Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
1.��������
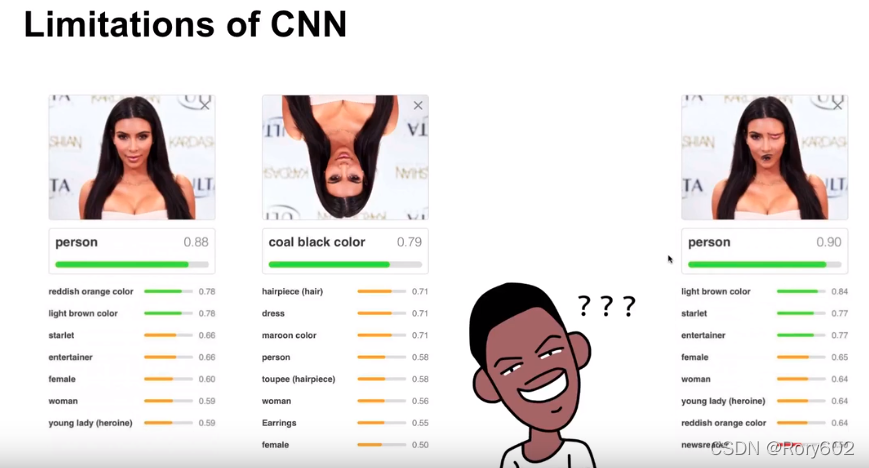
��ͼ����,ʶ���ʻ��½�,���۾��������λ��,����ʶ��Ϊ��,����CNNȱ������Կռ�λ�õı��
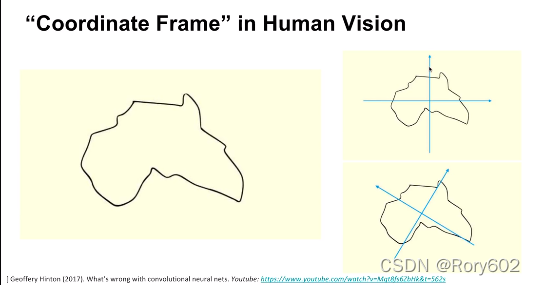
�����ǰĴ�����?ת������ϵ,��ʵ�Ƿ��ޡ�

low level capsuleת��Ϊhigh level capsule, ÿ��low level�൱�ڱ�ʾʵ��IJ�ͬ����, high level��ʾ����ʵ�塣
�����εĵ�1��������ʾ����,���� ������ʾʵ����ڵ����Ŷȡ�
1.1��������ʹ�ͳ�������������


��ͳ��������:(1)�������뵽��������Ĺ��̡�(2)�ۻ����->��������
����������:(1)�������뵽��������Ĺ��̡�(3)����任(�������Ծ���ת��Ϊ��һ�� ����)->ͨ��c�����Լ�Ȩ���->��ѹ(squash)->���v������c��ͨ��dynamic routing���ƶ�̬�����ġ�
�� s �� 2 1 + �� s �� 2 \frac{\|s\|^{2}}{1+\|s\|^{2}} 1+��s��2��s��2?: squash����sigmoid�任�ĺ���,��s�� �����ر�,�ӽ�����ʱ,����ѹ��Ϊ1,��sΪ0ʱΪ0.
