������ѧϰ�������ڶ��� ģ��������ѡ��
һ�������������
1.1 �������ͷ������
�����ʹ�ʽ
������
=
��������
��������
\text{������}=\frac{\text{��������}}{\text{��������}}
������=����������������?
���ȹ�ʽ
����
=
1
?
������
\text{����}=1-\text{������}
����=1?������
�������(ѵ�����):ѧϰ����ѵ�����ϵ����
�������:ѧϰ�������������ϵ����
1.2 ����Ϻ�Ƿ���
�����:ѧϰ����ѵ����������ѧ��̫����,���ܰ�ѵ������������һЩ�ص㵱����DZ�������������һ�������,���·��������½�
Ƿ���:��ѵ��������һ��������δѧ��
��־����ʦ�����оٳ���������һ������

������������
���ڷ���������Բ��Գ�,��˲��ò��������Ϊ������
�������
��
�������
\text{�������}\approx \text{�������}
����������������
2.1 ������
ֱ�ӽ����ݼ�D����Ϊ��������ļ���,����һ����ѵ����S,һ���Dz��Լ�T,S��T�������й�ϵ
{
D
=
S
��
T
?
=
S
��
T
\left\{ \begin{array}{c} D=S\cup T\\ \varnothing =S\cap T\\\end{array} \right.
{D=S��T?=S��T?
Tip:�����������������Ĵ�С��ͬ,������ģ��ѧϰ�Ľ������һ����Ӱ��,����Ϊѧϰ�㷨��Ҫ�����ݼ�D����ѧϰ,�����ַ�����Ҫ�����ݼ�D���л���,���ͨ�õĽⷨ�ǽ����2/3~4/5��������Ϊѵ����,ʣ��������Ϊ���Լ�
2.2 ������֤��
������֤��:�����ݼ�D����ΪK����С���ƵĻ����Ӽ�,���÷ֲ�����ķ���,��
D
=
D
1
��
D
2
��
?
��
D
k
(
D
i
��
D
j
)
D=D_1\cup D_2\cup \cdots \cup D_k\left( D_i\ne D_j \right)
D=D1?��D2?��?��Dk?(Di?��?=Dj?)
������֤��������ͼ������ʾ,
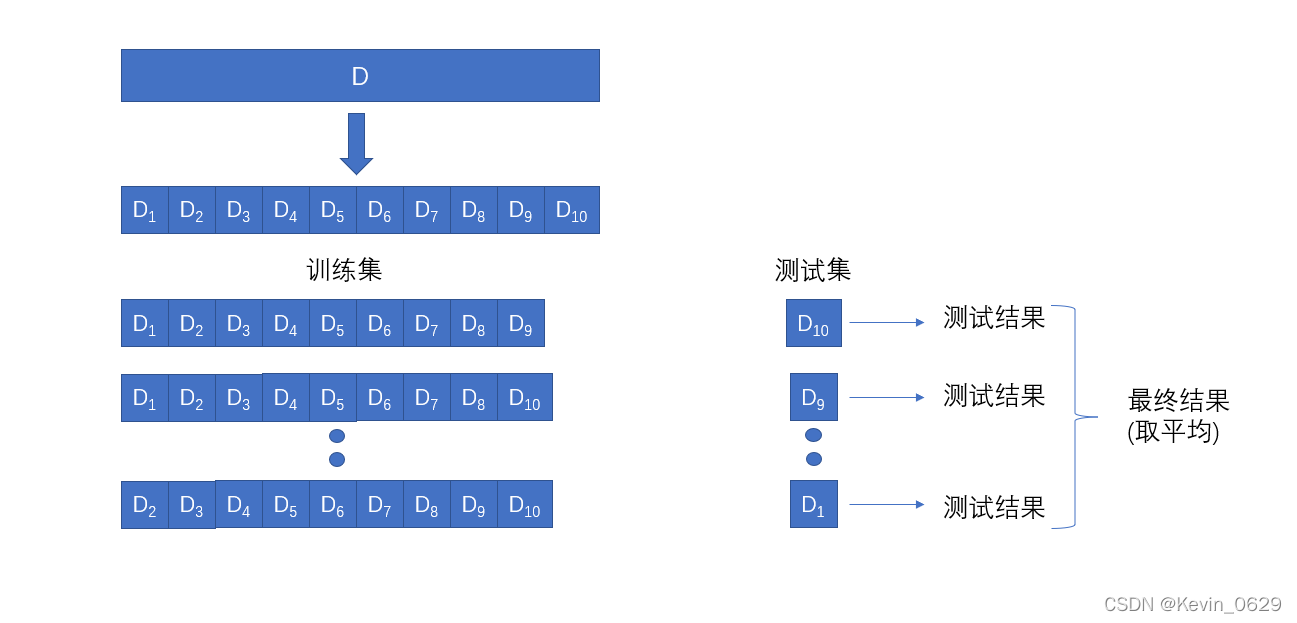
2.3 ������
һ�仰��������,ͨ�������ķ��������ݼ��е����ݽ��еȸ��ʵķŻ��Ͳ���,����������m�β�����ʼ�ղ����������ĸ���Ϊ
lim
?
(
1
?
1
m
)
m
��
0.38
\lim \left( 1-\frac{1}{m} \right) ^m\approx 0.38
lim(1?m1?)m��0.38
2.4 ����������ģ��
ÿһ��ģ�Ͷ����趨һ��Ĭ�ϵ�defaultֵ����,�����������defaultֵ����ѵ��������ģ�͵�Ч������,��˾���Ҫ����ʹ�õ��㷨���е���,���㷨���е��ξ��漰������������,������ڳ��õķ������趨һ�������ķ�Χ�Ͳ���,ͨ���Բ����ĵ���,Ȼ��ȥѵ��ģ��,��������㷨�еIJ����кܶ��,��ֹ��һ������,�����Ȼ����һ���ļ�����,ͬʱ���ڱȽ��µ��������������ȵ��η���,ֻ��ͨ����ģ�͵IJ������е��ں�,���ģ�Ͳ��������������ϱ��ֳ��ܺõ�����
�������ܶ���
��ô�����ܶ�ѧϰ��,���㷨����һ������,��������㷨���ѧϰ���Ǻõ�,����㷨�Ǻõ���,�����Ҫ�õ����ܶ�����һЩ���õķ���
3.1 �������뾫��
����ڶ����������
������:�������Ƿ�����������ռ���������ı���,��������
E
(
f
;
D
)
=
��
I
I
(
f
(
x
)
��
y
)
p
(
x
)
d
x
E\left( f;D \right) =\int{II\left( f\left( x \right) \ne y \right)}p\left( x \right) dx
E(f;D)=��II(f(x)��?=y)p(x)dx
����:�����Ƿ�����ȷ��������ռ���������ı���
a
c
c
(
f
;
D
)
=
��
(
f
(
x
)
=
y
)
p
(
x
)
d
x
=
1
?
E
(
f
;
D
)
acc\left( f;D \right) =\int{\left( f\left( x \right) =y \right) p\left( x \right) dx}\\=1-E\left( f;D \right)
acc(f;D)=��(f(x)=y)p(x)dx=1?E(f;D)
3.2���ʡ���ȫ���� F 1 F1 F1
| ��ʵ | Ԥ���� | Ԥ���� |
|---|---|---|
| ��� | ���� | ���� |
| ���� | TP(������) | FN(������) |
| ���� | FP(������) | TN(�淴��) |
����P
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP?
��ȫ��R
R
=
T
P
T
P
+
F
N
R=\frac{TP}{TP+FN}
R=TP+FNTP?
���ʺͲ�ȫ����һ��ì�ܵĶ���
Ϊ���ܹ����õĹ۲����һ��ѧϰ������,��ǰ����������ͼ��ʾ��P-R����ͼ
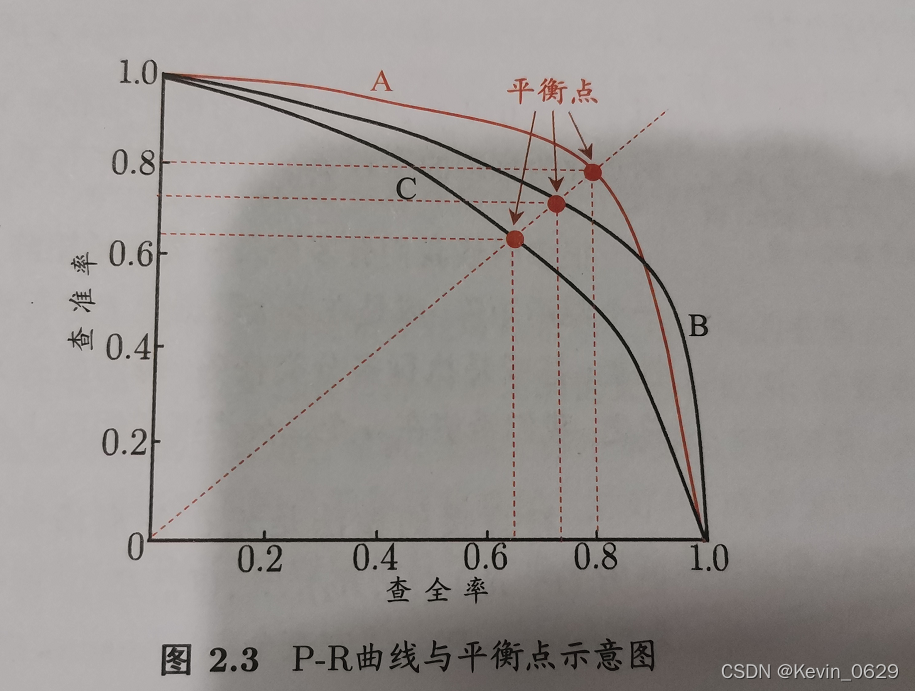
һ���õ�ѧϰ�������б�����
- ���һ��ѧϰ�������߰���������һ��ѧϰ��������,��ô���������ѧϰ�����������ڱ�������
- �Ƚ�����P-R��������Χ�����
- ʹ�á�ƽ��㡱,������
y
=
x
y=x
y=x����һ������ֱ��,�ҳ�����������ֱ���������λ��,����=��ȫ��,��ʱ��ֵ��ΪBEP,��ͨ���Ƚ�BEP��ֵ�����֪����һ��ѧϰ������
ʹ��BEP������ڼ�,�������F1�ĸ���
���õ�F1������
F 1 = 2 �� P �� R P + R = 2 �� T P �������� + T P ? T N F1=\frac{2\times P\times R}{P+R}=\frac{2\times TP}{\text{��������}+TP-TN} F1=P+R2��P��R?=��������+TP?TN2��TP?
F1������һ����ʽ F �� F_{\beta} F��?
F �� = ( 1 + �� 2 ) �� P �� R ( �� 2 �� P ) + R F_{\beta}=\frac{\left( 1+\beta ^2 \right) \times P\times R}{\left( \beta ^2\times P \right) +R} F��?=(��2��P)+R(1+��2)��P��R?
���������� �� \beta ����ȡֵ, �� \beta ��>0�����˲�ȫ�ʶԲ��ʵ������Ҫ��, �� \beta ��=1�����˱���F1, �� \beta ��>1ʱ��ȫ���и���Ӱ��, �� \beta ��<1�����и���Ӱ��
���ϻ��г������������������ڲ��ʺͲ�ȫ�ʵı���,����Ͳ�һһ�оٳ�����
3.3 ROC��AUC
ROC���о�ѧϰ���������ܵ���������,����ѧϰ����Ԥ������������������,����˳�������������Ϊ��������Ԥ��,ÿ�μ����������Ҫ����ֵ,�ֱ���������Ϊ�ᡢ��������ͼ,ROC���ߵ������ǡ���������(TPR)��,�����ǡ���������(FPR)��,����TPR�Ķ�������
T
P
R
=
T
P
T
P
+
F
N
TPR=\frac{TP}{TP+FN}
TPR=TP+FNTP?
FPR��������
F
P
R
=
F
P
T
N
+
F
P
FPR=\frac{FP}{TN+FP}
FPR=TN+FPFP?
��ô���ͨ��ROC����ͼ���ж�ѧϰ����ѧϰ����������?
��:ͨ��ROC��X��Y��Χ�ɵ����AUC����ʾ��ѧϰ���ĺû�,����AUC�Ķ�������
A
U
C
=
1
2
��
i
=
1
m
?
1
(
x
i
+
1
?
x
i
)
(
y
i
+
y
i
+
1
)
AUC=\frac{1}{2}\sum_{i=1}^{m-1}{\left( x_{i+1}-x_i \right)}\left( y_i+y_{i+1} \right)
AUC=21?i=1��m?1?(xi+1??xi?)(yi?+yi+1?)
3.4 ��������������������
��ѧϰ�����������ʱ��,ǰ���ѧϰ��Ĭ�Ϸ�������ʱ���������Ĵ�����һ����,������ʵ�еĴ��۲�����ͳһ��,��˱���������Ĵ������д�����
E
(
f
;
D
;
cos
?
t
)
=
1
m
(
��
x
i
��
D
+
I
I
(
f
(
x
i
)
��
y
i
)
��
cos
?
t
01
+
��
x
i
��
D
?
I
I
(
f
(
x
i
)
��
y
i
)
��
cos
?
t
10
)
E\left( f;D;\cos t \right) =\frac{1}{m}\left( \sum_{x_i\in D^+}^{}{II\left( f\left( x_i \right) \ne y_i \right) \times \cos t_{01}+\sum_{x_i\in D^-}^{}{II\left( f\left( x_i \right) \ne y_i \right) \times \cos t_{10}}} \right)
E(f;D;cost)=m1?(xi?��D+��?II(f(xi?)��?=yi?)��cost01?+xi?��D?��?II(f(xi?)��?=yi?)��cost10?)
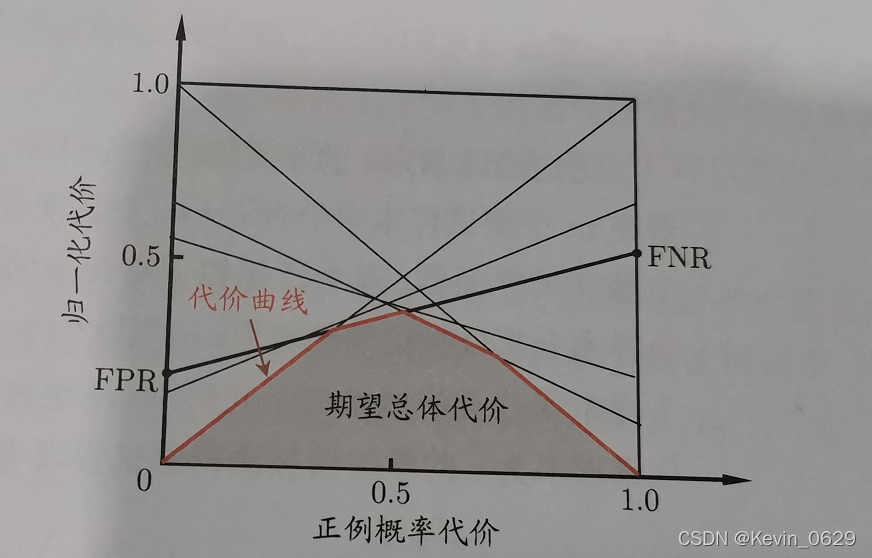
���ƴ�������ͼ,����FNR�ٷ����ʶ�������
F
N
R
=
1
?
T
P
R
FNR=1-TPR
FNR=1?TPR
��ROC������ÿһ���Ӧ�˴���ƽ���ϵ�һ���߶�,��ROC�����ϵĵ�����Ϊ(FPR,TPR),����Լ�����Ӧ��FNR,Ȼ���ڴ���ƽ���ϻ���һ����(0,FPR)��(1,FNR)���߶�,�߶��µ��������ʾ�˸������µ��������������,�鱾�����Ĵ��ۺ�����������ͼ��ʾ,
�ġ��Ƚϼ���
��ͨ���Ķ����ϵ������Լ������github��һ��������д�����ݽ��������������&����&ƫ��
�塢�ܽ�
ͨ���Ķ�����,�Ҷ�ѧϰ�������еĺû��ı��Լ����������û��������һ�����˽�,���ǶԼ�����һ����Ȼ������һ����֪ʶä��,ϣ����Щä���������Ժ��������Ĺ������ܹ�������������