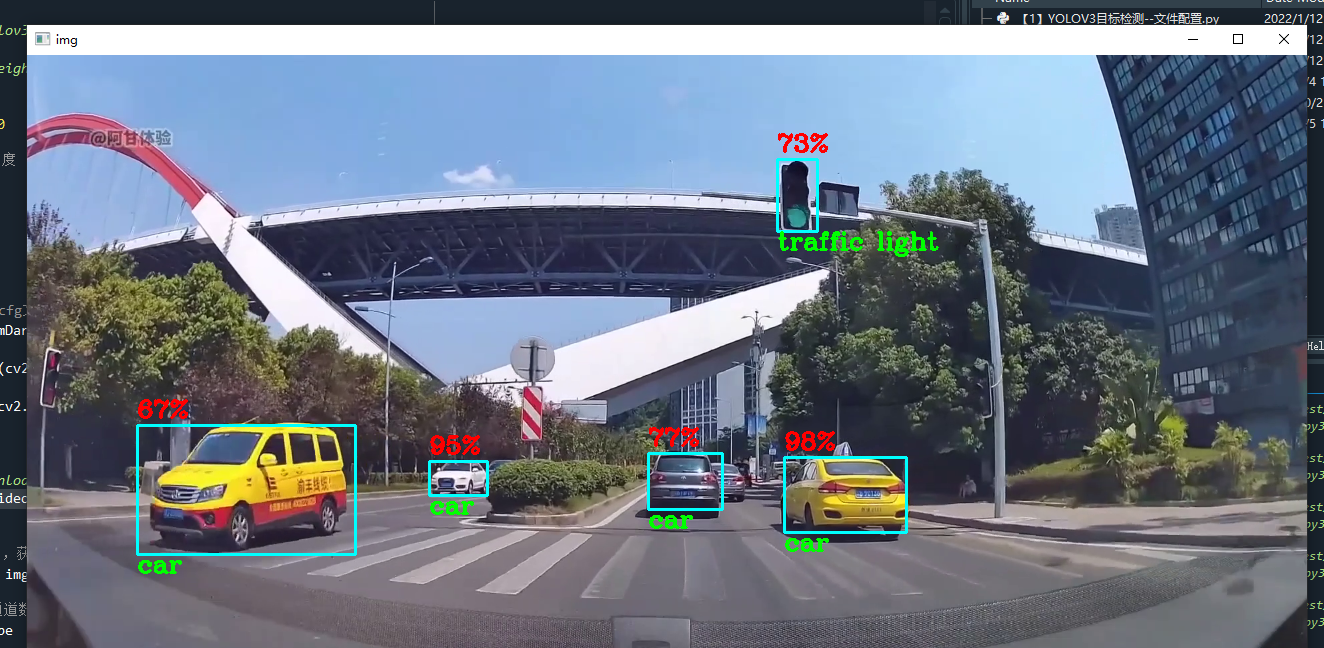
各位同学好,今天和大家分享一下如何使用 opencv 调用 yolov3 模型,加载网络权重,很方便地实现 yolov3 目标检测。先放张图看效果。
使用的网上找的行车记录仪视频做测试,数据集采用COCO数据集,检测效果还是不错的。
1. 预先准备
首先需要导入 COCO 数据集的分类名文件 'coco.names',以及yolov3的网络结构 'yolo.cfg',网络的权重参数 'yolo.weights',这些文件以及本案例的代码我给大家都提供好了,有需要的自取。
链接:https://pan.baidu.com/s/12iPJTjiN7SIBJ7hpHomn_w?