s �� s �� \frac{s}{\|s\|} ��s��s?Ϊ�����Ĺ��̡�

b 11 �� b 21 b_{11}��b_{21} b11?��b21?��ʼ��0,b��������Ϊagreement(ѡ�ٵ���˼,������ͳѡ��),���� u 1 �� u 2 u_1��u_2 u1?��u2?������ͳ��ѡ�ˡ�b����softmax���ɺ�Ϊ1��Ȩ�ء�����squash������ a 1 a_1 a1?, a 1 a_1 a1?�� u 1 u_1 u1?�ļнDZȽϽӽ�,��b(agreement)�ͻ�� u 1 u_1 u1?,update agreement������kmeans���ĵ�ļ��㡣v�ķ�����ʾconfidence�������ܴ�,��ʾ���ʺܴ�
ѵ������: �����minist���ݼ�,����ѵ����������Ϊ1,����ϣ��Ϊ��1������Ƚϴ�,�����ķ����Ƚ�С��
2. MIND
2.1����Ĺ�ʽ��ʾ
ƥ��ε���ҪĿ����Ƕ�ÿ���û� u �� U u\in \mathcal{U} u��U�ڼ�ʮ��item������ I \mathcal{I} I,��ѡ����������Լ��ǧ���ҡ�
ÿ������������ ( I u , P u , F i ) \left(\mathcal{I}_{u}, \mathcal{P}_{u}, \mathcal{F}_{i}\right) (Iu?,Pu?,Fi?)��ʾ,���� I u \mathcal{I}_{u} Iu?��ʾ���û�������item(����˵�û�����Ϊ)�� P u \mathcal{P}_{u} Pu?��ʾ�û��Ļ�����Ϣ(����:�û����Ա�����)�� F i \mathcal{F}_{i} Fi?��ʾĿ�� item(����:item id��category id)��
��ԭʼ����ӳ��Ϊ�û���ʾ:
V
u
=
f
user?
(
I
u
,
P
u
)
(1)
\mathrm{V}_{u}=f_{\text {user }}\left(I_{u}, \mathcal{P}_{u}\right)\tag{1}
Vu?=fuser??(Iu?,Pu?)(1)
����: V u = ( v �� u 1 , �� , v �� u K ) �� R d �� K \mathrm{V}_{u}=\left(\overrightarrow{\boldsymbol{v}}_{u}^{1}, \ldots, \overrightarrow{\boldsymbol{v}}_{u}^{K}\right) \in \mathbb{R}^{d \times K} Vu?=(vu1?,��,vuK?)��Rd��K������ʾ�û� u u u������, d d d��ʾ����ά��, K K K��ʾ�û���ʾ������, K = 1 K=1 K=1��ʾֻ��һ��������ʹ�� ,����YouTube DNN��
target item
i
i
i��������ʾΪ:
e
��
i
=
f
item?
(
F
i
)
(2)
\overrightarrow{\boldsymbol{e}}_{i}=f_{\text {item }}\left(\mathcal{F}_{i}\right)\tag{2}
ei?=fitem??(Fi?)(2)
����:
e
?
i
��
R
d
��
1
\vec{e}_{i} \in \mathbb{R}^{d \times 1}
ei?��Rd��1��ʾitem
i
i
i ��һ��������
Top N��ѡ������:
f
score?
(
V
u
,
e
��
i
)
=
max
?
