�����纭��
�����綨���кܶ�,�������èΪ��,����֪��è��ʲô,�������һ��è��ͼƬ������,���ܻش�������һֻè��ͼƬ�������еĹؼ��������������è������IJ���,ͨ��������ı����жԱȲ��������ı���������ı������Ĺ��̱���ѵ������Ȼ�����������,��ı�����������,���Ŀ�ʼ���������ʼ�������Ľ��������,���������ݵij�������Ҳ������յĽ������Ӱ�졣
��ʧ��������
�����������,������Ϊ����ʧ��������ı���������ı������ٵĶ�������������ı���ʽ�����������Ƶ�����ᵽ����:
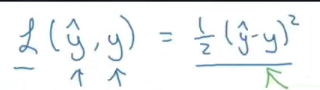
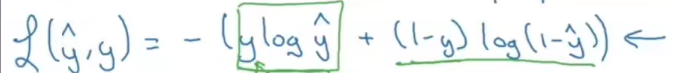
����������ʽ������Ƶ�������?����,���DZȽ�����ģ�Ͳ���ж���һ������������˼·:��С���˷�,������Ȼ����,������,����ֱ��������˼·�������Ƶ�
��С���˷�
���DZȽ�����ģ��֮��IJ����ķ���,��������Ҫ֪��ֱ�ӱȽ�ģ�Ͳ���,��Ϊ�������������ģ�����Ա���,���������������ģ�;����ü���Ƕ����ӿ�������,��ʱ�������Ч�ķ������DZȽϽ����
������èΪ��,����������n��ͼƬ,�ֱ���ЩͼƬ�������Ժ����������ж��Dz���è,�ж�������è,��ʱ����õ�
X
i
X_i
Xi?��
Y
i
Y_i
Yi?(�ֱ��ʾ�����Ժ��������е�
i
i
i��ͼƬ��è�ĸ���)��
�������������֪����һ��ͼƬ���Ժ���������Χ�ж�����ͨ��
�O
X
1
?
Y
1
�O
|X_1 -Y_1|
�OX1??Y1?�O���õ�,����������Ҫ��������ͼƬ�Ľ��,��������Ҫ����Щֵ�ۼ�����,�����
��
i
=
1
n
�O
X
i
?
Y
i
�O
\sum_{i=1}^{n} |X_i-Y_i|
��i=1n?�OXi??Yi?�O�������ֵ��С��ʱ��,��
m
i
n
��
i
=
1
n
�O
X
i
?
Y
i
�O
min\sum_{i=1}^{n} |X_i-Y_i|
min��i=1n?�OXi??Yi?�O,���ǿ�����Ϊ�����ģ�����������ģ���ǽ��Ƶġ�����������ȥ��������Ϊ�Ѿ��ﵽ������Ҫ��,���ǰ�����֮��IJ�ֵ�ҳ���������,��Ϊ��������Ǿ���ֵ,������ֵ���䶨�����ϲ�һ����ȫ�̿ɵ���,��ʱ�����ͨ�������ֵ��ƽ�������,��
m
i
n
��
i
=
1
n
(
X
i
?
Y
i
)
2
min\sum_{i=1}^{n} (X_i-Y_i)^2
min��i=1n?(Xi??Yi?)2����ƽ��֮��,����Ҫ������Ȼ����ֵ�����˸ı�,�����Ⲣ��Ӱ��
X
i
X_i
Xi?��
Y
i
Y_i
Yi?�Ĺ�ϵ,����ȫ�̿ɵ������������Dz��ѿ���Ϊʲô��Ҫ����С���˷���
���ڶԱȵ�һ��ͼƬ�ı���ʽ
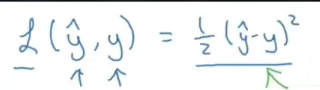
- ����� y ^ ? y \hat{y}-y y^??y�������������ᵽ�� X i ? Y i X_i-Y_i Xi??Yi?
