ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic SegmentationЛљгкЖдПЙьизюаЁЛЏЕФгявхЗжИюСьгђЪЪгІЗНЗЈ
0.еЊвЊ
гявхЗжИюЪЧаэЖрМЦЫуЛњЪгОѕШЮЮёЕФЙиМќЮЪЬтЁЃЫфШЛЛљгкОэЛ§ЩёОЭјТчЕФЗНЗЈдкВЛЭЌЕФЛљзМЩЯВЛЖЯДђЦЦаТМЧТМ,ЕЋНЋЦфЭЦЙуЕНВЛЭЌЕФВтЪдЛЗОГШдШЛЪЧвЛИіжиДѓЬєеНЁЃдкаэЖрЪЕМЪгІгУжа,бЕСЗгђКЭВтЪдгђжаЕФЪ§ОнЗжВМжЎМфШЗЪЕДцдкКмДѓЕФВюОр,етЛсЕМжТдЫааЪБЕФбЯжиадФмЫ№ЪЇЁЃдкетЯюЙЄзїжа,ЮвУЧНтОіСЫЛљгкЯёЫидЄВтьиЕФгаЫ№ЪЇгявхЗжИюжаЕФЮоМрЖНгђздЪЪгІШЮЮёЁЃЮЊДЫ,ЮвУЧЬсГіСЫСНжжаТЕФЛЅВЙЗНЗЈ,ЗжБ№ЪЙгУ(i)ьиЫ№ЪЇКЭ(ii)ЖдПЙадЫ№ЪЇЁЃЮвУЧдкСНИіОпгаЬєеНадЕФЁАКЯГЩЈC>ецЪЕЁБЩЯбнЪОСЫгявхЗжИюЕФзюаТадФм,ВЂБэУїИУЗНЗЈвВПЩгУгкМьВтЁЃ
1.ИХЪі
гявхЗжИюЪЧЮЊЭМЯёжаЕФЫљгаЯёЫиЗжХфРрБъЧЉЕФШЮЮёЁЃдкЪЕМљжа,ЗжИюФЃаЭЭЈГЃЪЧИДдгЕФМЦЫуЛњЪгОѕЯЕЭГ(ШчздЖЏМнЪЛЦћГЕ)ЕФжЇжљ,етаЉЯЕЭГдкИїжжИїбљЕФГЧЪаЛЗОГжаЖМвЊЧѓКмИпЕФОЋЖШЁЃР§Шч,дкЖёСгЬьЦјЯТ,ЯЕЭГБиаыФмЙЛЪЖБ№ЕРТЗЁЂГЕЕРЁЂВрБпЛђааШЫ,ОЁЙмЫћУЧЕФЭтЙлгыбЕСЗМЏжаЕФШЫДѓВЛЯрЭЌЁЃвЛИіИќЮЊМЋЖЫКЭживЊЕФР§згЪЧЫљЮНЕФЁАКЯГЩЈC>ецЪЕЁБЩшжУ[31,30]ЁЊЁЊбЕСЗбљБОЪЧгЩгЮЯЗв§ЧцКЯГЩЕФ,ВтЪдбљБОЪЧецЪЕГЁОАЁЃФПЧАЕФШЋМрЖНЗНЗЈ[23,47,2]ЛЙВЛФмБЃжЄЖдШЮвтВтЪдгУР§гаКмКУЕФЗКЛЏЁЃвђДЫ,дквЛИіГЦЮЊдДЕФгђЩЯбЕСЗЕФФЃаЭ,дкСэвЛИіГЦЮЊФПБъЕФгђЩЯгІгУЪБ,ЭЈГЃЛсОРњадФмЕФМБОчЯТНЕЁЃ
ЮоМрЖНгђЪЪгІ(Unsupervised domain adaptive, UDA)ЪЧвЛИібаОПСьгђ,ЦфФПЕФЪЧНіНіДгдДМрЖНжабЇЯАФПБъбљБОЩЯадФмСМКУЕФФЃаЭЁЃдкзюНќЕФUDAЗНЗЈжа,аэЖрЗНЗЈЭЈЙ§МѕЩйПчгђВювьРДНтОіетИіЮЪЬт,ВЂдкдДгђЩЯНјаагаМрЖНЕФбЕСЗЁЃЫќУЧЭЈЙ§ЗжБ№зюаЁЛЏдДЪ§ОнКЭФПБъЪ§ОнЕФжаМфЬиеїЗжВМЛђзюжеЪфГіЕФВювьРДНгНќUDAЁЃЪЙгУзюДѓЦНОљВювь(MMD)ЛђЖдПЙбЕСЗ(10,42)ПЩдкЕЅИі[15,32,44]ЛђЖрИіЫЎЦН[24,25]НјааЁЃЦфЫћЗНЗЈАќРЈздЮвбЕСЗ[51]ЬсЙЉЮББъЧЉЛђЩњГЩЭјТчРДЩњГЩФПБъЪ§Он[14,34,43]ЁЃ
АыМрЖНбЇЯАНтОіСЫвЛИіУмЧаЯрЙиЕФЮЪЬт,МДДгжЛгавЛИізгМЏЕФЪ§ОнжабЇЯАЁЃвђДЫ,ЫќЦєЗЂСЫUDAЕФМИжжЗНЗЈ,Р§Шч,здЮвбЕСЗ,ЩњГЩФЃаЭЛђжАвЕЦНКт[49]ЁЃьизюаЁЛЏвВЪЧАыМрЖНбЇЯА[38]ЕФГЩЙІЗНЗЈжЎвЛЁЃ
дкБОЙЄзїжа,ЮвУЧНЋьизюаЁЛЏддђгІгУгкUDAШЮЮёЕФгявхЗжИюЁЃЮвУЧДгвЛИіМђЕЅЕФЙлВьПЊЪМ:жЛдкдДгђЩЯбЕСЗЕФФЃаЭЭљЭљВњЩњЙ§ЖШздаХ,МДЕЭьи,ЖјЖдгкКЭдДЭМЯёРрЫЦЪ§ОнЕФдЄВтдђБэЯжГіВЛздаХ,МДИпьи,ЖдРрФПБъЭМЯёЕФдЄВтЁЃетжжЯжЯѓШчЭМ1ЫљЪОЁЃДгдДгђЕУЕНЕФГЁОАдЄВтьигГЩфПДЦ№РДОЭЯёдкИпьиМЄЛюЕФЧщПіЯТбиФПБъБпНчЕФБпдЕМьВтНсЙћЁЃСэвЛЗНУц,ЖдФПБъЭМЯёЕФдЄВтЪЧВЛШЗЖЈЕФ,ЕМжТЗЧГЃрадгЕФИпьиЪфГіЁЃЮвУЧШЯЮЊ,вЛжжПЩФмЕФЗНЗЈЪЧЭЈЙ§МгЧПФПБъдЄВтЕФИпдЄВтШЗЖЈад(ЕЭьи)РДУжКЯдДКЭФПБъжЎМфЕФСьгђВюОрЁЃЮЊДЫ,ЮвУЧЬсГіСЫСНжжЗНЗЈ:ЪЙгУьиЫ№ЪЇЕФжБНгьизюаЁЛЏКЭЪЙгУЖдПЙьиЫ№ЪЇЕФМфНгьизюаЁЛЏЁЃЕквЛжжЗНЗЈЖдЖРСЂЯёЫидЄВтЪЉМгСЫЕЭьидМЪј,ЖјКѓепЕФФПБъЪЧИљОнМгШЈздаХЯЂЖддДКЭФПБъЗжВМНјааШЋОжЦЅХфЮвУЧЕФЙБЯззмНсШчЯТ:
- ЖдгкгявхЗжИюUDA,ЮвУЧЬсГіРћгУьиЫ№ЪЇРДжБНгГЭЗЃФПБъгђЕФЕЭздаХдЄВтЁЃетжжьиЫ№ЪЇЕФЪЙгУВЛЛсИјЯжгаЕФгявхЗжИюПђМмдіМгЯджјЕФПЊЯњЁЃ
- ЬсГіСЫвЛжжаТЕФЛљгкьиЕФЖдПЙбЕСЗЗНЗЈ,ИУЗНЗЈВЛНівдьизюаЁЛЏЮЊФПБъ,ЖјЧввддДгђЕНФПБъгђЕФНсЙЙздЪЪгІЮЊФПБъЁЃ
- ЮЊСЫНјвЛВНЬсИпдкЬиЖЈЩшжУЯТЕФБэЯж,ЮвУЧЬсГіСНИіЖюЭтЕФЪЕбщ:(i)бЕСЗЬиЖЈЕФьиЗЖЮЇКЭ(ii)ФЩШыРрБШЯШбщЁЃЮвУЧЬжТлСЫдкЪЕбщКЭЯћШкбаОПжаЕФЪЕМЪМћНтЁЃ
ьизюаЁЛЏФПБъНЋФЃаЭЕФОіВпБпНчЭЦЯђдЄВтПеМфжаФПБъгђЗжВМЕФЕЭУмЖШЧјгђЁЃетбљПЩвдЕУЕНЁАИќИЩОЛЁБЕФгявхЗжИюЪфГі,ИќОЋЯИЕФЖдЯѓБпдЕКЭИќДѓЕФФЃК§ЭМЯёЧјгђБЛе§ШЗЕиЛжИД,ШчЭМ1ЫљЪОЁЃБОЮФЬсГіЕФФЃаЭдкМИИіUDAЛљзМЩЯЕФгявхЗжИюаЇЙћгХгкФПЧАзюЯШНјЕФЗНЗЈ,ЬиБ№ЪЧСНИіжївЊЕФКЯГЩЈC>ецЪЕЛљзМ,GTA5ЁњCityscapesКЭSYNTHIAЁњCityscapesЁЃ
2.ЯрЙиЙЄзї