提取码:p548
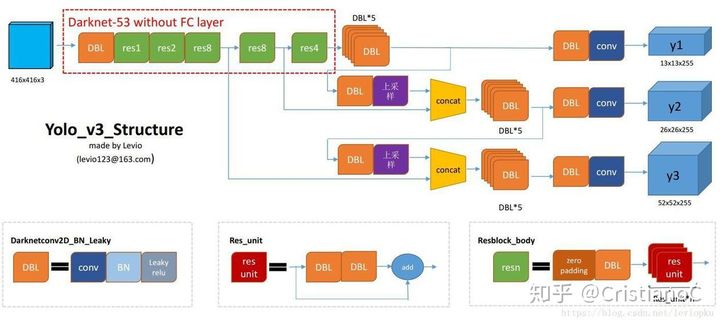
yolov3 使用 Darknet53 网络模型,这个网络我之前复现过,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/article/details/121997986
使用?cv2.dnn.readNetFromDarknet() 从opencv中读取网络模型,传入网络结构和权重参数。
由于我这个视频比较短,因此设置视频重复播放,使用 cv2.CAP_PROP_POS_FRAMES 获取当前视频所在第几帧,使用 cv2.CAP_PROP_FRAME_COUNT 获取该视频一共有多少帧。如果播放到了最后一帧,那就让当前帧=0,从头开始。
代码如下,net 配置完成,播放视频图像。
import numpy as np
import cv2
import time
#(1)加载预训练的COCO数据集
classesFile = 'coco.names' # 指定coco数据集分类名所在路径
classNames = [] # 创建列表,存放coco数据集的分类名称
# 打开数据集名称的文件
with open(classesFile, 'rt') as f: #读取文本文件
classNames = f.read().rstrip('\n').split('\n') # 通过换行符来拆分,再读入
# 加载yolov3结构cfg文件
modelConfiguration = 'yolov3.cfg'
# 加载yolov3网络权重
modelWeights = 'yolov3.weights'
#(2)构建网络结构
# 导入darknet53网络,传入cfg文件和网络权重
net = cv2.dnn.readNetFromDarknet(modelConfiguration, modelWeights)
# 申明使用opencv作为后端
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
# 申明使用CPU计算
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
#(3)获取摄像头
videoFile = 'C:\\GameDownload\\Deep Learning\\yolov3video.mp4'
cap = cv2.VideoCapture(videoFile) # 0代表电脑自带的摄像头,代表外接摄像头
pTime = 0 # 设置第一帧开始处理的起始时间
#(4)处理帧图像
while True:
# 接收图片是否导入成功、帧图像
success, img = cap.read()
# 改变图像大小
img = cv2.resize(img, (1280,720))
# 视频较短,循环播放
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
# 如果当前帧==总帧数,那就重置当前帧为0
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
#(5)显示图像
# 查看FPS
cTime = time.time() #处理完一帧图像的时间
fps = 1/(cTime-pTime)
pTime = cTime #重置起始时间
# 在视频上显示fps信息,先转换成整数再变成字符串形式,文本显示坐标,文本字体,文本大小
cv2.putText(img, str(int(fps)), (70,50), cv2.FONT_HERSHEY_PLAIN, 3, (255,0,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.imshow('img', img)
if cv2.waitKey(20) & 0xFF==27: #每帧滞留20毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()2. 获取检测框信息
2.1 确定输入及输出
先看下面代码中的第(6)步,图像传入神经网络之前先进行预处理?cv2.dnn.blobFromImage(),包括减均值,比例缩放,裁剪,交换通道等,返回一个4通道的blob(blob可以简单理解为一个N维的数组)。之后使用 net.setInput() 将blob类型图像作为网络输入。
cv2.dnn.blobFromImage(img, scalefactor, size, mean, swapRB, crop, ddepth)
'''
image: 输入图像
scalefactor: 图像各通道数值的缩放比例,默认=1
size: 输出图像的空间尺寸,如size=(200,300)表示高h=300,宽w=200
mean: 用于各通道减去的值,以降低光照的影响,
例:(image为BGR的3通道的图像,mean=[104.0, 177.0, 123.0],表示B通道的值-104,G-177,R-123)
swapRB: 交换RB通道,默认为False。(cv2.imread读取的是彩图是BGR通道)
crop: 图像裁剪,默认为False。当值为True时,先按比例缩放,然后从中心裁剪成size尺寸
ddepth: 输出的图像深度,可选CV_32F 或者 CV_8U.