- ����� 1 2 \frac{1}{2} 21?�Ƿ��������ʱ�ܹ���ָ��2�������
- ����û�� �� \sum{} ��,��Ҫ����Ϊѵ��ʱ,��������һ��ͼƬһ��ͼƬ��������õ����ķ������õ������Сֵ,�����������ʽ������ѧ����ʽ��û�е����Ĺ���,��������û�б��ʵIJ��
������,���ǿ���֪��������������ʧ������һ��ʽ����ͨ����С���˷��ó��Ľ�������ֻ���������ж���������ģ��֮��IJ���ж��ٻ��ǿ��Եġ�����,�ں�����������ᵽ,������Ϊ��ʧ���������ݶ��½���ʱ����ر��鷳,�����Ƽ���
������Ȼ����(�����Ȼ����)
������ͳ���ﳣ�õķ���,��Ȼ (likehood),�������Ϊ��ͨ�����ȥѰ�Ҹý������������ܵ�ԭ��,��һ�ָ��ʵķ���Ӧ�á�
������Ӿ���ͶӲ��,��������Ͷ10��Ӳ�����ж���Ӳ��������,�ж���Ӳ���Ƿ���,��Ȼ�����ģ�����������ķ��Ķ���
50
%
50\%
50%,����������Dz�֪���������ģ��Ҫͨ��һ�δ�ͶӲ������,���ܿ϶�ÿһ�ζ���Ͷ��5��������5���Ƿ�����?�Ȼ����,�����п�����7��������,������8��,Ҳ�п���ȫ�����ġ���ʱ�����Ǿ�Ҫ�Ƚϸ�������µõ�����������,�����ⲻ�����ģ�͵���ʵ����,��������ͨ��ͶӲ�ҳ��ֵ�ʵ������¼��������,����Ҳ�����Ϊ��Ȼֵ����Щ��Ȼֵ�������ľ���ʵ��ͶӲ�Ҹ�������Ŀ����ԡ�
������,���DZ���֪��������Ȼ���Ʊ�������Ȼֵ�����ֵ����Ϊ��Ȼ���Dz�֪��ͶӲ�ұ����ĸ���ģ������ô����,����ѡ����Ȼֵ����������ĸ���ģ�ͱ������п��ܵ�,��ӽ���ģ�͡�
�ֻص�è������,�������������������һ����ͼƬ������ͶӲ��,����������ĸ���ģ���ƽ������еĸ���ģ����һ�����Dz��������������ĺ�������,����������ĸ���ģ����һ����˹ģ��
N
(
��
,
��
2
)
N(\mu ,\sigma ^2)
N(��,��2),��ô����ѵ����ʱ����������������ģ��ȥƥ�������е�ģ��,ƥ����̾��Ǿ�������ͼ��ʹ֮�غ�,��ʱ����ǵ������������������ʵ����,�������������ģ�����ǿ��ܲ����,��������֪����Ȼ��,�������������ǿ����õ��Ӹ�֪���ķ�������ƽ�һ�ָ���ģ��,���������Dz�֪����ģ��Ҳ�ܱƽ�������,����������������ķ�ʽ���±������ģ��,��
N
N
(
W
,
b
2
)
NN(W,b^2)
NN(W,b2)(
W
W
W��δ֪��ϵ���ļ���,
b
b
b��ƫ��ϵ���ļ���),�����Ҫ�ﵽ�Ľ��,�������ģ��ȥ�ƽ������Ǹ�����ģ�͡�������,ֻҪ��֪���㹻��,�����κ�һ�ָ���ģ�Ͷ��ܴﵽ�����Ľ����
���
1
1
1����ͼƬ��è,
0
0
0����,�������ܵõ�����һ��ʽ��:
P
(
X
1
,
X
2
,
.
.
.
,
X
n
�O
W
,
b
)
=
��
i
=
1
n
P
(
X
i
�O
W
,
b
)
P(X_1,X_2,...,X_n|W,b)=\prod_{i=1}^{n} P(X_i|W,b)
P(X1?,X2?,...,Xn?�OW,b)=��i=1n?P(Xi?�OW,b)
(
1
)
(1)
(1)
����,
X
1
,
X
2
,
.
.
.
,
X
n
X_1,X_2,...,X_n
X1?,X2?,...,Xn?�����ж�ͼƬ�Dz���è,
W
,
b
W,b
W,b�����������еĸ���ģ��
���ʽ�Ӽ���õ���ֵ�������������Ȼֵ,�����ֵ����ʱ��,���Ǿ�����Ϊ�����������ģ���������е�ģ������ӽ��ġ�Ȼ��,����������һ������,������ѵ��ʱ
W
,
b
W,b
W,b��һ��ȷ����ֵ,����������ô������Ƭ����ȷ����,������Ǻ����жϵı�ǩ,���������è��ͼƬ��ȷ���Ļ�,�Ƕ���
1
1
1,������û�а취����ѵ���ġ�Ҳ����˵,������Ȼֵ���̶ֳȵ�Ӧ�����������ǿ��е�,����ȴû��ʵ�ʿɲ����Եġ�
������Ϊ���Ǻ�����ÿһ��ͼƬ�ж���صĽ��
y
i
y_i
yi?(��ͼƬ�Dz���è),��ѵ��������,
X
i
X_i
Xi?��
1
1
1����
0
0
0����֪��,�����ڿ��е�,����صĽ������
y
i
y_i
yi?,
y
i
y_i
yi?����
W
,
b
W,b
W,b��ȷ����,��ʱ������
(
1
)
(1)
(1)ʽ�Ϳ������������ʽ������:
P
(
X
1
,
X
2
,
.
.
.
,
X
n
�O
W
,
b
)
=
��
i
=
1
n
P
(
X
i
�O
y
i
)
P(X_1,X_2,...,X_n|W,b)=\prod_{i=1}^{n} P(X_i|y_i)
P(X1?,X2?,...,Xn?�OW,b)=��i=1n?P(Xi?�Oyi?)