ЮоМрЖНСьгђздЪЪгІЪЧЗжРрКЭМьВтСьгђбаОПЕФШШЕу,НќФъРДгявхЗжИюММЪѕвВШЁЕУСЫвЛаЉНјеЙЁЃСьгђЪЪгІадЕФвЛИіЗЧГЃЮќв§ШЫЕФгІгУЪЧдкЯжЪЕЪРНчЕФШЮЮёжаЪЙгУКЯГЩЪ§ОнЁЃетЙФРјСЫМИИіОпгаЯрЙиЪ§ОнМЏЕФКЯГЩГЁОАЯюФПЕФЗЂеЙ,ШчCarla [8], SYNTHIA[31]ЕШ[35,30]ЁЃ
UDAЕФжївЊЗНЗЈАќРЈдДФПБъЬиеїЗжВМВювьзюаЁЛЏ[10,24,15,25,42]ЁЂЮББъЧЉ[51]здбЕСЗКЭЩњГЩЗНЗЈ[14,34,43]ЁЃдкБОЙЄзїжа,ЮвУЧЬиБ№ИааЫШЄЕФЪЧгУгкгявхЗжИюЕФUDAЁЃвђДЫ,ЮвУЧдкетРяжЛЛиЙЫСЫгУгкгявхЗжИюЕФUDAЗНЗЈ(ИќвЛАуЕФЮФЯззлЪіМћ[7])ЁЃ
еыЖдUDAЕФЖдПЙбЕСЗЪЧФПЧАбаОПзюЖрЕФгявхЗжИюЗНЗЈЁЃЫќЩцМАСНИіЭјТчЁЃвЛИіЭјТчдЄВтЪфШыЭМЯёЕФЗжИюгГЩф,ЫќПЩвдРДзддДгђЛђФПБъгђ,ЖјСэвЛИіЭјТчзїЮЊвЛИіМјБ№Цї,ЫќДгЗжИюЭјТчжаЬсШЁЬиеїгГЩф,ВЂЪдЭМдЄВтЪфШыЕФгђЁЃЗжИюЭјТчЪдЭМЦлЦМјБ№Цї,ДгЖјЪЙРДздСНИігђЕФЬиеїОпгаЯрЫЦЕФЗжВМЁЃHoffmanЕШШЫ[15]ЪЧЕквЛИіНЋЖдПЙЗНЗЈгІгУгкUDAгявхЗжИюЕФШЫЁЃЭЈЙ§ДгдДгђДЋЪфБъЧЉЭГМЦаХЯЂ,ЫќУЧЛЙОпгаЬиЖЈгкРрБ№ЕФЪЪгІадЁЃ[5]жаЪЙгУСЫвЛжжРрЫЦЕФШЋОжКЭРрЕФЖдЦыЗНЗЈ,РрЕФЖдЦыЪЧЭЈЙ§ЖдЭјИёЕФШэЮББъЧЉНјааЖдПЙбЕСЗЭъГЩЕФЁЃдк[4]жа,ЖдПЙбЕСЗгУгкПеМфИажЊЪЪгІвдМАеєСѓЫ№ЪЇ,вдзЈУХНтОіКЯГЩЈC>ЪЕгђЧЈвЦЁЃ[16]ЪЙгУВаВюЭјЪЙдДЬиеїгГЩфгыФПБъЕФЬиеїгГЩфЯрЫЦ,ШЛКѓНЋИУЬиеїгГЩфгУгкЗжИюШЮЮёЁЃдк[41]жа,дкЪфГіПеМфЩЯЪЙгУЖдПЙЗНЗЈ,вдБуДгПчгђЕФНсЙЙвЛжТаджаЛёвцЁЃ[32,33]ЬсГіСЫСэвЛжжЪЙгУЖдПЙбЕСЗЕФгаШЄЗНЗЈ:ЫћУЧЖдФПБъгђЭМЯёНјааСНДЮдЄВт,етЪЧгЩСНИіЗжРрЦї[33]ЭъГЩЕФ,ЛђепдкЗжРрЦї[32]жаЪЙгУdropoutЁЃПМТЧЕНетСНжждЄВт,бЕСЗЗжРрЦїЪЙЗжВМжЎМфЕФВювьзюДѓЛЏ,ЖјбЕСЗЭјТчЕФЬиеїЬсШЁЦїВПЗжЪЙЗжВМжЎМфЕФВювьзюаЁЛЏЁЃ
вЛаЉЗНЗЈНЈСЂдкЩњГЩЭјТчЕФЛљДЁЩЯ,вддДЮЊЬѕМўЩњГЩФПБъЭМЯёЁЃHoffmanЕШШЫЬсГіСЫбЛЗвЛжТЖдПЙСьгђЪЪгІ(CyCADA),ЦфжаЫќУЧдкЯёЫиМЖКЭЬиеїМЖБэЪОЩЯЖМНјааСЫЪЪгІЁЃЖдгкЯёЫиМЖЕФздЪЪгІ,ЫћУЧЪЙгУCycle-GAN[48]ИљОндДЭМЯёЩњГЩФПБъЭМЯёЁЃдк[34]жа,бЇЯАЩњГЩФЃаЭ,ДгЬиеїПеМфжиНЈЭМЯёЁЃШЛКѓ,ЖдгкгђздЪЪгІ,ЭЈЙ§бЕСЗЬиеїФЃПщИљОндДЬиеїЩњГЩФПБъЭМЯё,ЗДжЎврШЛЁЃдкDCAN[43]жа,дкЗЂЩњЦїКЭЗжИюЭјТчжаЪЙгУСЫЭЈЕРЕФЬиеїЖдЦыЁЃЗжИюЭјТчЪЧдкЩњГЩЕФДјгадДФкШнКЭФПБъЗчИёЕФЭМЯёЩЯбЇЯАЕФ,дДЗжИюЭМзїЮЊФПБъЕФgroundtruthЁЃ[50]ЕФзїепЪЙгУЩњГЩЖдПЙЭјТч(GAN)[11]РДЖдЦыдДКЭФПБъЧЖШыЁЃДЫЭт,ЫќУЧЛЙгУвЛжжБЃЪиЕФЫ№ЪЇ(CL)ШЁДњСЫНЛВцьиЫ№ЪЇ,етжжЫ№ЪЇГЭЗЃСЫдДР§згжаШнвзКЭРЇФбЕФЧщПіЁЃCLЗНЗЈе§НЛгкДѓЖрЪ§UDAЗНЗЈ,АќРЈЮвУЧЕФ:ЫќПЩвдЪЙШЮКЮЪЙгУНЛВцьизїЮЊдДЕФЗНЗЈЪмвцЁЃ
UDAЕФСэвЛжжЗНЗЈЪЧздЮвбЕСЗЁЃЦфЫМЯыЪЧЪЙгУМЏГЩФЃаЭЕФдЄВтЛђФЃаЭЕФЧАвЛзДЬЌзїЮЊЮББъЧЉЕФЪ§Он,вдбЕСЗЕБЧАЕФФЃаЭЁЃаэЖрАыМрЖНЗНЗЈ[20,39]ЪЙгУздЮвбЕСЗЁЃдк[51]жа,UDAВЩгУздбЕСЗЕФЗНЗЈНјаагявхЗжИю,ВЂдкРрЦНКтКЭПеМфгХЯШЕФЛљДЁЩЯНјвЛВНРЉеЙЁЃздЮвбЕСЗгыЮвУЧдк3.1НкжаЬжТлЕФьизюаЁЛЏЗНЗЈгавЛИігаШЄЕФСЊЯЕЁЃ
дкЦфЫћвЛаЉЗНЗЈжа,[26]ЭЈЙ§ЖржиЫ№ЪЇЪЙгУЖдПЙКЭЩњГЩММЪѕЕФНсКЯ,[46]НсКЯЩњГЩЗНЗЈНјааЭтЙлЪЪгІКЭЖдПЙбЕСЗНјааБэеїЪЪгІ,[45]ЭЈЙ§МгЧПОжВП(ГЌЯёЫиМЖ)КЭШЋЧђБъЧЉЗжВМЕФвЛжТад,ЮЊUDAЬсГіСЫвЛжжПЮГЬЪНЕФбЇЯАЁЃ
ьизюаЁЛЏвбОБЛжЄУїЖдАыМрЖНбЇЯА[12,38]КЭОлРр[17,18]ЪЧгагУЕФЁЃИУЗНЗЈзюНќвВБЛгУгкЗжРрШЮЮё[25]ЕФСьгђздЪЪгІЁЃОнЮвУЧЫљжЊ,ЮвУЧЪЧЕквЛИіГЩЙІЕиНЋЛљгкьиЕФUDAбЕСЗгІгУгкгявхЗжИюШЮЮёЕФОКељадФмЁЃ
3.ЗНЗЈ
дкБОНкжа,ЮвУЧНщЩмСЫЮвУЧЬсГіЕФСНжжьизюаЁЛЏЗНЗЈ,ЪЙгУ(i)ЮоМрЖНьиЫ№ЪЇКЭ(ii)ЖдПЙбЕСЗЁЃЮЊСЫЙЙНЈЮвУЧЕФФЃаЭ,ЮвУЧДгЯжгаЕФгявхЗжИюПђМмПЊЪМ,ВЂЬэМгвЛИіЖюЭтЕФгУгкСьгђЪЪгІЕФЭјТчЗжжЇЁЃЭМ2ЫЕУїСЫЮвУЧЕФЬхЯЕНсЙЙЁЃ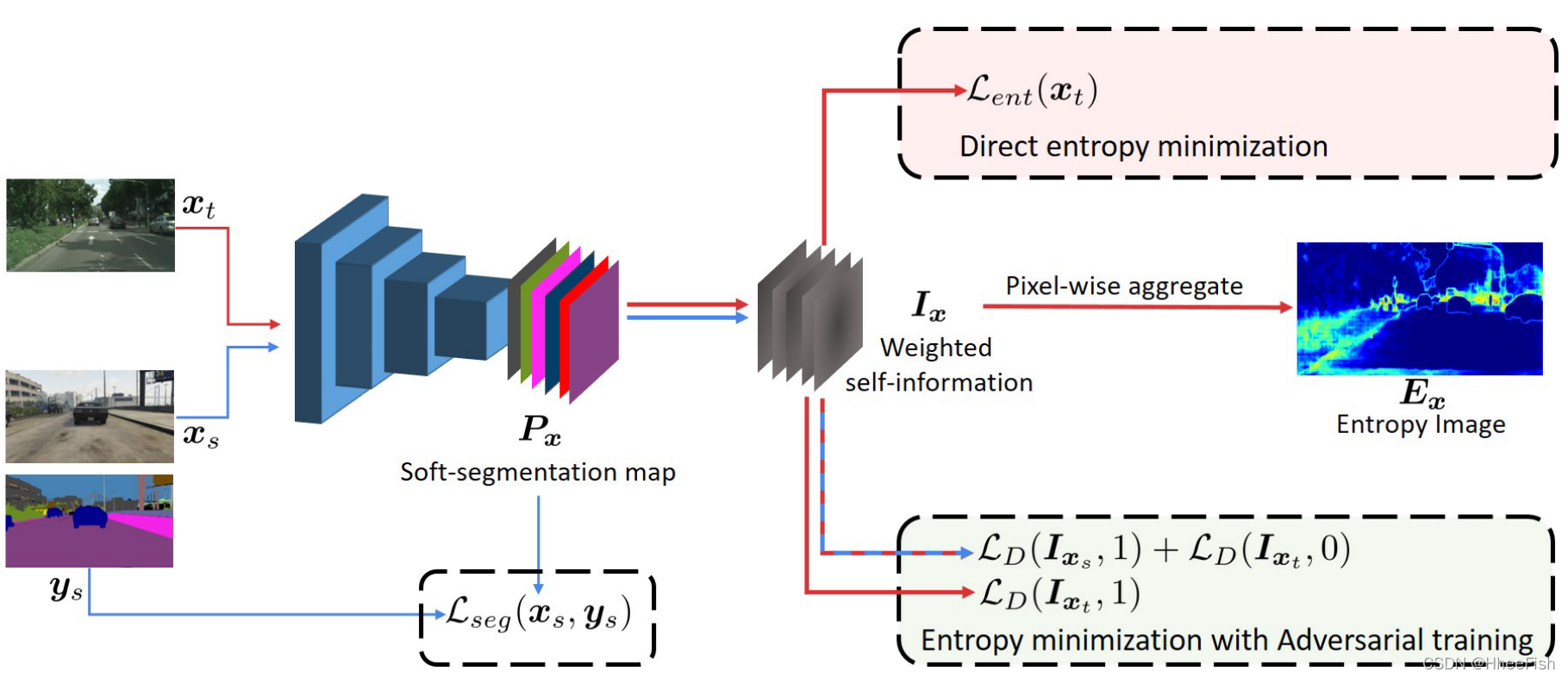
ЭМ2:ЗНЗЈИХЪіЁЃЭМжаЯдЪОСЫЮвУЧЖдUDAЕФСНжжЗНЗЈЁЃЪзЯШ,жБНгьизюаЁЛЏЪЙФПБъPxtЕФьизюаЁ,ЕШМлгкзюаЁЛЏМгШЈздаХЯЂгГЩфЕФКЭЁЃдкЕкЖўжжЛЅВЙЕФЗНЗЈжа,ЮвУЧЪЙгУЖдПЙадбЕСЗРДМгЧПIxПчСьгђЕФвЛжТадЁЃКьЩЋМ§ЭЗгУгкФПБъгђ,РЖЩЋМ§ЭЗгУгкдДЁЃЮФжаИјГіСЫьигГЩфЕФвЛИіР§згЁЃ