'''由下图的 Darknet53 网络结构图可知,网络有三个输出层,输出的shape分别为?[52,52,255] 用于预测小目标,[26,26,255] 用于预测中等大小的目标,[13,13,255] 用于预测大目标。因此我们通过?net.getUnconnectedOutLayers() 就能知道这三个输出层处于网络中的第几层,得到的返回结果是?[200, 227, 254]。通过?net.getLayerNames() 只要输入层的索引就能得到该索引所对应的层的名称。得到输出层的层名称后,将其传入 net.forward() 中,就能找到输出层的输出结果。
到这里就完成了网络模型的输入 blob,得到了模型的三个输出?outputs,打印输出结果的相关信息如下。以 outputs[0].shape =(300,85)为例,?300代表检测框的数量,85代表:中心点坐标 x,y;框的宽高 w,h;置信度 c;80 个分类各自的概率
print(outputs[0].shape) # (300, 85)
print(outputs[1].shape) # (1200, 85)
print(outputs[2].shape) # (4800, 85)
print(outputs[0][0]) # 打印第0个检测框所包含的信息
'''
(300, 85)
(1200, 85)
(4800, 85)
[4.9195103e-02 5.5935599e-02 6.5290880e-01 1.8459144e-01 8.2010246e-08
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00]
'''2.2 获取检测框信息
接下来我们就看到下面代码中的第(4)步,现在有了每个区域的预测结果 outputs,需要从中找到和每个物体对应的最合适的检测框。
注意一下,img.shape 是先指定图像的高,再指定宽,(h, w, c),不要搞错了。
其中 output 遍历三个输出层,每个输出层包含n个检测框,每个框包含85项信息。det 遍历每一层的n个检测框,det 包含85项信息。我们需要找到每个框属于哪个分类,以及该框属于该分类的概率 confidence。如果该分类概率大于阈值 confThreshold 证明找到了,这时候就将该框的左上角坐标(x,y),框的宽w和高h,及置信度 confidence 保存下来。
这里需要注意的是,每个框的85项信息中的其四个信息:中心坐标和宽高,都是归一化之后的比例坐标和比例宽高。需要将比例宽高乘上原图像宽高才能得到检测框的真实宽高。
在第二节的代码中补充。
import numpy as np
import cv2
import time
#(1)加载预训练的COCO数据集
classesFile = 'coco.names' # 指定coco数据集分类名所在路径
classNames = [] # 创建列表,存放coco数据集的分类名称
# 打开数据集名称的文件
with open(classesFile, 'rt') as f: #读取文本文件
classNames = f.read().rstrip('\n').split('\n') # 通过换行符来拆分,再读入
# 加载yolov3结构cfg文件
modelConfiguration = 'yolov3.cfg'
# 加载yolov3网络权重
modelWeights = 'yolov3.weights'
# 确定输入图像的宽和高
wInput, hInput = 320, 320
# 自定义目标检测的最小置信度
confThreshold = 0.5
#(2)构建网络结构
# 导入darknet53网络,传入cfg文件和网络权重
net = cv2.dnn.readNetFromDarknet(modelConfiguration, modelWeights)
# 申明使用opencv作为后端
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
# 申明使用CPU计算
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
#(3)获取摄像头
videoFile = 'C:\\GameDownload\\Deep Learning\\trafficvideo2.mp4'
cap = cv2.VideoCapture(videoFile) # 0代表电脑自带的摄像头,代表外接摄像头
pTime = 0 # 设置第一帧开始处理的起始时间
#(4)定义函数用于检测目标,获取检测框信息,以及分类类别
def findObjects(outputs, img):
# 图像的高度、宽度、通道数
hT, wT, cT = img.shape
# 定义一个列表存放检测框的中心点坐标和宽高
bbox = []
# 定义列表存放分类的名称的索引
classIds = []
# 定义列表存放置信度
confs = [] # 如果找到目标了,就将检测框的信息存放起来