(
2
)
(2)
(2)
����ΪͼƬֻҪ
1
1
1��
0
0
0�����ֿ���,��ͷ��ϲ�Ŭ���ֲ���
X i ? { 0 , 1 } X_i\epsilon \{0,1\} Xi??{0,1}
�� f ( x ) = p x ( 1 ? p ) x = { p , x = 1 1 ? p , x = 0 f(x)=p^x(1-p)^x=\left\{\begin{matrix} p, x=1\\ 1-p,x=0\end{matrix}\right. f(x)=px(1?p)x={p,x=11?p,x=0?
�ɴ˿���ͨ����Ŭ���ֲ��� ( 2 ) (2) (2)ʽչ���õ��������ʽ�ӡ�
P
(
X
1
,
X
2
,
.
.
.
,
X
n
�O
W
,
b
)
=
��
i
=
1
n
y
i
X
i
(
1
?
y
i
)
1
?
X
i
P(X_1,X_2,...,X_n|W,b)=\prod_{i=1}^{n}{y_i}^{X_i}(1-y_i)^{1-X_i}
P(X1?,X2?,...,Xn?�OW,b)=��i=1n?yi?Xi?(1?yi?)1?Xi?
(
3
)
(3)
(3)
��ʱ������ȡ�������۳˻����ۼ�,�õ�
(
4
)
(4)
(4)ʽ
l
o
g
(
��
i
=
1
n
y
i
X
i
(
1
?
y
i
)
1
?
X
i
)
log(\prod_{i=1}^ {n}{y_i}^ {X_i}(1-y_i)^{1-X_i})
log(��i=1n?yi?Xi?(1?yi?)1?Xi?)
=
��
i
=
1
n
l
o
g
(
y
i
X
i
(
1
?
y
i
)
1
?
X
i
)
=\sum_{i=1}^{n} log({y_i}^{X_i}(1-y_i)^{1-X_i})
=��i=1n?log(yi?Xi?(1?yi?)1?Xi?)
=
��
i
=
1
n
(
X
i
?
l
o
g
y
i
+
(
1
?
X
i
)
?
l
o
g
(
1
?
y
i
)
=\sum_{i=1}^{n}(X_i* logy_i + (1-X_i)*log(1-y_i)
=��i=1n?(Xi??logyi?+(1?Xi?)?log(1?yi?)
(
4
)
(4)
(4)
���� l o g log log�Dz���ı���Ȼֵ�õ����Ժ�פ���,�����������Ȼֵ�����ֵҲ������ ( 4 ) (4) (4)ʽ�����ֵ,Ҳ���ܵõ���������������ģ����ӽ��ĸ���ģ��,����
m a x ( �� i = 1 n ( X i ? l o g y i + ( 1 ? X i ) ? l o g ( 1 ? y i ) ) max(\sum_{i=1}^{n}(X_i* logy_i + (1-X_i)*log(1-y_i)) max(��i=1n?(Xi??logyi?+(1?Xi?)?log(1?yi?))
������ʵ�ʼ���ʱ,����һ���ȥ����Сֵ,��:
? ( �� i = 1 n ( X i ? l o g y i + ( 1 ? X i ) ? l o g ( 1 ? y i ) ) -(\sum_{i=1}^{n}(X_i* logy_i + (1-X_i)*log(1-y_i)) ?(��i=1n?(Xi??logyi?+(1?Xi?)?log(1?yi?))
������,������ȥ�Ա�������������ĵڶ���ʽ��
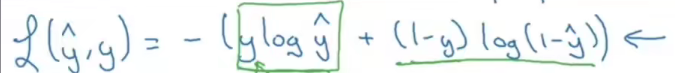
- ����� y ^ \hat {y} y^?������������ֵ,������������ y i y_i yi?��ʾ
- ����� y y y�������DZ�ǩ��ֵ,������������� X i X_i Xi?
- ����û�� �� \sum{} ��,����һ��ʽ�ӽ���һ��������й�
������п�������ⲿ����Ƶ,��ῴ����Ļ�в�����˵����ͨ�������صõ���,��ʵ,ͨ��������Ȼ���ƺͽ����ض����Ƶ�����ʽ��,�Ⲣ��ì��,�����Ӳ�ͬ�Ƕȿ�ͬһ�����в�ͬ���ݡ�
������
���������Ҫֱ�ӱȽ�����ģ��,����Ҫ��������ģ��ת���ͬһ������,����ν���������,����õ����Ӿ��ǻ�����ϵ,����Ԫ���ο�����Ե�,���ڸ���ģ����˵,���۸���ģ����ʲô����,���Ƕ���������������ͳһ������
д����������������,�ټ��Ͽ�����ƪ������,����,�Ͳ�д��ȥ��,�����Һ�������Ҫԭ��,���������������ټ����ɡ�
���Ҳ������Ҫ�ķ���èͼ��
