????????文本匹配任务也是nlp领域中一个非常常见的任务了,也是在文本检索、文本召回中需要用到的关键技术了。
比较经典的文本匹配模型有dssm这种一条样本匹配多个候选集的模型,还有Siamese孪生网络这种双塔模型。这两种模型都可以作为文本匹配任务的baseline首先尝试。下面简单介绍一下这两个模型的原理。
一、DSSM模型
DSSM深度语义匹配模型原理很简单:获取搜索引擎中的用户搜索query和doc的海量曝光和点击日志数据,训练阶段分别用复杂的深度学习网络构建query侧特征的query embedding和doc侧特征的doc embedding,线上infer时通过计算两个语义向量的cos距离来表示语义相似度,最终获得语义相似模型。这个模型既可以获得语句的低维语义向量表达sentence embedding,还可以预测两句话的语义相似度。
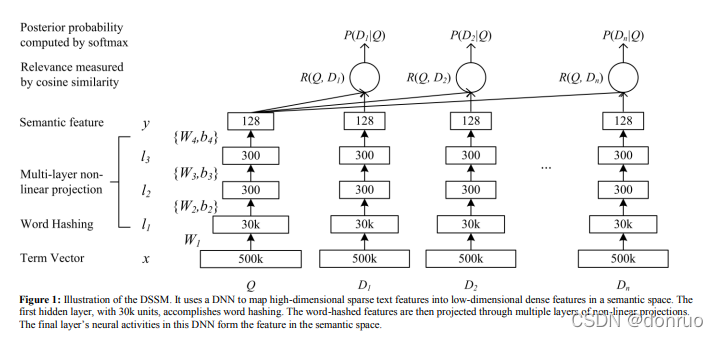
????????如上图所示,输入是一个集合{query, D1,D2,...Dn},候选集一般为一个正样本和多个负样本构成。输入后经过几个网络层,分别为词哈希、非线性变换、语义特征等几个网络层变为稠密的句子向量,然后再通过余弦相似度计算相似数值,最后通过softmax层计算预测结果值。
? ? ? ? 实现代码如下所示:
class DSSM(tf.keras.Model):
'''
dssm模型
'''
def __init__(self, config, vocab_size, word_vectors):
self.config = config
self.vocab_size = vocab_size
self.word_vectors = word_vectors
# 定义输入
query = tf.keras.layers.Input(shape=(None,), dtype=tf.int64, name='input_x_ids')
sim_query = tf.keras.layers.Input(shape=(None,), dtype=tf.int64, name='input_y_ids')
# embedding层
class GatherLayer(tf.keras.layers.Layer):
def __init__(self, config, vocab_size, word_vectors):
super(GatherLayer, self).__init__()
self.config = config
self.vocab_size = vocab_size
self.word_vectors = word_vectors
def build(self, input_shape):
with tf.name_scope('embedding'):
if not self.config['use_word2vec']:
self.embedding_w = tf.Variable(tf.keras.initializers.glorot_normal()(
shape=[self.vocab_size, self.config['embedding_size']],
dtype=tf.float32), trainable=True, name='embedding_w')
else:
self.embedding_w = tf.Variable(tf.cast(self.word_vectors, tf.float32), trainable=True,
name='embedding_w')
self.build = True
def call(self, indices):
return tf.gather(self.embedding_w, indices, name='embedded_words')
def get_config(self):
config = super(GatherLayer, self).get_config()
return config
# 利用词嵌入矩阵将输入数据转成词向量,shape=[batch_size, seq_len, embedding_size]
query_embedding = GatherLayer(config, vocab_size, word_vectors)(query)
query_embedding = tf.reshape(query_embedding, [self.config['batch_size'], self.config['seq_len']*self.config['embedding_size']])
sim_query_embedding = GatherLayer(config, vocab_size, word_vectors)(sim_query)
sim_query_embedding = tf.reshape(sim_query_embedding, [self.config['batch_size'], self.config['seq_len']*self.config['embedding_size']])
#3层dnn提取特征[300,300,128], 输出为[batch_size, dense_embedding]
for size in self.config['hidden_size']:
query_embedding = tf.keras.layers.Dense(size)(query_embedding)
sim_query_embedding = tf.keras.layers.Dense(size)(sim_query_embedding)
#than激活函数
query_embedding = tf.keras.activations.tanh(query_embedding)
sim_query_embedding = tf.keras.activations.tanh(sim_query_embedding)
#cos_similarity余弦相似度[batch_size, similarity]
query_norm = tf.sqrt(tf.reduce_sum(tf.square(query_embedding), axis=-1), name='query_norm')
sim_query_norm = tf.sqrt(tf.reduce_sum(tf.square(sim_query_embedding), axis=-1), name='sim_query_norm')
dot = tf.reduce_sum(tf.multiply(query_embedding, sim_query_embedding), axis=-1)
cos_similarity = tf.divide(dot, (query_norm*sim_query_norm), name='cos_similarity')
self.similarity = cos_similarity
#对于只有一个负样本的情况处理loss,根据阈值确定正负样本
# 预测为正例的概率
cond = (self.similarity > self.config["neg_threshold"])
zeros = tf.zeros_like(self.similarity, dtype=tf.float32)
ones = tf.ones_like(self.similarity, dtype=tf.float32)
# pred_neg_prob = tf.where(cond, tf.square(self.similarity), zeros)
# logits = [[pred_pos_prob[i], pred_neg_prob[i]] for i in range(self.batch_size)]
# cond = (self.similarity > 0.0)
pos = tf.where(cond, tf.square(self.similarity), 1 - tf.square(self.similarity))
neg = tf.where(cond, 1 - tf.square(self.similarity), tf.square(self.similarity))
predictions = [[neg[i], pos[i]] for i in range(self.config['batch_size'])]
self.logits = self.similarity
outputs = dict(logits=self.logits, predictions=predictions)
super(DSSM, self).__init__(inputs=[query, sim_query], outputs=outputs)二、siamese模型
孪生网络顾名思义就是query和doc共享一套网络结构,得到各自的句子embedding,然后计算句子相似度,网络结构可以参考下图:
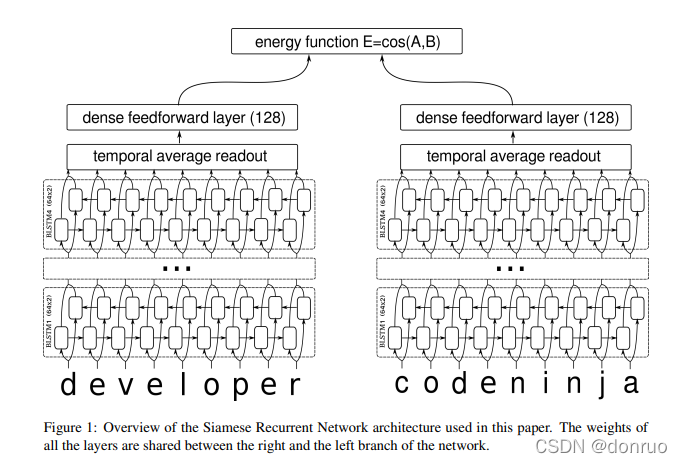
?左边和右边都为rnn的网络结构,但是两个参数是共享的。代码如下:
class Siamese(tf.keras.Model):
'''
dssm模型
'''
def __init__(self, config, vocab_size, word_vectors):
self.config = config
self.vocab_size = vocab_size
self.word_vectors = word_vectors
# 定义输入
query = tf.keras.layers.Input(shape=(None,), dtype=tf.int64, name='input_x_ids')
sim_query = tf.keras.layers.Input(shape=(None,), dtype=tf.int64, name='input_y_ids')
# embedding层
# 利用词嵌入矩阵将输入数据转成词向量,shape=[batch_size, seq_len, embedding_size]
class GatherLayer(tf.keras.layers.Layer):
def __init__(self, config, vocab_size, word_vectors):
super(GatherLayer, self).__init__()
self.config = config
self.vocab_size = vocab_size
self.word_vectors = word_vectors
def build(self, input_shape):
with tf.name_scope('embedding'):
if not self.config['use_word2vec']:
self.embedding_w = tf.Variable(tf.keras.initializers.glorot_normal()(
shape=[self.vocab_size, self.config['embedding_size']],
dtype=tf.float32), trainable=True, name='embedding_w')
else:
self.embedding_w = tf.Variable(tf.cast(self.word_vectors, tf.float32), trainable=True,
name='embedding_w')
self.build = True
def call(self, inputs, **kwargs):
return tf.gather(self.embedding_w, inputs, name='embedded_words')
def get_config(self):
config = super(GatherLayer, self).get_config()
return config
shared_net = tf.keras.Sequential([GatherLayer(config, vocab_size, word_vectors),
shared_lstm_layer(config)])
query_embedding_output = shared_net.predict_step(query)
sim_query_embedding_output = shared_net.predict_step(sim_query)
#余弦函数计算相似度
# cos_similarity余弦相似度[batch_size, similarity]
query_norm = tf.sqrt(tf.reduce_sum(tf.square(query_embedding_output), axis=-1), name='query_norm')
sim_query_norm = tf.sqrt(tf.reduce_sum(tf.square(sim_query_embedding_output), axis=-1), name='sim_query_norm')
