ГЕСОааШЫМьВтбЇЯАБЪМЧ
1ЁЂФПБъМьВт&ГЃМћМьВтЭјТч
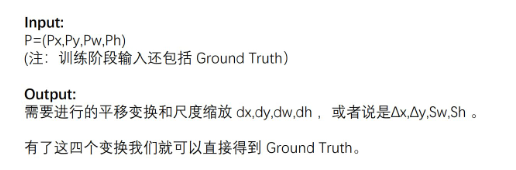
ФПБъМьВт:ЮяЬхЪЖБ№ЪЧвЊЗжБцГіЭМЦЌжагаЪВУДЮяЬх,ЪфШыЪЧЭМЦЌ,ЪфГіЪЧРрБ№БъЧЉКЭИХТЪЁЃЖјФПБъМьВтВЛНівЊМьВтЭМЦЌжагаЪВУДЮяЬх,ЛЙвЊЪфГіЮовьЕФЭтПђ(x,y,width,height)РДЖЈЮЛЮяЬхЕФЮЛжУЁЃ
object detection,ОЭЪЧдкИјЖЈЕФЭМЦЌжаОЋШЗевЕНЮяЬхЫљдкЮЛжУ,ВЂБъзЂГіЮяЬхЕФРрБ№ЁЃ
object detectionвЊНтОіЕФЮЪЬтОЭЪЧЮяЬхдкФФРявдМАЪЧЪВУДЕФећИіСїГЬЮЪЬтЁЃ
ШЛЖј,етИіЮЪЬтПЩВЛЪЧФЧУДШнвзНтОіЕФ,ЮяЬхЕФГпДчБфЛЏЗЖЮЇКмДѓ,АкЗХЮяЬхЕФНЧЖШ,зЫЬЌВЛЖЈ,ЖјЧвПЩвдГіЯждкЭМЦЌЕФШЮКЮЕиЗН,ИќКЮПіЮяЬхЛЙПЩвдЪЧЖрИіРрБ№ЁЃ
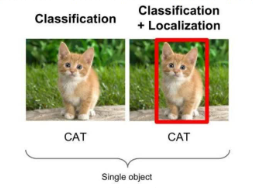
ФПЧАбЇЪѕКЭЙЄвЕНчГіЯжЕФФПБъМьВтЫуЗЈЗжГЩ3Рр:
1.ДЋЭГЕФФПБъМьВтЫуЗЈ:
Cascade + HOG/DPM + Haar/SVMвдМАЩЯЪіЗНЗЈЕФжюЖрИФНјЁЂгХЛЏ;
2.КђбЁЧјгђ/Пђ+ЩюЖШбЇЯАЗжРр:ЭЈЙ§ЬсШЁКђбЁЧјгђ,ВЂЖдЯргІЧјгђНјаавдЩюЖШбЇЯАЗНЗЈЮЊжїЕФ
ЗжРрЕФЗНАИ,Шч:
?R-CNN(Selective Search + CNN + SVM)
?SPP-net(ROI Pooling)
?Fast R-CNN(Selective Search + CNN + ROI)
?Faster R-CNN(RPN + CNN + ROI)
3.ЛљгкЩюЖШбЇЯАЕФЛиЙщЗНЗЈ:YOLO/SSDЕШЗНЗЈ
ЦРМлБъзМ
1ЁЂIOU(Intersection over Union)
IOUЪЧвЛжжВтСПдкЬиЖЈЪ§ОнМЏжаМьВтЯргІЮяЬхзМШЗЖШЕФвЛИіБъзМЁЃ
IoUЪЧвЛИіМђЕЅЕФВтСПБъзМ,жЛвЊЪЧдкЪфГіжаЕУГівЛИідЄВтЗЖЮЇ(bounding box)ЕФШЮЮёЖМПЩвдгУIoUРДНјааВтСПЁЃ
ЮЊСЫПЩвдЪЙIoUгУгкВтСПШЮвтДѓаЁаЮзДЕФЮяЬхМьВт,ЮвУЧашвЊ:
1ЁЂ(ШЫЮЊдкбЕСЗМЏЭМЯёжаБъГівЊМьВтЮяЬхЕФДѓИХЗЖЮЇ)
2ЁЂЮвУЧЕФЫуЗЈЕУГіЕФНсЙћЗЖЮЇ
вВОЭЪЧЫЕ,етИіБъзМгУгкВтСПецЪЕКЭдЄВтжЎМфЕФЯрЙиЖШ,ЯрЙиЖШдНИп,ИУжЕдНИпЁЃ

