Reformulating Zero-shot Action Recognition for Multi-label Actions笔记
前言
近期导师给发了一篇21年NeurlPS收录的一篇文章,读完之后略有感触写与此。
摘要
1、提出了一个ZSAR框架,它不依赖于最近邻分类,而是由一个成对的评分函数组成
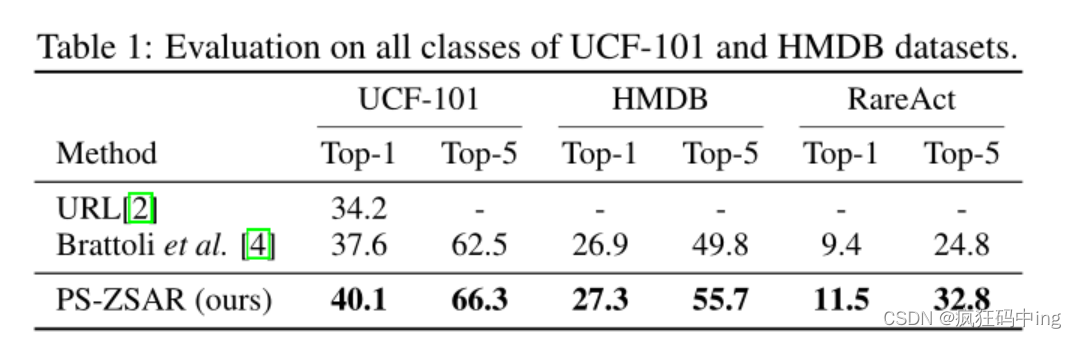
2、作者的方法不仅在三个单标签动作分类数据集(UCF-101、HMDB和RareAct)上取得了强大的性能,而且在一个具有挑战性的多标签数据集(AVA)和一个真实世界的惊喜活动检测数据集(MEVA)上也优于以前的ZSAR方法。
Introduction
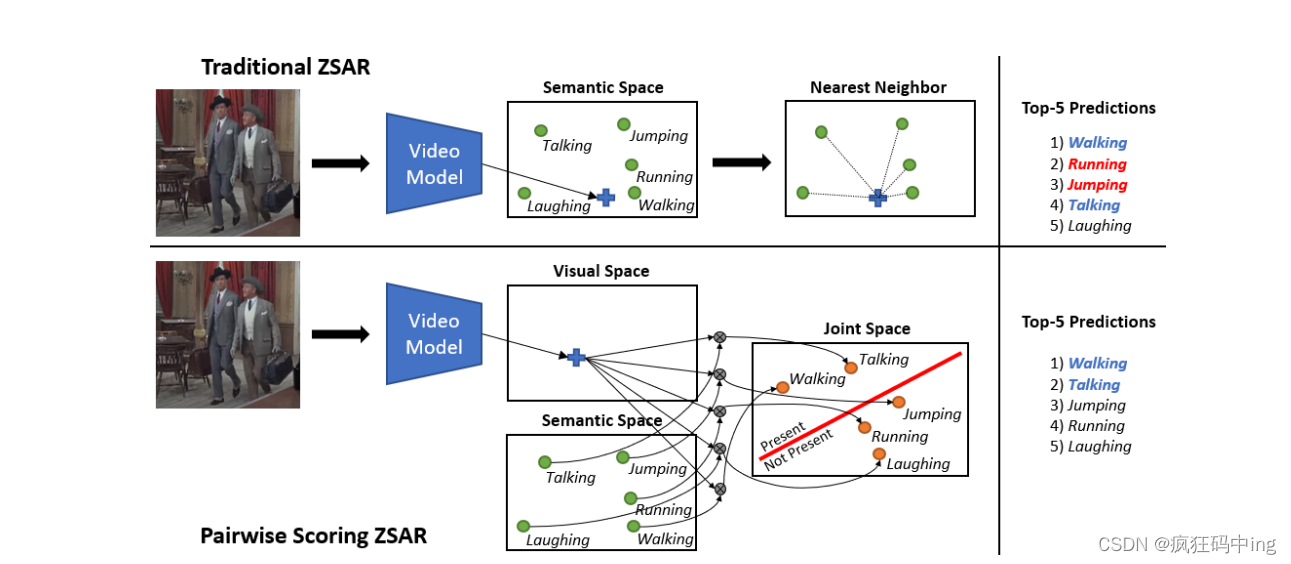
作者指出传统的方式是根据近邻法如上图所示,根据距离来判断行为,而作者的方法是跟定一段视频与动作类独立的预测每个类的信息分数。
Method
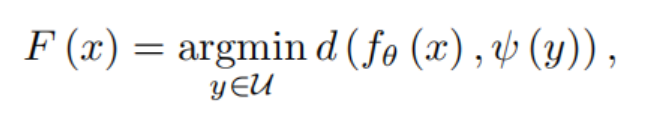
ψ(y)每个类的语义嵌入向量,fθ:将输入的视频映射到语义空间所得到的输出,d为距离度量
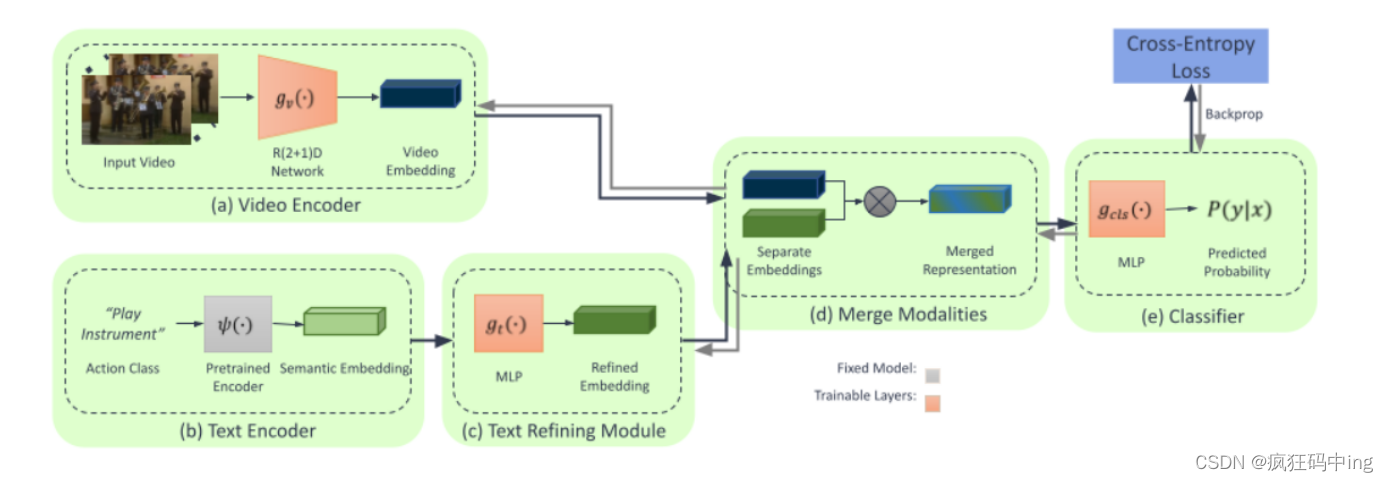
a、从视频编码器提取视频特征
b、文本编码器生成语义嵌入
c、文本细化模块微调语义嵌入
d、评分函数生成匹配概率
e、采用交叉熵损失函数进行端到端的训练
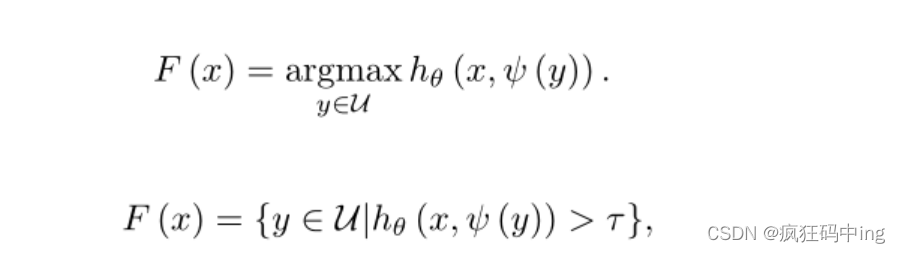
上述为作者提出的评分函数,作者指出当得分当大于某个阈值是即为多标签
评分过程细则:
由于传统的文本编码器往往缺乏动作的视觉属性信息,比如:流水和人跑在视觉上是不同的,但跑的嵌入对于两者都是相同的。因此作者提出了一个模块gt,用于他改进或微调文本编码,生成一个gt (ψ (y)) 当做新的文本表示
首先合并提取的视觉特征和细化的文本特征得到m (gv (x), gt (ψ (y))),作者指出可以用使用多种方式比如连接、加法、乘法,然后通过MLP,gls获得分类logits
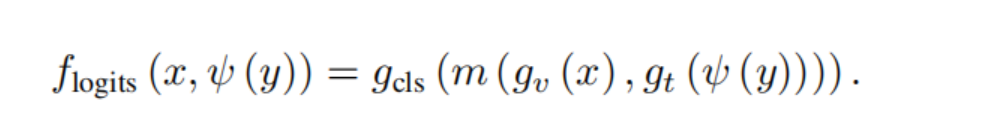
最后通过softmax得到最终的概率分数,当对多标签训练时softmax换位sigmoid
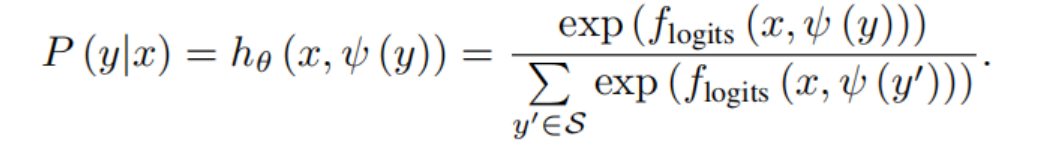
训练采用交叉熵损失: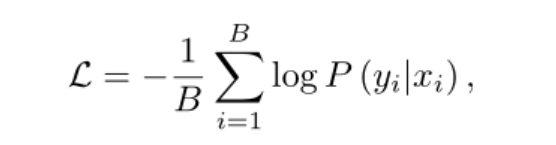
实现细节:
视频编码器采用pytorch实现的R(2+1)D-18网络,文本编码器默认使用Word2Vec模型
文本细化模块由一个学习的3层MLP组成,隐藏维度为1024,ReLU激活,最终输出维度为Dt=600。输出通过一个sigmoid激活来获得范围[0,1]内的嵌入。使用Adam优化器,初始学习率为1e-3,批量大小为114