dot = tf.reduce_sum(tf.multiply(query_embedding_output, sim_query_embedding_output), axis=-1)
cos_similarity = tf.divide(dot, (query_norm * sim_query_norm), name='cos_similarity')
self.similarity = cos_similarity
# 预测为正例的概率
cond = (self.similarity > self.config["neg_threshold"])
pos = tf.where(cond, tf.square(self.similarity), 1 - tf.square(self.similarity))
neg = tf.where(cond, 1 - tf.square(self.similarity), tf.square(self.similarity))
predictions = [[neg[i], pos[i]] for i in range(self.config['batch_size'])]
self.logits = self.similarity
outputs = dict(logits=self.logits, predictions=predictions)
super(Siamese, self).__init__(inputs=[query, sim_query], outputs=outputs)
class shared_lstm_layer(tf.keras.layers.Layer):
'''
共享lstm层参数
'''
def __init__(self, config):
self.config = config
super(shared_lstm_layer, self).__init__()
def build(self, input_shape):
forward_layer_1 = tf.keras.layers.LSTM(self.config['hidden_size'], dropout=self.config['dropout_rate'],
return_sequences=True)
backward_layer_1 = tf.keras.layers.LSTM(self.config['hidden_size'], dropout=self.config['dropout_rate'],
return_sequences=True, go_backwards=True)
forward_layer_2 = tf.keras.layers.LSTM(self.config['hidden_size'], dropout=self.config['dropout_rate'],
return_sequences=True)
backward_layer_2 = tf.keras.layers.LSTM(self.config['hidden_size'], dropout=self.config['dropout_rate'],
return_sequences=True, go_backwards=True)
self.bilstm_1 = tf.keras.layers.Bidirectional(forward_layer_1, backward_layer=backward_layer_1)
self.bilstm_2 = tf.keras.layers.Bidirectional(forward_layer_2, backward_layer=backward_layer_2)
self.layer_dropout = tf.keras.layers.Dropout(0.4)
self.output_dense = tf.keras.layers.Dense(self.config['output_size'])
super(shared_lstm_layer, self).build(input_shape)
def get_config(self):
config = {}
return config
def call(self, inputs, **kwargs):
query_res_1 = self.bilstm_1(inputs)
query_res_1 = self.layer_dropout(query_res_1)
query_res_2 = self.bilstm_2(query_res_1)
#取时间步的平均值,摊平[batch_size, forward_size+backward_size]
avg_query_embedding = tf.reduce_mean(query_res_2, axis=1)
tmp_query_embedding = tf.reshape(avg_query_embedding, [self.config['batch_size'], self.config['hidden_size']*2])
# 全连接层[batch_size, dense_dim]
query_embedding_output = self.output_dense(tmp_query_embedding)
query_embedding_output = tf.keras.activations.relu(query_embedding_output)
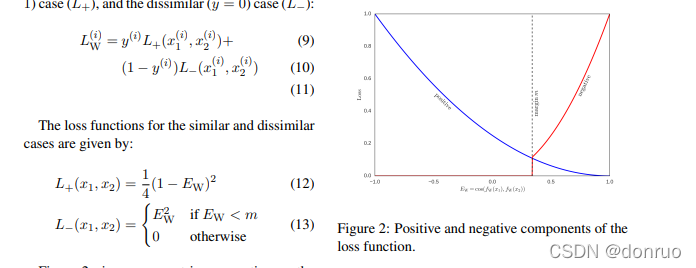
return query_embedding_output上面的代码段实现的其实是双向lstm网络层。此外需要提一下论文中的损失函数是对比损失,
?
从网上其他网友参考可以分析出一下结论
注:从这里的图来看,上面的式子是有误的,EW<mEW<m?应该改成EW>mEW>m。
我们来分析下上面的式子:假设现在是一个正样本,也就是y(i)=1y(i)=1,此时若预测的EWEW接近于1(即预测两个句子很相似),则整体损失很小,此时若预测的EWEW接近于-1(即预测两个句子不相似),则整体损失很大。假设现在是一个负样本,给定m=0.5m=0.5,也就是y(i)=0y(i)=0,此时若预测的EWEW小于mm,则损失为0,若预测的EWEW大于mm,则损失很大。其实这个损失函数可以认为通过调整mm的值,可以控制对句子相似度的苛刻度,mm的值比较大时,会导致两个相似的句子的余弦相似度值是比较高的。
参考文献:
https://aclanthology.org/W16-1617.pdf
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf