�������Ʒ�ģ��(HMM)
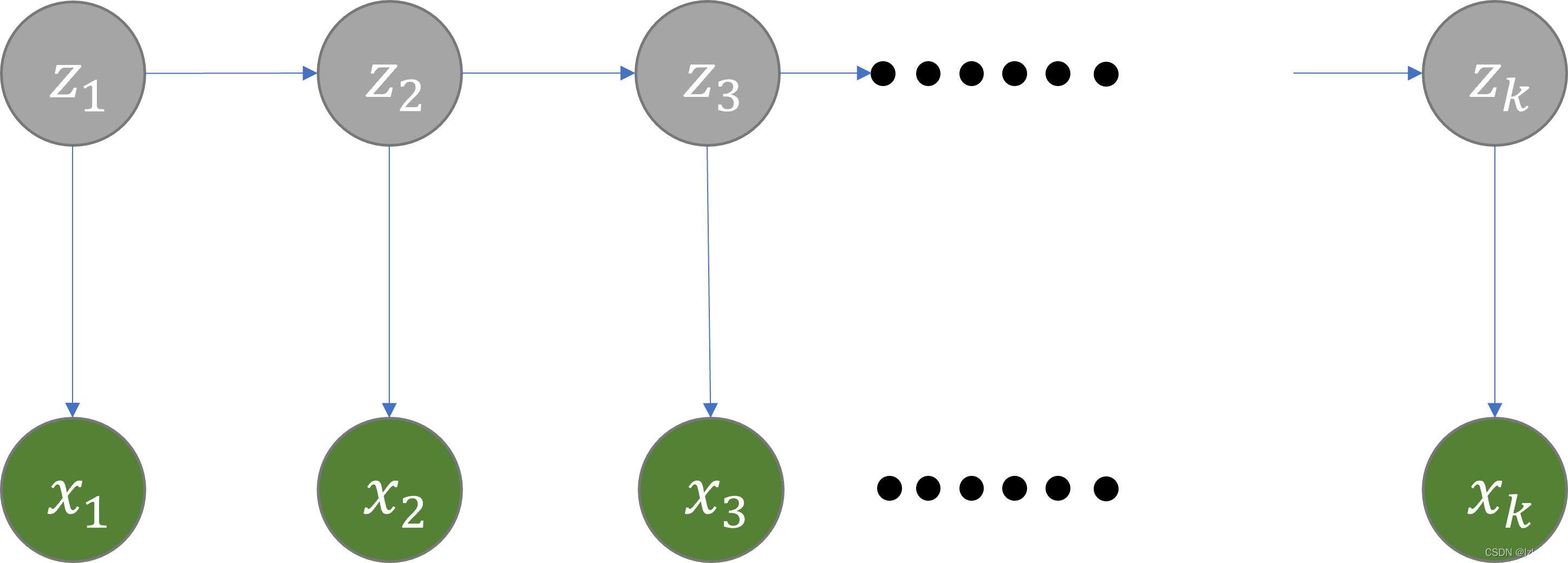
�������ɷ�ģ���ǹ���ʱ��ĸ���ģ��,������һ�����ص������ɷ���������ɲ��ɹ۲��״̬�������,���ɸ���״̬����һ���۲�������۲�������еĹ��̡����ص������ɷ���������ɵ�״̬������,��Ϊ״̬����(state sequence);ÿ��״̬����һ���۲�,���ɴ˲����Ĺ۲���������,��Ϊ�۲�����(observation sequence)�����е�ÿһ��λ���ֿ��Կ�����һ��ʱ�̡�
����ʽģ��vs�б�ʽģ��
��������:��֪���� x x x,���ǩ y y y,����Ҫ����ʵ���Ͼ����� p ( Y �O X ) p(Y|X) p(Y�OX)
����ʽģ��
����ʽģ���Ƕ����ϸ��� p ( x , y ) p(x, y) p(x,y)���н�ģ,���ǿ������п��ܵı�ǩ y y y,ѡ�� p ( x , y ) p(x,y) p(x,y)?������Ϊ�����
�Ƚϳ���������ʽģ����:���ر�Ҷ˹���������Ʒ�ģ�͵�
�б�ʽģ��
�б�ʽģ���Ƕ��������� p ( y �O x ) p(y|x) p(y�Ox)���н�ģ,��������֪��������ͨ��ͳ�ƻ����õ���������,ѡ�� p ( y �O x ) p(y|x) p(y�Ox)������Ϊ�����
�Ƚϳ������б�ʽģ����:���ع顢�����������
�������ɷ�ģ����һ������ʽ��ģ��,��ÿ�θ����۲�����,���ǿ������еı������ y y y����� p ( x , y ) p(x, y) p(x,y),�ҵ�ʹ p ( x , y ) p(x,y) p(x,y)���� y y y?