1
��
k
��
K
e
��
i
T
v
��
u
k
(3)
f_{\text {score }}\left(\mathrm{V}_{u}, \overrightarrow{\boldsymbol{e}}_{i}\right)=\max _{1 \leq k \leq K} \overrightarrow{\boldsymbol{e}}_{i}^{\mathrm{T}} \overrightarrow{\boldsymbol{v}}_{u}^{k}\tag{3}
fscore??(Vu?,ei?)=1��k��Kmax?eiT?vuk?(3)
N
N
N��ʾ��ѡ����������
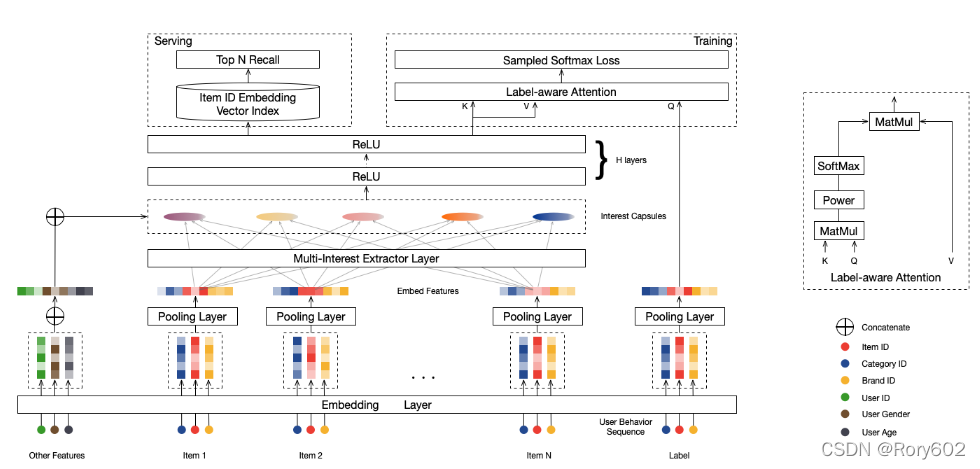
2.2Ƕ��ͳػ���
MIND�� ������������3����:�û���������
P
u
\mathcal{P}_{u}
Pu?���û�����Ϊ����
I
u
\mathcal{I_u}
Iu?�ͱ�ǩitem
F
i
\mathcal{F_i}
Fi?
P
u
\mathcal{P}_{u}
Pu?(�Ա�����)����concatenate��
F i \mathcal{F_i} Fi?(Ʒ��id, shop id)����average pooling ��,�γ�item embedding Ϊ e ? i \vec{e}_{i} ei?��
I u \mathcal{I_u} Iu?�û�����Ϊ����, E u = { e �� j , j �� I u } \mathrm{E}_{u}=\left\{\overrightarrow{\boldsymbol{e}}_{j}, j \in I_{u}\right\} Eu?={ej?,j��Iu?}��
2.3 ����Ȥ��ȡ��
���û�����ʷ��Ϊ���о���
2.3.1 ��̬·��
����������capsules, low-level capsules c ? i l �� R N l �� 1 , i �� { 1 , �� , m } \vec{c}_{i}^{l} \in \mathbb{R}^{N_{l} \times 1}, i \in\{1, \ldots, m\} cil?��RNl?��1,i��{1,��,m} ��high-level capsules c ? j h �� R N h �� 1 , j �� { 1 , �� , n } \vec{c}_{j}^{h} \in \mathbb{R}^{N_{h} \times 1}, j \in \{1, \ldots, n\} cjh?��RNh?��1,j��{1,��,n}
low-level capsule
i
i
i�� high-level capsule
j
j
j֮���logit
b
i
j
b_{ij}
bij?���㹫ʽ����:
b
i
j
=
(
c
?
j
h
)
T
?
S
i
j
c
?
i
l
(4)
b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l} \tag{4}
bij?=(cjh?)T?Sij?cil?(4)
����,
S
i
j
��
R
N
h
��
N
l
\mathrm{S}_{i j} \in \mathbb{R}^{N_{h} \times N_{l}}
Sij?��RNh?��Nl?����Ҫѧϰ��˫����ӳ�����
candidate vector for high-level capsule j
z
?
j
h
=
��
i
=
1
m
w
i
j
?
S
i
j
c
��
i
l
(5)
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} \mathrm{~S}_{i j} \overrightarrow{\boldsymbol{c}}_{i}^{l}\tag{5}
zjh?=i=1��m?wij??Sij?cil?(5)
w
i
j
w_{ij}
wij?������low-level��high-level֮���Ȩ��,���㷽ʽ����:
w
i
j
=
exp
?
b
i
j
��
k
=
1
m
exp
?
b
i
k
(6)
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}}\tag{6}
wij?=��k=1m?expbik?expbij??(6)
quash ����Ӧ����high-level capsules, ���㷽ʽ����:
c
?
j
h
=
squash
?
