背景
为了衡量广告是否能提高销量检验广告的作用,我们分别对广告有触达和没触达的人群的购买率进行对比,由于人群太大所以只能抽样进行,需要有方法能够证明抽样是具有代表性的。
目标
我们通过抽样test组(有广告曝光)和control组(无广告曝光)做ab test来对比有无广告曝光对购买率的影响,为了确保结果是具有代表性的--即有显著性(significance),我们要对test vs control两组间的差异进行假设检验。
现实场景中我们避不开几个问题:
1. A/B test两组人群的转化效果是否存在差异――假设检验 Hypothesis Test
2. A/B test结果的只是小概率事件的可能性――显著水平 Significance Level
2. 我们正确判断出A/B test两组人群有差异的把握有多大――统计功效 Power
3. 在一定显著性水平和和统计功效下,我们需要选定多少样本量进行试验――反选样本量
本文涉及到的一些重要定义
Z检验和Z score
当样本量大于30时使用Z检验,样本量小于30时使用T检验。Z检验的过程是求X样本对应的Z score(aka 标准分数),根据Z score的另一条公式 Z=(x-μ)/σ 可知,Z score指的是在正态分布的前提下,样本x与总体的标准差之间的比值关系。又因为标准差σ的数学意义表示的是数据集的离散程度,所以Z score代表了样本x的分布在呈正态分布的“总体”中的“占比”。通过Z score可以查表得到x样本对应的概率值,用1减去这个概率值即求得 p-value,用p-value对比α可以判断样本x是否落在拒绝域内。
例如,当单尾检验时α=0.05时对应的z score=1.65,此时查表得知对应的面积 aka 概率值=0.9505;双尾检验时α=0.05时对应的单侧的阴影面积应为(1-0.9505)/2=0.02475,对应的z score是概率为1-0.02475≈0.975时的Z score=1.96。
此时若存在一个X样本对应的Z score等于1.7,1.7>1.65落在单尾检验的拒绝域,否定H0,significance=1,认为test vs control有显著差异;但1.7<1.96落在双尾检验的接受域,接受H0,significance=0,认为test vs control没有显著差异。
假设检验
假设检验(hypothesis testing),又称统计假设检验,是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。常用的假设检验方法有Z检验、t检验、卡方检验、F检验等。
1、提出检验假设又称无效假设,符号是H0;备择假设的符号是H1。H0:样本与总体或样本与样本间的差异是由抽样误差引起的;H1:样本与总体或样本与样本间存在本质差异;预先设定的检验水准为0.05;当检验假设为真,但被错误地拒绝的概率,记作α,通常取α=0.05或α=0.01。
2、选定统计方法,由样本观察值按相应的公式计算出统计量的大小,如X2值、t值等。根据资料的类型和特点,可分别选用Z检验,T检验,秩和检验和卡方检验等。
3、根据统计量的大小及其分布确定检验假设成立的可能性P的大小并判断结果。若P>α,结论为按α所取水准不显著,不拒绝H0,即认为差别很可能是由于抽样误差造成的,在统计上不成立;如果P≤α,结论为按所取α水准显著,拒绝H0,接受H1,则认为此差别不大可能仅由抽样误差所致,很可能是实验因素不同造成的,故在统计上成立。P值的大小一般可通过查阅相应的界值表得到。
来源于百度百科
第一类错误α 第二类错误β 以及? 检验效能power
第一类错误:是指拒绝了实际上成立的H0,为“弃真”的错误,丢弃了真阳性,其概率通常用α表示,称为显著性水平(significance level)。α可取单侧也可取双侧,可以根据需要确定α的大小,一般规定α=0.05或α=0.01。其意义为:如果假设检验结论拒绝H0,发生I型错误的概率为5%或1%,即100次拒绝H0的结论中,平均有5次或1次是错误的。?“ 人们把少见的行为或数据(小概率事件),看做是异常或不同,也就是significance。”
?第二类错误:是指不拒绝实际上不成立的H0,为“存伪”/“纳伪”的错误,容纳了假阳性,其概率通常用β表示。β只能取单尾,假设检验时一般不知道β的值,在一定条件下(如已知两总体的差值δ、样本含量n和检验水准α)可以测算出来。在假设检验中同时减少两类错误的最好方法是适当增加样本含量。
由定义可知 α 和 β 都是关于H0 的条件概率。
检验效能/统计功效 (power of the test):别名敏感度(sensitivity) ,定义为在原假设H0是错误的情况下正确拒绝原假设的概率,反映出广告是有效的并且我们能够得出相同结论的概率,power=1-β。
对于同一个检验,size和power是tradeoff的,不可兼得。对某个假设的两个不同test进行比较时,在相同的size下,power越高越好。常说某个test的power低,是指在control 5% size时,test过于保守,经常不能拒绝原假设。(作者:lakyblu链接:https://www.zhihu.com/question/306162938/answer/555571486来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。)
来源于百度百科

假设检验的结论和两类错误(这个图不叫混淆矩阵)
方法
1. 采用反证的思路,假设H0事件代表广告是没有作用的,则test组(有广告)的购买率=control组的购买率,H1则是 test组的购买率≠control组的购买率(由于不保证广告没有负面影响所以这里做双尾检验,若事件的影响是单向的则可用单尾检验,主要的差异是双尾检验的拒绝域被平均分为两边,H0事件要落在拒绝域内的条件更加苛刻)。
2. 由于样本中每个人群都只存在买or不买两种行为,于是认为样本符合二项分布。根据中心极限定理,二项分布可近似为正态分布,这是下面检验方法成立的前提。
3. 通过收集到的事件概率P_test, P_control(这里分别是广告组和无广告组各自的购买率)和样本量N_test, N_control,利用Z检验公式求得Z score,通过用Z score查表(附图在最后附录)可求得假设的p-value。
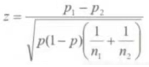
图为Z检验公式,?p1, p2分别为P_test(广告组购买率)和 P_control(无广告组购买率),n1, n2分别为?样本量N_test, N_control,p=(p1*n1+p2*n2)/(n1+n2)
4. 通过对比p-value是否<α决定是否接受原假设,若是,则根据小概率原理判断原假设不成立,从而接受备择假设,当α=0.05时得出结论:有95%的把握test跟control在该广告曝光后的购买率是有显著差异的。
第二类错误和统计功效的计算
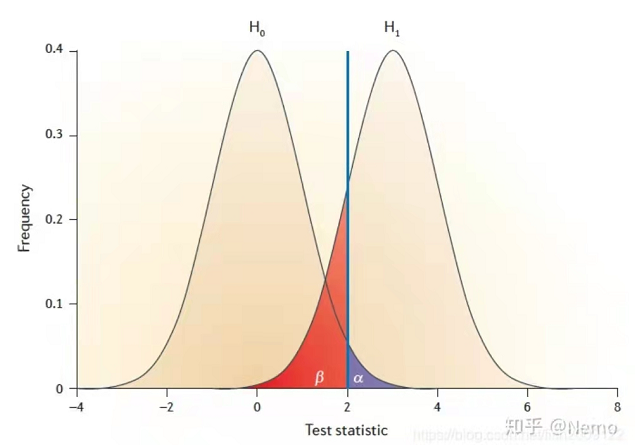
H0假设下的分布(左)与H1假设下的分布(右)
蓝色部分就是我们的α 就是h0拒绝域。
红色部分代表的概率就是β,其通俗的理解方法:在假设检验中处于h0的接受域,但是实际红色部分是属于h1这个总体的。
计算β和power
1. 首先通过公式?Z=(x-μ)/σ 求得使alternative条件H1成立的阈值threshold x的取值范围(即当Z score刚好等于α=0.05对应的z = 1.96 (双尾) or 1.65 (单尾)时的x)
2. 由于H1成立,我们有理由认为样本X是一个均值μA落在H0拒绝域内的分布(即上图右边的数据集分布),μA由ab test统计得出。
3. 同样通过公式 Z=(x-μ)/σ 求得当threshold x不变,μ由H0的μ0变为H1的μA时(σ不变),β拒绝域(红色区域)对于H1分布而言的Z score = Zβ。
4. 由Zβ查表求得β拒绝域所对应的概率p-value = β。
5. 求得功效 Power = 1 -?β。
计算过程教学参考视频:https://www.bilibili.com/video/BV1CV411y76B?from=search&seid=15759938247074871487&spm_id_from=333.337.0.0

绿色是H0,粉红色是H1
影响Power的因素
1. α ↑? => β ↓?=> power ↑? ? ? ? ? ? ? ? ?弃真率下降,FN减少,TP增加, power增加? /? ?α增加,threshold右移,β减小,power增加
2. n?↑? => β ↓?=> power ↑? ? ? ? ? ? ? ? ?样本量增加,标准差减小,分布的锥形会变窄
3. (μA - μ0) ↑? => β ↓?=> power ↑? ? ?如果广告效果相当显著,不需要很多的样本就能发现
最小样本量计算
最小样本量是在准备开展AB实验时,对目标提升效果预计需要的样本量估算,方便提前估算出AB实验的运行周期。
以单边检验为列,进行最小样本量计算,假设两组样本数量相等,均为n ,则最小样本量为:

S均值, σ标准差
双边检验的推导类似,最小样本量为:

S均值,?σ标准差
最小样本量同时考虑了第一类、第二类错误。
Summary
・ 假设检验是利用反证法来判断样本的事件与总体的事件之间有无差异的方法。
・ Z score是样本分布与总体分布之间的比例,用于推算样本代表的事件出现的概率。
・ p-value则是单侧拒绝域的概率面积,用于查表找到对应的Z score方便对比事件出现的概率。
・ 检验的方法就是,假设我们希望出现的事件的相反事件才是大概率存在的,求该相反事件出现的概率,如果落在拒绝域则说明这个相反事件才是小概率出现的,反过来说明我们希望出现的事件是大概率出现的。
延伸拓展
A/B Test中的Test和control是两个不同的样本,而m+和m-是同一个两本中的两种不同结果的群体(在广告的例子中就是 test组 or control组 当中的 购买 和 没有购买 的群体)。若把有广告曝光记作事件A,没有曝光记作事件B,则test和control对比的是事件A和B带来的差异,这个差异就是m+和m-的分布,事件A和B内部都会有m+和m-,即m+(A) m-(A)和m+(B) m-(B)。
第一类错误α第二类错误β与ROC曲线及精度、召回率之间的差异,体现了统计学和机器学习之间的学科差异:
在机器学习中:
????ROC Curve中(附图如下):
????????X轴- 假阳性在负样本中的比例,FP/m- =?FP/(FP+TN) = FPRate假阳率;
????????Y轴- 真阳性在正样本中的比例,TP/m+ = TP/(TP+FN) = TPRate真阳率? = Recall召回率。
????*m+: 正样本集合,m-:负样本集合,FP: False Positive假阳性,TN: True Negative真阴性。
????Recall召回率 = TP/(TP+FN);Precision精度 =?TP/(TP+FP)。?
在统计学中的:
????第一类错误指的是弃真率,即FN/m-,是假阴性在负样本中的比例。
????第二类错误指的是纳伪率,即FP/m+,是假阳性在正样本中的比例。
统计学中所关注的一些量大抵都是可以被推断(inference)的,有时候不那么care实际使用,但一定要能够被分析推断(推断的定义和细节自行GG)。机器学习作为一门实用型工具学科(其实还是起源于统计,不过后来慢慢地混进了一些CS就变味了),更注重指标实用性。
从Paper里面可以很明确的感知到这一点,统计的文章有明晰的推理证明过程,给出统计量的分布,属于理论科学;比较近的机器学习文章一般喜欢画个分布图,举几个算例概括概括,属于实验科学。(早期的机器学习文章严格来说叫统计学习,毕竟是统计学家搞的,有严格的模型结构)。
参考引用知乎作者:ChenZhou
链接:https://www.zhihu.com/question/414461284/answer/1416350616
个人觉得和应用场景?的关系比较大。
比如机器学习的应用,非常广泛,其中有很多是预测、分类(比如图像识别,预测收入)。这样的问题里最重要的需求是提供可靠的决策支持,预测得准、分类得准。如果用假阳性、假阴性来说,就是希望TPR、FNR都尽量给我低一点。(回想一下常用的指标,ACC、F1-score,其实都是希望判对、判错都尽量准一些。在这种场景下,假阳性、假阴性产生的代价一般是差不多的。我把一副猫的照片判成猴子,猴子照片判成猫,好像都差不多。
而假设检验的应用场景,在医疗、生物比较多(当然在其他行业也广泛存在,比如xx公司推荐系统上线一个新算法了,经常选择做ABtest,用假设检验来看是否新算法靠谱)。在这种场景下,假阳性和假阴性带来的代价是不对等的。比如,我的目标是推断“如果病人有XX症状,那么ta是否得了癌症”,我的统计推断模型能够输出“是”和“否”,那么如果有一个假阳性的案例(病人实际没得癌症,但我的模型说ta得了)和一个假阴性的案例(病人实际得了,但模型说ta没得),明显这两个代价天差地别!两个都是判断错了,但是第一个最多让病人受惊吓,第二个则会错失挽救生命的机会。所以这时候可能我们会选择更更更重点关注假阴性,让假阴性出现越小越好,假阳性出现多一点可以包容。
这样一来,可能两个模型,模型A从ACC、F1-score来看比模型B要差(也就是说从一般的分类模型意义来看,A的预测准确度更差),但是模型A的假阴性率更低,那我们也要选择模型A,因为犯错的代价是不对等的。
参考引用知乎作者:张铁山
链接:https://www.zhihu.com/question/414461284/answer/1435663339
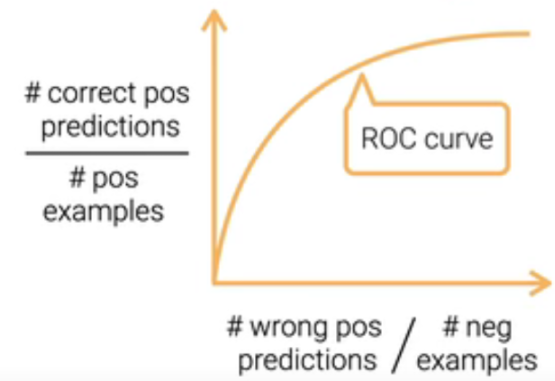
ROC Curve
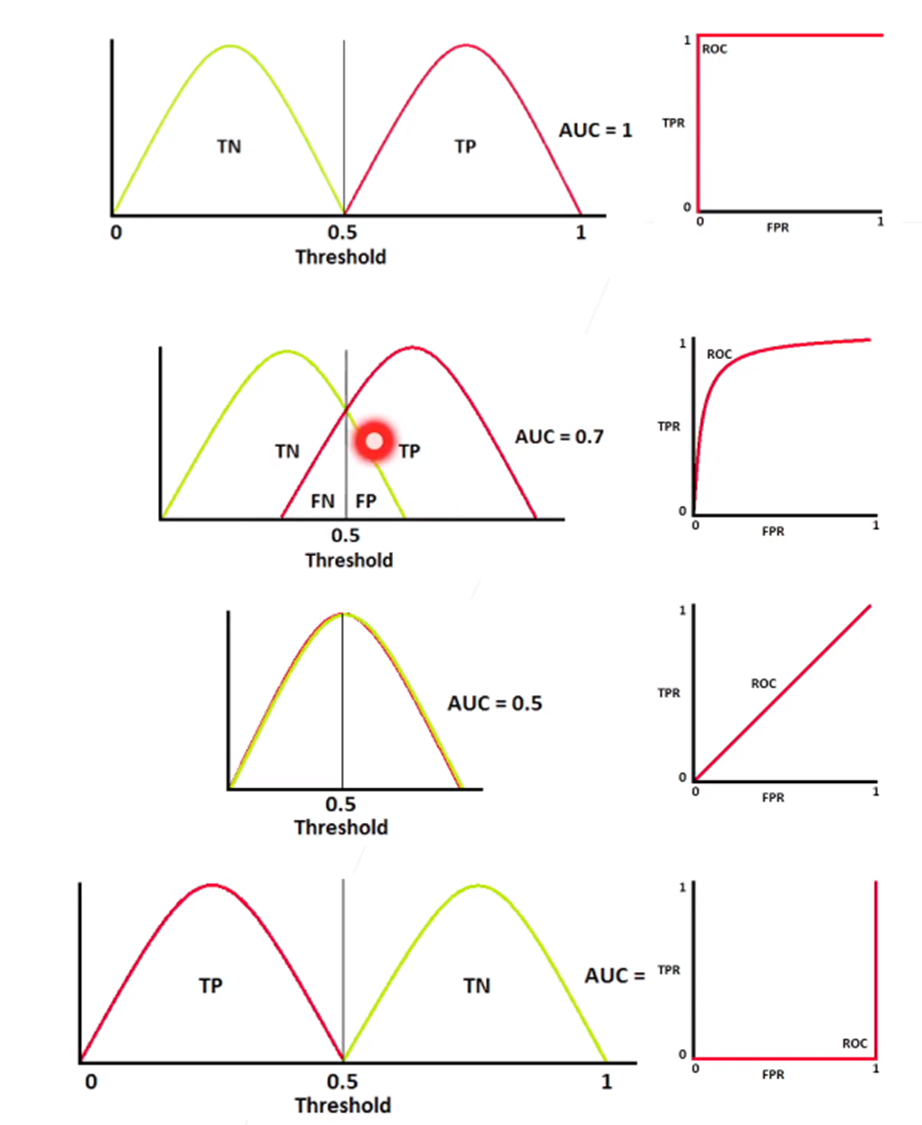
ROC Curve的解读示例
图片来源于李沐大神的《实用机器学习》课程
鸣谢
谨以此文感谢Garson Weichun在该内容上一起学习讨论!