�������HMM��������
HMM�IJ���
HMMģ�����������,�� �� = ( �� , A , B ) \theta=(\pi,A,B) ��=(��,A,B)
���� �� \pi ��
���� �� \pi ����һ��һά������ ( �� 1 , �� 2 . . . �� n ) (\pi_{1},\pi_2...\pi_n) (��1?,��2?...��n?),ÿ��Ԫ�ش�������״̬ i i i���������е�һ��λ�õĸ��ʡ��Դ���Ԥ��Ϊ��, �� \pi ���ͱ�ʾ���ʡ����ʡ����ݴʡ��������ھ��ӿ�ͷ�ĸ��ʡ�
����A
���� A A AҲ��transition probability matrix,Ҳ����״̬ת�Ƹ��ʾ�������ÿһ��Ԫ�� A i j A_{ij} Aij?��ʾ��״̬ i i iת�Ƶ�״̬ j j j�ĸ��ʡ�
����B
���� B B BҲ����emission probability matrix,Ҳ�������ɸ��ʾ�������ÿһ��Ԫ�� B i j B_{ij} Bij?��ʾ״̬ i i i���ɹ۲�ֵ j j j�ĸ��ʡ�
����,�����ص����HMM�е���������,����ÿһ����������ϸ̽�֡�
HMM��������
HMMҪ�����������������:
- Inference:����֪ģ�Ͳ��� �� \theta ���۲����� x x x��ǰ����,������� p ( z k �O x , �� ) p(z_k|x,\theta) p(zk?�Ox,��)��
- Learning:��֪�۲����� x x x,��HMMģ�Ͳ��� �� = ( �� , A , B ) \theta=(\pi,A,B) ��=(��,A,B)
- Decoding:��֪ģ�Ͳ��� �� \theta ���۲����� x x x,�����ŵı������ z z z
Inference
���Ƚ���Inference����,Ҳ��������֪ģ�Ͳ��� �� \theta ��?????�۲����� x x x?????��ǰ����,������� p ( z k �O x , �� ) p(z_k|x,\theta) p(zk?�Ox,��)???????����ֱ��ķ�����ö�����п��ܵ�״̬����,�ٽ��м���,����Ȼ������Ӷ���ָ�������,����ȡ�������������ʹ�ʽ, p ( z k �O x , �� ) = p ( z k , x �O �� ) p ( x �O �� ) p(z_k|x,\theta)=\frac{p(z_k,x|\theta)}{p(x|\theta)} p(zk?�Ox,��)=p(x�O��)p(zk?,x�O��)????,Ҳ����˵ p ( z k �O x , �� ) �� p ( z k , x �O �� ) p(z_k|x,\theta)\propto p(z_k,x|\theta) p(zk?�Ox,��)��p(zk?,x�O��)???���� p ( z k , x ) = p ( x 1 : k , z k ) p ( x k + 1 : n �O z k , x 1 : k ) p(z_k,x)=p(x_{1:k},z_k)p(x_{k+1:n}|z_k,x_{1:k}) p(zk?,x)=p(x1:k?,zk?)p(xk+1:n?�Ozk?,x1:k?)??�����,���ǽ���������Ҫ�㷨�������һ����,��Forward��Backward�㷨,�������㷨�ı��ʶ��Ƕ�̬�滮(DP)��
ǰ���㷨(Forward Algorithm)
ǰ���㷨�������
p
(
x
1
:
k
,
z
k
�O
��
)
p(x_{1:k},z_k|\theta)
p(x1:k?,zk?�O��)??������,���dz����ҵ����ƹ�ϵ
p
(
x
1
:
k
,
z
k
�O
��
)
=
C
?