ЮвУЧЕФФЃаЭЪЧдкдДгђЩЯЪЙгУМрЖНЫ№КФНјаабЕСЗЕФЁЃаЮЪНЩЯ,ЮвУЧПМТЧвЛзщXs?RHЁСWЁС3ЕФдДР§зг,вдМАЯрЙиЕФground-truth CРрЗжИюЭМ,Ys?(1,C)HЁСWЁЃбљБОxsЪЧвЛЗљH ЁС WЕФВЪЩЋЭМЯё,ЪфШыys^(H, W)=[y~s~(H, W,c)^]ЙиСЊЕиЭМysЬсЙЉЯёЫи(h, w)ЕФБъЧЉЮЊЖРШШТыЯђСПЁЃЩшFЮЊгявхЗжИюЭјТч,ШЁЭМЯёx,дЄВтcЮЌЁАШэЗжИюЭМЁБF (x) = Px =[Px(w,h,c)]h,w,cЁЃЭЈЙ§зюКѓЕФsoftmaxВу,УПИіcЮЌЯёЫиЗНЯђЕФЪИСП[Px(w,h,c)]cдкРрЩЯБэЯжЮЊРыЩЂЗжВМЁЃШчЙћвЛИіРрЭЛГі,ЗжВМЪЧЕЭьиЕФ,ШчЙћЗжЪ§ЪЧОљдШЗжВМЕФ,ДгЭјТчЕФНЧЖШРДПД,етЪЧВЛШЗЖЈЕФМЃЯѓ,ьиОЭКмДѓЁЃбЇЯАFЕФВЮЪ§ІШFвдзюаЁЛЏЗжИюЫ№ЪЇLseg(xs, ys) =?ЁЦHh=1ЁЦWw=1ЁЦCc=1y(h,w,c)s(logP(h,w,c)xs)ЁЃдкжЛЖддДгђНјаабЕСЗЖјВЛНјаагђздЪЪгІЕФЧщПіЯТ,гХЛЏЮЪЬтЮЊ:
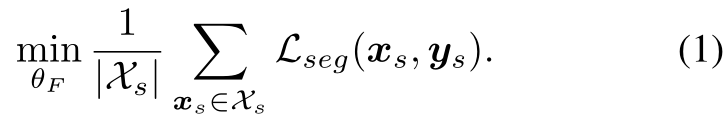
3.1.жБНгьизюаЁЛЏ
ЖдгкФПБъгђ,гЩгкЮвУЧУЛгаЖдгкЭМЯёбљБОxtЁЪXtЕФзЂЪЭyt,ЫљвдЮвУЧВЛФмЪЙгУ(1)РДбЇЯАFЁЃгааЉЗНЗЈЪЙгУФЃаЭЕФдЄВтyЁФtзїЮЊytЕФЬцДњЁЃДЫЭт,ИУЬцДњНігУгкдЄВтОпгазуЙЛПЩаХЖШЕФЯёЫиЁЃЮвУЧВЛЪЙгУИпздаХЕФДњРэ,ЖјЪЧЬсГідМЪјФЃаЭ,ЪЙЦфВњЩњИпздаХЕФдЄВтЁЃЮвУЧЭЈЙ§зюаЁЛЏдЄВтЕФьиРДЪЕЯжетвЛЕуЁЃ
ЮвУЧв§ШыьиЫ№ЪЇLentжБНгзюДѓЛЏФПБъгђЕФдЄВтШЗЖЈадЁЃдкетЯюЙЄзїжа,ЮвУЧЪЙгУShannonьи[36]ЁЃИјЖЈФПБъЪфШыЭМЯёxt,ьигГЩфExtЁЪ[0,1]HЁСWгЩЙщвЛЛЏЕН[0,1]ЗЖЮЇФкЕФЖРСЂЯёЫиьизщГЩ,(h,w)ДІЯёЫиЕФьиЮЊ:
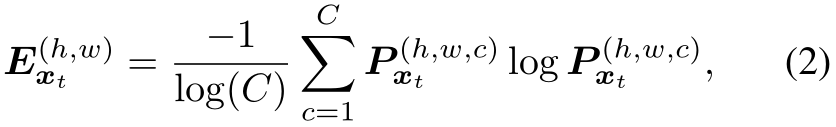
ьигГЩфЕФвЛИіР§згШч2ЫљЪОЁЃьиЫ№ЪЇLentЖЈвхЮЊЫљгаЯёЫиМЖБ№ЙщвЛЛЏьиЕФКЭ:
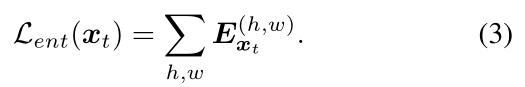
дкбЕСЗЙ§ГЬжа,ЮвУЧСЊКЯгХЛЏдДбљБОЕФМрЖНЗжИюЫ№ЪЇLsegКЭФПБъбљБОЕФЮоМрЖНьиЫ№ЪЇLentЁЃзюжеЕФгХЛЏЮЪЬтБэЪОЮЊ:
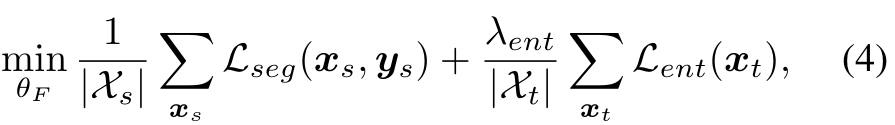
ІЫentзїЮЊьиLentЕФШЈживђзг
гыздбЕСЗДцдкЕФСЊЯЕ:ЮББъМЧЪЧвЛжжМђЕЅЖјгааЇЕФАыМрЖНбЇЯАЗНЗЈЁЃНќФъРД,ИУЗНЗЈвбБЛгІгУгкЛљгкЕќДњздбЕСЗ(ST)ГЬађ[51]ЕФгявхЗжИюШЮЮёжаЁЃSTЗНЗЈМйЩшЖдФПБъбљБОНјааИпЕУЗжЯёЫидЄВтЫљЕУЕНЕФМЏКЯK?(1,H) ЁС (1, W)ЪЧе§ШЗЕФ,ЧвИХТЪНЯИпЁЃетбљЕФМйЩшдЪаэЪЙгУНЛВцьиЫ№ЪЇгыЮББъЧЉЕФФПБъдЄВтЁЃдкЪЕМљжа,KЪЧЭЈЙ§бЁдёОпгаЙЬЖЈуажЕЛђдЄЖЈуажЕЕФИпЗжЯёЫиРДЙЙНЈЕФЁЃЮЊСЫгыьизюаЁЛЏСЊЯЕЦ№РД,ЮвУЧНЋSTЗНЗЈЕФбЕСЗЮЪЬтаДЮЊ: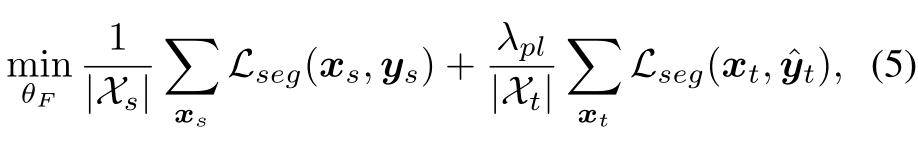
ЦфжаyЁФtЪЧxtЕФЖРШШТыРрБ№дЄВт,ВЂЧвга:
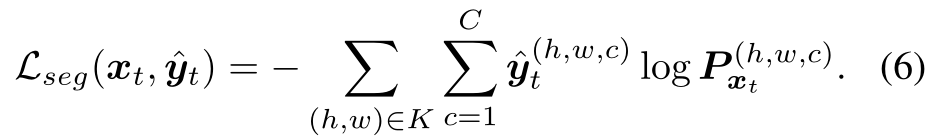
БШНЯЪН(2-3)КЭ(6),ЮвУЧзЂвтЕНЮвУЧЕФьиЫ№ЪЇLent(xt)ПЩвдБЛЪгЮЊЮББъЧЉНЛВцьиЫ№ЪЇLseg(xt,yЁФt)ЕФШэЗжХфАцБОЁЃгыST[51]ВЛЭЌ,ЮвУЧЕФЛљгкьиЕФЗНЗЈВЛашвЊИДдгЕФЕїЖШЙ§ГЬРДбЁдёуажЕЁЃЩѕжС,гыSTМйЩшЯрЗД,ЮвУЧдк4.3НкжаБэУї,дкФГаЉЧщПіЯТ,бЕСЗЁАРЇФбЕФЁБЛђЁАзюРЇЛѓЕФЁБЯёЫиЛсВњЩњИќКУЕФадФмЁЃ
3.2.РћгУЖдПЙбЇЯАзюаЁЛЏьи
ЭМ2:ЗНЗЈИХЪіЁЃЭМжаЯдЪОСЫЮвУЧЖдUDAЕФСНжжЗНЗЈЁЃЪзЯШ,жБНгьизюаЁЛЏЪЙФПБъPxtЕФьизюаЁ,ЕШМлгкзюаЁЛЏМгШЈздаХЯЂгГЩфЕФКЭЁЃдкЕкЖўжжЛЅВЙЕФЗНЗЈжа,ЮвУЧЪЙгУЖдПЙадбЕСЗРДМгЧПIxПчСьгђЕФвЛжТадЁЃКьЩЋМ§ЭЗгУгкФПБъгђ,РЖЩЋМ§ЭЗгУгкдДЁЃЮФжаИјГіСЫьигГЩфЕФвЛИіР§згЁЃ
дкЪН(3)жа,ЪфШыЭМЯёЕФьиЫ№ЪЇЖЈвхЮЊЖРСЂЯёЫидЄВтьиЕФКЭЁЃвђДЫ,етжжЫ№ЪЇЕФзюаЁЛЏКіТдСЫОжВПгявхжЎМфЕФНсЙЙвРРЕЙиЯЕЁЃШч[41]ЫљЪО,ЖдгкUDAНјаагявхЗжИюЪБ,ЖдНсЙЙЛЏЕФЪфГіПеМфНјааЪЪХфЪЧгавцЕФЁЃзХЛљгкдДгђКЭФПБъгђдкгявхВМОжЩЯОпгаКмЧПЕФЯрЫЦадЁЃ
дкетвЛВПЗжжа,ЮвУЧв§ШыСЫвЛИіЭГвЛЕФЖдПЙбЕСЗПђМм,ЭЈЙ§ЪЙФПБъЕФьиЗжВМгыдДЕФьиЗжВМЯрЫЦРДМфНгЕизюаЁЛЏьиЁЃетдЪаэРћгУгђжЎМфЕФНсЙЙвЛжТадЁЃЮЊДЫ,ЮвУЧНЋUDAШЮЮёЖЈвхЮЊдкМгШЈздаХЯЂПеМфЩЯЪЙдДКЭФПБъжЎМфЕФЗжВМОрРызюаЁЁЃЭМ2ЫЕУїСЫЮвУЧЕФЖдПЙбЇЯАЙ§ГЬЁЃЮвУЧЕФЖдПЙЗНЗЈЕФЖЏЛњЪЧ,ОЙ§бЕСЗЕФФЃаЭздШЛЕиВњЩњЕЭьидЄВтЕФдДРрЭМЯёЁЃЭЈЙ§ЖдЦыФПБъгђКЭдДгђЕФМгШЈздаХЯЂЗжВМ,МфНгзюаЁЛЏФПБъдЄВтьиЁЃДЫЭт,гЩгкЪЪгІЪЧдкМгШЈздаХЯЂПеМфЩЯНјааЕФ,ЮвУЧЕФФЃаЭРћгУСЫДгдДЕНФПБъЕФНсЙЙаХЯЂЁЃ
ОпЬхРДЫЕ,ИјЖЈЯёЫиМЖРрдЄВтЗжЪ§Px(h,w,c),здаХЯЂЛђЁАsurprisalЁБ[40]ЖЈвхЮЊ?log Px(h,w,c)ЁЃЪЕМЪЩЯ,(2)жаЕФьиEx(h,w)ОЭЪЧздаХЯЂEc[?log Px(h,w,c)]ЕФЦкЭћжЕЁЃЮвУЧдкгЩЯёЫиМЖЯђСПIx(h,w) = -Px(h,w,c)logPx(h,w,c)зщГЩЕФМгШЈздаХЯЂгГЩфIxЩЯНјааЖдПЙздЪЪгІЁЃетаЉЯђСППЩвдПДзїЪЧShannonьиЕФЯћОРВјЁЃШЛКѓ,ЮвУЧЙЙдьвЛИіШЋОэЛ§МјБ№ЦїЭјТчD,ВЮЪ§ІШDвдIxЮЊЪфШы,ВњЩњгђЗжРрЪфГі,МДРрБ№БъЮЊ1(0)ЮЊдД(ФПБъ)гђЁЃгы[11]РрЫЦ,ЮвУЧбЕСЗЪЖБ№ЦїРДЧјЗжРДзддДЭМЯёКЭФПБъЭМЯёЕФЪфГі,ЭЌЪБбЕСЗЗжИюЭјТчРДЦлЦЪЖБ№ЦїЁЃЦфжа,ШУLDБэЪОНЛВцьигђЕФЗжРрЫ№ЪЇЁЃМјБ№ЦїЕФбЕСЗФПБъЮЊ:
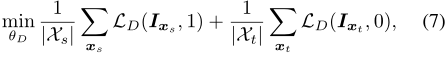
бЕСЗЗжИюЭјТчЕФЖдПЙФПБъЪЧ:
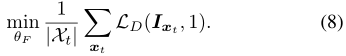
НсКЯ(1)КЭ(8),ЕУЕНзюгХЛЏЮЪЬт:
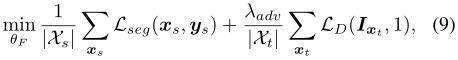
ЪЙгУЖдПЙЯюLDЕФМгШЈвђзгІЫadvЁЃдкбЕСЗЦкМф,ЮвУЧЪЙгУ(7)КЭ(9)жаЕФФПБъКЏЪ§НЛЬцгХЛЏЭјТчDКЭFЁЃ
3.3. СЊКЯЪЙгУРрБ№еМБШТЪЕФЯШбщжЊЪЖ
ьизюаЁЛЏПЩФмЛсЦЋЯђгквЛаЉМђЕЅЕФРрЁЃвђДЫ,гаЪБгУвЛаЉЯШбщжЊЪЖРДжИЕМбЇЯАЪЧгавцЕФЁЃЮЊДЫ,ЮвУЧЛљгкРрдкдДБъЧЉЩЯЕФЗжВМ,ЪЙгУвЛИіМђЕЅЕФРрЯШбщЁЃЮвУЧНЋдДБъЧЉЩЯУПИіРрЕФЯёЫиЪ§ЕФ?1-ЙщвЛЛЏжБЗНЭММЦЫузїЮЊРрЯШбщЯђСПpsЁЃЯждк,ИљОндЄВтЕФPxt,ШЮКЮРрБ№ЕФдЄЦкИХТЪгыжЎЧАЕФРрБ№psжЎМфЕФЬЋДѓВювьНЋЪмЕНГЭЗЃ,ЪЙгУ
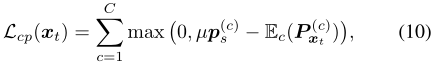
Цфжа,ІЬЁЪ[0,1]гУгкЗХЫЩРрЯШбщдМЪјЁЃетНтОіСЫЕЅИіФПБъЭМЯёЩЯЕФРрЗжВМВЛвЛЖЈНгНќpsЕФЪТЪЕЁЃ
4.ЪЕбщ
дкБОНкжа,ЮвУЧНЋНщЩмЮвУЧЕФЪЕбщНсЙћЁЃЕк4.1НкНщЩмСЫЪЙгУЕФЪ§ОнМЏвдМАЮвУЧЕФбЕСЗВЮЪ§ЁЃдк4.2НкКЭ4.3Нкжа,ЮвУЧБЈИцКЭЬжТлЮвУЧЕФжївЊНсЙћЁЃдк4.3Нкжа,ЮвУЧЬжТлСЫЛљгкьиЕФUDAМьВтЕФГѕВННсЙћЁЃ
4.1.ЪЕбщЯИНк
Ъ§ОнМЏ
ЮЊСЫЦРЙРЮвУЧЕФЗНЗЈ,ЮвУЧЪЙгУОпгаЬєеНадЕФКЯГЩЈC>ецЪЕЮоМрЖНСьгђЪЪгІЩшжУЁЃФЃаЭдкЭъећзЂЪЭЕФКЯГЩЪ§ОнЩЯНјаабЕСЗ,ВЂдкецЪЕЪРНчЕФЪ§ОнЩЯНјаабщжЄЁЃдкетбљЕФЩшжУжа,ФЃаЭПЩвддкбЕСЗжаЛёЕУвЛаЉЮДБъМЧЕФецЪЕЭМЯёЁЃЮЊСЫбЕСЗЮвУЧЕФФЃаЭ,ЮвУЧЪЙгУGTA5[30]ЛђSYNTHIA[31]зїЮЊдДгђКЯГЩЪ§Он,ВЂНЋCityscapesЪ§ОнМЏ[6]ЕФбЕСЗЗжИюзїЮЊФПБъгђЪ§ОнЁЃРрЫЦЕФЩшжУвдЧАвВдкЦфЫћзїЦЗжаЪЙгУЙ§[15,14,41,51]ЁЃ
- GTA5ЁњCityscapes:GTA5Ъ§ОнМЏгЩ24,966жЁКЯГЩЕФЪгЦЕгЮЯЗЛУцзщГЩЁЃЭМЯёЬсЙЉСЫ33ИіРрЕФЯёЫиМЖгявхБъзЂЁЃгы[15]РрЫЦ,ЮвУЧЪЙгУСЫгыcityscapeЪ§ОнМЏЯрЭЌЕФ19ИіРрЁЃ
- SYNTHIAЁњCityscapes:ЮвУЧЪЙгУSYNTHIARAND-CITYSCAPESМЏКЯ4КЭ9400еХКЯГЩЭМЯёНјаабЕСЗЁЃЮвУЧгУSYNTHIAКЭcityscapeжаЕФ16ИіЙЋЙВРрРДбЕСЗЮвУЧЕФФЃаЭЁЃдкЦРЙРЪБ,ЮвУЧБШНЯСЫ[51]жаЪЙгУЕФавщдк16РрКЭ13РрзгМЏЩЯЕФадФмЁЃ
дкетСНИіЩшжУжа,2975ИіЮДБъМЧЕФГЧЪаОАЙлЭМЯёБЛгУгкбЕСЗЁЃЮвУЧгУБъзМЕФЦНОљ-ЯрНЛ-КЯВЂ(mIoU)ЖШСП[9]РДКтСПЗжИюадФмЁЃЖд500еХбщжЄЭМЯёНјааЦРЙРЁЃ
ЭјТчЬхЯЕНсЙЙ
ЮвУЧЪЙгУDeeplab-V2[2]зїЮЊЛљДЁгявхЗжИюЬхЯЕНсЙЙFЁЃЮЊСЫИќКУЕиВЖзНГЁОАЩЯЯТЮФ,зюКѓвЛВуЕФЬиеїЪфГіВЩгУAtrousПеМфН№зжЫўГи(Atrous Spatial Pyramid Pooling, ASPP)ЁЃВЩбљТЪЙЬЖЈЮЊ{6,12,18,24},РрЫЦгк[2]жаЕФASPP-LФЃаЭЁЃЮвУЧдкСНжжВЛЭЌЕФbase deep CNNМмЙЙЩЯНјааСЫЪЕбщ:VGG-16[37]КЭResNet101[13]ЁЃдк[2]жЎКѓ,ЮвУЧаоИФзюКѓвЛВуЕФstrideКЭexpand rate,вдВњЩњИќУмМЏЁЂЪгвАИќДѓЕФfeature mapЁЃЮЊСЫНјвЛВНЬсИпResNet-101ЕФадФм,ЮвУЧЖдРДздconv4КЭconv5[41]ЕФЖрМЖЪфГіЬиеїНјааСЫздЪЪгІЁЃ
еТНк3.2жаНщЩмЕФЖдПЙЭјТчDОпгагыDCGAN[28]жаЪЙгУЕФЯрЭЌЕФМмЙЙЁЃМгШЈздаХЯЂгГЩфIxЭЈЙ§4ИіОэЛ§ВузЊЗЂ,УПИіОэЛ§ВугывЛИіЙЬЖЈИКаБТЪЮЊ0.2ЕФleaky-ReLUВуёюКЯЁЃзюКѓ,ЗжРрЦїВуЩњГЩЗжРрЪфГі,жИЪОЪфШыЪЧЗёЖдгІгкдДгђЛђФПБъгђ
ЪЕЯжЯИНк