# 遍历三个输出层
for output in outputs:
# 遍历输出层的85项信息
for det in output: # det是数组类型
# 在80个分类中找到哪个分类的值是最高的
score = det[5:] # 忽略检测框的x,y,w,h,c
# 找到分类值最大对应的索引号
classId = np.argmax(score)
# 找到分类概率最大值的索引对应的值
confidence = score[classId]
# 如果检测置信度大于规定的阈值,表明检测到了物体
if confidence > confThreshold:
# 记录检测框的宽和高,这里的宽高是归一化之后的比例宽度和高度
w, h = int(det[2]*wT), int(det[3]*hT) # 比例宽高转为像素宽高,像素宽高是整数
# 记录检测框的左上角坐标
x, y = det[0]*wT-w//2, det[1]*hT-h//2
# 将检测框的信息保存起来
bbox.append([x, y, w, h])
# 将目标属于哪个类别的索引保存下来
classIds.append(classId)
# 保存检测框的置信度,检测出某个目标的概率
confs.append(float(confidence))
# 打印检测框信息
print('classids:', classIds, 'confidence:', confs, 'bbox:', bbox)
#(5)处理帧图像
while True:
# 接收图片是否导入成功、帧图像
success, img = cap.read()
# 改变图像大小
img = cv2.resize(img, (1280,720))
# 视频较短,循环播放
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
# 如果当前帧==总帧数,那就重置当前帧为0
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
#(6)将img图片转换成blob块类型,网络只接受这种类型
# 输入img图像,,图像宽w高h,默认参数[0,0,0],,
blob = cv2.dnn.blobFromImage(img, 1/255, (wInput,hInput), [0,0,0], 1, crop=False)
# 将转换类型后的图像作为输入数据
net.setInput(blob)
# 获得网络各层的名称,由于网络会输出最后三层的结果,用于定位输出层
layerNames = net.getLayerNames() # 得到网络所有层的名称
# 提取输出层,返回输出层是第几层,层数是从1开始,索引是从0开始
# net.getUnconnectedOutLayers() # [200, 227, 254]
outputNames = [] # 存放输出层名称
# 得到输出层在网络中属于第几层
for outindex in net.getUnconnectedOutLayers():
# 得到输出层的名称,outindex是第几层(从1开始),传入的是索引(从0开始)
outputNames.append(layerNames[outindex-1])
# 获取输出层返回结果
outputs = net.forward(outputNames)
print(outputs[0].shape) # (300, 85) 300代表检测框的数量,85代表:中心点坐标x,y,框的宽高w,h,置信度c,80个分类各自的概率
print(outputs[1].shape) # (1200, 85)
print(outputs[2].shape) # (4800, 85)
print(outputs[0][0]) # 打印第0个检测框所包含的信息
#(7)目标检测
findObjects(outputs, img)
#(8)显示图像
# 查看FPS
cTime = time.time() #处理完一帧图像的时间
fps = 1/(cTime-pTime)
pTime = cTime #重置起始时间
# 在视频上显示fps信息,先转换成整数再变成字符串形式,文本显示坐标,文本字体,文本大小
cv2.putText(img, str(int(fps)), (70,50), cv2.FONT_HERSHEY_PLAIN, 3, (255,0,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.namedWindow("img", 0) # 窗口大小可调整
cv2.imshow('img', img)
if cv2.waitKey(20) & 0xFF==27: #每帧滞留20毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
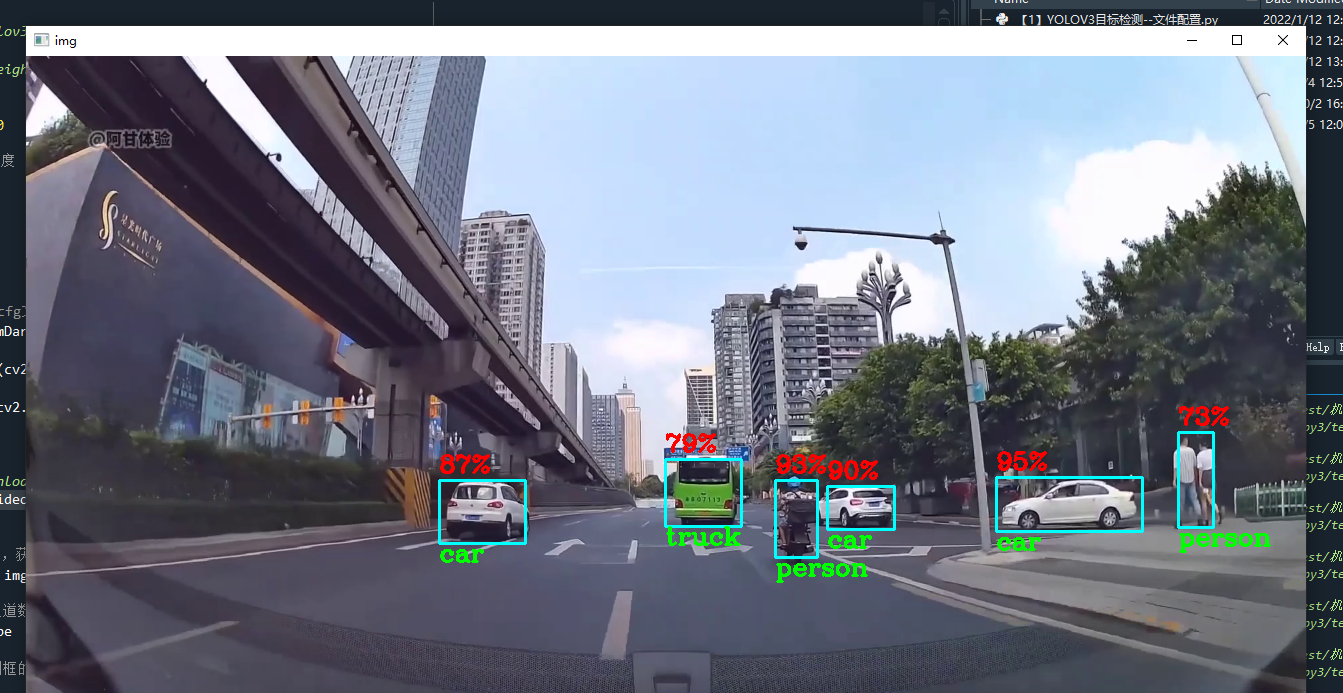
cv2.destroyAllWindows()打印得到的检测框信息
