在李宏毅《机器学习》| 回归中提到了梯度下降的方法,这篇文章来详细总结下梯度下降,梯度下降代码展示见文章李宏毅《机器学习》| 回归-Gradient Descent代码展示。
目录
一、回顾
回归问题求解最优参数时,需要解决最优化问题为
,其中
为损失函数,
为参数。
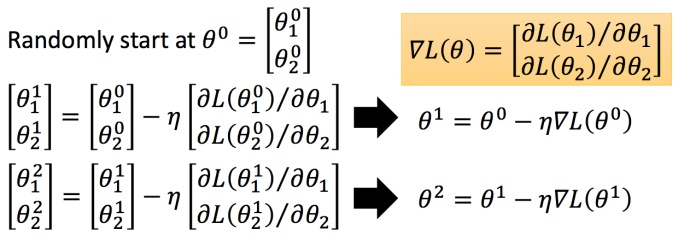
分别计算初始点处,两个参数对
的偏微分,然后
减掉学习率learning rate
乘上偏微分的值,得到更新后的一组参数。同理反复进行这样的计算。
即为梯度

二、调整学习速率
法1:一点点调整
左边黑色曲线为损失函数的曲线。假设从左边最高点开始,若学习率调整的刚刚好,如红色的线,就能顺利找到最低点。如果学习率调整的太小,如蓝色的线,就会走的太慢。如果学习率调整的太大,如绿色的线,就会震荡,永远无法到达最低点。如果学习率调整的非常大,如黄色的线,更新参数时会发现损失函数越更新越大。

虽然这样的可视化可以很直观观察,但可视化只是能在参数是一或二维的时候进行,更高维的情况已经无法可视化了。
解决方法就是上图右边的方案,将参数改变对损失函数的影响进行可视化。比如学习率太小(蓝色的线),损失函数下降的非常慢;学习率太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;学习率特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
法2:自适应学习率
一个简单的思想:随着次数的增加,通过一些因子来减少学习率。
一般初始点会距离最低点比较远,所以使用大一点的学习率;update多次参数后,较为靠近最低点,此时减少学习率,如,
是迭代次数。随着次数的增加,
减小。
学习率不能是一个值通用所有特征,不同的参数需要不同的学习率。
法3:Adagrad算法
算法
每个参数的学习率都把它除上之前微分的均方根,即,其中
,
为之前参数的所有微分的均方根,对于每个参数都是不一样的。更新算法如下:

矛盾
在Adagrad中,当梯度越大时,步伐也应该越大;但分母又导致当梯度越大时,步伐会越小。

?直观解释:

?正式解释:

假设初始点在,最低点为
,最佳的步伐就是
到最低点之间的距离
,即
?,而分子
就是方程绝对值在
这一点的微分。如果计算得到的微分越大,则距离最低点越远,且最佳步长和微分的大小成正比。所以如果踏出去的步伐和微分成正比,它可能是比较好的。即梯度越大,距离最低点越远。
考虑多参数情况
上述结论结论在多参数时不一定成立:

上图左边是两个参数的损失函数,颜色代表损失函数的值。如果只考虑参数(图中蓝色线),得到右边上图结果;如果只考虑参数
(图中绿色线),得到右边下图结果。对于
和
,或者结论是成立的,同理
?和
也成立。但是如果对比
和
就不成立了,
比
大,但
距最低点较近。因此该结论只在没有考虑跨参数的情况下才成立。

?之前讲到最佳距离中的分母
是对function进行二次微分得到的:
,所以最好的步伐不仅仅要正比于一次微分,同时要和二次微分呈反比,即
。
进一步解释
对于?就是希望尽可能不增加过多运算的情况下模拟二次微分(如果计算二次微分,在实际情况中可能会增加很多的时间消耗)。

三、随机梯度下降法
之前的梯度下降需要处理所有的数据:

?随机梯度下降法的损失函数不需要处理训练集所有的数据,只选取一个例子,只需要计算某一个例子的损失函数
,就可以update 梯度。

常规梯度下降法走一步要处理所有二十个例子,但随机算法此时已走了二十步(每处理一个例子就更新)?。
四、特征缩放
假设有函数,两个输入的分布的范围很不一样,建议把他们的范围缩放,使得不同输入的范围是一样的。

原因
下图左边的scale比
要小很多,所以当
和
做同样变化时,
对
的变化影响是比较小的,
对
的变化影响是比较大的。?

坐标系中是两个参数的error surface(现在考虑左边蓝色),因为对
的变化影响比较小,所以
对损失函数的影响比较小,
对损失函数有比较小的微分,所以
方向上是比较平滑的。同理
对
的变化影响比较大,所以
对损失函数的影响比较大,在
方向有比较尖的峡谷。
当两个参数scaling比较接近时(右边绿色图),error surface就比较接近圆形。
对于左边这种狭长的情形,不用Adagrad的话是比较难处理的,两个方向上需要不同的学习率,同一组学习率会搞不定它。而右边情形更新参数就会变得比较容易。左边的梯度下降并不是向着最低点方向走的,而是顺着等高线切线法线方向走的。但绿色就可以向着圆心(最低点)走,这样做参数更新也是比较有效率。
做法
下图每一列都是一个例子,里面都有一组特征。对每一个维度(绿色框)计算平均数
,计算标准差
。然后用第
个例子中的第
个输入,减掉平均数
,然后除以标准差
,得到的结果是所有的维数都是0,所有的方差都是1。

五、理论基础
问题
用梯度下降解决问题,每次更新参数
,都得到一个新的
,它都使得损失函数更小,即
的结论是错误的。

比如在处,可以在一个小范围的圆圈内找到损失函数细小的
,不断的这样去寻找。接下来就是如何在小圆圈内快速的找到使得loss最小的参数?
泰勒展开式

举例:图中3条蓝色线是把前3项作图,橙色线是。

多变量展开式:
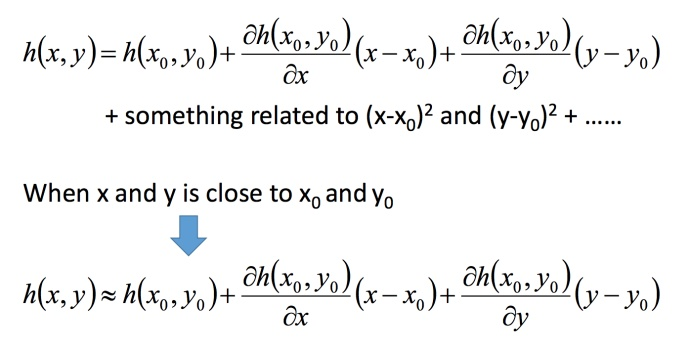
?利用泰勒展开式简化
回到之前如何快速在圆圈内找到最小值。基于泰勒展开式,在(a,b)点的红色圆圈范围内,可以将损失函数用泰勒展开式进行简化:

将问题简化为:

不考虑s的话,可以看出剩下的部分就是两个向量和(u,v)的内积,那怎样让它最小,就是和向量(u,v)方向相反的向量:

然后将u和v带入

最后的式子就是梯度下降的式子L(θ)≈s+u(θ1??a)+v(θ2??b)。但用这种方法找到这个式子有个前提,泰勒展开式给的损失函数的估算值要足够精确,而这需红色圈圈足够小(也就是学习率足够小)来保证。故理论上每次更新参数都想要损失函数减小的话,即保证成立的话,就需要学习率足够足够小才可以。
所以实际中,当更新参数时,若学习率没有设好,有可能不成立,所以导致做梯度下降时,损失函数没有越来越小。
上式只考虑了泰勒展开式的一次项,如考虑到二次项(如牛顿法),在实际中不是特别好,会涉及到二次微分等,将增加很多的运算,性价比不高。
六、梯度下降的限制
容易陷入局部极值;还有可能卡在不是极值,但微分值是0的地方;还有可能实际中只是当微分值小于某一个数值就停下来了,但这里只是比较平缓,并不是极值点。