p
(
x
1
:
k
?
1
,
z
k
?
1
�O
��
)
p(x_{1:k},z_k|\theta)=C*p(x_{1:k-1},z_{k-1}|\theta)
p(x1:k?,zk?�O��)=C?p(x1:k?1?,zk?1?�O��)
�����
C
C
C������Ҫ�ҵ�һ��ʽ�ӡ�������Կ�����һ��
z
k
?
1
z_{k-1}
zk?1?��,������ǿ��Գ�������
z
k
?
1
z_{k-1}
zk?1?��������Ե��,��
p
(
x
1
:
k
,
z
k
�O
��
)
=
��
z
k
?
1
p
(
z
k
?
1
,
z
k
,
x
1
:
k
)
p(x_{1:k},z_k|\theta)=\sum_{z_{k-1}}{p(z_{k-1},z_k,x_{1:k})}
p(x1:k?,zk?�O��)=zk?1?��?p(zk?1?,zk?,x1:k?)
�������Ƕ�ʽ�ӽ���һ����ֵõ�
��
z
k
?
1
p
(
z
k
?
1
,
z
k
,
x
1
:
k
)
=
��
z
k
?
1
p
(
z
k
?
1
,
z
k
,
x
1
:
k
?
1
,
x
k
)
\sum_{z_{k-1}}p(z_{k-1},z_k,x_{1:k})=\sum_{z_{k-1}}p(z_{k-1},z_k,x_{1:k-1},x_k)
zk?1?��?p(zk?1?,zk?,x1:k?)=zk?1?��?p(zk?1?,zk?,x1:k?1?,xk?)
�� z k ? 1 p ( z k ? 1 , z k , x 1 : k ? 1 , x k ) = �� z k ? 1 p ( x 1 : k ? 1 , z k ? 1 ) p ( z k �O x 1 : k ? 1 , z k ? 1 ) p ( x k �O z k , z k ? 1 , x 1 : k ? 1 ) \sum_{z_{k-1}}p(z_{k-1},z_k,x_{1:k-1},x_k)=\sum_{z_{k-1}}p(x_{1:k-1},z_{k-1})p(z_k|x_{1:k-1},z_{k-1})p(x_k|z_k,z_{k-1},x_{1:k-1}) zk?1?��?p(zk?1?,zk?,x1:k?1?,xk?)=zk?1?��?p(x1:k?1?,zk?1?)p(zk?�Ox1:k?1?,zk?1?)p(xk?�Ozk?,zk?1?,x1:k?1?)
����D-Separation����֪����ʽ���Ը�дΪ
��
z
k
?
1
p
(
x
1
:
k
?
1
,
z
k
?
1
)
p
(
z
k
�O
x
1
:
k
?
1
,
z
k
?
1
)
p
(
x
k
�O
z
k
,
z
k
?
1
,
x
1
:
k
?
1
)
=
��
z
k
?
1
p
(
x
1
:
k
?
1
,
z
k
?
1
)
p
(
z
k
�O
z
k
?
