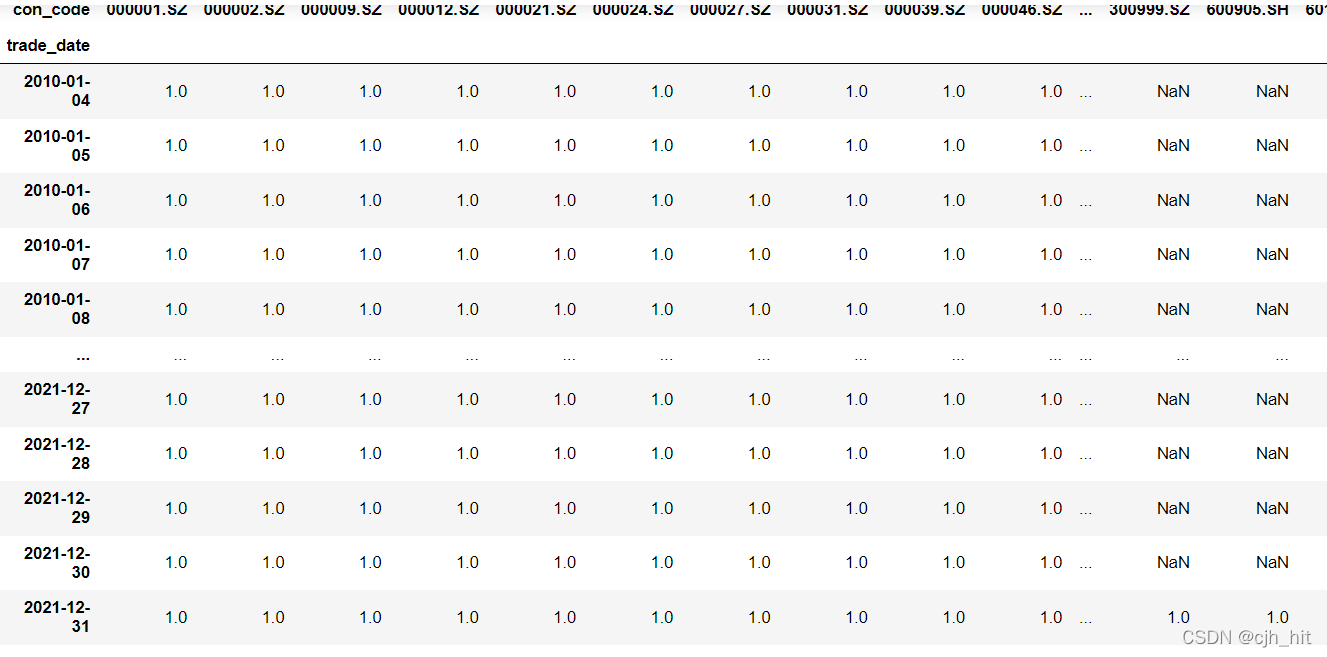
st�ɡ�ͣ�ơ��ǵ�ͣ
ST_valid = DataReader.read_ST_valid()
suspend_valid = DataReader.read_suspend_valid()
limit_valid = DataReader.read_limit_valid()
forb_days = ST_valid*suspend_valid*limit_valid
forb_days.tail(5)
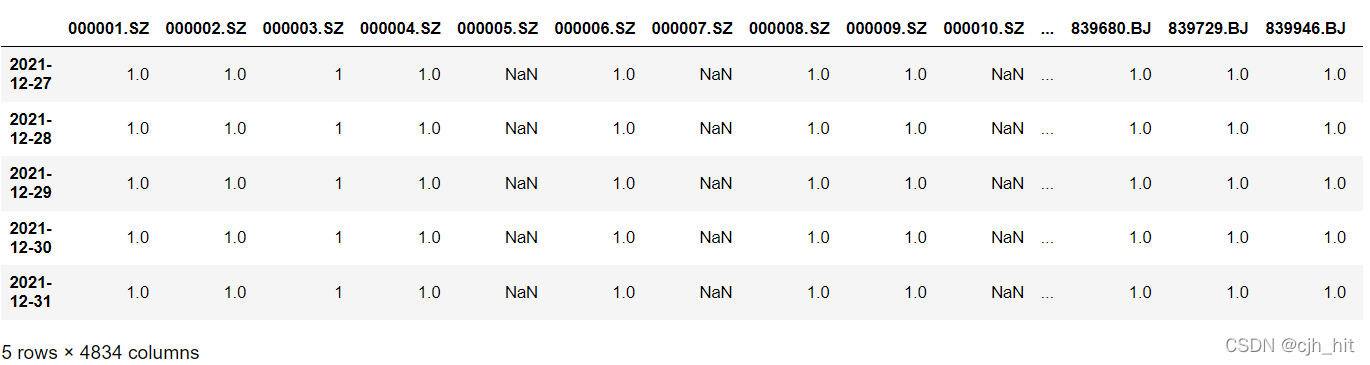
ÿ�������ʾ���
rtn_df = DataReader.read_dailyRtn()
rtn_df.tail(5)
���Ӳ�����ز�
ԭʼ����
idx_rtn = DataReader.read_index_dailyRtn('399300.SZ')#ָ����������
factor_stats(
factor_df=factor_df,#���ӻ��߲�λ����
chg_n=20,#��������
univ_data=univ_a,#��Ʊ��
rtn_df=rtn_df,#��Ʊÿ���������
idx_rtn=idx_rtn,#������������(����hg�Գ�)
forbid_days=forb_days,#st*suspend*limit
method='factor',#factor\ls_alpha\hg_alpha(ԭʼ���ӡ�ָ���Գ塢��նԳ�)
group_split_ls=[(0,0.1),(0.1,0.2),(0.2,0.3),(0.3,0.4),(0.4,0.5),(0.5,0.6),(0.6,0.7),(0.7,0.8),(0.8,0.9),(0.9,1.0)]#����ز����
)
ָ���Գ�
#����ѡ��,������λ
factor_rank_pct = factor_df.rank(ascending=False, pct=True, axis=1)
factor_selected = factor_df[factor_rank_pct>0.8]
factor_selected = factor_selected.where(pd.isnull(factor_selected), 1)
