���ǿ��ѧϰActor-Critic�ĸ����������ʼ�
ǰ��:
ǰ�����ڸ�ʦ�ܽ�actor-critic�ܹ���������ʱ��,actor���Ż����ҿ��˺�һ���,����Ҳû�������İ�����������,����պó�����������,��֮ǰ��PPT�ó���,����PPT������,��AC�ܹ��ĸ�����˵����,�ش���һ���ʼǡ�
Actor-Critic�ܹ����:
����AC�ܹ�,���Ǽ�˵˵�ҵ������,����ǿ����˵,Ŀ�����ҵ�һ�����Ų���ģ��,ʹ�����Ķ����켣�ۼƻر�ֵ�����Ȼ����һ������ģ��,�������ΪActor,���������ǵ�ǰ��״̬��Ϣstate,���Ϊ����action�����û����������critic�Ļ�,�Ǿ�ֻ�����ù켣���ۼƻر������²�����,һ���켣����һ��,Ч�ʽϵ͡��������������,Ҫ��Ҫ��������ģ��,�����ض���״̬�Ͷ���,ֱ�Ӹ���һ������ֵ,����ָ��actor���Ż�����
critic�ĸ�����
������ģ��critic����ֵ��������ʲô��?�����֮ǰ��ǿ������֪ʶ�Ļ�,��(s, a)������,����Q(s, a)=r+��*Q(s��,a��),����DZ��������̵�Qֵ��ʽ,���ڱ��������̵�����,�Һ���Ҳ�����ʼǡ�
��������ĵ�ʽ,����Q(s��, a��)����֪��,s, a, r, s�� ������֪��,��ôֻ��Ҫ����critic�IJ�����,ʹ��Q(s,a|��)������ӽ�r+��*Q(s��,a��)���ɡ�����һ���мලѧϰ,�������ѧϰ�Ļ���������
����Q(s��,a��)������,��DDPG�㷨��,Q(s��,a��|��-target)�ĸ���Ƶ��Ҫ����Q(s,a|��),����������·��ʱ��,����ȹ̶�����,�ҽ���ǰ��,Ȼ���������ǰ��,һ��һ����ǰŲ~
���������Ѿ��õ���critic�ĸ��·�ʽ��,ֻҪ����ӵ���㹻���(s, a, r, s��),��ô���Ǿ��ܻ�ȡ��һ���ܺõ�����ģ��,�����ض���(s,a)���ܸ�һ�����пϡ������ۡ�
actor�ĸ�����:
�����������ô����actorģ����?
���ǿ������ı���ʽ:
actor��ʽ��:
a
=
��
(
s
�O
��
)
a=\pi(s|\theta)
a=��(s�O��)
critic��ʽ��:
q
=
Q
(
s
,
a
�O
?
)
=
Q
(
s
,
��
(
s
�O
��
)
�O
?
)
q=Q(s,a|\phi)=Q(s, \pi(s|\theta)|\phi)
q=Q(s,a�O?)=Q(s,��(s�O��)�O?)
������actor��˼·��,�����ض�״̬s,����actorģ�Ͳ�����,ʹ��actor����� �� ( s �O �� ) \pi(s|\theta) ��(s�O��),����criticģ�ͺ����� Q ( s , �� ( s �O �� ) �O ? ) Q(s, \pi(s|\theta)|\phi) Q(s,��(s�O��)�O?)������ķ�����¡�
����������Ҫ��һ�����Ϻ���������ʽ��
��������,����
Q
(
s
,
��
(
s
�O
��
)
�O
?
)
Q(s, \pi(s|\theta)|\phi)
Q(s,��(s�O��)�O?),��critic�����ղ�����ض���״̬s�����,Q��һ������actor�����ȵĸ��Ϻ���,��ʽ�ɵ�:
J = �� Q / �� �� = ( �� Q ( s , a ) / �� �� ( s �O �� ) ) ? ( �� �� ( s �O �� ) / �� �� ) J = \delta Q / \delta \theta = (\delta Q(s, a)/ \delta \pi(s|\theta)) * (\delta \pi(s|\theta)/\delta \theta) J=��Q/����=(��Q(s,a)/����(s�O��))?(����(s�O��)/����)
�õ��˵���,���ݶ���,�������ݶ����ϸ���,����ʹ�� Q ( s , �� ( s ) ) Q(s,\pi(s)) Q(s,��(s))��ֵ���,��actor��������ø��á�
����DDPG�㷨����ͼ:

���к��Ĺ�ʽ�����������:
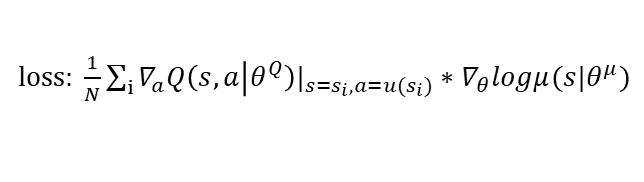
�����a=u(s),u(s)��
��
(
s
)
\pi(s)
��(s),����ȷ���Բ���,����д����u(s),���Ǹ�logֻ��һ������,������㡣