1
)
p
(
x
k
�O
z
k
)
\sum_{z_{k-1}}p(x_{1:k-1},z_{k-1})p(z_k|x_{1:k-1},z_{k-1})p(x_k|z_k,z_{k-1},x_{1:k-1})=\sum_{z_{k-1}}p(x_{1:k-1},z_{k-1})p(z_k|z_{k-1})p(x_k|z_k)
zk?1?��?p(x1:k?1?,zk?1?)p(zk?�Ox1:k?1?,zk?1?)p(xk?�Ozk?,zk?1?,x1:k?1?)=zk?1?��?p(x1:k?1?,zk?1?)p(zk?�Ozk?1?)p(xk?�Ozk?)
����,���dzɹ����ҵ���������ƹ�ϵ������
��
t
(
i
)
\alpha_{t}(i)
��t?(i)?��ʾ
1
1
1��
t
t
t?ʱ��״̬
z
t
=
i
z_t=i
zt?=i?��ǰ�����,���ƹ�ʽΪ
��
t
(
j
)
=
[
��
i
N
��
t
?
1
(
i
)
A
i
j
]
B
j
,
x
k
\alpha_t{(j)}=[\sum_{i}^{N}{\alpha_{t-1}(i)A_{ij}}]B_{j,x_k}
��t?(j)=[i��N?��t?1?(i)Aij?]Bj,xk??
��ʼ״̬Ϊ
��
1
(
i
)
=
��
i
B
i
,
x
1
\alpha_1(i)=\pi_iB_{i,x_1}
��1?(i)=��i?Bi,x1??
�����㷨(Backward Algorithm)
�����㷨Ҫ�������
p
(
x
k
+
1
:
n
�O
z
k
,
��
)
p(x_{k+1:n}|z_k,\theta)
p(xk+1:n?�Ozk?,��)?,���Ƶ�������ǰ���㷨һ��,ֻ�ǵ��Ƶķ���ͬ��
p
(
x
k
+
1
:
n
�O
z
k
)
=
��
z
k
+
1
p
(
x
k
+
1
:
n
,
z
k
+
1
�O
z
k
)
p(x_{k+1:n}|z_k)=\sum_{z_{k+1}}p(x_{k+1:n},z_{k+1}|z_k)
p(xk+1:n?�Ozk?)=zk+1?��?p(xk+1:n?,zk+1?�Ozk?)
�� z k + 1 p ( x k + 1 : n , z k + 1 �O z k ) = �� z k + 1 p ( z k + 1 �O z k ) p ( x k + 1 �O z k , z k + 1 ) p ( x k + 2 : n �O z k , z k + 1 , x k + 1 ) \sum_{z_{k+1}}p(x_{k+1:n},z_{k+1}|z_k)=\sum_{z_{k+1}}p(z_{k+1}|z_k)p(x_{k+1}|z_k,z_{k+1})p(x_{k+2:n}|z_k,z_{k+1},x_{k+1}) zk+1?��?p(xk+1:n?,zk+1?�Ozk?)=zk+1?��?p(zk+1?�Ozk?)p(xk+1?�Ozk?,zk+1?)p(xk+2:n?�Ozk?,zk+1?,xk+1?)
�� z k + 1 p ( z k + 1 �O z k ) p ( x k + 1 �O z k , z k + 1 ) p ( x k + 2 : n �O z k , z k + 1 , x k + 1 ) = �� z k + 1 p ( z k + 1 �O z k ) p ( x k + 1 �O z k + 1 ) p ( x k + 2 : n �O z k + 1 ) \sum_{z_{k+1}}p(z_{k+1}|z_k)p(x_{k+1}|z_k,z_{k+1})p(x_{k+2:n}|z_k,z_{k+1},x_{k+1})=\sum_{z_{k+1}}p(z_{k+1}|z_k)p(x_{k+1}|z_{k+1})p(x_{k+2:n}|z_{k+1}) zk+1?��?p(zk+1?�Ozk?)p(xk+1?�Ozk?,zk+1?)p(xk+2:n?�Ozk?,zk+1?,xk+1?)=zk+1?��?p(zk+1?�Ozk?)p(xk+1?�Ozk+1?)p(xk+2:n?�Ozk+1?)