БШШчЭЈЙ§ЩЯЭМРДРэНтвЛЯТIoUЕФзїгУ,ТЬПђЪЧground-truth bounding box,КьПђЪЧдЄВтжЕ,ЫћУЧСНИіКмЯдШЛЪЧгаВюОрЕФ,гУдЪММгМѕЕФЗНЪНПЯЖЈЪЧБШНЯВЛСЫЕФ,ЮвУЧашвЊгУНЛВЂБШЕФЗНЗЈ,ШчЯТЙЋЪН:

IoUЪЕМЪЩЯОЭЪЧУцЛ§ЕФЯрГ§,НЛМЏ/ВЂМЏ,ОйИіР§зг,IOU=0.53ЖЈвхЮЊbad,IOU=0.76ЖЈвхЮЊnice,IOU=0.98ЖЈвхЮЊprefect(здМКИљОнЪЕМЪЧщПіЖЈвх)

2ЁЂTP TN FP FN
TP TN FP FNРяУцвЛЙВГіЯжСЫ4ИізжФИ,ЗжБ№ЪЧT F P NЁЃ
TЪЧTrue;
FЪЧFalse;
PЪЧPositive;
NЪЧNegativeЁЃ
TP(True Positives)втЫМОЭЪЧБЛЗжЮЊСЫе§бљБО,ЖјЧвЗжЖдСЫЁЃ
TN(True Negatives)
втЫМОЭЪЧБЛЗжЮЊСЫИКбљБО,ЖјЧвЗжЖдСЫ,
FP(False Positives)втЫМОЭЪЧБЛЗжЮЊСЫе§бљБО,ЕЋЪЧЗжДэСЫ(ЪТЪЕЩЯетИібљБОЪЧИКбљБО)ЁЃ
FN(False Negatives)втЫМОЭЪЧБЛЗжЮЊСЫИКбљБО,ЕЋЪЧЗжДэСЫ(ЪТЪЕЩЯетИібљБОЪЧе§бљБО)ЁЃ
дкmAPМЦЫуЕФЙ§ГЬжажївЊгУЕНСЫ,TPЁЂFPЁЂFNетШ§ИіИХФюЁЃ
precision(ОЋШЗЖШ)КЭrecall(ейЛиТЪ)
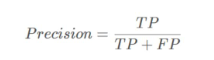
TPЪЧЗжРрЦїШЯЮЊЪЧе§бљБОЖјЧвШЗЪЕЪЧе§бљБОЕФР§зг,FPЪЧЗжРрЦїШЯЮЊЪЧе§бљБОЕЋЪЕМЪЩЯВЛЪЧе§бљБОЕФР§згТ№,precisionвтЫМЪЧЗжРрЦїШЯЮЊЪЧе§РрВЂЧвШЗЪЕЪЧе§РрЕФВПЗжеМЫљгаЗжРрЦїШЯЮЊЪЧе§РрЕФБШР§ЁЃ
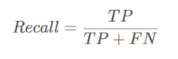
TPЪЧЗжРрЦїШЯЮЊЪЧе§бљБОЖјЧвШЗЪЕЪЧе§бљБОЕФР§зг,FNЪЧЗжРрЦїШЯЮЊЪЧИКбљБОЕЋЪЕМЪЩЯВЛЪЧИКбљБОЕФР§зг,recallвтЫМЪЧЗжРрЦїШЯЮЊЪЧе§РрВЂЧвШЗЪЕЪЧе§РрЕФВПЗжеМЫљгаШЗЪЕЪЧе§РрЕФБШР§ЁЃ
ОЋЖШОЭЪЧевЕУЖд,ейЛиТЪОЭЪЧевЕФШЋ
ЯТЭМДњБэЕФЪЧзМШЗТЪКЭейЛиТЪЕФвЛИігІгУ:

РЖЩЋЕФПђЪЧецЪЕПђЁЃТЬЩЋКЭКьЩЋЕФПђЪЧдЄВтПЙ,ТЬЩЋЕФПђЪЧе§бљБО,КьЩЋЕФПђЪЧИКбљБОЁЃ
вЛАуРДНВ,ЕБдЄВтПђКЭецЪЕПђIOU>=0.5ЪБ,БЛШЯЮЊЪЧе§бљБОЁЃ(0.5ЪЧздМКЩшЖЈЕФ)
БпПђЛиЙщBounding-Box regressionЫуЗЈ(ИќЖргУдкFaster RCNNжа)
ПЩвдПДЕНдЄВтПђКЭецЪЕПђЛЙгаВюОр,дѕУДНтОіетИіЮЪЬтФи,ОЭГіЯжСЫБпПђЛиЙщ

БпПђЛиЙщЪЧЪВУД?
1ЁЂЖдгкДАПквЛАуЪЙгУЫФЮЌЯђСП(x,y,w,h)РДБэЪО,ЗжБ№БэЪОДАПкЕФжааФЕузјБъКЭПэИпЁЃ
2ЁЂКьЩЋЕФПђPДњБэдЪМЕФproposal;
3ЁЂТЬЩЋЕФПђGДњБэФПБъЕФground truth;
ЮвУЧЕФФПБъЪЧбАеввЛжжЙиЯЕЪЙЕУЪфШыдЪМЕФДАПкPОЙ§гГЩфЕУЕНвЛИіИњецЪЕДАПкGИќМгНгНќЕФЛиЙщДАПкG^ЁЃ
Ыљвд,БпПђЛиЙщЕФФПЕФЪЧ:


БпПђЛиЙщдѕУДзі?
БШНЯМђЕЅЕФЫМТЗОЭЪЧ:ЦНвЦ+ГпЖШЫѕЗХ

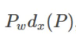
втЮЖзХДгГЄЖШЕЅЮЛзЊЛЛЮЊзјБъЕЅЮЛ

one-stageКЭtwo-stage
two-stage:two-stageЫуЗЈЛсЯШЪЙгУвЛИіЭјТчЩњГЩproposal,Шчselective searchКЭRPNЭјТч,RPNГіЯжКѓ,ssЗНЗЈЛљБООЭБЛо№ЦњСЫЁЃRPNЭјТчНгдкЭМЯёЬиеїЬсШЁЭјТчbackboneКѓ,ЛсЩшжУRPNloss(bbox
regression loss+classification loss)ЖдRPNЭјТчНјаабЕСЗ,RPNЩњГЩЕФproposalдйЫЭЕНКѓУцЕФЭјТчжаНјааИќОЋЯИЕФbbox regressionКЭclassificationЁЃ
**one-stage:**One-stageзЗЧѓЫйЖШЩсЦњСЫtwo-stageМмЙЙ,МДВЛдйЩшжУЕЅЖРЭјТчЩњГЩproposal,ЖјЪЧжБНгдкfeature mapЩЯНјааУмМЏГщбљ,ВњЩњДѓСПЕФЯШбщПђ,ШчYOLOЕФЭјИёЗНЗЈЁЃетаЉЯШбщПђУЛгаОЙ§СНВНДІРэ,ЧвПђЕФГпДчЭљЭљЪЧШЫЮЊЙцЖЈЁЃ
two-stageЫуЗЈжївЊЪЧRCNNЯЕСа,АќРЈRCNN,Fast-RCNN,Faster-RCNNЁЃжЎКѓЕФMask-RCNNШкКЯСЫFaster-RCNNМмЙЙЁЂResNetКЭFPN(Feature Pyramid Networks)backbone,вдМАFCNРяЕФsegmentationЗНЗЈ,дкЭъГЩСЫsegmentationЕФЭЌЪБвВЬсИпСЫdetectionЕФОЋЖШЁЃ
one-stageЫуЗЈзюЕфаЭЕФЪЧYOLO(КѓУцгжИќаТСЫYOLO2,YOLO3),ИУЫуЗЈЫйЖШМЋПьЁЃ
YOLO-You Only Look Once
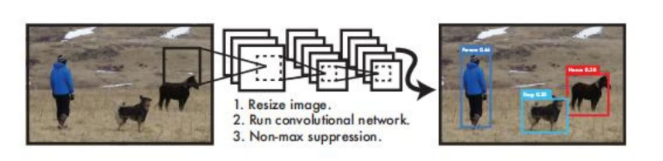
YOLOЫуЗЈЪЕМЪЩЯВЩгУвЛИіЕЅЖРЕФCNNФЃаЭЪЕЯжend-to-endЕФФПБъМьВт:
1ЁЂResizeГЩ448*448,ЭМЦЌЗжИюЕУЕН7 * 7ЭјИё(cell)
2ЁЂCNNЬсШЁЬиеїКЭдЄВт:ОэЛ§ВПЗжИКд№ЬсШЁЬиеї,ШЋСЌНгВПЗжИКд№дЄВтЁЃ
3ЁЂЙ§ТЫBbox(ЭЈЙ§NMS:ЗЧМЋДѓжЕвжжЦЫуЗЈ)