pos = factor_selected.div(factor_selected.sum(axis=1), axis=0)
pos = pos.fillna(0)#��Ҫ,����ffill�����
factor_stats(
factor_df = pos,
chg_n=20,
univ_data=univ_a,
rtn_df=rtn_df,
idx_rtn=idx_rtn.replace(np.inf,np.nan).replace(-np.inf,np.nan),
forbid_days=forb_days,
method='hg_alpha',#factor\ls_alpha\hg_alpha
)
��նԳ�
factor_df = factor_df.reindex_like(univ_a)*univ_a
factor_rank_pct = factor_df.rank(ascending=False, pct=True, axis=1)
#��ͷ��λ
factor_selected = factor_df[factor_rank_pct>0.8]
factor_selected = factor_selected.where(pd.isnull(factor_selected), 1)
pos_long = factor_selected.div(factor_selected.sum(axis=1), axis=0).fillna(0)
#��ͷ��λ
factor_selected = factor_df[factor_rank_pct<0.2]
factor_selected = factor_selected.where(pd.isnull(factor_selected), 1)
pos_short = factor_selected.div(factor_selected.sum(axis=1), axis=0).fillna(0)
factor_stats(
factor_df = pos_long.fillna(0) - pos_short.fillna(0),
chg_n=20,
univ_data=univ_a,
rtn_df=rtn_df,
idx_rtn=idx_rtn.replace(np.inf,np.nan).replace(-np.inf,np.nan),
forbid_days=forb_days,
method='ls_alpha',#factor\ls_alpha\hg_alpha
)