����
��
t
(
i
)
\beta_{t}(i)
��t?(i)??��ʾ
t
t
t?��
n
n
n?,
t
t
t?ʱ��״̬Ϊ
z
t
=
i
z_t=i
zt?=i??�ĺ������,���ƹ�ʽΪ
��
t
(
i
)
=
��
j
n
A
i
j
B
j
,
x
t
+
1
��
t
+
1
(
j
)
\beta_t(i)=\sum_{j}^n{A_{ij}B_{j,x_{t+1}}\beta_{t+1}(j)}
��t?(i)=j��n?Aij?Bj,xt+1??��t+1?(j)
��ʼ״̬Ϊ
��
T
(
i
)
=
1
\beta_T(i)=1
��T?(i)=1
����ǰ���㷨�ͺ����㷨,���ǵ�
p
(
z
k
�O
x
)
p(z_k|x)
p(zk?�Ox)�Ϳ��Խ��м���,֮ǰ���ǵõ�
p
(
z
k
�O
x
)
��
p
(
x
1
:
k
,
z
k
)
p
(
x
k
+
1
:
n
�O
z
k
,
x
1
:
k
)
p(z_k|x)\propto p(x_{1:k},z_k)p(x_{k+1:n}|z_k,x_{1:k})
p(zk?�Ox)��p(x1:k?,zk?)p(xk+1:n?�Ozk?,x1:k?),����ǰ������㷨,
p
(
z
k
=
i
�O
x
)
��
��
k
(
i
)
��
k
(
i
)
p(z_k=i|x)\propto \alpha_k(i)\beta_k(i)
p(zk?=i�Ox)����k?(i)��k?(i)?�������Ǹ���,����������һ����һ��,Ҳ����
p
(
z
k
=
i
�O
x
)
=
��
k
(
i
)
��
k
(
i
)
��
j
��
k
(
j
)
��
k
(
j
)
p(z_k=i|x)=\frac{\alpha_k(i)\beta_k(i)}{\sum_{j}\alpha_k(j)\beta_k(j)}
p(zk?=i�Ox)=��j?��k?(j)��k?(j)��k?(i)��k?(i)?
���ǰ����������
��
k
(
i
)
\gamma_k(i)
��k?(i)����ʾ
����ǰ�������ͺ�������,���ǿ�����һ������
��
k
(
i
,
j
)
=
p
(
z
k
=
i
,
z
k
+
1
=
j
�O
x
,
��
)
=
p
(
z
k
=
i
,
z
k
+
1
=
j
,
x
�O
��
)
p
(
x
�O
��
)
\xi_k(i,j)=p(z_k=i,z_{k+1}=j|x,\theta)=\frac{p(z_k=i,z_{k+1}=j,x|\theta)}{p(x|\theta)}
��k?(i,j)=p(zk?=i,zk+1?=j�Ox,��)=p(x�O��)p(zk?=i,zk+1?=j,x�O��)?
p ( x �O �� ) = �� i n �� j n p ( z k = i , z k + 1 = j , x �O �� ) p(x|\theta)=\sum_{i}^n\sum_{j}^np(z_k=i,z_{k+1}=j,x|\theta) p(x�O��)=i��n?j��n?p(zk?=i,zk+1?=j,x�O��)
p ( z k = i , z k + 1 = j , x �O �� ) = �� k ( i ) A i j B j , x k + 1 �� k + 1 ( j ) p(z_k=i,z_{k+1}=j,x|\theta)=\alpha_k(i)A_{ij}B_{j,x_{k+1}}\beta_{k+1}(j) p(zk?=i,zk+1?=j,x�O��)=��k?(i)Aij?Bj,xk+1??��k+1?(j)
����,
��
k
(
i
,
j
)
=
��
k
(
i
)
A
i
j
B
j
,
x
k
+
1
��
k
+
1
(
j
)
��
i
n
��
j
n
��
k
(
i
)
A
i
j
B
j
,
x
k
+
1
��
k
+
1
(
j
)
\xi_k(i,j)=\frac{\alpha_k(i)A_{ij}B_{j,x_{k+1}}\beta_{k+1}(j)}{\sum_{i}^n\sum_{j}^n\alpha_k(i)A_{ij}B_{j,x_{k+1}}\beta_{k+1}(j)}
��k?(i,j)=��in?��jn?��k?(i)Aij?Bj,xk+1??��k+1?(j)��k?(i)Aij?Bj,xk+1??��k+1?(j)?