(
z
?
j
h
)
=
��
z
?
j
h
��
2
1
+
��
�O
z
j
h
��
2
z
?
j
h
��
z
?
j
h
��
(7)
\vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\mid{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|}\tag{7}
cjh?=squash(zjh?)=1+����?�Ozjh?����?2����?zjh?����?2?����?zjh?����?zjh??(7)
b
i
j
b_{ij}
bij?��ʼ��Ϊ0, ��·�ɽ���,
c
?
j
h
\vec{c}_{j}^{h}
cjh?���Թ̶�����,��Ϊ��һ������롣
ʹ��Shared bilinear mapping matrix��Ҫ��������:�ӵͽ��û���Ϊ������ѧϰ�߽��û���Ȥ����(1)�û���Ϊ�DZ䳤��,����ϣ��ģ����ͨ�á�(2)����ϣ���û���Ϊ���û���Ȥ�ܹ���һ�������ռ��С�
b
i
j
=
u
?
j
T
?
S
e
��
i
,
i
��
I
u
,
j
��
{
1
,
��
,
K
}
(8)
b_{i j}=\vec{u}_{j}^{T} \mathrm{~S} \overrightarrow{\boldsymbol{e}}_{i}, \quad i \in I_{u}, j \in\{1, \ldots, K\}\tag{8}
bij?=ujT??Sei?,i��Iu?,j��{1,��,K}(8)
e
?
i
��
R
d
\vec{e}_{i} \in \mathbb{R}^{d}
ei?��Rd��ʾitem
i
i
i���û���Ϊ,
u
?
j
��
R
d
\vec{u}_{j} \in \mathbb{R}^{d}
uj?��Rd��ʾ�û���Ȥ����
j
j
j��
S
��
R
d
��
d
S \in\mathbb{R}^{d \times d}
S��Rd��d���û���Ϊ���Һ��û���Ȥ����֮��Ĺ�������
**��ʼ��routing logits:**��������ʼ��Ϊ0,�ᵼ���û���Ȥ��ͬ,��˲��ø�˹�ֲ����г�ʼ����
��̬�û���Ȥ������:
K
u
��
=
max
?
(
1
,
min
?
(
K
,
log
?
2
(
�O
I
u
�O
)
)
)
(9)
K_{u}^{\prime}=\max \left(1, \min \left(K, \log _{2}\left(\left|I_{u}\right|\right)\right)\right)\tag{9}
Ku��?=max(1,min(K,log2?(�OIu?�O)))(9)
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-7vklCkM8-1642259038786)(Selection_006.png)]
def build(self, input_shape):
self.routing_logits = self.add_weight(shape=[1, self.k_max, self.max_len],
initializer=RandomNormal(stddev=self.init_std),
trainable=False, name="B", dtype=tf.float32)
self.bilinear_mapping_matrix = self.add_weight(shape=[self.input_units, self.out_units],
initializer=RandomNormal(stddev=self.init_std),
name="S", dtype=tf.float32)
super(CapsuleLayer, self).build(input_shape)
def call(self, inputs, **kwargs):
behavior_embddings, seq_len = inputs
batch_size = tf.shape(behavior_embddings)[0]
seq_len_tile = tf.tile(seq_len, [1, self.k_max])
for i in range(self.iteration_times):
mask = tf.sequence_mask(seq_len_tile, self.max_len)
pad = tf.ones_like(mask, dtype=tf.float32) * (-2 ** 32 + 1)
routing_logits_with_padding = tf.where(mask, tf.tile(self.routing_logits, [batch_size, 1, 1]), pad)
weight = tf.nn.softmax(routing_logits_with_padding)
behavior_embdding_mapping = tf.tensordot(behavior_embddings, self.bilinear_mapping_matrix, axes=1)
Z = tf.matmul(weight, behavior_embdding_mapping)
interest_capsules = squash(Z)
delta_routing_logits = reduce_sum(
tf.matmul(interest_capsules, tf.transpose(behavior_embdding_mapping, perm=[0, 2, 1])),
axis=0, keep_dims=True
)
self.routing_logits.assign_add(delta_routing_logits)
interest_capsules = tf.reshape(interest_capsules, [-1, self.k_max, self.out_units])
return interest_capsules
2.3.2 Label-aware Attention
���� �û�����Ȥ���Һ�item��������attention����,��item���м�Ȩ��label��query, ��Ȥ������keys��values��user u�����������item i���㷽ʽ����:
v
?
u
=
?Attention?