жУаХЖШЪЧжИПђЪєгкФГвЛРрБ№ЕФИХТЪЪЧЖрЩйЁЃ
ЙигкБъЖЈПђ:
ЭјТчЕФЪфГіЪЧS * S*(5*B+C)ЕФвЛИіtensor(S-ГпДч,BБъЖЈПђИіЪ§,C-МьВтРрБ№Ъ§,5-БъЖЈПђаХЯЂ)
ЁЊ5ЗжЮЊ4+1
ЁЊ4ДњБэБъЖЈПђЕФЮЛжУаХЯЂЁЃПђЕФжааФЕу(x,y),ПђЕФИпПэh,w
ЁЊ1ДњБэУПИіБъЖЈПђЕФжУаХЖШвдМАБъЖЈПђЕФзМШЗЖШаХЯЂ

вЛАуЧщПіЯТ,YOLOВЛЛсдЄВтБпНчПђжааФЕФШЗЧазјБъ,ЫќдЄВт:
(1)гыдЄВтФПБъЕФЭјИёЕЅдЊзѓЩЯНЧЯрЙиЕФЦЋвЦ;
(2)ЪЙгУЬиеїЭМЕЅдЊЕФЮЌЖШНјааЙщвЛЛЏЕФЦЋвЦЁЃ
Р§Шч:
вдЩЯЭМЮЊР§ ,ШчЙћжааФЕФдЄВтЪЧ(0.4,0.7),дђжааФдк13*13ЬиеїЭМЩЯЕФзјБъЪЧ(6.4,6.7)(КьЩЋЕЅдЊЕФзѓЩЯНЧзјБъЪЧ(6,6))
ЕЋЪЧШчЙћдЄВтЕФx,yзјБъДѓгк1,БШШч(1.2,0.7)ЁЃФЧУДдЄВтЕФжааФзјБъЪЧ(7.2,6.7)
зЂвт:ИУжааФдкКьЩЋЕЅдЊгвВрЕФЕЅдЊжаЁЃетДђЦЦСЫYOLOБГКѓЕФРэТл,вђЮЊШчЙћЮвУЧМйЩшКьЩЋПђИКд№дЄВтФПБъЙЗ,ФЧУДЙЗЕФжааФБиаыдкКьЩЋЕЅдЊжа,ВЛгІИУдкЫќХдБпЕФЭјИёЕЅдЊжаЁЃ
вђДЫ,ЮЊСЫНтОіетИіЮЪЬт,ЮвУЧЖдЪфГіжДааsigmoidКЏЪ§,НЋЪфГібЙЫѕЕНЧјМф0ЕН1жЎМф,гааЇШЗБЃжааФДІгкжДаадЄВтЕФЭјИёЕЅдЊжаЁЃ
УПИіБъЖЈПђЕФжУаХЖШвдМАБъЖЈПђЕФзМШЗЖШаХЯЂ:
зѓБпДњБэАќКЌетИіБъЖЈПђЕФИёзгРяУцЪЧЗёгаФПБъЁЃга=1,УЛга=0