Learning
ѧϰ����Ҳ���Dz����������⡣����״̬ z z z������֪�����(complete case),����ֻ��Ҫ�����ݼ�����ͳ�Ƽ���,������N-gramģ�͡�������HMM��,���ǵ�״̬������δ֪��,��Ҳ����Ϊʲô�������������Ʒ�ģ�͡������������(incomplete case),���Dz��õķ�������EM�㷨
EM�㷨
EM�㷨ȫ�ƽ���Expectation Maximization algorithm,ר��������⺬�� l a t e n t latent latent v a r i a b l e variable variable?��ģ�Ͳ�����EM�㷨����������:
- ����ģ�Ͳ����ij�ʼֵ �� 0 \theta_0 ��0?
- E��:��ģ�Ͳ�����ʼֵ��Ϊ��֪��,���ݵ� i i i�ε�����ģ�Ͳ��� �� i \theta_i ��i?��� i + 1 i+1 i+1��״̬���� z z z?������
- M��:��ʹ��E���������������ģ�Ͳ��� �� i + 1 \theta_{i+1} ��i+1??��Ϊ�� i + 1 i+1 i+1�ε�����ģ�Ͳ�������ֵ
- ����,ֱ������
���� �� \pi �����
��
=
(
��
1
,
��
2
.
.
.
.
.
.
��
n
)
\pi=(\pi_1,\pi_2......\pi_n)
��=(��1?,��2?......��n?)?��ʾÿһ��״̬��Ϊ��ʼ״̬�ĸ��ʡ���Inference�������ǿ������
p
(
z
k
�O
x
)
p(z_k|x)
p(zk?�Ox)?,���ǿ���������ʵ�����
��
\pi
��?��һ������ֵ����������EM�㷨���ɡ��������㹫ʽΪ
��
i
(
n
+
1
)
=
��
1
(
i
)
\pi_i^{(n+1)}=\gamma_1(i)
��i(n+1)?=��1?(i)
����A���
����
A
A
A��ת�Ƹ��ʾ���,ÿ��Ԫ��
A
i
j
A_{ij}
Aij?�ĸ��ʱ���Ϊ
p
(
z
k
=
i
,
z
k
+
1
=
j
�O
x
)
p(z_k=i,z_{k+1}=j|x)
p(zk?=i,zk+1?=j�Ox)�����������������֮ǰ�����
��
k
(
i
,
j
)
\xi_k(i,j)
��k?(i,j)?���������Ҳ���Ա�������һ������ֵ,���ǿ���ʹ��EM�㷨���������㹫ʽΪ
A
i
j
(
n
+
1
)
=
��
t
=
1
T
?
1
��
t
(
i
,
j
)
��
t
=
1
T
?
1
��
t
(
i
)
A_{ij}^{(n+1)}=\frac{\sum_{t=1}^{T-1}\xi_t(i,j)}{\sum_{t=1}^{T-1}\gamma_t(i)}
Aij(n+1)?=��t=1T?1?��t?(i)��t=1T?1?��t?(i,j)?