classids: [2, 7, 7, 2, 2, 2, 2, 2, 2]
confidence: [0.8474083542823792, 0.6886539459228516, 0.7003887891769409, 0.9768345952033997, 0.7150803804397583, 0.7982962131500244, 0.7913717031478882, 0.9718230962753296, 0.8747612833976746]
bbox: [[769.3665313720703, 398.1743869781494, 110, 88], [348.8137969970703, 387.51572608947754, 98, 70], [347.2083282470703, 388.56964111328125, 101, 71], [453.0018081665039, 409.030611038208, 32, 26], [625.3595275878906, 397.98907947540283, 67, 57], [681.5968627929688, 405.41797828674316, 37, 36], [694.1919250488281, 410.92028617858887, 37, 30], [760.8668212890625, 402.86146450042725, 124, 75], [777.7303924560547, 401.2068338394165, 112, 77]]3. 显示预测框,完成目标检测
进行完上面的操作后,我们现在得到一个物体上可能有很多的检测框都满足条件,接下来采用 NMS 非极大值抑制?cv2.dnn.NMSBoxes(),搜索出局部最大值,将置信度最大的框保存,其余剔除,确保每个目标至少有一个框。
cv2.dnn.NMSBoxes(bboxes, scores, score_threshold, nms_threshold, eta=None, top_k=None)
'''
bboxes:检测框信息 [x,y,w,h]
scores:每个待处理检测框的置信度
score_threshold:用于过滤检测框的置信度阈值
nms_threshold:NMS阈值
eta:自适应阈值公式中的相关系数
top_k: 如果 top_k>0,则保留最多 top_k 个边界框索引值
'''接下去就能使用矩形框绘制函数?cv2.rectangle() 把每个检测框绘制出来。
在上一节的代码中补充。
import numpy as np
import cv2
import time
#(1)加载预训练的COCO数据集
classesFile = 'C:\\Users\\admin\\.spyder-py3\\test\\机器视觉\\yolov3\\coco.names' # 指定coco数据集分类名所在路径
classNames = [] # 创建列表,存放coco数据集的分类名称
# 打开数据集名称的文件
with open(classesFile, 'rt') as f: #读取文本文件
classNames = f.read().rstrip('\n').split('\n') # 通过换行符来拆分,再读入
# 加载yolov3结构cfg文件
modelConfiguration = 'yolov3.cfg'
# 加载yolov3网络权重
modelWeights = 'yolov3.weights'
# 确定输入图像的宽和高
wInput, hInput = 320, 320
# 自定义目标检测的最小置信度
confThreshold = 0.5
# 自定义非极大值抑制的参数
nms_threshold = 0.3
#(2)构建网络结构
# 导入darknet53网络,传入cfg文件和网络权重
net = cv2.dnn.readNetFromDarknet(modelConfiguration, modelWeights)
# 申明使用opencv作为后端
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
# 申明使用CPU计算
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
#(3)获取摄像头
videoFile = 'C:\\GameDownload\\Deep Learning\\trafficvideo1.mp4'
cap = cv2.VideoCapture(videoFile) # 0代表电脑自带的摄像头,代表外接摄像头
#(4)定义函数用于检测目标,获取检测框信息,以及分类类别
def findObjects(outputs, img):
# 图像的高度、宽度、通道数
hT, wT, cT = img.shape # 先保存高度,再保存宽度
# 定义一个列表存放检测框的中心点坐标和宽高
bbox = []
# 定义列表存放分类的名称的索引
classIds = []