ЮвУЧдкЪЕЯжжаЪЙгУСЫPyTorchЩюЖШбЇЯАПђМм[27]ЁЃЫљгаЕФЪЕбщЖМЪЧдкЕЅИіNVIDIA 1080TIЯдПЈЩЯЭъГЩЕФ,ФкДцЮЊ11 GBЁЃГ§СЫ3.2НкжаЬсЕНЕФЖдПЙХаБ№ЦїЭт,ЮвУЧЕФФЃаЭЪЧЪЙгУЫцЛњЬнЖШЯТНЕгХЛЏЦї[1]бЕСЗЕФ,бЇЯАТЪЮЊ2.5 ЁС 10?4,ЖЏСПЮЊ0.9,ШЈжЕЫЅМѕЮЊ10?4ЁЃЮвУЧЪЙгУбЇЯАЫйТЪЮЊ10?4ЕФAdamгХЛЏЦї[19]РДбЕСЗМјБ№ЦїЁЃЮЊСЫАВХХбЇЯАЫйТЪ,ЮвУЧзёб[2]жаЬсЕНЕФЖрЯюЪНЭЫЛ№ГЬађЁЃ
ьиКЭЖдПЙадЫ№ЪЇЕФШЈживђзг:ЮЊLentЩшжУШЈжи,бЕСЗМЏЕФадФмЬсЙЉСЫживЊЕФжИБъЁЃЕБІЫentНЯДѓЪБ,ьиЯТНЕЙ§Пь,ФЃаЭЧПСвЦЋЯђгкЩйЪ§РрЁЃЕБІЫentбЁШЁдквЛЖЈЗЖЮЇФкЪБ,адФмНЯКУ,ЖдОЋЖШжЕВЛУєИаЁЃвђДЫ,ЮоТлЭјТчЛЙЪЧЪ§ОнМЏ,ЮвУЧЖдЫљгаЕФЪЕбщЖМЪЙгУЯрЭЌЕФІЫent = 0.001ЁЃЖдгк(9)жаЕФжиСПІЫadv,вВгаРрЫЦЕФТлЕуЁЃЮвУЧдкЫљгаЪЕбщжаЖМШЗЖЈІЫadv= 0.001ЁЃ
4.2.НсЙћ
ЮвУЧНЋетаЉЗНЗЈЕФЪЕбщНсЙћгыВЛЭЌЕФЛљЯпНјааБШНЯЁЃЮвУЧЕФФЃаЭдкСНИіUDAЛљзМжаЪЕЯжСЫзюЯШНјЕФадФмЁЃдкНгЯТРДЕФФкШнжа,ЮвУЧеЙЪОСЫЮвУЧЕФЗНЗЈдкВЛЭЌЩшжУЯТЕФВЛЭЌааЮЊ,МДбЕСЗМЏКЭЛљДЁcnnЁЃ
GTA5ЁњCityscapes
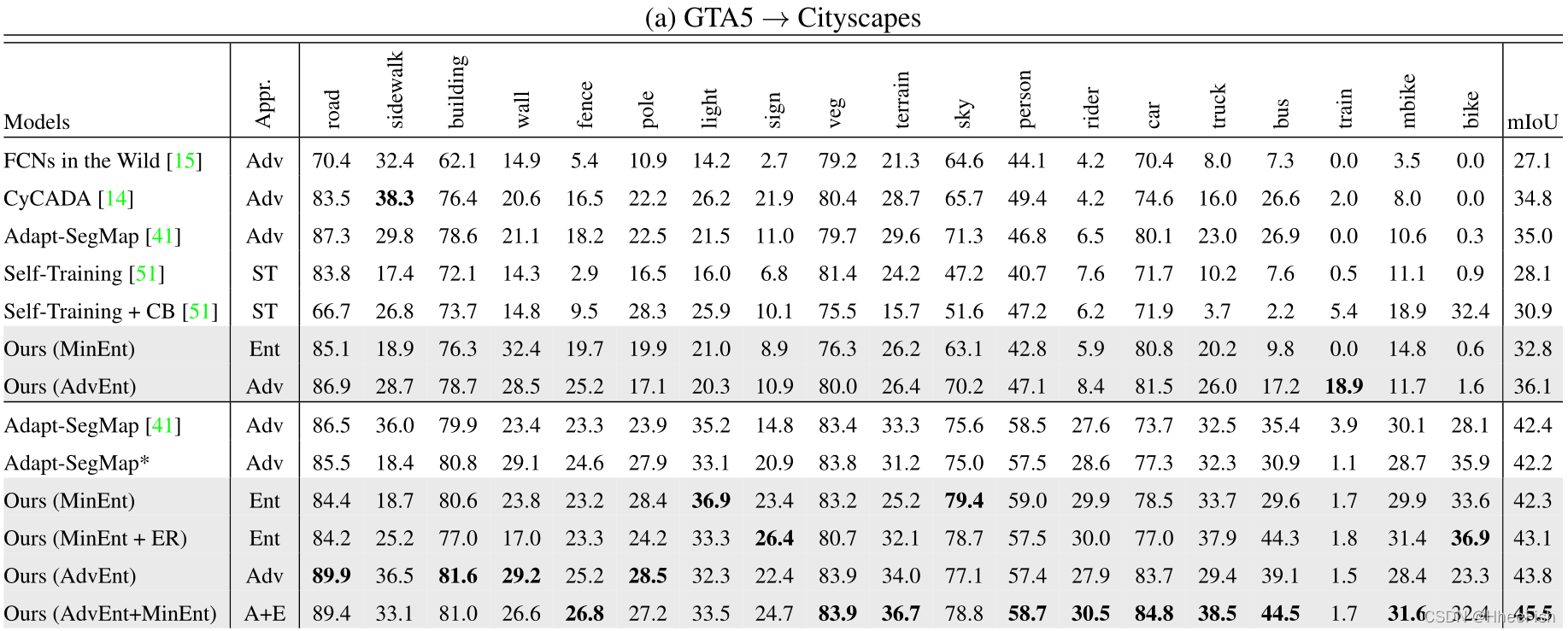
ЮвУЧдкБэ1жаБЈИцСЫCityscapesбщжЄМЏЩЯЕФmIoU(%)гявхЗжИюадФмЁЃЮвУЧЕФЕквЛжжжБНгьизюаЁЛЏЗНЗЈ,дкБэ1-aжаГЦЮЊMinEnt,дкЛљгкVGG-16КЭresnet -101ЕФcnnЩЯЖМЪЕЯжСЫгызюЯШНјЕФЛљЯпЯрЕБЕФадФмЁЃдкУЛгаКЭгаРрБ№ЦНКт[51]ЕФЧщПіЯТ,MinEntБШздЮвбЕСЗ(ST)ЗНЗЈБэЯжИќКУЁЃгы[41]ЯрБШ,Лљгкresnet -101ЕФMinEntЯдЪОГіРрЫЦЕФНсЙћ,ЕЋУЛгаВЩгУМјБ№ЦїЭјТчЕФбЕСЗЁЃьиЫ№ЪЇЕФЧсПЊЯњЪЙЕУбЕСЗЪБМфДѓДѓМѕЩйЁЃЮвУЧЕФьиЗНЗЈЕФСэвЛИігХЕуЪЧвзгкбЕСЗЁЃЪТЪЕЩЯ,бЕСЗЖдПЙЭјТчЭЈГЃБЛШЯЮЊЪЧвЛЯюРЇФбЕФШЮЮё,вђЮЊЫќВЛЮШЖЈЁЃЮвУЧЙлВьЕНвЛИіИќЮШЖЈЕФааЮЊбЕСЗФЃаЭгыьиЫ№ЪЇЁЃ
гаШЄЕФЪЧ,ЮвУЧЗЂЯждкФГаЉЧщПіЯТ,жЛгадквЛЖЈЗЖЮЇФкгІгУьиЫ№ЪЇаЇЙћзюКУЁЃетжжЯжЯѓЪЧЭЈЙ§Лљгкresnet -101ЕФФЃаЭЙлВтЕНЕФЁЃЪТЪЕЩЯ,ЭЈЙ§бЕСЗьижЕдкУПИіФПБъбљБОЧА30%ЕФЯёЫи,ЮвУЧПЩвдЕУЕНвЛИіИќКУЕФФЃаЭЁЃИУФЃаЭдкБэ1-aжаГЦЮЊMinEnt+ERЁЃЮвУЧдкGTA5ЁњCityscapesЩшжУжаЪЙгУетвЛВпТдЛёЕУСЫ43.1%ЕФmIoUЁЃИќЖрЯИНкМћЕк4.3НкЁЃ
ЮвУЧЕФЕкЖўжжЗНЗЈЪЙгУМгШЈздаХЯЂПеМфЩЯЕФЖдПЙбЕСЗ,МДAdvEnt,дкСНИіЛљДЁЭјТчЩЯЯдЪОГіЖдЛљЯпЕФГжајИФЩЦЁЃвЛАуРДЫЕ,AdvEntЕФЙЄзїаЇЙћБШMinEntКУЁЃдкGTA5ЁњCityscapesUDAЩшжУжа,AdvEntДяЕНСЫзюЯШНјЕФmIoU 43.8ЁЃетаЉНсЙћжЄЪЕСЫЮвУЧЫљШЯЮЊЕФНсЙЙЪЪгІживЊадЁЃЪЙгУЛљгкvgg -16ЕФЭјТч,гыжБНгьизюаЁЛЏЯрБШ,МгШЈздаХЯЂПеМфЕФздЪЪгІДјРДСЫ+3.3% mIoUЕФИФНјЁЃЖдгкЛљгкresnet101ЕФЭјТч,ИФНјНЯаЁ,МД+1.5% mIoUЁЃЮвУЧЭЦВт,гЩгкGTA5гявхВМОжгыCityscapesжаЕФгявхВМОжЗЧГЃЯрЫЦ,вђДЫResNet-101ЕШОпгаИпШнСПCNNЛљДЁЕФЗжИюЭјТчFФмЙЛДгдДбљБОЕФМрЖНжабЇЯАЕНвЛаЉПеМфЯШбщЁЃЖдгкЯёVGG-16етбљЕФЕЭШнСПЛљДЁФЃаЭ,дкНсЙЙЛЏПеМфЩЯНјааЖюЭтЕФе§дђЛЏгыЖдПЙбЕСЗЪЧИќгавцЕФЁЃ
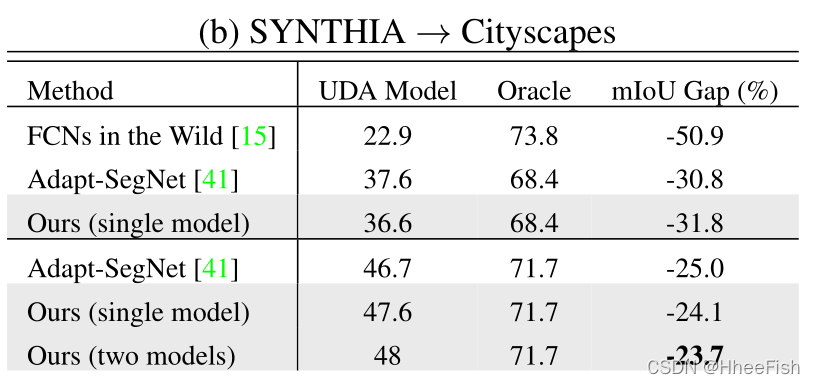
ЭЈЙ§НсКЯMinEntКЭAdvEntСНИіФЃаЭЕФНсЙћ,ЮвУЧЙлВьЕНгыЕЅИіФЃаЭЕФНсЙћЯрБШ,адФмгаСЫЯрЕБДѓЕФЬсЩ§ЁЃИУзщКЯдкCityscapesбщжЄМЏЩЯЪЕЯжСЫ45.5%ЕФmIoUЁЃСНИіФЃаЭбЇЯАЕНЕФаХЯЂЪЧЛЅВЙЕФЁЃЪТЪЕЩЯ,ЫфШЛьиЫ№ЪЇЛсГЭЗЃЖРСЂЯёЫиМЖЕФдЄВт,ЕЋЖдПЙадЫ№ЪЇИќЖрЕизїгУгкЭМЯёМЖ,МДГЁОАЭиЦЫЁЃгы[41]РрЫЦ,ЮЊСЫгыЦфЫћUDAЗНЗЈНјааИќгавтвхЕФБШНЯ,дкБэ2-aжа,ЮвУЧеЙЪОСЫUDAФЃаЭгыoracleжЎМфЕФадФмВюОр,МДдкCityscapesбЕСЗМЏЩЯНгЪмШЋУцМрЖНЕФФЃаЭЁЃгыЭЈЙ§ЦфЫћЗНЗЈбЕСЗЕФФЃаЭЯрБШ,ЮвУЧЕФЕЅвЛКЭМЏГЩФЃаЭгыoracleЕФmIoUВюОрИќаЁЁЃ

дкЭМ3жа,ЮвУЧеЙЪОСЫЮвУЧФЃаЭЕФвЛаЉЖЈадНсЙћЁЃдкУЛгагђздЪЪгІЕФЧщПіЯТ,НідкдДМрПиЩЯбЕСЗЕФФЃаЭЛсВњЩњгадыЩљЕФЗжЖЮдЄВтвдМАИпьиМЄЛю,дкФГаЉРр(ШчЁАbuildingЁБКЭЁАcarЁБ)ЩЯгаЩйЪ§Р§ЭтЁЃОЁЙмШчДЫ,ШдШЛДцдкаэЖрЭъШЋДэЮѓЕФздаХдЄВт(ЕЭьи)ЁЃСэвЛЗНУц,ЮвУЧЕФФЃаЭФмЙЛдкИпжУаХЖШЯТВњЩње§ШЗЕФдЄВтЁЃЮвУЧЙлВьЕН,змЬхЖјбд,гыMinEntФЃаЭЯрБШ,AdvEntФЃаЭЪЕЯжСЫИќЕЭЕФдЄВтьиЁЃ
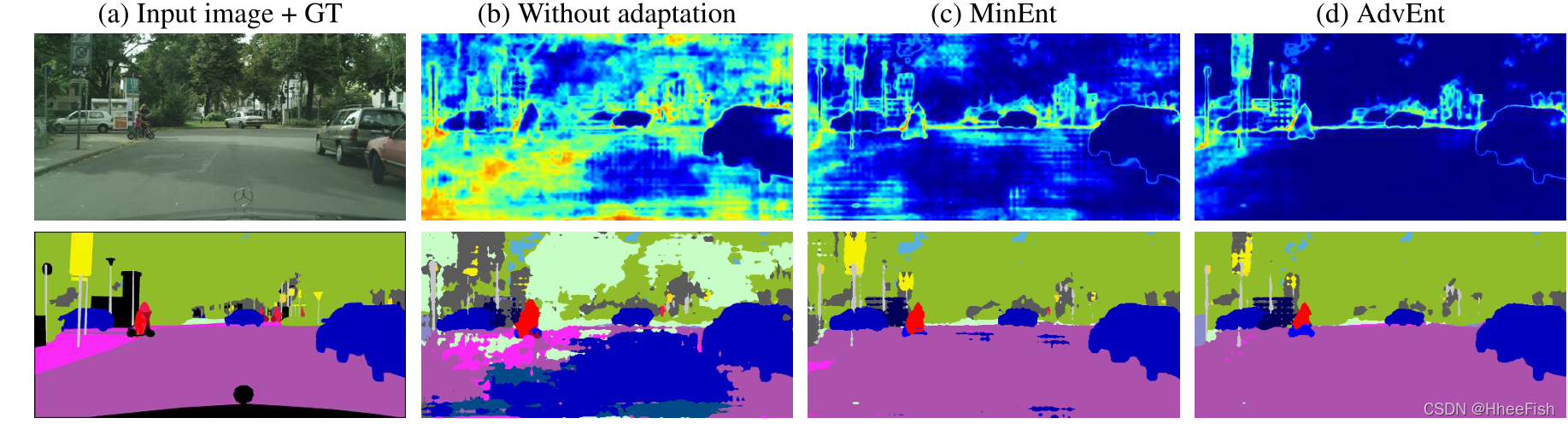
ЭМ3: GTA5жаЕФЖЈадНсЙћЁњCityscapesЩшжУЁЃСа(a)ЯдЪОСЫЪфШыЭМЯёКЭЯргІЕФгявхЧаЗжЁЃСа(b)ЁЂ(c)КЭ(d)ЯдЪОСЫЗжИюНсЙћ(ЕзВП)вдМАВЛЭЌЗНЗЈЩњГЩЕФдЄВтьиЭМ(ЖЅВП)ЁЃзюКУгУВЪЩЋРДЙлПДЁЃ
SYNTHIAЁњCityscapes
Бэ1-bЯдЪОСЫГЧЪаОАЙлбщжЄМЏЕФ16РрКЭ13РрзгМЏЕФНсЙћЁЃЮвУЧзЂвтЕН,гыGTA5КЭCityscapesжаЕФГЁОАЭМЯёЯрБШ,SYNTHIAжаЕФГЁОАЭМЯёКИЧСЫИќЖрВЛЭЌЕФЪгЕуЁЃетЕМжТСЫЮвУЧЕФЗНЗЈЕФВЛЭЌааЮЊЁЃ
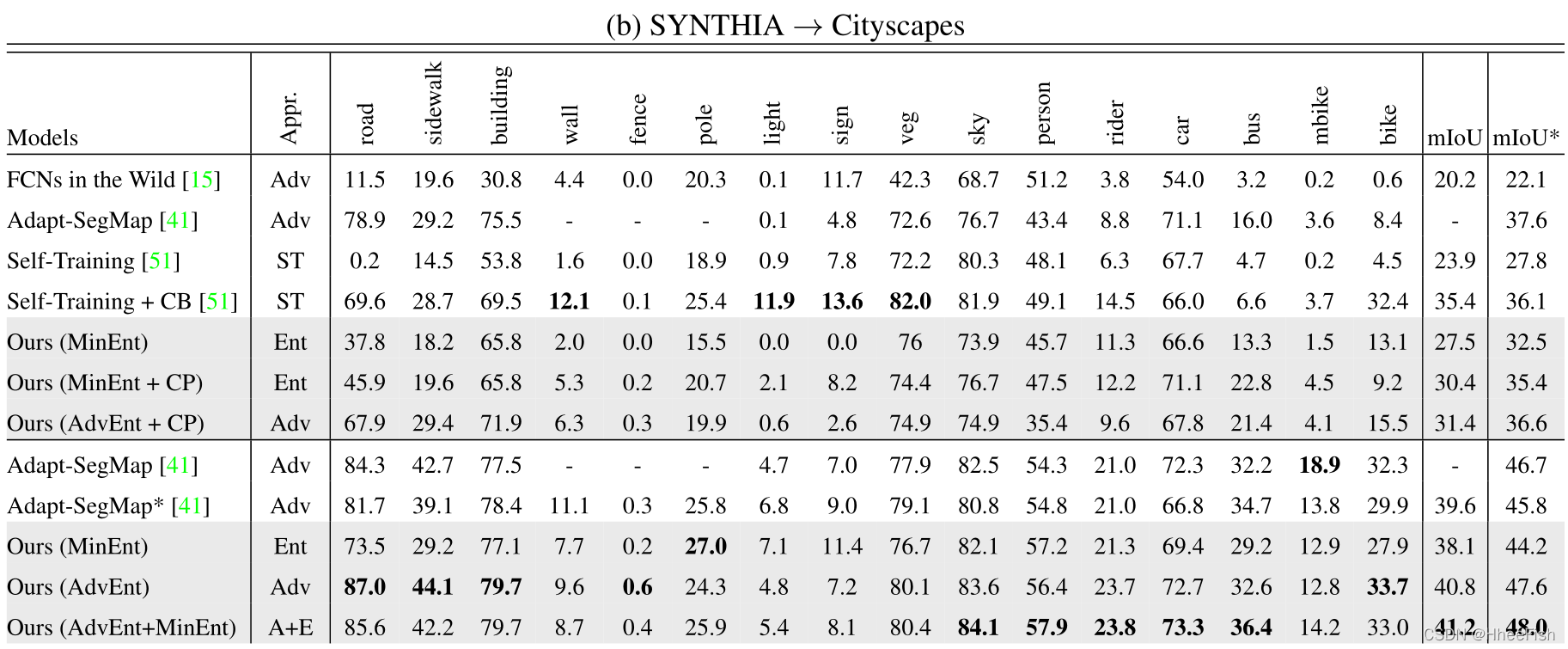
дкЛљгкVGG-16ЕФЭјТчЩЯ,MinEntФЃаЭЯдЪОГігызюаТЗНЗЈЯрЕБЕФНсЙћЁЃгыздбЕСЗ[51]ЯрБШ,ЮвУЧЕФФЃаЭдк16РрКЭ13РрзгМЏЩЯЗжБ№ДяЕН+3.6%КЭ+4.7%ЁЃШЛЖј,гыРрБ№ЦНКтздЮвбЕСЗЕШИќЧПЕФЛљЯпЯрБШ,ЮвУЧЙлВьЕНРрБ№ЁАЕРТЗЁБЯджјЯТНЕЁЃЮвУЧШЯЮЊетЪЧгЩгкSYNTHIAКЭCityscapesжЎМфЕФОоДѓВМОжВюОрЁЃЮЊСЫНтОіетИіЮЪЬт,ЮвУЧв§ШыСЫдДгђЕФРрБ№еМБШЯШбщжЊЪЖ,ШчЕк3.3НкЫљЪіЁЃЭЈЙ§ЪЙгУРрБ№БШТЪЯШбщдМЪјФПБъВњГіЗжВМ,ШчБэ1bжаЕФCPЫљЪО,ЮвУЧдк16РрКЭ13РрзгМЏЩЯНЋMinEntЬсИпСЫ+2.9%mIoUЁЃЭЈЙ§ЖдПЙадбЕСЗ,ЮвУЧгавЛИіЖюЭтЕФдіГЄ1%ЁЃдкЛљгкResNet-101ЕФЭјТчЩЯ,AdvEntФЃаЭЪЕЯжСЫзюЯШНјЕФадФмЁЃгы[41]ЕФдйбЕСЗФЃаЭ(МДAdapt SegMap*)ЯрБШ,ИУФЃаЭЕФГіЯжНЋ16РрКЭ13РрзгМЏЕФmIoUsЗжБ№ЬсИпСЫ+1.2%КЭ+1.8%ЁЃгыЩЯЪіGTA5НсЙћвЛжТ,дкSYNTHIAЩЯбЕСЗЕФСНИіФЃаЭMinEntКЭAdvEntЕФМЏКЯдк16РрКЭ13РрзгМЏЩЯЗжБ№ДяЕН41.2%КЭ48.0%ЕФзюМбmIoUЁЃИљОнБэ2-b,ЮвУЧЕФФЃаЭгыoracleЕФmIoUВюОрзюаЁЁЃ
4.3.ЬжТл
Ек4.2НкжаЕФЪЕбщНсЙћбщжЄСЫЮвУЧЗНЗЈЕФгХЪЦЁЃЮЊСЫНјвЛВНЭЦЖЏМЈаЇ,ЮвУЧЬсГіСЫСНжжВЛЭЌЕФЗНЗЈРДЙцЗЖСНжжЬиЖЈЛЗОГЯТЕФХрбЕЁЃБОНкЬжТлЮвУЧЕФЪЕбщбЁдёВЂНтЪЭЦфБГКѓЕФжБОѕЁЃ
GTA5ЁњCityscapes:дкЬиЖЈЕФьиЗЖЮЇФкбЕСЗ
дкДЫЩшжУжа,ЮвУЧЙлВьЕНЪЙгУЛљгкResNet-101ЕФЭјТчЕФФЃаЭЭкОђЕФадФмПЩвдЭЈЙ§дкЬиЖЈЗЖЮЇФкОпгаьижЕЕФФПБъЯёЫиЩЯНјаабЕСЗРДЬсИпЁЃгаШЄЕФЪЧ,зюКУЕФMinEntФЃаЭЪЧдкУПИіФПБъбљБОЕФЧА30%зюИпьиЯёЫиЩЯбЕСЗЕФ,БШЦеЭЈФЃаЭдіМгСЫ0.8%ЕФmIoUЁЃЮвУЧзЂвтЕН,ИпьиЯёЫиЪЧЁАзюШнвзЛьЯ§ЁБЕФЯёЫи,вВОЭЪЧЫЕ,ЗжИюФЃаЭдкЖрИіРржЎМфЪЧВЛШЗЖЈЕФЁЃвЛИідвђЪЧЛљгкResNet-101ЕФФЃаЭдкетжжЬиЖЈЕФЛЗОГЯТОпгаСМКУЕФЭЈгУадЁЃвђДЫ,дкЁАзюСюШЫРЇЛѓЁБЕФдЄВтжа,гаЯрЕБЪ§СПЕФдЄВтЪЧе§ШЗЕФ,ЕЋЁАжУаХЖШНЯЕЭЁБЁЃзюаЁЛЏетбљвЛИіМЏКЯЩЯЕФьиЫ№ЪЇШдШЛЛсЭЦЖЏФЃаЭГЏзХРэЯыЕФЗНЯђЗЂеЙЁЃШЛЖј,етжжМйЩшВЂВЛЪЪгУгкЛљгкVGG-16ЕФФЃаЭЁЃ
SYNTHIAЁњCityscapes:ЪЙгУРреМБШТЪЯШбщжЊЪЖ
ШчЧАЫљЪі,SYNTHIAЕФВМОжКЭЪгНЧгыГЧЪаОАЙлCityscapesУїЯдВЛЭЌЁЃетжжВювьПЩФмЛсЖдФГаЉРрдьГЩЗЧГЃдуИтЕФдЄВт,ШЛКѓЭЈЙ§зюаЁЛЏьиЛђНЋЦфгУзїздЮвбЕСЗжаЕФБъМЧДњРэРДНјвЛВНЙФРјетжждЄВтЁЃвђДЫ,ЫќПЩФмЕМжТЧПСвЕФРрЦЋВю,ЛђепдкМЋЖЫЧщПіЯТ,дкФПБъгђжаЭъШЋШБЩйФГаЉРрЁЃдкЧАУцЬэМгРрБШТЪПЩвдЙФРјЫљгаРрЕФДцдк,ДгЖјгажњгкБмУтДЫРрЭЫЛЏНтЁЃШчЕкНкЫљЪіЁЃ3.3,ЮвУЧЪЙгУІЬРДЗХПэдДРрБШгХЯШМЖ,Р§ШчІЬ=0БэЪОЮогХЯШМЖ,ЖјІЬ=1БэЪОЧПжЦжДааОЋШЗЕФРрБШгХЯШМЖЁЃІЬ=1ВЂВЛРэЯы,вђЮЊетвтЮЖзХУПИіФПБъгГЯёЖМгІИУзёбдДгђЕФРрБШТЪЁЃЮвУЧбЁдёІЬ=0.5вдЪЙФПБъРрБШТЪгыдДРрБШТЪТдгаВЛЭЌЁЃ
**UDAдкФПБъМьВтжаЕФгІгУ **
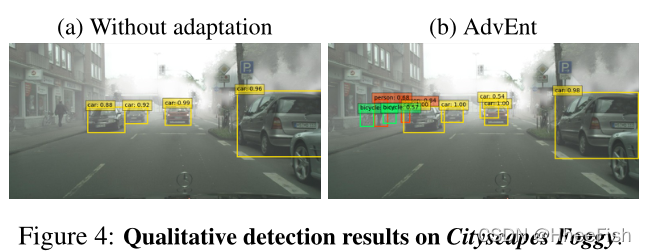
ЫљЬсГіЕФЛљгкьиЕФЗНЗЈВЛНіЯогкгявхЗжИю,ЖјЧвПЩвдгІгУгкUDAЕФЦфЫћЪЖБ№ШЮЮё,ШчФПБъМьВтЁЃЮвУЧдкUDAФПБъМьВтзАжУCityscapesжаНјааСЫЪЕбщCityscapesЁњCityscapes Foggy,гы[3]жаЕФЯрЫЦЁЃжБНгНЋьиЫ№ЪЇКЭЖдПЙадЫ№ЪЇгІгУгкЯжгаМьВтМмЙЙSSD-300[22],гыНідкдДЩЯбЕСЗЕФЛљЯпФЃаЭЯрБШ,ЯджјЬсИпСЫМьВтадФмЁЃОЭЦНОљОЋЖШ(mAP)Жјбд,гы14.7%ЕФЛљЯпадФмЯрБШ,MinEntКЭAdvEntФЃаЭЕФmAPЗжБ№ЮЊ16.9%КЭ26.2%ЁЃдк[3]жа,зїепБЈИцСЫ27.6%mAPЕФадФмЩдКУ,ЪЙгУИќПьЕФRCNN[29],етЪЧвЛжжБШЮвУЧИќИДдгЕФМьВтЬхЯЕНсЙЙЁЃЮвУЧзЂвтЕН,ЮвУЧЕФМьВтЯЕЭГдкНЯЕЭЗжБцТЪ(МД300ЁС300)ЕФЭМЯёЩЯНјааСЫбЕСЗКЭВтЪдЁЃОЁЙмДцдкетаЉВЛРћвђЫи,ЮвУЧЖдЛљЯпЕФИФЩЦ(+11.5%ЪЙгУAdvEntЕиЭМ)Дѓгк[3]жаБЈИцЕФИФЩЦ(+8.8%)ЁЃетбљвЛИіГѕВНЕФНсЙћБэУїСЫЛљгкьиЕФЗНЗЈдкUDAЩЯНјааМьВтЕФПЩФмадЁЃБэ3БЈИцСЫУПРрIoU,ЭМ4ЯдЪОСЫГЧЪаОАЙлЮэЕФЖЈадНсЙћЁЃ 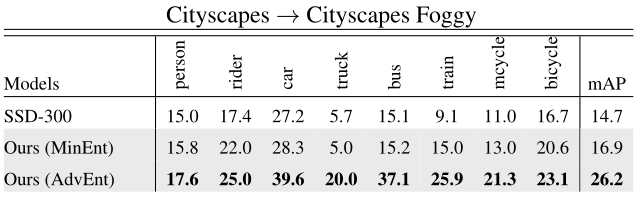
5.НсТл
дкетЯюЙЄзїжа,ЮвУЧЬсГіСЫСНжжЛЅВЙЕФЛљгкьиЕФгявхЗжИюЗНЗЈЁЃЮвУЧЕФФЃаЭдкСНИіОпгаЬєеНадЕФЁАКЯГЩЈC>ецЪЕЁБЛљзМЩЯДяЕНСЫзюЯШНјЫЎЦНЁЃСНИіФЃаЭЕФМЏГЩНјвЛВНЬсИпСЫадФмЁЃдкгУгкФПБъМьВтЕФUDAЩЯ,ЮвУЧеЙЪОСЫвЛИігаЯЃЭћЕФНсЙћ,ВЂЧвЯраХЪЙгУИќНЁзГЕФМьВтМмЙЙПЩвдЛёЕУИќКУЕФадФмЁЃ
ВЮПМЮФЯз
[1] L. Bottou. Large-scale machine learning with stochastic gradient descent. In COMPSTAT. 2010. 5
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. PAMI, 2018. 1, 5
[3] Y. Chen, W. Li, C. Sakaridis, D. Dai, and L. Van Gool. Domain adaptive faster R-CNN for object detection in the wild. In CVPR, 2018. 8
[4] Y. Chen, W. Li, and L. Van Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In CVPR, 2018. 2
[5] Y.-H. Chen, W.-Y. Chen, Y.-T. Chen, B.-C. Tsai, Y.-C. F. Wang, and M. Sun. No more discrimination: Cross city adaptation of road scene segmenters. In ICCV, 2017. 2
[6] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The Cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 5
[7] G. Csurka. Domain adaptation for visual applications: A comprehensive survey. Springer. 2
[8] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. CARLA: An open urban driving simulator. In CoRL, 2017. 2
[9] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The Pascal visual object classes challenge: A retrospective. IJCV, 2015. 5
[10] Y. Ganin and V. Lempitsky. Unsupervised domain adaptation by backpropagation. In ICML, 2015. 1, 2
[11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014. 3, 4
[12] Y. Grandvalet and Y. Bengio. Semi-supervised learning by entropy minimization. In NIPS, 2005. 3
[13] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 5
[14] J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. Efros, and T. Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In ICML, 2018. 1, 2, 5, 6, 7
[15] J. Hoffman, D. Wang, F. Yu, and T. Darrell. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 1, 2, 5, 6, 7
[16] W. Hong, Z. Wang, M. Yang, and J. Yuan. Conditional generative adversarial network for structured domain adaptation. In CVPR, 2018. 2
[17] H. Jain, J. Zepeda, P. PЈІrez, and R. Gribonval. Subic: A supervised, structured binary code for image search. In ICCV, 2017. 3
[18] H. Jain, J. Zepeda, P. PЈІrez, and R. Gribonval. Learning a complete image indexing pipeline. In CVPR, 2018. 3
[19] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2015. 5
[20] S. Laine and T. Aila. Temporal ensembling for semisupervised learning. arXiv preprint arXiv:1610.02242, 2016. 3
[21] D.-H. Lee. Pseudo-label: The simple and efficient semisupervised learning method for deep neural networks. In ICML Workshop, 2013. 3
[22] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg. SSD: single shot multibox detector. In ECCV, 2016. 8