����B���
����B�����ɸ��ʾ���,?ͬ��,�������㹫ʽΪ
B
i
,
x
t
(
n
+
1
)
=
��
t
=
1
,
x
t
=
k
T
��
t
(
i
)
��
t
=
1
T
��
t
(
i
)
B_{i,x_t}^{(n+1)}=\frac{\sum_{t=1,x_t=k}^T\gamma_t(i)}{\sum_{t=1}^T\gamma_t(i)}
Bi,xt?(n+1)?=��t=1T?��t?(i)��t=1,xt?=kT?��t?(i)?

Decoding
Ԥ������Ҳ����Ϊ��������,������֪�۲����к�ģ�Ͳ���,��Ԥ�����ŵı�����С���İ취��ö�ٳ����п��ܵ�״̬����,Ȼ���Ҹ�������,�����Ӷ���Ȼ�Dz��ɽ��ܵġ�
�������Viterbi�㷨��ά�ر��㷨������һ�ֶ�̬�滮�㷨,���ļ���ԭ������ͨ����ͼ������

Viterbi�㷨��ʵ������Ѱ��һ�����ŵ�·��,��ô��HMM������,������һ����������·����
����
��
k
(
i
)
\delta_k(i)
��k?(i)��ʾ����
k
k
kʱ��,
z
k
=
i
z_k=i
zk?=i������·��,���ƹ�ʽ����
��
k
+
1
(
j
)
=
m
a
x
i
=
(
1
,
2
,
3...
n
)
(
��
k
(
i
)
A
i
j
B
i
,
x
k
+
1
)
\delta_{k+1}(j)=max_{i=(1,2,3...n)}(\delta_{k}(i)A_{ij}B_{i,x_{k+1}})
��k+1?(j)=maxi=(1,2,3...n)?(��k?(i)Aij?Bi,xk+1??)
��ʼ����Ϊ
��
1
(
i
)
=
��
i
B
i
,
x
1
\delta_1(i)=\pi_iB_{i,x_1}
��1?(i)=��i?Bi,x1??
�����漰���������,����Ҳ����
��
\delta
��?�����ڶ����ռ�,��ô����ʽΪ
��
k
+
1
(
j
)
=
m
a
x
i
=
(
1
,
2
,
3...
n
)
{
��
k
(
i
)
+
l
o
g
(
A
i
j
)
+
l
o
g
(
B
j
,
x
k
+
1
)
}
\delta_{k+1}(j)=max_{i=(1,2,3...n)}\lbrace\delta_{k}(i)+log(A_{ij}) + log(B_{j,x_{k+1}})\rbrace
��k+1?(j)=maxi=(1,2,3...n)?{��k?(i)+log(Aij?)+log(Bj,xk+1??)}
�� 1 ( i ) = l o g �� i + l o g B i , x 1 \delta_1(i)=log\pi_i+logB_{i,x_1} ��1?(i)=log��i?+logBi,x1??
�㷨���Ӷ��� O ( n 2 m ) O(n^2m) O(n2m)?
��
��
\delta
��?�����ڶ����ռ�,��ô����ʽΪ
��
k
+
1
(
j
)
=
m
a
x
i
=
(
1
,
2
,
3...
n
)
{
��
k
(
i
)
+
l
o
g
(
A
i
j
)
+
l
o
g
(
B
j
,
x
k
+
1
)
}
\delta_{k+1}(j)=max_{i=(1,2,3...n)}\lbrace\delta_{k}(i)+log(A_{ij}) + log(B_{j,x_{k+1}})\rbrace
��k+1?(j)=maxi=(1,2,3...n)?{��k?(i)+log(Aij?)+log(Bj,xk+1??)}
�� 1 ( i ) = l o g �� i + l o g B i , x 1 \delta_1(i)=log\pi_i+logB_{i,x_1} ��1?(i)=log��i?+logBi,x1??
�㷨���Ӷ��� O ( n 2 m ) O(n^2m) O(n2m)?
����,HMMģ�͵����ݾͽ�������,���ģ�͵�ԭ����Ϊ����,Ҫ�ڸ�ϰ��