附录
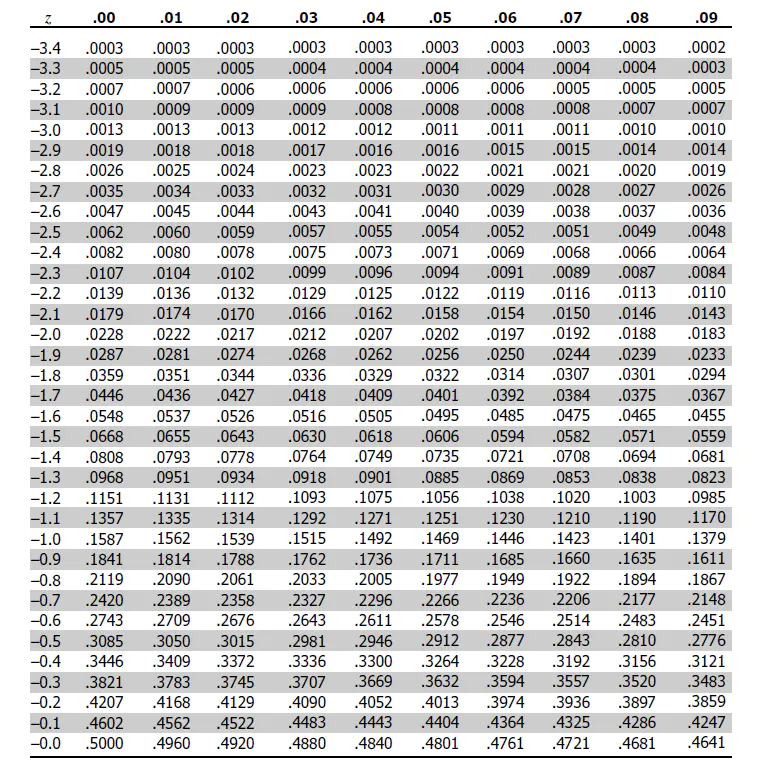
Z值表格1:z score对应的概率
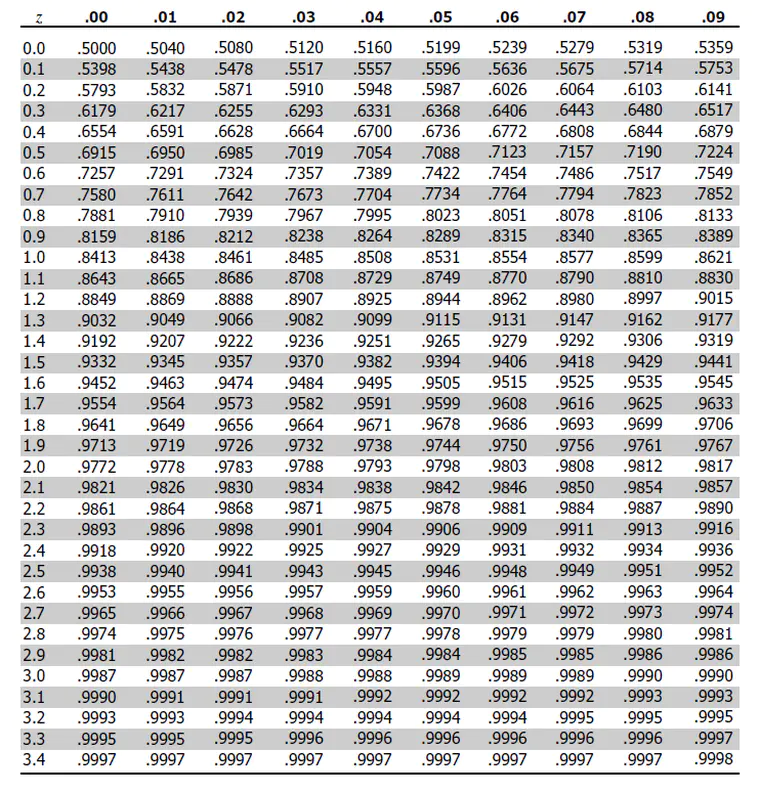
Z值表格2:z score对应的概率