гвБпДњБэБъЖЈПђЕФзМШЗГЬЖШ,гвБпЕФВПЗжЪЧАбСНИіБъЖЈПђ(вЛИіЪЧground truth,вЛИіЪЧдЄВтЕФБъЖЈПђ)НјаавЛИіIOUВйзї,МДСНИіБъЖЈПђЕФНЛМЏБШВЂМЏ,Ъ§жЕдНДѓ,МДБъЖЈПђжиКЯдНЖр,дНзМШЗЁЃ
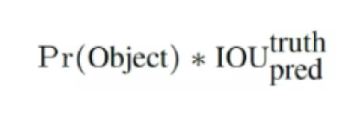
ЮвУЧПЩвдМЦЫуГіИїИіБъЖЈПђЕФРрБ№жУаХЖШ:БэДяЕФЪЧИУБъЖЈПђжаФПБъЪєгкИїИіРрБ№ЕФПЩФмадДѓаЁвдМАБъЖЈПђЦЅХфФПБъЕФКУЛЕЁЃ
УПИіЭјТчдЄВтЕФclassаХЯЂ(БэЪОЕФЪЧУПИіРрБ№ЕФИХТЪ)КЭbounding boxдЄВтЕФconfidenceаХЯЂЯрГЫ,ОЭЕУЕНУПИіbounding boxЕФРрБ№жУаХЖШЁЃ
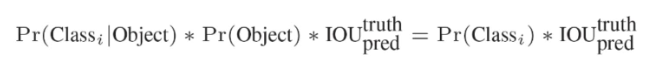
ЪЕМЪЩЯ,етИіЙЋЪНЕФвтвхОЭЪЧ:ЕквЛЯюЪЧУПИіЭјТчдЄВтЕФРрБ№ЕФИХТЪ,МДвЛЙВ20Рр,УПвЛРрЕФИХТЪ;ЕкЖўЯюЪЧМьВтБъЖЈПђЪЧЗёгаФПБъ;ЕкШ§ЯюЪЧМЦЫуIOUЁЃ
ПДвЛЯТећЬхПђЭМ:


ЕНетРя,ОЭЕУЕН7730ЕФЭјИё,жЎЧАЖМЪЧОэЛ§ГиЛЏ,ЛљБОЕФЩёОЭјТчВйзї,ФЧЕУЕН7730ЕФЭјИёЪЧШчКЮНјааМьВтЕФФи,ЮвУЧМЬајЭљЯТПД:


АбЫќПДГЩаЁЪњЬѕ,ЧА10ЪЧСНИіБъЖЈПђЕФx,y,w,hКЭжУаХЖШ,Кѓ20ИіЪЧРрБ№Ъ§

вЛЙВга49Ьѕ,УПЬѕЖМЪЧ30ИіЪ§зж,зщГЩ7730ЕФtensor,НгЯТРДПЊЪММЦЫу:
ЯТЭМжа,ЧА5ИіБъЖЈПђЕФвЛИіжУаХЖШГЫвдКѓУцРЖЬѕЕФРрБ№ЕУЕН20ИіжУаХЖШ,ЕУЕН20Иіclass scores for Bbox 1ЁЃУПИіаЁИёгаСНИіБъЖЈПђ,УПИіБъЖЈПђЛсЕУЕН20ИіЪ§,вЛЙВЕУЕН40ИіЪ§