(
e
?
i
,
?
V
u
,
?
V
u
)
=
V
u
softmax
?
(
pow
?
(
V
u
T
e
?
i
,
p
)
)
\begin{aligned} \vec{v}_{u} &=\text { Attention }\left(\vec{e}_{i}, \mathrm{~V}_{u}, \mathrm{~V}_{u}\right) \\ &=\mathrm{V}_{u} \operatorname{softmax}\left(\operatorname{pow}\left(\mathrm{V}_{u}^{\mathrm{T}} \vec{e}_{i}, p\right)\right) \end{aligned}
vu??=?Attention?(ei?,?Vu?,?Vu?)=Vu?softmax(pow(VuT?ei?,p))?
����,
p
p
p�ǵ���attention�ֲ��IJ���,��pΪ0ʱ, attention��ƽ���ġ�
p
p
pԽ��,����������ʱ,value���ӹ�עȨ������ֵ,�����������
def call(self, inputs, training=None, **kwargs):
keys = inputs[0]
query = inputs[1]
weight = reduce_sum(keys * query, axis=-1, keep_dims=True)
weight = tf.pow(weight, self.pow_p) # [x,k_max,1]
if len(inputs) == 3:
k_user = tf.cast(tf.maximum(
1.,
tf.minimum(
tf.cast(self.k_max, dtype="float32"), # k_max
tf.log1p(tf.cast(inputs[2], dtype="float32")) / tf.log(2.) # hist_len
)
), dtype="int64")
seq_mask = tf.transpose(tf.sequence_mask(k_user, self.k_max), [0, 2, 1])
padding = tf.ones_like(seq_mask, dtype=tf.float32) * (-2 ** 32 + 1) # [x,k_max,1]
weight = tf.where(seq_mask, weight, padding)
weight = softmax(weight, dim=1, name="weight")
output = reduce_sum(keys * weight, axis=1)
return output
2.3.3 Training&Serving
�õ��û�������
v
?
u
\vec{v}_{u}
vu?�ͱ�ǩ������
e
?
i
\vec{e}_{i}
ei?, �����û��ͱ�ǩ��֮��Ľ����ĸ���
Pr
?
(
i
�O
u
)
=
Pr
?
(
e
?
i
�O
v
?
u
)
=
exp
?
(
v
?
u
T
e
?
i
)
��
j
��
I
exp
?
(
v
?
u
T
e
?
j
)
(10)
\operatorname{Pr}(i \mid u)=\operatorname{Pr}\left(\vec{e}_{i} \mid \vec{v}_{u}\right)=\frac{\exp \left(\vec{v}_{u}^{\mathrm{T}} \vec{e}_{i}\right)}{\sum_{j \in I} \exp \left(\vec{v}_{u}^{\mathrm{T}} \vec{e}_{j}\right)}\tag{10}
Pr(i�Ou)=Pr(ei?�Ovu?)=��j��I?exp(vuT?ej?)exp(vuT?ei?)?(10)
ѵ����Ŀ�꺯��:
L
=
��
(
u
,
i
)
��
D
log
?
Pr
?
(
i
�O
u
)
(11)
L=\sum_{(u, i) \in \mathcal{D}} \log \operatorname{Pr}(i \mid u)\tag{11}
L=(u,i)��D��?logPr(i�Ou)(11)
����
D
\mathcal{D}
D�ǰ����û���item��ѵ������