[23] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 1
[24] M. Long, Y. Cao, J. Wang, and M. I. Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015. 1, 2
[25] M. Long, H. Zhu, J. Wang, and M. I. Jordan. Unsupervised domain adaptation with residual transfer networks. In NIPS, 2016. 1, 2, 3
[26] Z. Murez, S. Kolouri, D. Kriegman, R. Ramamoorthi, and K. Kim. Image to image translation for domain adaptation. In CVPR, 2018. 3
[27] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in PyTorch. In NIPS Workshop, 2017. 5
[28] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. 5
[29] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 8
[30] S. R. Richter, V. Vineet, S. Roth, and V. Koltun. Playing for data: Ground truth from computer games. In ECCV, 2016. 1, 2, 5
[31] G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, 2016. 1, 2, 5
[32] K. Saito, Y. Ushiku, T. Harada, and K. Saenko. Adversarial dropout regularization. In ICLR, 2018. 1, 2
[33] K. Saito, K. Watanabe, Y. Ushiku, and T. Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, 2018. 2
[34] S. Sankaranarayanan, Y. Balaji, A. Jain, S. Nam Lim, and R. Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In CVPR, 2018. 1, 2
[35] A. Shafaei, J. J. Little, and M. Schmidt. Play and learn: Using video games to train computer vision models. In BMVC, 2016. 2
[36] C. E. Shannon. A mathematical theory of communication. Bell system technical journal, 1948. 3
[37] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 5
[38] J. T. Springenberg. Unsupervised and semi-supervised learning with categorical generative adversarial networks. ICLR, 2016. 2, 3
[39] A. Tarvainen and H. Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semisupervised deep learning results. In NIPS, 2017. 3
[40] M. Tribus. Thermostatics and thermodynamics. van Nostrand, 1970. 4
[41] Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, 2018. 2, 4, 5, 6, 7
[42] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017. 1, 2
[43] Z. Wu, X. Han, Y.-L. Lin, M. Gokhan Uzunbas, T. Goldstein, S. Nam Lim, and L. S. Davis. DCAN: Dual channel-wise alignment networks for unsupervised scene adaptation. In ECCV, 2018. 1, 2, 3
[44] H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In CVPR, 2017. 1
[45] Y. Zhang, P. David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, 2017. 3
[46] Y. Zhang, Z. Qiu, T. Yao, D. Liu, and T. Mei. Fully convolutional adaptation networks for semantic segmentation. In CVPR, 2018. 3
[47] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In CVPR, 2017. 1
[48] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In ICCV, 2017. 2
[49] X. Zhu. Semi-supervised learning literature survey. Technical Report 1530, Computer Sciences, University of Wisconsin-Madison, 2005. 2
[50] X. Zhu, H. Zhou, C. Yang, J. Shi, and D. Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In ECCV, September 2018. 3
[51] Y. Zou, Z. Yu, B. V. Kumar, and J. Wang. Unsupervised domain adaptation for semantic segmentation via classbalanced self-training. In ECCV, 2018. 1, 2, 3, 4, 5, 6, 7