ЕУЕНУПИіBboxЕФРрБ№жУаХЖШвдКѓ,ЩшжУуажЕ,Й§ТЧЕєЕУЗж(РрБ№жУаХЖШ)ЕЭЕФboxes,ШЛКѓзівЛИіНЕађХХСа(АДееЭЌвЛРрБ№НЕађХХСа,БШШч:ЕквЛДЮЖдЙЗЕФЕУЗжНјааНЕађХХСа,ЕкЖўДЮЖдУЈ,бЛЗ20ДЮ)ЖдБЃСєЕФboxesНјааNMSДІРэ,ЕУЕНзюжеЕФМьВтНсЙћЁЃЯТЭМвдЙЗЮЊР§

зЂвт:ЯТЭМШЁЕУЪЧЩЯЭМЕФвЛКсаа(КьЩЋащЯпПђ)

ЩЯЭМУПвЛИіИёЖМДњБэвЛИіПђ,зюДѓжЕЕФBboxгыБШЫќаЁЕФЗЧ0жЕзїБШНЯIOU,ШЅГ§Шпгр,IOUдННгНќ,ЫЕУїдНШпгр,IOUДѓгквЛЖЈЕФуажЕ,дђЩшЮЊ0,ШЅГ§ТЬЩЋЕФПђ

ЕквЛИіжЕБШНЯЭъ,НгЯТРДЕнЙщ,вдЯТвЛИіЗЧ0жЕЕФBboxзюДѓжЕМЬајБШНЯIOU,ШчЯТЭМЫљЪО

зюже,ЪЃЯТnИіПђ


ЗжЪ§ЮЊ0вВОЭЪЧУЛгаФПБъЕФжБНгЬјЙ§,Дѓгк0ЕФевУПИіBboxЗжЪ§зюДѓЕФ

ШЛКѓОЭПЩвдевЕНе§ШЗЕФПђ

ЕНетвЛВНЦфЪЕжївЊОРњСЫетбљМИВН:АбЭМЯёЭЈЙ§ОэЛ§В№ГЩКУЖрЗн,БШШч7*7,НјааBounding box +жУаХЖШ,ЪЕЯжСЫИХТЪЕиЭМ,зюжеЕУЕНвЛИіПђ

YOLOЕФШБЕу:
(1)YOLOЖдЯрЛЅППЕФКмНќЕФЮяЬх(АЄдквЛЦ№ЧвжаЕуЖМТфдкЭЌвЛИіИёзгЩЯЕФЧщПі),ЛЙгаКмаЁЕФШКЬхМьВтаЇЙћВЛКУ,етЪЧвђЮЊвЛИіЭјИёжажЛдЄВтСЫСНИіПђ,ВЂЧвжЛЪєгквЛРрЁЃ
(2)ВтЪдЭМЯёжа,ЕБЭЌвЛРрЮяЬхГіЯжВЛГЃМћЕФГЄПэБШКЭЦфЫћЧщПіЪЧЗКЛЏФмСІЦЋШѕЁЃ
YOLO2
1ЁЂYOLO2ЪЙгУСЫвЛИіаТЕФЗжРрЭјТчзїЮЊЬиеїЬсШЁВПЗж;
2ЁЂЭјТчЪЙгУНЯЖрЕФ33ОэЛ§КЫ,дкУПвЛДЮГиЛЏВйзїКѓАбЭЈЕРЪ§ЗБЖ;
3ЁЂАб11ЕФОэЛ§КЫжУгк33ЕФОэЛ§КЫжЎМф,гУРДбЙЫѕЬиеї;
4ЁЂЪЙгУbatch normalizationЮШЖЈФЃаЭбЕСЗ,МгЫйЪеСВ;
5ЁЂБЃСєСЫвЛИіshortcutгУгкДцДЂжЎЧАЕФЬиеї;
6ЁЂYOLO2ЯрБШгкYOLO1МгШыСЫЯШбщПђ,зюКѓЪфГіЕФconv_decЕФshapeЮЊ(13,13,425):
(1)1313ЪЧАбећИіЭМЗжЮЊ1313ЕФЭјИёгУгкдЄВтЁЃ
(2)425ПЩвдЗжНтЮЊ(855)ЁЃдк85жа,гУгкYOLO2ГЃгУЕФЪЧCOCOЪ§ОнМЏ,ЦфжаОпга80ИіРр;ЪЃгрЕФ5жИЕФЪЧx,y,w,hКЭжУаХЖШЁЃЁС5втЮЖзХдЄВтНсЙћАќКЌ5ИіПђ,ЗжБ№ЖдгІ5ИіЯШбщПђЁЃ


Dimension Clusters(ЮЌЖШОлРр)
ЪЙгУkmeansОлРрЛёШЁЯШбщПђЕФаХЯЂ
жЎЧАЯШбщПђЖМЪЧЪжЙЄЩшЖЈЕФ,YOLO2ГЂЪдЭГМЦГіИќЗћКЯбљБОжаЖдЯѓГпДчЕФЯШбщПђ,етбљОЭПЩвдМѕЩйЭјТчЮЂЕїЯШбщПђЕНЪЕМЪЮЛжУЕФФбЖШЁЃYOLO2ЕФзіЗЈЪЧЖдбЕСЗМЏжаБъзЂЕФБпПђНјааОлРрЗжЮі,вдбАевОЁПЩФмЦЅХфбљБОЕФБпПђГпДчЁЃ
ОлРрЫуЗЈзюживЊЕФЪЧбЁдёШчКЮМЦЫуСНИіБпПђжЎМфЕФЁАОрРыЁБ,ЖдгкГЃгУЕФХЗЪНОрРы,ДѓБпПђЛсВњЩњИќДѓЕФЮѓВю,ЕЋЮвУЧЙиаФЕФЪЧБпПђЕФIOUЁЃЫљвд,YOLO2дкОлРрЪБВЩгУвдЯТЙЋЪНРДМЦЫуСНИіБпПђЕФЁАОрРыЁБЁЃ
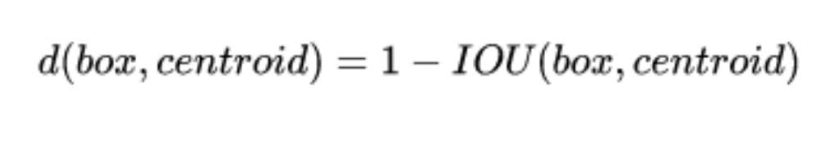
ЕНОлРржааФЕФОрРыдНаЁдНКУ,ЕЋIOUжЕЪЧдНДѓдНКУ,ЫљвдЪЙгУ 1 - IOU;етбљОЭБЃжЄОрРыдНаЁ,IOUжЕдНДѓЁЃОпЬхЪЕЯжЗНЗЈШчЯТ:


YOLO3
YOLO3ЯрБШжЎЧАЕФYOLO1КЭYOLO2,жївЊИФНјЗНЯђ:
1ЁЂЪЙгУСЫВаВюНсЙЙ
2ЁЂЬсШЁЖрЬиеїВуНјааФПБъМьВт,вЛЙВЬсШЁШ§ИіЬиеїВу,ЫћЕФshapeЗжЮЊЮЊ(13,13,75),(26,26,75),(52,52,75)ЁЃзюКѓвЛИіЮЌЖШЮЊ75ЪЧвђЮЊИУЭМЪЧЛљгкvocЪ§ОнМЏЕФ,ЫќЕФРрЮЊ20жжЁЃYOLO3еыЖдУПвЛИіЬиеїВуДцдк3ИіЯШбщПђ,ЫљвдзюКѓЕФЮЌЖШЮЊ3*25
3ЁЂВЩгУСЫupsampling2dЩшМЦ

ЯТУцЪЧЫќЕФаЇЙћЭМ:

ВЮПМзЪСЯ:https://ai-wx.blog.csdn.net/article/details/107509243
СДНг:https://pan.baidu.com/s/1R90nTPYR4IAmqy5k7QN3bg?pwd=p5kd?
ЬсШЁТы:p5kd