从2020年10月的ViT,到2021年3月的SwinT,到2021年7月的FocalT,Vison Transformer的论文可谓是百花齐放,我希望通过这篇笔记,来简单的梳理一下各种Vison Transformer的论文,从它解决什么问题,实现什么目的,采用什么方法,实现什么效果几个角度来进行分析。
1. AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ViT)
时间:2020.10
单位:Google Research, Brain Team
会议:ICLR 2021 Oral

?
ViT利用Patch Embedding,将图像转化成了transformer的输入形式,将纯transformer应用于CV领域,实验表明在中等大小的数据集上,ViT性能略弱于resnet,但当其在足够大的数据集上进行充分的预训练,其性能会超过resnet。
1.1Patch Embedding
对于输入的图像,首先进行Patch Embedding,什么是Patch Embedding呢,patch就是将图像均匀切成很多的小块,之后其过程为:
?
?
?
?
?
这里P为patch的边长,D为设置的Patch Embedding维度;第一步就是reshape的过程,也就是??,第二步是一个共享权值的全连接层,也可以用卷积核和步长为P的卷积代替。
1.2Position Embedding
有了Patch Embedding,我们还需要加入Position Embedding,否则无论以什么顺序输入都会得到相同的结果,Position Embedding可以是一个可学习的1-D向量,也可以是固定的相对位置编码。
1.3Class Token
ViT加入了Class Token,为可训练的1-D向量,与所有的patch计算attention,最后使用这个向量进行分类。
1.4Multi-head self-attention (MSA)
计算attention的核心,其公式为,网上讲的很多了就不展开了:
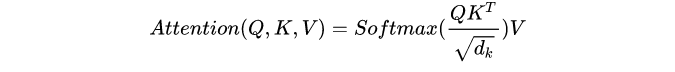
1.5 MLP
全连接层,特征维度变化为:
2.Training data-efficient image transformers & distillation through attention
时间:2020.12
单位:Facebook AI
会议:ICML2021
ViT需要超大数据集+强大计算资源+超长时间的训练才能取得SOTA的性能,这篇论文通过调整训练策略,采用模型蒸馏的方法,整体网络和ViT相同,在ImageNet上8GPU训练3天就可以取得超过ViT的性能。

?
2.1 Ditillation token
相比于ViT,在输入中加入了一个distillation token,与其他token计算attention,class token是与真实标签计算Loss,distillation token是与蒸馏的软/硬标签计算Loss。
2.2 Soft distillation/Hard-label distillation
本文提出了两种蒸馏方法,第一种为软蒸馏,公式为:

其中第一项为class token与真实标签计算交叉熵损失,第二项为计算distillation token和教师模型输出的KL散度(相对熵),即让distillation token去拟合教师模型的输出向量。λ和τ为比例系数和蒸馏温度系数。
第二种为硬蒸馏,公式为:
 ?
?
其中第一项与上式相同,第二项为计算distillation token和教师模型输出的argmax值的交叉熵损失,即让distillation token去拟合教师模型输出所得到的onehot向量。
3.Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
时间:2021.2
单位:南京大学,香港大学
会议:ICCV2021
ViT固定patch的大小为16*16,对于图片分类这类不需要密集预测的任务,可以使用较大的patch,但对于目标检测和分割任务,则需要更加细粒度的特征,但减小patch的分辨率又会大大增加计算slef-attention的计算量,了解决这一问题,PVT应运而生,使用更小的patch(4*4和2*2),通过引入类似CNN的金字塔结构来逐步减少patch的数量,使用patial-reduction attention (SRA)替换multi-head attention (MHA)来减小计算量。

?
3.1 Patch embedding
与ViT选取16*16的patch不同,对于输入图像选取4*4的patch,在每个stage前选取2*2的patch,这意味着不同stage的patch数量不同,数量为是上一层的1/4。类似于cnn,可以理解为每个patch的感受野是上一层的四倍。
3.2 Patial-reduction attention (SRA)
虽然通过在每一层前将patch数量降低为1/4,但计算量仍很大,本文又提出了Patial-reduction attention 减少了计算attention时的k和v的数量,将计算量降低为?。

?
可以理解为对这层计算patch embedding,path的大小为R*R,利用这个patch embedding为k和v;也可以理解为与我计算attention不是单独的patch embedding而是R*R个的patch embedding经过线性变化的patch embedding;也可以理解为对这一层进行卷积核为R,步长为R的卷积,得到的大小为(H/R,W/R,C)作为k和v。
4.Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
时间:2021.3
单位:微软亚研院
会议:ICCV2021 Best paper
PVT的同期作品,都是为了进行密集预测任务减少计算量,都引入了CNN的金字塔结构,是什么让他能够获得Best paper呢,留到下一篇再写吧!