# 定义列表存放置信度
confs = [] # 如果找到目标了,就将检测框的信息存放起来
# 遍历三个输出层
for output in outputs:
# 遍历输出层的85项信息
for det in output: # det是数组类型
# 在80个分类中找到哪个分类的值是最高的
score = det[5:] # 忽略检测框的x,y,w,h,c
# 找到分类值最大对应的索引号
classId = np.argmax(score)
# 找到分类概率最大值的索引对应的值
confidence = score[classId]
# 如果检测置信度大于规定的阈值,表明检测到了物体
if confidence > confThreshold:
# 记录检测框的宽和高,这里的宽高是归一化之后的比例宽度和高度
w, h = int(det[2]*wT), int(det[3]*hT) # 比例宽高转为像素宽高,像素宽高是整数
# 记录检测框的左上角坐标
x, y = int(det[0]*wT-w/2), int(det[1]*hT-h/2)
# 将检测框的信息保存起来
bbox.append([x, y, w, h])
# 将目标属于哪个类别的索引保存下来
classIds.append(classId)
# 保存检测框的置信度,检测出某个目标的概率
confs.append(float(confidence))
#(5)消除重叠的矩形框,非极大值抑制
indices = cv2.dnn.NMSBoxes(bbox, confs, confThreshold, nms_threshold) # 返回检测框的索引
# 遍历索引绘制矩形框
for i in indices:
# 在所有包含目标的矩形框中找到最符合的矩形框
box = bbox[i]
# 提取矩形框的信息
x, y, w, h = box[0], box[1], box[2], box[3]
# 绘制矩形框
cv2.rectangle(img, (x,y), (x+w,y+h), (255,255,0), 2)
# 显示文本
cv2.putText(img, f'{classNames[classIds[i]]}',
(x,y+h+18), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0,255,0), 2)
cv2.putText(img, f'{int(confs[i]*100)}%',
(x,y-8), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0,0,255), 2)
#(6)处理帧图像
while True:
# 接收图片是否导入成功、帧图像
success, img = cap.read()
# 改变图像大小
img = cv2.resize(img, (1280,720))
# 视频较短,循环播放
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
# 如果当前帧==总帧数,那就重置当前帧为0
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
#(7)将img图片转换成blob块类型,网络只接受这种类型
# 输入img图像,,图像宽w高h,默认参数[0,0,0],,
blob = cv2.dnn.blobFromImage(img, 1/255, (wInput,hInput), [0,0,0], 1, crop=False)
# 将转换类型后的图像作为输入数据
net.setInput(blob)
# 获得网络各层的名称,由于网络会输出最后三层的结果,用于定位输出层
layerNames = net.getLayerNames() # 得到网络所有层的名称
# 提取输出层,返回输出层是第几层,层数是从1开始,索引是从0开始
# net.getUnconnectedOutLayers() # [200, 227, 254]
outputNames = [] # 存放输出层名称
# 得到输出层在网络中属于第几层
for outindex in net.getUnconnectedOutLayers():
# 得到输出层的名称,outindex是第几层(从1开始),传入的是索引(从0开始)
outputNames.append(layerNames[outindex-1])
# 获取输出层返回结果
outputs = net.forward(outputNames)
#(8)目标检测
findObjects(outputs, img)
#(9)显示图像
# 显示图像,输入窗口名及图像数据
cv2.namedWindow("img", 0) # 窗口大小可调整
cv2.imshow('img', img)
if cv2.waitKey(1) & 0xFF==27: #每帧滞留20毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()检测结果如下: