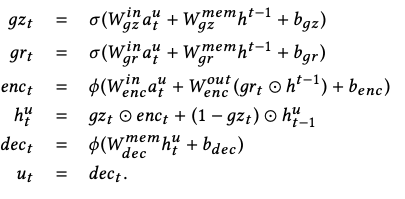一、概述
本文提出了一个三层的基于embedding的分布式表示方法:
- 基于一种弱监督的降噪自编码器对文章进行embedding向量化;
- 利用用户的历史浏览信息作为rnn的训练数据生成用户的embedding向量;
- 直接利用文章embedding向量和用户的embedding向量做内积,匹配出用户最可能感兴趣的topN文章列表,并对该列表做去重。
日本雅虎团队将该推荐策略应用在来日本雅虎的智能手机主页推荐业务上。整个流程分为五部分:
- 识别:获得预先根据用户历史数据计算好的用户特征
- 匹配:使用用户特征从所有可用的文章中提取出候选文章集
- 排序:按照一定的排序规则算法对文章进行排序
- 去重:移除包含相同信息的文章
- 广告:必要时插入广告
以上这一系列动作都需要在用户的请求和显示推荐的文章这之间的几百毫秒内全部完成,但是每天能推荐的文章是一直在变的,有成千上万的文章被删除,也有成千上万的文章加进来,所以必须得提前将所有的文章emebdding和用户embedding计算好。然后再针对每个用户去选取候选的文章,选取的方式就是计算用户embedding和文章embedding的内积,根据内积的大小设置预测来选取一定数量的候选文章集。
有了候选文章集就可以继续利用其他的因素,来对文章进一步的精排序,比如文章的访问量,文章的新鲜度等等,这就需要进一步对文章,用户以及文章用户之间的上下文信息进行特征工程。
基于embedding可以对文章进行去重。本文作者采用的是利用贪心策略对推荐出的文章集合进行去重。分别计算推荐出的文章embedding的余弦相似度,当排序后更加靠前的文章和后面的文章余弦相似度超过一定阈值后,就把后面的文章认为和前面的文章重复,把后面出现的文章从推荐列表中去掉。
二、文章embedding的生成方法
利用降噪自编码器来生成embedding向量:

原始输入x,经过损坏函数q(x),破坏原始的输入x,生成了被损坏的
x
~
\widetilde{x}
x
,然后经过全连接f(x)就可以隐层的表示h了,再通过同样的方式把h重建回原来的x;就是上图中的y。最终的损失函数就是要让重建的y和真实的输出x尽量一致。做q(x)的目的就是为了让学习出来的f(x)能更加的鲁棒。
但是自编码器只能将原始的输入进行编码,无法学习输入的文章是否是相同或者不同的文章,所以需要对降噪自编码器的损失函数做来一点修改,加入一点监督信息,让模型能学习到文章之间的差异和相似。即:
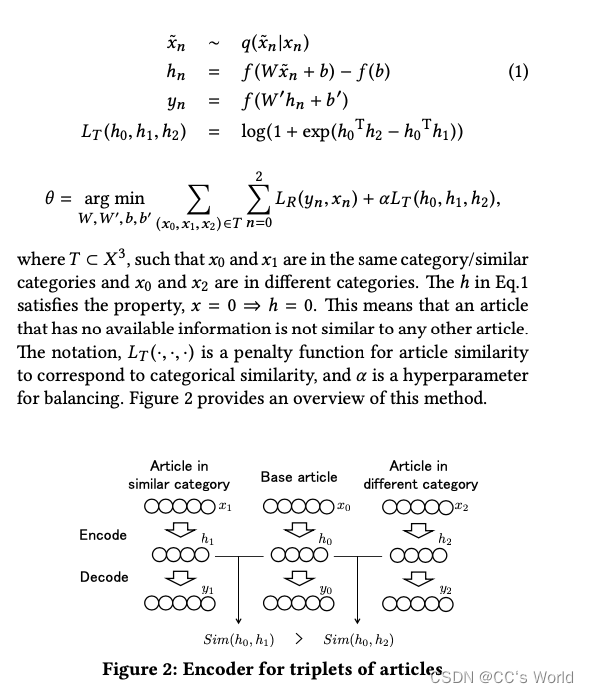
和原始的降噪自编码器对比一下就能发现,改动主要在损失函数,但是这里整体的网络结构是个三元组(
x
0
,
x
1
,
x
2
x_0,x_1,x_2
x0?,x1?,x2?)。其中
x
0
x_0
x0?和
x
1
x_1
x1?来自同一类目,
x
0
x_0
x0?和
x
2
x_2
x2?来自不同的类目。可以看出来主要的区别就是在损失函数中加入了对三个输出的隐层的度量,使得
h
0
h_0
h0?和
h
1
h_1
h1?的相似度能大于
h
0
h0
h0和
h
2
h_2
h2?的相似度。从这部分损失就可以看出来,log(1+exp(x))要想最小化就需要exp(x)尽量等于0,那么x就要趋近于负无穷。这里的x就是
h
0
T
h
2
?
h
0
T
h
1
h_0^Th_2-h_0^Th_1
h0T?h2??h0T?h1?,要让
h
0
T
h
2
?
h
0
T
h
1
h_0^Th_2-h_0^Th_1
h0T?h2??h0T?h1?趋近于负无穷就是要让
h
0
T
h
1
h_0^Th_1
h0T?h1?远大于
h
0
T
h
2
h_0^Th_2
h0T?h2?。

最后模型生成的h就是输入x的emebdding向量。
三、用户embedding向量的生成方法
用户u ∈ U 的浏览历史表示为:
a
u
∈
A
t
=
1
,
?
?
?
,
T
u
{a_u ∈A}_{t=1,・・・,T_u}
au?∈At=1,???,Tu?? ,其中a是文章的分布式表示向量。
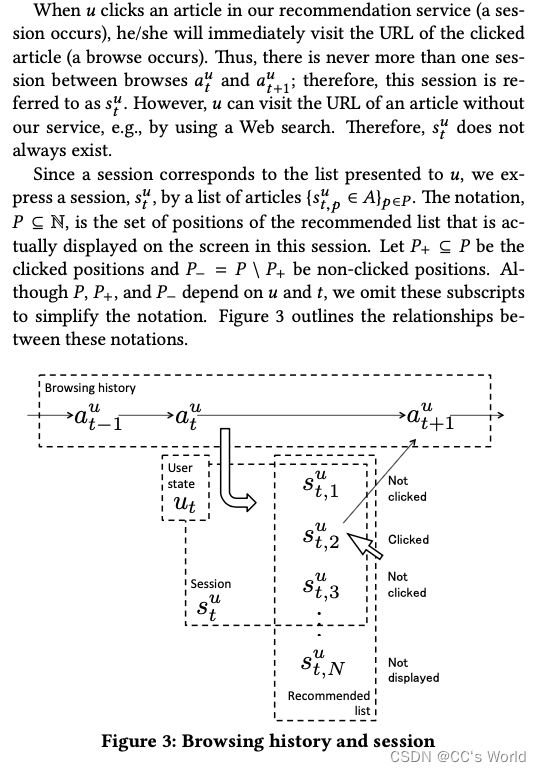
u
t
u_t
ut?是取决于
a
1
u
,
.
.
.
,
a
t
u
a_1^u, ..., a_t^u
a1u?,...,atu?的用户状态,
R
(
u
t
,
a
)
R(u_t,a)
R(ut?,a)是用户状态
u
t
u_t
ut?和文章a之间的相关性。我们的主要目标是构造满足以下性质的用户状态函数F和相关函数R:
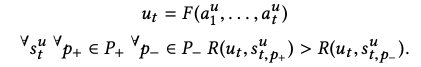
在考虑具有大流量的实际新闻发布系统的受限响应时间时,R必须是一个可以快速计算的简单函数。因为候选条目经常被替换,所以不可能预先计算所有用户以及所有文章之间的相关性得分。因此,有必要在很短的时间内进行计算。但是,我们有足够的时间计算用户状态函数F,直到下一个会话从浏览某些文章页面开始。
基于这些原因,我们将相关函数
R
(
u
t
,
a
)
R(u_t,a)
R(ut?,a)限制为一个简单的内积关系
R
(
u
t
,
a
)
=
u
t
T
a
R(u_t,a)=u_t^Ta
R(ut?,a)=utT?a,并且只优化用户状态函数F。优化目标为:
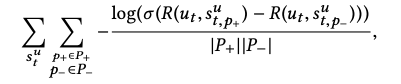
由于存在偏差,在实践中,当文章被垂直排列时,点击概率取决于显示位置,我们使用以下目标,包括偏差项B(・,・),来纠正此类影响:
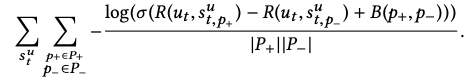
然后用GRU进行建模: